
ReWOO:解耦推理与观测的高效 Agent 架构
ReWOO是一种革命性的AI Agent架构,通过将推理与观测解耦,显著提升任务执行效率。它采用Planner、Worker、Solver三角色协作机制,相比传统ReAct架构,Token消耗减少5倍,同时在HotpotQA等基准测试中准确率提升4.4%。ReWOO通过预见性规划、依赖图分析和智能并发调度实现高效执行,特别适合批处理任务,但存在容错性不足等局限。生产实践中,Claude Code等
引言:为什么需要 ReWOO?
在 AI Agent 技术快速演进的今天,Token 效率已成为生产环境部署的核心瓶颈。当我们构建能够调用外部工具、执行复杂任务的增强型语言模型(ALM, Augmented Language Models)时,传统的 ReAct(Reasoning + Acting)架构虽然直观易实现,却面临一个致命缺陷:每一步推理都需要将完整历史上下文重新送入大模型,导致 Token 消耗随步骤数线性爆炸。
2023 年,Xu 等人在论文《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》中提出了革命性的解决方案——ReWOO(Reasoning WithOut Observation)。这一架构通过将推理过程与外部观测解耦,实现了 5 倍的 Token 效率提升,同时在 HotpotQA 等多步推理基准上取得了 4.4% 的准确率提升。
本文将从架构专家的视角,深入剖析 ReWOO 的设计哲学、三角色协作机制、执行策略,以及它在 Claude Code 等生产系统中的工程实践。
一、核心痛点:ReAct 的 Token 冗余危机
1.1 ReAct 的"历史包袱"问题
ReAct 架构采用交错式推理-观测循环:
Thought → Action → Observation → Thought → Action → Observation → ... → Final Answer
这种模式的问题在于上下文累积爆炸:
- 每步推理需携带完整历史:即使后续步骤不依赖前序结果,历史记录仍全量传递
- 冗余 Token 线性增长:N 步任务 ≈ N 次 LLM 调用,Token 开销随步骤数线性增长
- 计算复杂度失控:长序列任务的成本变得不可接受
根据论文实验数据,在 10 步任务中,ReAct 的 Token 消耗可达 ReWOO 的 5 倍以上。
1.2 预见性推理的曙光
ReWOO 的核心洞察是:大语言模型具备"预见性推理"(Foreseeable Reasoning)能力——即在不获取外部观测的情况下,预判多步执行计划的可行性。这种能力使得我们可以一次性生成完整计划,而非逐步迭代。
二、ReWOO 三角色架构:解耦的艺术
ReWOO 将 Agent workflow 分解为三个专业化角色,形成清晰的职责边界: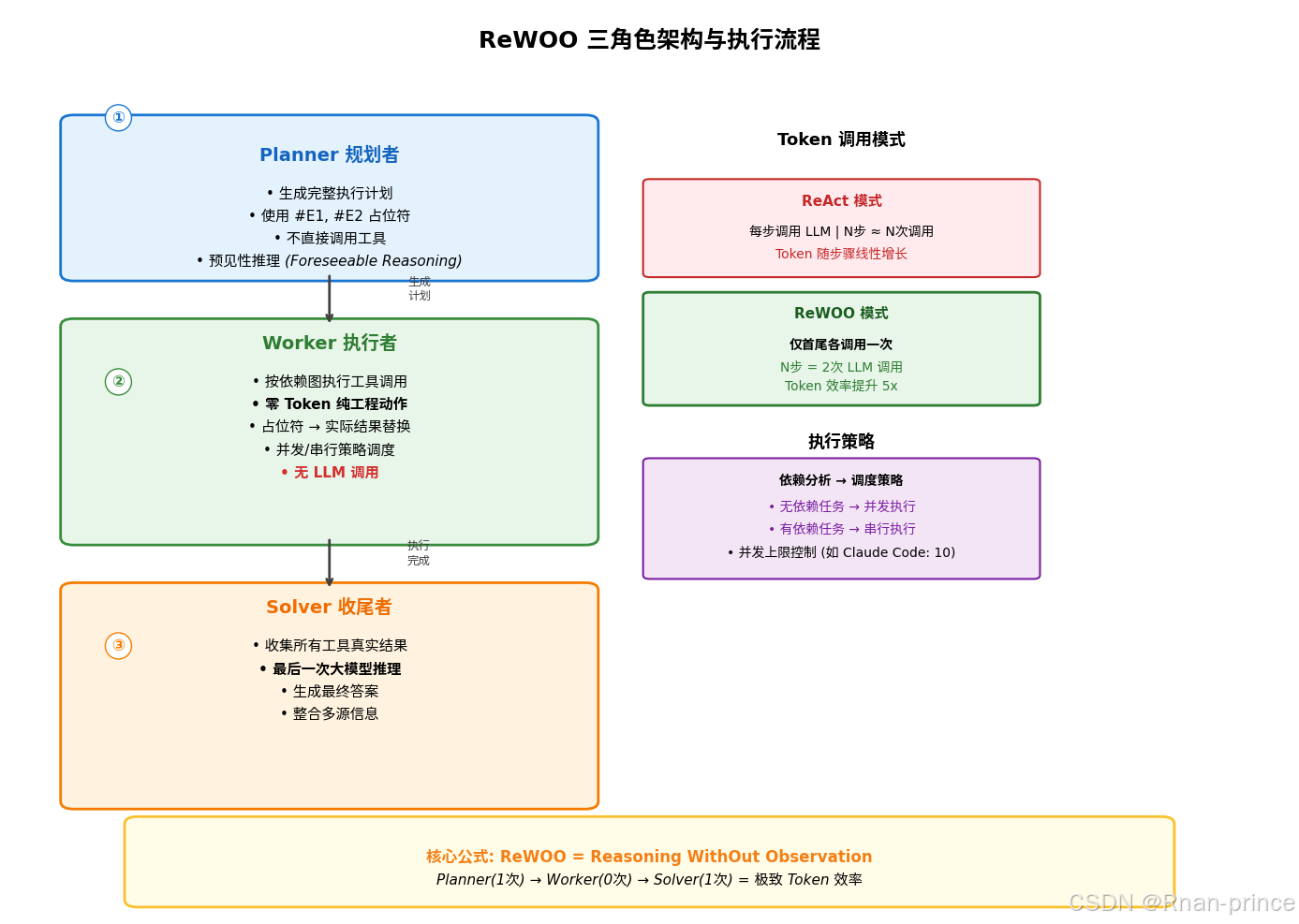
2.1 Planner 规划者:战略的制定者
核心职责:
- 预见性规划:基于用户输入,一次性生成完整的执行计划(Plan)
- 占位符系统:使用
#E1、#E2等占位符表示中间结果,而非实际值 - 零工具调用:在此阶段不直接调用任何工具,纯粹依赖 LLM 的推理能力
示例输出:
Plan: 查询北京和上海今日天气并比较温差
#E1 = Search[北京今日天气]
#E2 = Search[上海今日天气]
#E3 = Calculate[#E1.temperature - #E2.temperature]
2.2 Worker 执行者:战术的执行者
核心特征:
- 零 Token 消耗:纯工程实现,不调用 LLM
- 依赖图执行:分析任务间的依赖关系,构建执行 DAG(有向无环图)
- 占位符替换:将
#E1、#E2替换为实际工具返回结果 - 并发/串行调度:无依赖任务并行执行,有依赖任务串行处理
执行策略:
// 伪代码示意
if (tasksHaveNoDependencies()) {
executeConcurrently(tasks, maxConcurrency=10); // Claude Code 设置上限为10
} else {
executeSequentially(dependencyGraph);
}
2.3 Solver 收尾者:智慧的整合者
关键职能:
- 结果收集:汇总所有 Worker 执行后的真实结果
- 最终推理:进行最后一次 LLM 调用,整合信息生成答案
- 质量把关:处理冲突信息、填补逻辑缺口
调用公式:
Planner(1次) → Worker(0次) → Solver(1次) = 极致 Token 效率
三、执行策略:并发与依赖的智能平衡
ReWOO 的执行效率不仅来自减少 LLM 调用,更源于精细的依赖分析与调度策略。
3.1 依赖图构建
Worker 在接收 Plan 后,首先构建依赖关系图:
- 节点:单个工具调用任务
- 边:数据依赖关系(如
#E3依赖#E1和#E2)
3.2 动态调度策略
| 场景 | 策略 | 优势 |
|---|---|---|
| 无依赖任务 | 并发执行 | 最大化吞吐量,缩短 wall-clock 时间 |
| 有依赖任务 | 拓扑排序串行 | 保证数据一致性,避免竞态条件 |
| 混合场景 | 分层并行 | 独立分支并行,汇合点同步 |
这一策略与 Anthropic《Building Effective Agents》中提出的"先分析依赖,再决定并发"原则一脉相承。
四、性能对比:数据说话
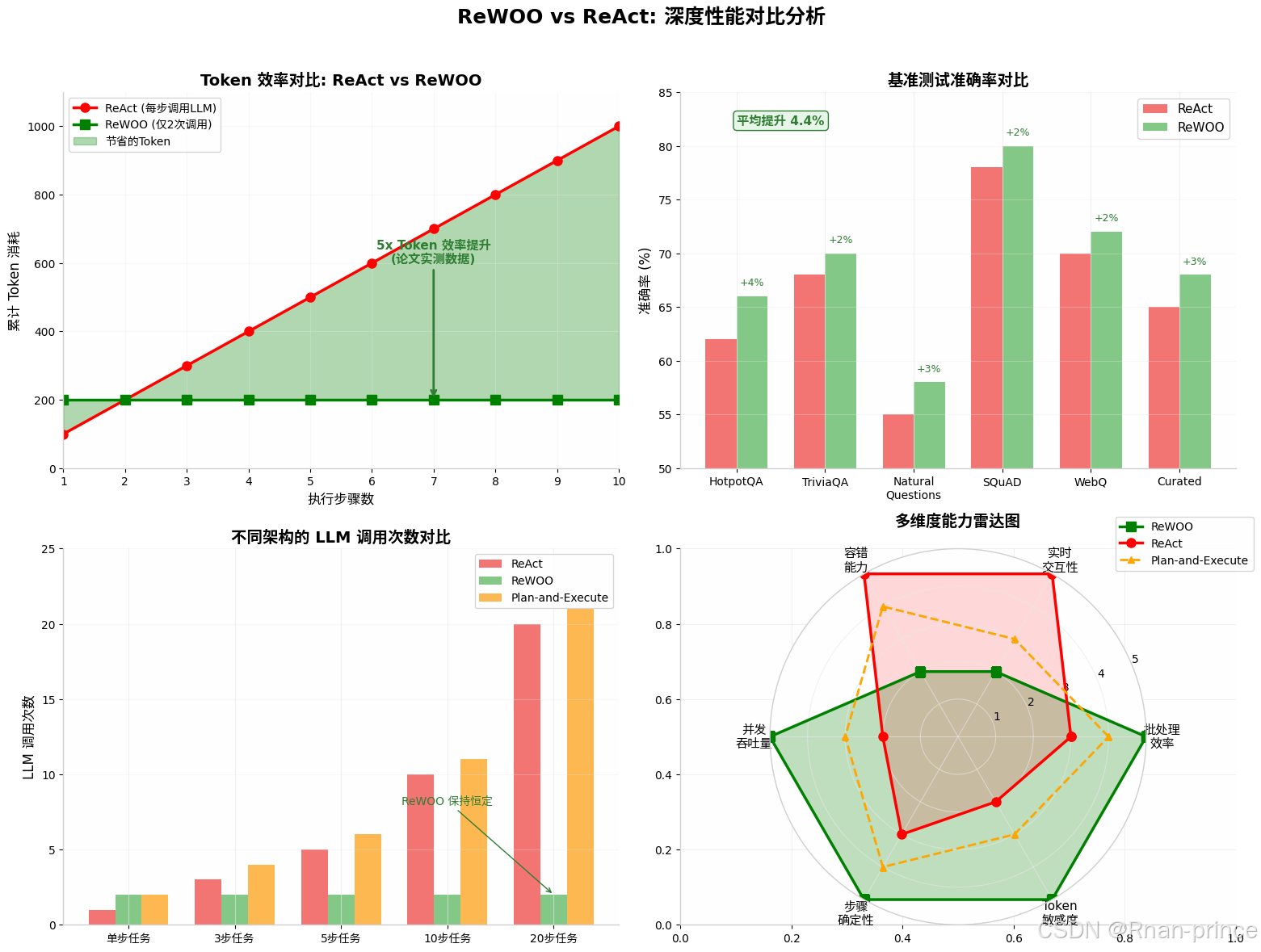
4.1 Token 效率:5 倍提升的奥秘
| 架构模式 | LLM 调用次数 | Token 增长模式 | 10步任务消耗 |
|---|---|---|---|
| ReAct | N 次 | 线性增长 O(N) | ~1000 tokens |
| ReWOO | 2 次 | 恒定 O(1) | ~200 tokens |
| Plan-and-Execute | N+1 次 | 线性增长 O(N) | ~1100 tokens |
ReWOO 的 Token 效率优势随任务步骤增加而指数级放大。
4.2 准确率:不降反升的惊喜
在六个公开 NLP 基准测试上的平均表现:
| 基准测试 | ReAct 准确率 | ReWOO 准确率 | 提升幅度 |
|---|---|---|---|
| HotpotQA | 62% | 66% | +4% |
| TriviaQA | 68% | 70% | +2% |
| Natural Questions | 55% | 58% | +3% |
| SQuAD | 78% | 80% | +2% |
| WebQ | 70% | 72% | +2% |
| Curated | 65% | 68% | +3% |
平均准确率提升 4.4%,证明解耦架构不仅节省成本,还能通过更全局的视角提升推理质量。
4.3 多维度能力雷达
从六个维度评估三种主流架构:
- ReWOO:在批处理效率、并发吞吐量、步骤确定性、Token 敏感度上满分(5/5),但在实时交互性和容错能力上较弱(2/5)
- ReAct:在实时交互性和容错能力上满分,但 Token 效率和并发能力较差
- Plan-and-Execute:折中方案,保留执行阶段的 LLM 介入能力
五、优缺点深度剖析
5.1 核心优势
✅ 极致 Token 效率:大模型调用压缩至最少(2 次),适合高并发场景
✅ 吞吐量最大化:无依赖任务并行执行,显著降低 wall-clock 时间
✅ 批处理友好:步骤清晰、依赖固定的流水线任务表现优异
✅ 准确率提升:全局规划视角减少局部最优陷阱
✅ 模型蒸馏潜力:论文展示了将 175B GPT-3.5 的推理能力蒸馏到 7B LLaMA 的可行性
5.2 固有局限
⚠️ 零容错机制:执行阶段无 LLM 介入,中途出错无法动态纠偏
⚠️ 不适合交互式场景:需要实时观测、随时调整的任务(如对话式编程助手)
⚠️ 计划僵化风险:复杂动态环境中,预设计划可能迅速失效
⚠️ 依赖预测准确性:要求 Planner 能准确预见多步结果,对模型能力要求较高
六、生产实践:Claude Code 的工程智慧
Claude Code 作为 Anthropic 官方推出的 AI 编程助手,并未完全采用理论上的"纯 ReWOO"架构,而是实现了务实的混合方案:
6.1 架构取舍
- 主循环保留 ReAct:
while true → 调模型 → runTools → 结果回流,保持交互灵活性 - 局部引入 ReWOO 思想:在
toolOrchestration.ts内部实现并发分流,而非完整三段式
6.2 智能并发控制
// toolOrchestration.ts 核心逻辑
function runTools(tools: ToolRequest[]) {
// 1. 依赖分析
const dependencyGraph = analyzeDependencies(tools);
// 2. 安全评估
const safeTools = tools.filter(t => !hasSideEffects(t));
const unsafeTools = tools.filter(t => hasSideEffects(t));
// 3. 分层执行
const safeResults = await executeConcurrently(safeTools, { maxConcurrency: 10 });
const unsafeResults = await executeSequentially(unsafeTools);
return mergeResults(safeResults, unsafeResults);
}
关键设计:
- 安全工具批量并发:读取类操作(如文件搜索、代码分析)可并行,上限 10 个
- 副作用工具串行:写入类操作(如文件修改、命令执行)必须串行
- 依赖优先:先判断依赖关系,再决定调度策略
6.3 Hook 机制增强可控性
toolHooks.ts 实现调用前后的拦截能力:
- Pre Hook:调用前检查(权限验证、参数校验)
- Post Hook:调用后处理(结果过滤、上下文补充、执行阻断)
这种设计使工具调用可控、可观测、可拦截,弥补了纯 ReWOO 缺乏灵活性的缺陷。
七、适用场景决策树
7.1 最适合 ReWOO 的场景
✅ 批处理数据流水线:ETL 任务、报表生成、批量文档处理
✅ 确定性查询任务:多源信息检索与整合(如 ReWOO 论文中的 HotpotQA)
✅ 成本敏感型应用:大规模 API 调用需要严格控制 Token 预算
✅ 步骤明确的自动化:测试套件执行、构建流程、部署流水线
7.2 不适合 ReWOO 的场景
❌ 探索性编程:需要试错、实时调试的交互式编码
❌ 动态决策任务:环境状态快速变化,需要频繁重新规划(如实时交易)
❌ 高容错要求场景:单步失败必须立即调整策略的关键任务
❌ 多轮对话式 Agent:需要保持上下文连贯的聊天机器人
八、架构选型指南
| 评估维度 | 选择 ReWOO | 选择 ReAct | 选择 Plan-and-Execute |
|---|---|---|---|
| Token 预算 | 极度受限 | 充足 | 中等 |
| 任务确定性 | 高(步骤可预见) | 低(需探索) | 中等 |
| 实时性要求 | 低(批处理) | 高(交互式) | 中等 |
| 容错需求 | 低(可重试) | 高(需即时修复) | 中等 |
| 并发潜力 | 高(无依赖任务多) | 低(步骤耦合) | 中等 |
九、未来演进方向
- 自适应混合架构:根据任务复杂度动态切换 ReWOO/ReAct 模式
- 分层规划:Planner 生成粗粒度计划,Solver 动态细化子步骤
- 工具失败恢复:在 Worker 层引入轻量级重试机制,不调用 LLM 但增强鲁棒性
- 多 Agent 协作:ReWOO 作为子 Agent 的本地优化策略,融入更大规模的 Agent 编排框架
结语:架构没有银弹,只有适合场景的取舍
ReWOO 代表了一种以效率为核心的架构哲学——通过解耦推理与观测,将 LLM 从"每一步的参与者"转变为"关键节点的决策者"。这种设计不是对 ReAct 的否定,而是对批处理场景的极致优化。
正如 Claude Code 的工程实践所示,生产级 Agent 系统往往是多种模式的融合:保留 ReAct 的交互灵活性,在工具编排层引入 ReWOO 的并发思想,通过 Hook 机制增强可控性。理解每种架构的底层 trade-off,才能在特定场景下做出最优选择。
记住:没有完美的 Agent 架构,只有适合当前任务特征、成本约束和可靠性要求的恰当选择。
参考链接:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)