
【大模型智能体】【Agent Skill综述】SoK: Agentic Skills — Beyond Tool Use in LLM Agents
SoK: Agentic Skills — Beyond Tool Use in LLM Agents
系统化知识库:智能体技能——超越大语言模型智能体的工具使用范畴
论文链接
摘要
摘要——智能体系统日益依赖可复用的程序化能力(即智能体技能)来可靠地执行长周期工作流。这些能力是可调用的模块,将程序性知识与明确的适用条件、执行策略、终止准则和可复用接口封装在一起。与一次性计划或原子化的工具调用不同,技能可跨任务运行(且通常表现良好)。本文梳理了技能在完整生命周期(发现、练习、精炼、存储、组合、评估与更新)中的层次结构,并引入两种互补的分类法。第一种是系统级的设计模式集,包含七种模式,从元数据驱动的渐进式呈现与可执行代码技能,到自进化的技能库与市场分发,概括了技能在实践中如何被封装和执行。第二种是正交的“表示形式×作用范围”分类法,描述了技能是什么(自然语言、代码、策略、混合型)及其运行的环境范畴(网络、操作系统、软件工程、机器人)。我们分析了基于技能的智能体在安全与治理方面的影响,涵盖供应链风险、通过技能载荷进行的提示注入攻击和信任分级执行机制,并以ClawHavoc攻击活动为例进行论证——该活动中近1,200个恶意技能渗透进一个主流智能体市场,大规模窃取API密钥、加密货币钱包和浏览器凭证。我们进一步综述了确定性评估方法,并援引近期基准测试证据表明:精心设计的技能可显著提升智能体成功率,而自主生成的技能可能降低其性能。最后,我们提出了面向现实世界自主智能体的鲁棒、可验证、可认证技能所面临的开放挑战。
1.引言
大语言模型(LLM)智能体已快速发展,从单轮问答系统演变为多步骤自主系统,能够浏览网页[1]、编写/调试软件[2]、[3]、按序列协调工具[4]、[5],并作为多智能体团队进行协作[6]、[7]。然而,一个根本性的低效问题依然存在:每项新任务都迫使智能体从头开始重新推导执行策略。一个已成功调试空指针异常上百次的编码智能体,在面对第一百零一次同类问题时,仍然会将其当作全新问题处理。从经验中获得的程序性知识在每一个上下文窗口结束时便不复存在。
这一观察引出了本文的核心抽象概念:智能体技能。我们将技能定义为一种可重用、可调用的模块,它封装了一系列动作或策略,使智能体能够在重复出现的条件下达成一类目标。技能与工具(具有固定接口的原子原语)、计划(一次性推理框架)和情景记忆(存储的观测结果)的不同之处在于,它同时具备可执行性、可重用性和可治理性。技能自带适用条件、终止标准和可调用接口,使其成为过程性知识的一类独立基本单元。
孤立来看,这一概念并非新鲜事物。诸如ACT-R [8] 和 Soar [9] 等认知架构早在数十年前就已将程序性记忆形式化。强化学习(RL)领域也长期研究选项框架与分层策略 [10]。真正的创新在于这些思想在LLM智能体中的汇聚 [11], [12]。技能的表现形式多样,涵盖自然语言操作规程、可执行的Python脚本乃至通过市场分发的插件。这种表征的多样性要求系统化的梳理。现有的综述或广泛涵盖LLM智能体 [13], [14], [15], [16], [17], [18], [19],或聚焦于工具使用 [20], [21], [22],或关注多智能体协作 [23]。尚无以技能为核心视角,追踪其从获取到治理全生命周期的研究。本文旨在填补这一空白。
贡献。本知识系统化研究提供六项贡献:
• 统一的智能体技能定义(§2),形式化为 S = (C, π, T, R),并明确了区分技能与工具、计划和记忆的精确边界条件。
• 技能生命周期模型(§4),描绘从发现、评估到更新的各阶段,并总结代表性系统与生命周期阶段的对应关系。
• 七模式设计分类法(§5),阐述实际系统中技能的封装、加载与执行方式。
• 正交的表示法 × 作用域分类法(§5.10),描述技能的本质及其作用的环境,并与七种模式相结合。
• 安全与治理分析(§7),涵盖威胁模型、信任层级、模式特定的风险矩阵,以及针对ClawHavoc市场供应链攻击的锚定案例研究。
• 评估框架(§8),包含度量标准、基准测试映射,以及一项锚定案例研究,证明经筛选的技能优于自我生成的技能。
阅读导图。§2 定义核心抽象概念。§3 阐述我们的系统化方法论。§4 介绍生命周期模型。§5 提出七种设计模式及表征×范畴分类法。§6 涵盖技能获取与组合。§7 分析安全与治理,包括ClawHavoc案例研究。§8 综述评估方法。§9 讨论交叉性观察与局限性。§10 概述开放挑战。§11 总结我们的工作。
2. 何为智能体技能?
2.1. 形式化定义
我们将能动技能的概念建立在四元组形式化基础上,该形式化捕捉了区分技能与相关抽象概念的本质属性。
上下文 定义1(具身智能体技能)上下文
设智能体通过动作空间A、观察空间O与目标空间G与环境E进行交互。令 H = ( o 1 , a 1 , . . . , o t − 1 , a t − 1 ) H = (o_1, a_1, . . . , o_{t−1}, a_{t−1}) H=(o1,a1,...,ot−1,at−1)表示截至当前步骤的交互历史。一个具身智能体技能是一个元组
S = ( C , π , T , R ) S=(C,\pi,T,R) S=(C,π,T,R)
其中:
- 上下文 适用条件上下文 C : O × G → { 0 , 1 } C: O \times G \to \{0, 1\} C:O×G→{0,1} 为一个谓词,基于观察与智能体当前目标判断该技能是否适用于当前上下文 ;
- 上下文 可执行策略上下文 π : O × H → A ∪ Σ \pi: O \times H \to A \cup \Sigma π:O×H→A∪Σ 为从观察与交互历史到动作或技能库 Σ \Sigma Σ 中技能调用的映射,可通过自然语言指令、可执行代码、学习型控制器或其混合形式实现。当 π \pi π 选择技能 s ∈ Σ s \in \Sigma s∈Σ 而非原始动作 a ∈ A a \in A a∈A 时,将产生层次化组合(§6.6.1),这对应强化学习选项框架中的选项-子程序结构[10];
- 上下文 终止条件上下文 T : O × H × G → { 0 , 1 } T: O \times H \times G \to \{0, 1\} T:O×H×G→{0,1} 规定技能相对于当前目标的完成状态(成功或失败);
- 上下文 可复用调用接口上下文 R = ( 名称 , 参数 , 返回类型 ) R = (\text{名称}, \text{参数}, \text{返回类型}) R=(名称,参数,返回类型) 为元数据与契约组件,定义了可供智能体、其他技能或外部编排器通过编程调用的技能签名(名称、参数模式、返回类型)。
G 可被编码于 O 内(例如作为观测中的任务提示),也可作为显式参数传递;为清晰起见,此处我们将其显式化。实现中通常计算软适用性分数 C : O × G → [0, 1] 并应用阈值;我们以二值形式呈现,作为一种捕捉核心门控逻辑的简化约定。在协调器管理的架构中,C 和 T 可由外部提供而非技能内部实现;此时该四元组描述的是逻辑接口,与各功能的具体实现位置无关。
我们认为这四个组成部分构成了一个有效的精简范式,能够捕捉技能区别于相关抽象概念的特性。移除C将产生无法自主决策的策略;移除T将形成无法组合的策略(调用者不知何时恢复执行)。R产生了无法通过编程调用的内部知识;移除π则使得元数据失去可执行性。该形式化过程刻意保持了表征无关性:π可以是提示模板、Python函数、强化学习策略,或是其组合形式。
这种形式化与Sutton等人[10]提出的选项框架(I, π, β)相呼应,其中我们的C对应启动集I,T对应终止条件β。接口R在选项框架基础上进行扩展,使技能能够被显式调用,这对于运行时组合是必需的。而强化学习选项则由元策略隐式选择,因此无法满足这一需求。图1展示了由此产生的四组件架构。
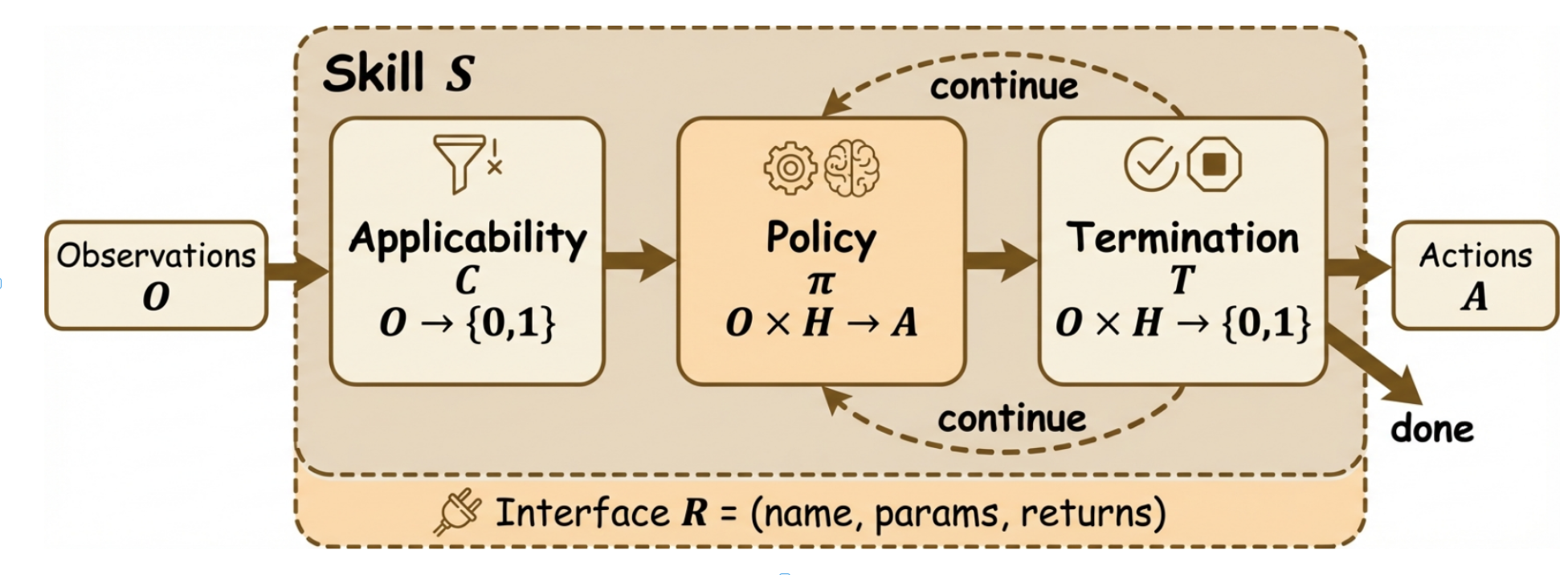
图1. 智能体技能的内部解剖结构。观测O进入适用性门控C;策略π生成动作A;终止条件T决定继续执行或停止。接口R将整个模块封装为可调用的API边界。目标G通常编码在观测O中或作为独立任务参数传递;为视觉简洁性,图中将O显示为单一输入。
2.2. 技能与相关抽象概念
我们将智能体技能与四个相关概念进行比较(表1):复用单元、执行语义、验证层面、可组合性与治理层面。
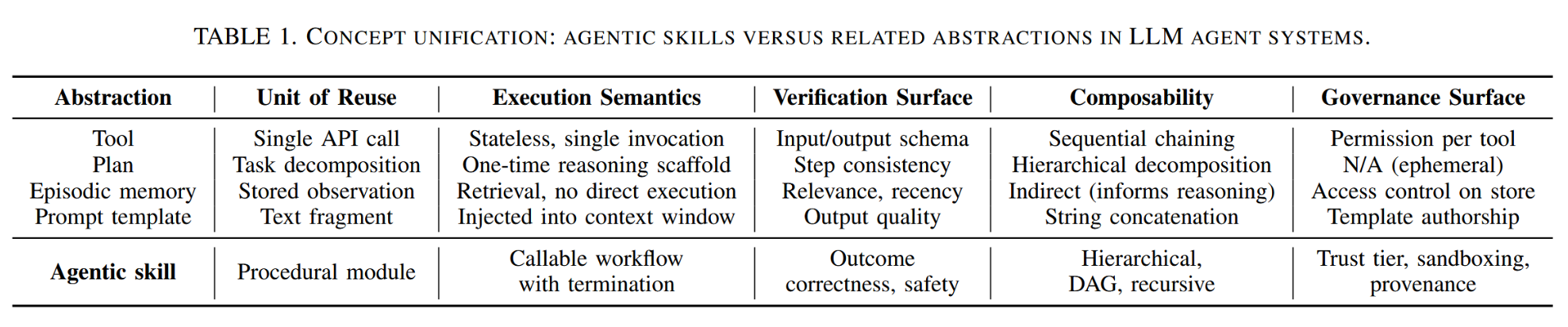
表1:概念统一——LLM智能体系统中智能体技能与相关抽象概念的对比。
工具。工具是一种原子级原语(例如网络搜索API或文件写入函数),其接口固定且不具备内部决策能力。先前的研究如Toolformer[22]表明,大语言模型能够自主学习调用工具,但此类行为通常局限于单一调用层面。技能可以调用工具,但通过适用性逻辑、多步骤序列化和明确的终止标准对工具进行了扩展。从概念上看,这种区别类似于软件工程中系统调用与库例程之间的差异。
计划。计划是智能体为将任务分解为子目标而生成的推理产物。计划通常具有一次性、会话范围限定等特性,且未经进一步解释无法直接执行。相比之下,技能可跨会话持久存在,具备可执行策略,并对外提供可调用接口。计划可选择调用技能,但技能本身并非计划。
记忆。情景记忆与语义记忆系统储存可后续提取的观察结果与事实[24]、[25]、[26]。技能是程序性记忆的一种形式:它们编码的是如何行动,而非发生了何事。LLM智能体中陈述性记忆与程序性技能的关系,呼应了认知心理学中关于“知道是何”(knowing-that)与“知道如何”(knowing-how)的区分[8]。
提示词模板。提示词模板是注入上下文窗口的静态文本片段[27]。它们不具备适用条件、终止逻辑或可调用接口。一项技能可能包含提示词模板作为其策略π的组成部分,但仅凭模板本身并不构成一项技能。
经典AI规划形式化方法。技能抽象也与经典AI规划相关联。在分层任务网络(HTN)[28]中,方法通过前置条件将任务分解为子任务,这与我们的分层组合结构相呼应(§6.6.1)。BDI(信念-期望-意图)架构[29]使用具有上下文条件的可重用规划方案,这对应于我们的条件C与策略π。STRIPS/PDDL动作[30]明确规定了前置条件与效果,这预见了我们的适用性条件与终止条件。主要区别在于表示形式:基于LLM的技能作用于自然语言观察,并可将策略编码为自然语言指令或混合产物,而经典形式化方法假设符号化状态。我们保持形式化与表示方式无关,以衔接这些研究方向。
2.3. 作为程序性记忆的技能
认知科学为理解技能重要性提供了一个有益的视角。安德森的ACT-R理论[8]区分了陈述性记忆(事实与事件)与程序性记忆(编码条件-行动对的生产规则)。专家与新手的差异,主要不在于其知识储备,而在于其程序性知识库的丰富程度:当条件满足时,能自动触发的行动模式,从而将工作记忆释放出来以进行更高层次的推理。
LLM智能体面临类似的挑战。若无技能层,每项任务都需代理在有限上下文窗口内从第一性原理进行推理,消耗大量令牌以重新推导本可存储并调用的流程。技能作为智能体的程序性记忆,将习得流程压缩为可复用模块,从而减轻模型上下文窗口的认知负荷——这类似于人类专业技能中的组块化将多步骤程序压缩为单一可检索单元的过程[31]。
这种框架具有一个实际含义:技能的价值不仅在于便利性,更在于可靠性。经过多场景验证的规范化技能比临时生成的即兴方案更可靠,正如经过测试的库函数比内联代码更可靠。最近的实证证据支持了这一观点:SkillsBench基准测试[32]表明,规范化技能平均将智能体通过率提升16.2个百分点,而自主生成的技能会使性能下降1.3个百分点,因其编码了错误或过于特定的启发式规则。值得注意的是,配备规范化技能的较小模型可以超越未使用此类技能的较大模型。一种解释是,程序性记忆充当了效率倍增器,并能在一定程度上替代模型规模。
3.方法
本节阐述了用于收集和分析LLM智能体系统中智能体技能文献的系统化流程,以及我们构建分类体系的方法论。
3.1. 文献检索与筛选
我们在六大数据库中进行了结构化检索:Google Scholar、Semantic Scholar、DBLP、ACM数字图书馆、IEEE Xplore和arXiv。我们使用了关键词查询(包括智能体技能、技能学习大语言模型、可复用智能体行为、程序性知识智能体、工具组合大语言模型、智能体库、分层智能体策略),并基于种子论文(Voyager [33]、ReAct [34]、Reflexion [35]、SWE-agent [2])进行了前向与后向引文追溯。
本次检索覆盖了2020年1月至2025年2月期间关于LLM智能体系统的文献。我们收录了一项特例——2026年2月发表的并行研究SkillsBench [32],因其与技能评估直接相关;其他主要文献均位于所述时间范围内。为将技能抽象建立在成熟理论基础上,认知科学[8]、[31]、认知架构[9]及强化学习[10]等领域的基础性文献不受发表时间限制,均予收录。
纳入标准。一篇论文若满足以下至少一项条件即被纳入:(i) 介绍、实现或评估基于大语言模型或语言条件智能体的可复用程序能力;(ii) 涉及智能体程序知识至少一个生命周期阶段(发现、精炼、提纯、存储、检索、执行或评估);或(iii) 提供一个可测量智能体技能的基准环境。
排除标准。我们排除了仅关注无流程组合的单次工具调用、无技能持久化或复用的纯提示工程,以及未涉及技能抽象的多智能体协调研究。同时,我们也排除了仅专注于指令跟随微调而未包含明确技能表征的论文。
3.2. 语料库与分析
初步检索共获得约180篇候选文献。经纳入与排除标准筛选后,我们保留65篇文献进行详细分析。其中,24个系统通过映射表(表2和表5)进行了深入分析,其余文献则为生命周期阶段、设计模式、安全性与评估等方面的分析提供了依据。该文献集涵盖八个基准环境、七种设计模式及五种表征类别。
3.3. 分类法开发
两种分类体系均通过自下而上的迭代过程构建。我们首先为每个分析系统编制了特征矩阵,记录其技能表示、获取方法、执行模型、存储机制与治理特征。该矩阵中反复出现的聚类催生了七种设计模式(§5)和五种表示类别(§5.10.1)。
我们对每个候选分类法进行了全语料库测试,通过三轮修订循环不断完善分类体系,直至每个经过深度分析的系统都能被自然归类。表征×范畴分类法的构建采用了正交方法:范畴类别源自被分析系统所处理的环境类型。通过验证结果矩阵中多数单元格均存在对应实例,我们确认了范畴与表征维度之间的正交性。
设计模式在设定上具有非排他性:实际系统常融合多种模式(例如采用元数据驱动加载、结合自然语言与代码混合实现的集市式分布式插件系统)。我们将可组合性视为模式框架的特性而非分类缺陷,因为若采用互斥性模式,将无法真实反映实践中技能部署的实际样态。
4.技能生命周期模型
我们围绕一个生命周期模型来梳理相关文献,该模型追踪自主智能技能从初步形成到最终退役的全过程。该模型不将技能视为静态产物,而是将其理解为通过交互、反馈和部署约束不断演化的系统组件。该生命周期包含七个阶段(如图2所示):
• 发现:识别反复出现的任务模式、故障类型或工作流瓶颈,从而确定将特定行为封装为可复用技能的合理性。
• 练习/优化:通过试错执行、反思与外部反馈迭代改进候选技能,使策略和提示在重复使用中趋于稳定。
• 提炼:从执行轨迹或示范中提取稳定且可泛化的流程,将其与描述性元数据、使用约束共同封装为(C, π, T, R)四元组形式。
• 存储:将技能持久保存在技能库或存储库中,辅以索引、版本管理与元数据,以支持高效检索与治理。
• 检索/组合:在运行时选择相关技能并将其组合为更高层级的工作流,通常需进行接口、上下文及依赖关系的兼容性校验。
• 执行:在沙盒隔离、权限控制与资源约束下,于智能体行动循环中运行技能策略,以限定潜在副作用。
• 评估/更新:监测部署后的性能表现,检测偏移或故障,并随环境与需求变化对技能进行修订、替换或退役处理。
生命周期并非严格线性。反馈回路将评估与实践相连(当技能表现不佳时)、检索与存储相连(当索引无法呈现相关技能时)、执行与发现相连(当运行时故障揭示新技能需求时)。表2展示了代表性系统对生命周期各阶段的贡献映射。
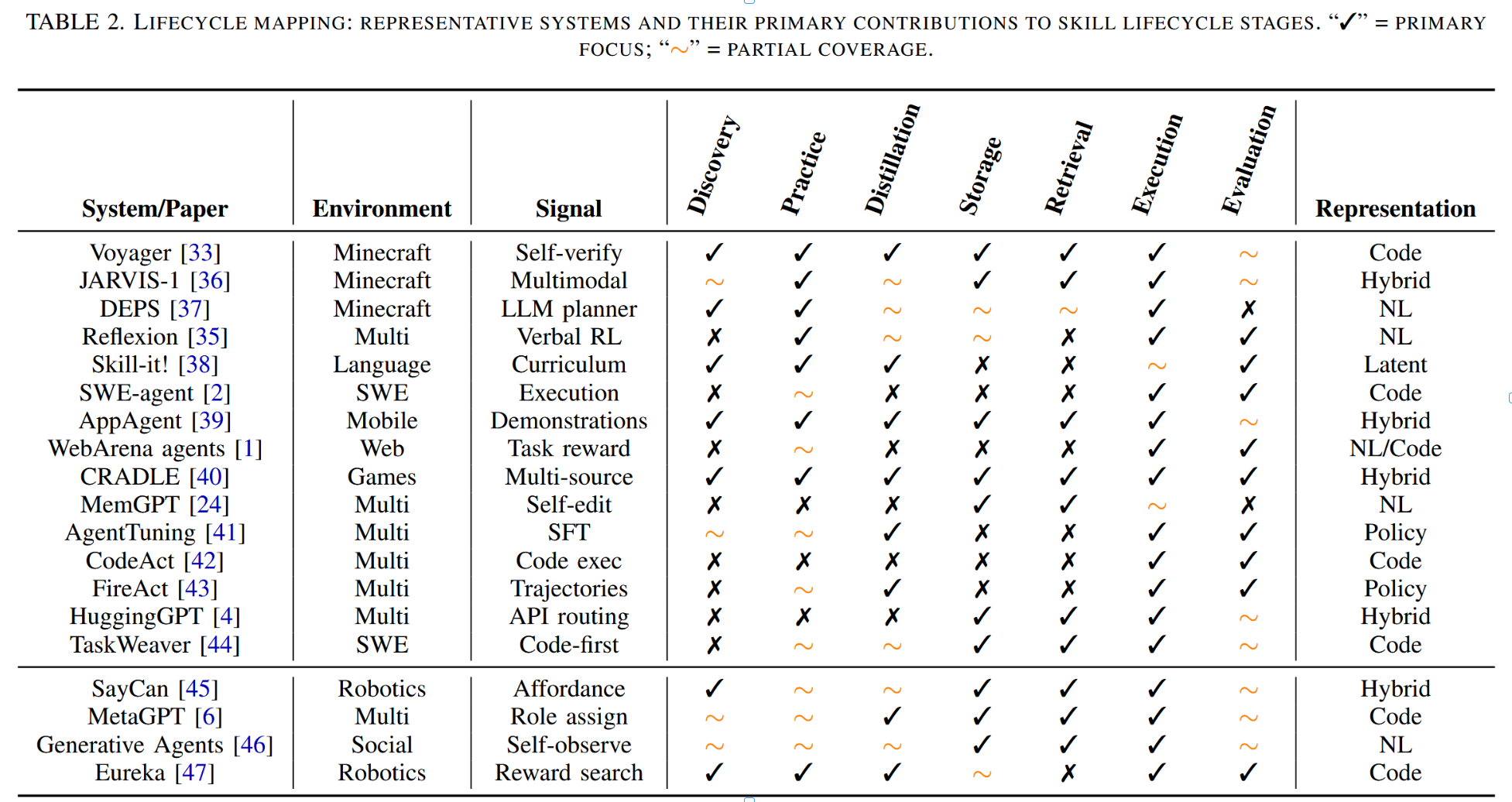
表2. 生命周期映射:代表性系统及其对技能生命周期各阶段的主要贡献。“✓”=主要关注;“∼”=部分覆盖。
4.1. 发现
技能发现是识别重复出现且值得封装为可复用模块的任务模式的过程。在Voyager[33]中,该发现过程由课程机制驱动:该机制会持续提出复杂度递增的《我的世界》游戏任务;当智能体成功完成新任务时,解决方案轨迹成为候选技能。DEPS[37]通过计划分解发现技能:高层次规划器识别子目标,重复出现的子目标模式被提升为技能。AppAgent[39]通过用户在移动界面上的演示发现技能,识别跨应用程序的可复用交互模式。
在机器人学领域,SayCan [45] 通过将语言指令与机器人可供性进行关联来发现可执行技能:该系统通过语言相关性和物理可行性对候选技能进行评分,从而有效识别特定情境下适用的技能。DECKARD [48] 则利用语言引导的世界模型,通过具身决策来发现技能,在执行前对行动方案进行推演想象。
一个关键的开放性问题是无监督发现:即在没有人类提供任务定义或明确成功信号的情况下识别技能边界。现有系统要么依赖预定义的任务课程,要么通过人类演示来启动发现过程。
4.2. 实践、优化与提炼
一旦某项候选技能被识别,就必须将其完善为可靠的执行流程。Reflexion [35] 展示了一种语言强化的学习循环:智能体对失败尝试进行反思,生成文本反馈以指导后续试验。这种反思机制作为一种实践循环,无需更新参数即可提升技能的可靠性。
蒸馏将原始行为轨迹转化为紧凑且可泛化的技能表征。AgentTuning [41] 通过监督式微调将来自GPT-4的行为轨迹提炼至更小模型中,从而生成具备内化技能的智能体。FireAct [43] 则在多样化的ReAct式行为轨迹上对智能体进行微调,将多步推理模式蒸馏至模型权重中。
内在独白[49]通过基于语言的场景描述与成功信号,为具身智能体提供语言反馈,从而迭代优化机器人动作序列。Eureka[47]研究表明,大型语言模型能够通过进化搜索自主设计机器人技能习得的奖励函数,实现人类水平的表现,有效自动化物理技能"实践-优化"的循环过程。
实践与提炼之间的区别至关重要:实践通过反复操作提升技能的可靠性,而提炼则改变其表现形式(例如,从冗长的操作轨迹变为紧凑的代码函数,或从基于提示的指令变为模型权重)。
4.3. 存储与检索
技能存储需要支持高效检索的索引机制。Voyager [33] 维护了一个通过自然语言描述建立索引的技能库,利用嵌入相似性为新任务检索相关技能。CRADLE [40] 对此进行了扩展,采用多级记忆结构,将技能与情境上下文共同存储,从而能够根据任务相似性和环境状态进行检索。
存储-检索接口是技能系统与记忆架构的交汇点。MemGPT[24]提供的分级记忆系统可作为技能库的基础设施,其主内存(上下文窗口)与归档存储(外部数据库)支持不同的访问模式。生成式智能体[46]为模拟社会智能体实现了一套记忆架构,其中类似社交技能的行为模式会基于时效性、重要性和相关性进行存储与检索,这为技能库如何与更广泛的记忆系统整合提供了模型。核心挑战在于设计能平衡精度(返回最适用的技能)与召回率(在新颖情境中不遗漏相关技能)的检索策略。
4.4. 执行与评估
执行是技能策略π在智能体行动循环中被实施的阶段。执行模型因技能表征方式而异:自然语言技能被注入上下文窗口,代码技能在沙盒环境中运行,而策略技能则通过学习得到的参数进行操作。CodeAct [42] 表明,将智能体行动表征为可执行的Python代码(而非工具调用的JSON格式),能同时提升技能执行的表达力与可验证性。
评估旨在检验某项技能是否能够稳定实现其预期结果。为实现可扩展性,采用确定性评估方法——即利用环境本身提供真实值验证——优于人工评分。SkillsBench [32] 将这一原则具体化:其为全部86项任务中的每一项均配备了确定性验证器,通过对比环境状态与预期结果进行检查,从而在7,308条智能体轨迹上实现了可复现的评估。我们将在§8节深入探讨评估相关议题。
5.设计模式与分类学
我们将新兴技能版图从两个互补维度进行分类。首先,我们识别出七种设计模式,用以描述技能在系统层面如何被封装、加载和执行。其次,我们构建了一个"表征×范围"分类法(§5.10),用以阐述技能的本质及其运作场域。图3将这七种模式沿自主性轴线进行排列。本节将依次阐述这两个维度,首先从表3所总结的设计模式开始。
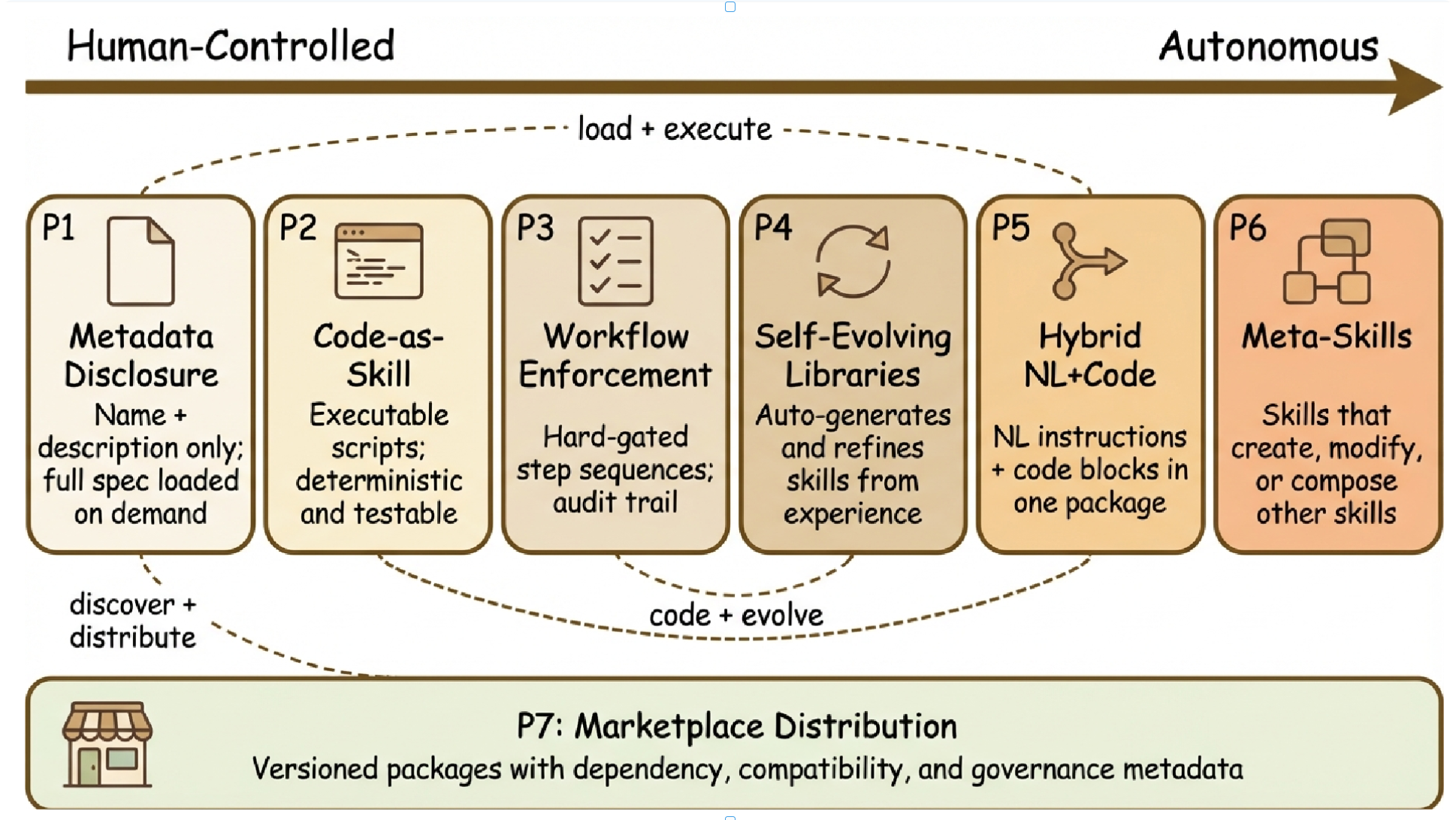
图3. 沿自主性谱系排列的七种智能体技能设计模式,涵盖从人类控制的元数据披露(P1)到完全自主的元技能(P6)。市场分布(P7)作为一种跨领域分布机制,贯穿整个谱系。虚线表示常被组合使用的模式。
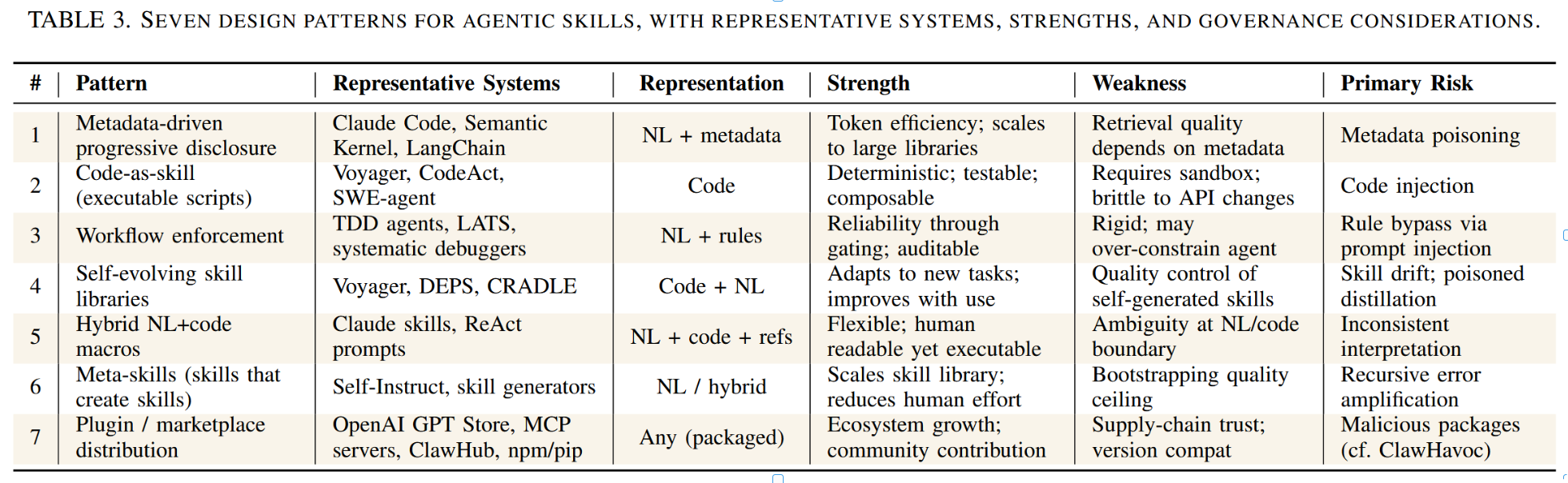
表3. 面向智能体技能的七种设计模式,及其代表性系统、优势与治理考量。
5.1. 为何使用设计模式?
长期以来,软件工程领域一直认为记录反复出现的设计模式对实践和研究都具有重要价值[50]。我们将这一方法沿用于智能体技能的研究。设计模式描述的是在不同系统中反复出现的解决方案形态。本文中的模式属于系统层级:它们描述基础设施如何管理技能。相比之下,表征/范围分类法则属于技能层级。二者互为补充:一种模式(例如,市场分发模式)可以承载具备任何表征形式和适用范围的技能。
5.2. 模式一:元数据驱动式披露
在模式一中,技能通过紧凑的元数据摘要(名称、描述、触发条件)被发现占用最小上下文。完整指令仅在技能被选中执行时,才加载至智能体的上下文窗口中。这种两阶段加载策略解决了大型语言模型智能体的一个根本性约束:有限的上下文窗口无法同时容纳所有可用技能。
Claude Code的技能系统是这一模式的典型代表。每个技能都通过简短描述和一组触发短语进行注册。当智能体判定某项技能与当前任务相关时,便会加载完整的技能规范——其中可能包含多页说明、参考文档和执行脚本。Semantic Kernel框架[51]通过其插件发现机制实现了类似方案:系统先注册函数元数据,仅在选定后才调用完整的函数实现。
核心优势在于规模:一个智能体可掌握数百种技能,却仅需为少数激活的技能消耗上下文标记。主要风险在于元数据质量:若技能描述存在错误或不完整,检索过程可能选择错误技能或遗漏相关技能。
5.3. 模式二:代码即技能(可执行脚本)
代码即技能将技能表示为可执行程序(Python函数、Shell脚本或领域特定语言程序),智能体通过运行时接口调用这些程序。Voyager [33] 为《我的世界》生成JavaScript函数作为技能,将其存储在技能库中,并通过自然语言描述进行检索。CodeAct [42] 的研究表明,将智能体行为框架定义为可执行的Python代码(而非结构化的JSON工具调用),能够实现更具表现力且可验证的行为。在机器人领域,Code as Policies [52] 生成用于机器人控制的Python程序,ProgPrompt [53] 则创建可执行程序形式的情境任务规划,二者均将生成的代码视为可复用的物理操作技能。
代码技能的关键优势在于确定性:在相同输入条件下,代码技能将产生相同输出,这使得传统软件测试与验证成为可能。代码技能同样由函数调用、导入操作和控制流构成。其局限性在于脆弱性:当底层API、UI元素或环境条件发生变化时,代码技能会发生断裂,需要进行维护和版本管理(§4.4)。
5.4. 模式三:工作流强制执行
工作流强制技能对智能体的行为施加硬性门控流程,确保智能体遵循预设方法而非即兴发挥。以测试驱动开发(TDD)技能为例,它强制要求智能体在实现功能前编写测试,运行测试套件,并循环迭代直至所有测试通过。智能体不能跳过或重新排列这些步骤。
LATS(语言代理树搜索)[54] 采用树搜索工作流,将规划、执行与反思整合于结构化循环中。其系统化调试能力强制实行“先诊断后修复”方法,要求代理必须复现错误、定位根本原因并在宣告成功前验证修复的有效性。
该模式以牺牲灵活性为代价换取可靠性。通过将智能体的行动空间约束于已验证的序列,工作流强制执行降低了由幻觉驱动走捷径的概率,并提供了清晰的审计轨迹。需注意模式三在控制器层面运作:它规定智能体的执行方式,其本身并非可复用的技能构件。LATS(分层思维序列)正是可承载其他模式技能的工作流控制器范例。治理界面即规则集本身:若攻击者能够修改工作流规则(例如通过提示注入),则执行机制即被破坏。
5.5. 模式四:自演进技能库
自演化技能库将技能执行与自动化质量评估及库维护相结合。每次任务结束后,系统会评估智能体的行为是否产生了成功的轨迹,值得提取为新技能或用于优化现有技能。
Voyager[33]提供了一个典型示例:它生成基于代码的技能,通过游戏内执行进行验证,并将已验证技能整合到按自然语言描述索引的持久化库中。CRADLE[40]通过显式记忆管理扩展了此范式,将技能与情景语境关联,从而实现基于环境相似度的检索。
自演进库的核心矛盾在于质量控制。SkillsBench基准测试[32]显示,自生成技能相较于无技能基线的平均表现差值为-1.3个百分点,五种测试配置中仅有一种显示出改进。这表明在开放场景中,未经迭代验证的零样本自生成可能降低系统性能。这一现象与Voyager和Eureka形成对比——在后者中,自生成技能能在具备确定性执行验证的受限环境中取得成功。这意味着自生成技术的可行性高度依赖于领域特异性及自动化验证机制的存在。若缺乏人工监督或强健的验证机制,自演进库可能积累类似软件系统中“技术债”的“技能债”。
5.6. 模式五:混合自然语言+代码宏
混合技能将自然语言规约与可执行组件结合于单一包中。自然语言组件以人类可读的形式描述技能的目的、适用条件及高层逻辑,而可执行组件则提供实现具体步骤的代码片段、参考文档或工具调用序列。
这种模式常见于生产级智能体系统,其技能必须同时具备人类可审查性和机器可执行性。例如Claude Code的技能系统将技能定义为包含自然语言指令、代码块和外部资产引用的Markdown文档。ReAct范式[34]则代表了一种轻量级实现:智能体在自然语言推理(“我需要搜索X”)与可执行动作(搜索API调用)之间交替进行,这种交错过程本身就构成了一种隐式的混合技能。
混合技能的优势在于灵活性:自然语言组件通过推理提供上下文并处理边缘情况,而代码组件则为明确步骤提供确定性。其风险在于边界模糊:当指令与代码冲突时,智能体必须决定遵循何种规则,这可能导致行为不一致。
5.7. 模式六:元技能
元技能是一种旨在创造、修改或组合其他技能的技能。元技能可以通过分析智能体的任务历史来识别重复出现的模式,基于这些模式生成候选技能,并在预留任务上对其进行测试。从这个视角来看,Self-Instruct [55] 可被视为此类方法:大语言模型生成新的指令遵循示例,这些示例作为技能习得的训练数据。CREATOR [56] 更进一步,使大语言模型能够按需创建新工具(即代码函数),从而将抽象推理与具体工具实现分离开来。Eureka [47] 生成奖励函数作为机器人技能的参数化形式,通过代码高效地创建技能规范。
我们将 Self-Instruct 和 CREATOR 视为先驱方法:它们体现了训练时元技能的理念,但主要是离线方式。我们严格意义上的 Pattern-6 专指那些可作为运行时可调用生成器的方法。发现(§4.1)明确了流程间隙;元技能正是填补这一间隙的生成机制。两者处于不同层次(生命周期阶段 vs. 设计模式):元技能将原本需手动完成的过程自动化。
元技能能让一个核心技能集无需相应比例的人力投入即可发展成庞大的技能库。其风险在于递归性错误放大:若元技能产生有缺陷的技能,而该技能随后又被用作进一步生成技能的输入,错误便会逐级累积。因此,在每一代生成步骤中设置质量关卡至关重要(参见第7节)。
5.8. 模式七:插件/应用市场分发模式
市场模式将技能视为带有明确依赖、兼容性和治理元数据的版本化可分发包。OpenAI的GPT商店分发自定义GPT配置,其功能等同于打包技能。Anthropic的模型上下文协议(MCP)[57]定义了一个用于工具和技能服务器的标准化接口,支持第三方技能在身份验证和权限边界内进行分发。ToolLLM[58]展示了与超过16,000个真实世界API的集成,例证了市场式分发所能实现的规模。
最具代表性的市场级技能分发案例是OpenClaw [59],这是一个建立在四工具核心(读取、写入、编辑、bash)之上的智能体框架,它将技能视为首要的可扩展机制。OpenClaw的社区技能注册中心ClawHub,在上线数周内已发布的技能数量从零增长至超过10,700个,而该项目本身在GitHub上获得超过20万个星标的速度,也超越了历史上任何软件代码库[60]。OpenClaw的设计理念与我们的分类体系尤其相关:它倡导自我生成技能(模式4 + 模式6),鼓励智能体通过编写代码来自我扩展,而非下载预构建的扩展模块。当与社区分发机制(模式7)结合时,双源技能库:人工编写的社群技能与智能体编写的本地技能并存,两者皆可在拥有完整系统权限的条件下执行。
在软件生态系统中,类似的模式包括JavaScript的npm包、Python的pip包以及集成开发环境的插件系统。这种市场模式实现了社区驱动的规模化技能创建,但引入了供应链风险:一个恶意或被入侵的技能包可以在智能体权限范围内执行任意操作。OpenClaw的爆炸性增长及其随后发生的安全事件严重性(§7.6)为此风险提供了鲜明例证。我们将在§7中详细分析这些风险。
5.9. 模式权衡
我们的模式代表了多维权衡空间中的不同点位。表4总结了关键维度:上下文成本衡量模式在活跃使用时消耗的令牌数量;确定性反映执行结果的预测性;可组合性体现遵循该模式的技能如何被便捷地整合到更大型工作流中;治理面表示模式是否便于审计、权限控制和溯源追踪。
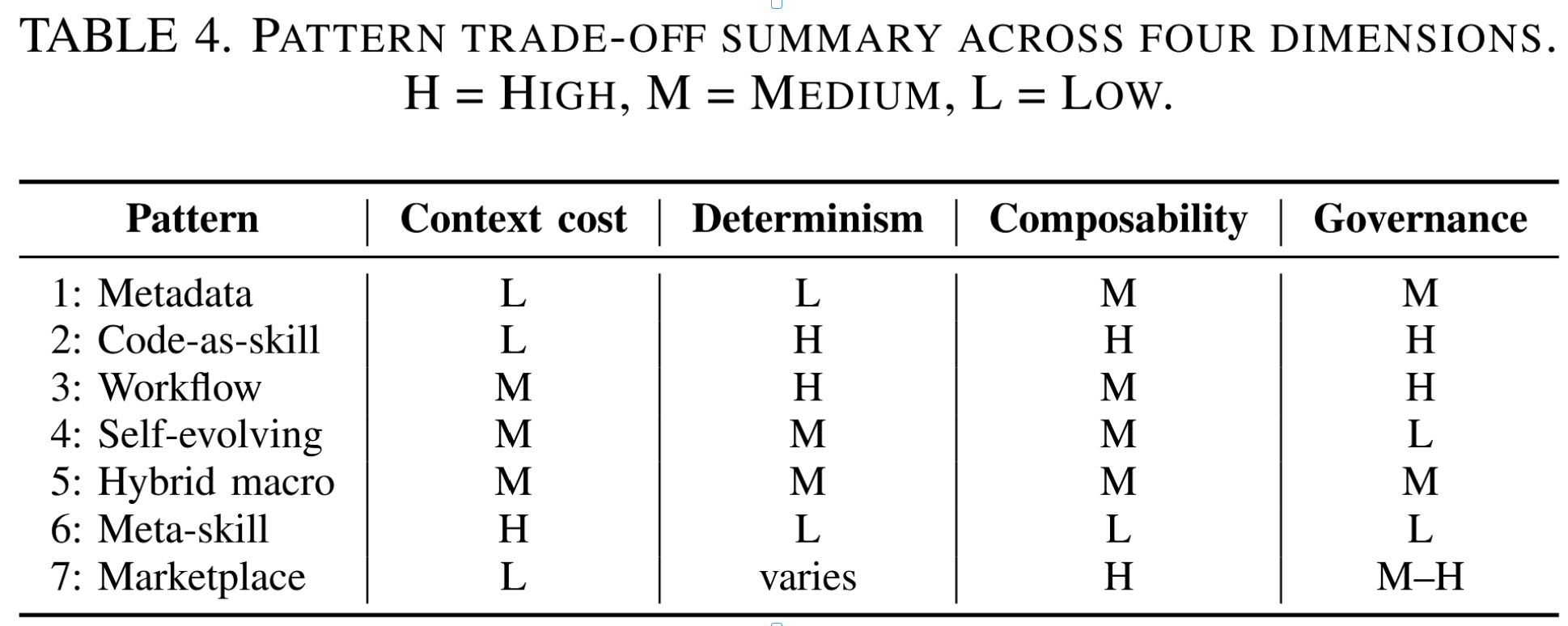
表4. 四维度模式权衡总结。H=高,M=中,L=低。
模式共现性。我们语料库中的系统中位使用2种模式(范围:1–4)。最常见的组合是模式1+7(元数据+市场),出现在4个系统中(HuggingGPT、MetaGPT、AutoGen、ToolLLM)。两个系统(Claude Code和OpenClaw)使用了4种模式,属于异常值。五个系统使用单一模式,十二个系统恰好使用两种。适中的共现率表明这些模式捕捉到了有显著差异的架构选择,而非坍缩为单一集群。
不存在单一的主导模式。生产系统通常结合多种模式:一个市场分布式插件(模式-7)可能采用元数据驱动加载(模式-1),结合混合自然语言+代码实现(模式-5),并对关键步骤实施工作流强制执行(模式-3)。
计算开销。技能层会带来额外开销:检索增加延迟,指令加载消耗上下文令牌,而多层组合则会使这两项成本倍增。表4将其抽象为“上下文成本”,但在不同部署场景中,量化基于技能的智能体与无技能智能体在延迟与准确性之间的权衡关系,仍是一个有待实证研究的开放性问题。
5.10. 表征 × 范围分类法
在系统级设计模式之外,我们提出了一种基于两个正交维度的内在分类法:表征(技能策略的编码方式)与范畴(技能所适用的环境或任务领域)。模式描述基础设施如何管理技能,而此分类法则在技能层级发挥作用。
5.10.1. 表征轴
我们识别出五种表征类别,大致按形式化程度递增的顺序排列:
自然语言技能。策略π完全以自然语言表述:包括分步指导、标准操作程序或手册条目。智能体通过其语言理解能力解析这些指令。自然语言技能易于编写与审查,但存在解释歧义,且无法通过传统测试进行验证。
代码即技能。策略π是一个可执行程序:可以是Python函数、Shell脚本、领域特定语言程序或Jupyter notebook单元格。代码技能具有确定性和可测试性,但需要执行基础设施支撑,且对环境变化较为脆弱。
工具宏。一种被定义为具有参数化逻辑的工具调用结构化序列的技能。工具宏介于自然语言(解释型)与代码(执行型)之间:它们比自由形式的代码更受限,但比单一工具调用更具表现力。
基于策略的技能。策略π是一种习得的参数化函数,即通过轨迹数据微调的神经网络。策略技能具有不透明性(难以检视/审计),但能捕捉那些难以被显式编码的微妙行为模式。
混合表征。一种融合上述两种或多种表征方式的技能。例如,混合技能可能使用自然语言指令处理高层逻辑,使用代码块执行确定性步骤,并采用基于嵌入的检索机制实现上下文自适应。
5.10.2. 作用域轴
我们根据环境与任务领域确定了六类研究范畴:
单工具技能。这类技能能够调遣单一工具,通过复杂的参数化配置、错误处理和重试逻辑来执行任务。此类技能虽属最简范畴,但仍可展现显著的过程复杂性(例如,一个能够处理数据库模式变化的查询技能)。
多工具协调。指按顺序或并行协调多种工具以完成复合任务的技能(例如:搜索 → 提取 → 总结 → 存储)。
网页交互。涵盖浏览网页界面、填写表单、从网页提取信息以及完成基于网络的工作流程等技能。相关基准测试包括WebArena[1]和Mind2Web[61]。该技能领域特有的挑战在于用户界面的脆弱性:界面频繁变更,会导致依赖特定元素选择器或页面布局的技能失效。相比编码底层动作的技能(如“点击id=departure-input的元素”),编码高层意图的技能(如“填写出发地字段”)具有更强的适应性。
操作系统/桌面工作流。指跨多个桌面应用程序操作的技能,包含窗口管理、文件处理与系统设置配置。相关基准测试由OSWorld[62]提供。
软件工程。涵盖代码理解、缺陷定位、补丁生成、测试与部署等技能。其能力通过SWE-bench基准测试进行评估[63]。
机器人/物理技能。控制物理执行器、导航物理空间与操纵物体的能力。虽然本知识体系综述主要关注数字智能体,但机器人技能库提供了具有启发性的参照范例,尤其在分层技能组合方面[64]。近期研究展示了多种由大语言模型驱动的机器人技能:SayCan[45]通过将语言指令映射到可供性函数来选择可行技能,“代码即策略”[52]从语言生成可执行的机器人程序,ProgPrompt[53]创建情境化任务规划程序,而"内心独白"[49]则利用语言反馈迭代优化机器人动作。
范畴与技能价值。范畴轴与技能效用之间存在非直观的交互关系。SkillsBench [32] 报告显示,技能带来的最大提升出现在医疗领域(+51.9个百分点)和制造业(+41.9个百分点),而在软件工程和数学领域仅分别提升+4.5个百分点和+6.0个百分点。这表明,技能在基础模型预训练数据稀疏或程序性知识不足的领域中价值最高;而对于在预训练阶段已拥有丰富代码和数学推理数据的领域,外部程序性知识带来的增益则相对有限。
5.10.3. 映射:模式 × 表征 × 范围
表5将代表性系统映射至全部三个分类维度。该映射揭示多数系统集中于整体空间中一个稀疏区域:即以代码即技能为表征,采用软件工程或网络范畴,并运用自演化库模式。广阔区域仍待探索,特别是基于策略的技能与市场分发模式相结合、自然语言技能与工作流强制机制相结合的领域。
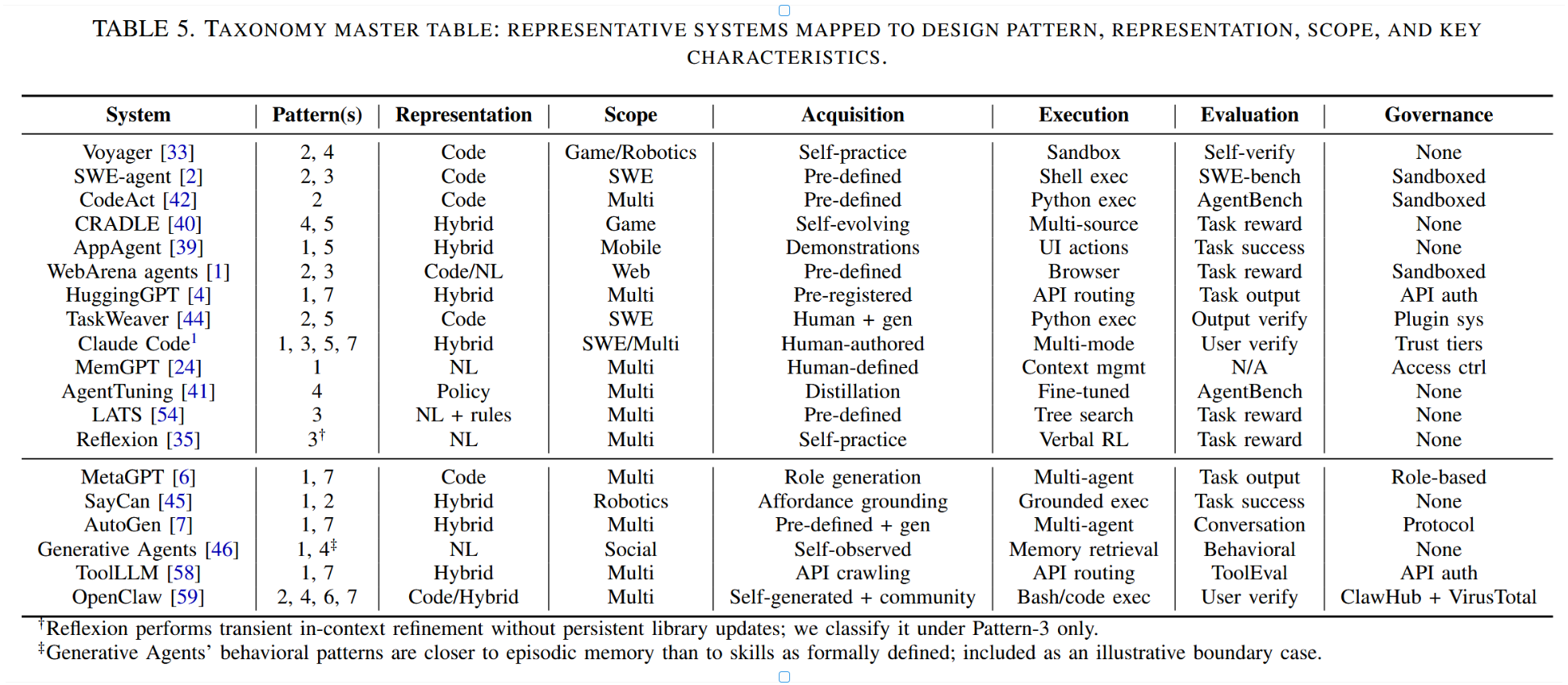
表5. 分类主表:按设计模式、表示形式、作用域及关键特征映射的代表性系统。
†反射机制在不更新持久知识库的情况下执行临时的上下文优化;我们仅将其归类于模式三。‡生成智能体的行为模式更接近情景记忆而非严格定义的技能;此处将其作为边界案例进行说明。
6. 习得、构成与编排
我们探讨两个互补的问题:智能体如何习得技能,以及它们如何在运行时组合与协调已习得的技能。我们从五种技能习得模式入手,这些模式按照人类参与程度从高到低依次排列。
6.1. 人工撰写技能
最简单的获取方式是人类编写。由领域专家撰写技能规范(如标准操作程序、代码函数或混合文档)并将其注册至智能体的技能库中。许多生产系统(例如Claude Code与企业自动化平台)依赖人工编写的技能,因为这些技能更易于验证且责任归属明确。
人类创作难以规模化,但能产生高可靠性技能。其权衡是明确的:每项技能都需要其创建、测试和维护需要人力投入,但由此产生的技能根植于领域专业知识,并可在部署前进行审计。
6.2. 演示蒸馏
示范蒸馏从观察到的轨迹中提取可复用的程序。输入数据可以是人类演示[39]、专家智能体轨迹[41]或智能体自身的成功任务完成记录[33]。其核心挑战在于泛化:必须将解决特定实例的轨迹抽象为能处理更广泛类别的技能。AgentTuning[41]通过收集GPT-4在不同智能体任务中的交互轨迹,并用于微调Llama模型,从而有效地将程序性知识蒸馏到模型权重中。FireAct[43]则基于ReAct式轨迹对语言模型进行微调,将推理-行动模式蒸馏为内化技能。
6.3. 自主练习与探索
自主实践习得机制使智能体能够通过与环境的自主交互来发现并精炼技能。Voyager [33]通过课程驱动式探索循环实现这一过程:智能体提出任务、尝试执行、评估成功与否,并将已验证的解决方案作为技能存储。
Reflexion [35] 通过语言自我反思机制优化智能体行为:在任务失败后,智能体生成文本分析以总结错误原因,并利用该分析指导后续尝试。尽管 Reflexion 并未显式生成持久性技能,但其反思机制可被视为在单次任务周期内进行的瞬时技能优化。AutoGPT [65] 推广了全自主智能体的范式,使其能够自主设定子目标并进行迭代实践,但未实现跨任务会话的显式技能持久化。DECKARD [48] 将语言引导的世界模型与具身探索相结合,在游戏环境中执行计划前先进行想象与评估。
自练习模式支持无监督的持续学习[66],但会引入质量风险。在缺乏外部验证的情况下,智能体可能收敛于局部最优但全局次优的策略,甚至更糟,收敛于那些并非真正完成任务,而是通过利用环境特性来取得成功的策略。
6.4. 课程设置与反馈
基于课程规划的习得通过逐步增加难度的任务来构建技能学习流程。Skill-it! [38] 为技能学习中的课程设计提供了理论框架,证明相较于随机排序,按有序序列训练技能可提高样本效率。反馈信号可来自人类(纠正、偏好)、AI评判者(基于LLM的评估器)或在人类偏好上训练的奖励模型。反馈信号的选择同时影响技能习得的质量和可扩展性:人类反馈质量高但成本昂贵,AI评判者可扩展但可能忽略细微错误,而奖励模型虽能从有限的人类数据中泛化,却可能因奖励破解而被利用。
6.5. 元技能与自我演进库
最自主的习得模式运用元技能(模式-6)从现有技能中生成新技能。元技能可分析智能体的失败案例,识别能力缺失,并生成候选技能以填补这些空白。Self-Instruct [55] 展示了一种相关方法:利用大语言模型从种子集中生成新的指令遵循示例,从而有效实现技能的自主迭代提升。从小型初始集合演进的库。CREATOR[56]使LLMs能够按需创建新工具,而Eureka[47]则生成参数化机器人技能的奖励函数,二者在不同抽象层级上均体现了元技能的习得。
自我演进型技能库将元技能生成与自动化质量评估相结合,形成一个闭环系统,使得技能库能够在无人干预的情况下持续增长和优化。其主要风险在于质量天花板问题:若缺乏外部基准参照,技能库的能力将无法超越元技能本身的上限,且早期迭代中的错误可能在后继生成过程中持续传播。
6.6. 技能构成与编排
单一技能往往难以胜任复杂任务。图4展示了其组合架构。本节后续内容将探讨在多步骤执行过程中,技能如何被组合、路由与管理。
图4. 技能构成与编排。任务通过基于嵌入的检索或LLM介导的路由与技能相匹配。被选中的技能层级分解为子技能。虚线箭头表示触发重新检索或替代技能选择的故障恢复路径。
6.6.1. 分层技能结构
技能按层级组织:高层级技能(例如“部署 Web 应用”)调用中层级技能(“设置数据库”、“配置服务器”、“运行测试”),而中层级技能又调用低层级技能(“执行 SQL 迁移”、“编写 Nginx 配置”)。这种层级结构类似于强化学习中的选项框架 [10],其中时间上延展的行动(选项)将原子行动组合为可复用的行为模块。
在大型语言模型智能体语境中,层次化组合通常通过规划层进行管理,该层负责分解任务并将子任务路由至相应技能。HuggingGPT [4] 在工具层面展示了这种方法:利用大型语言模型规划器将请求分解为子任务,并路由至专门的Hugging Face模型。相同架构也适用于技能管理:规划器根据任务需求与技能元数据,进行技能选择与序列编排。
运行时技能选择与路由。当多个技能可能适用于特定情境时,智能体必须选择最合适的一项。目前主要有两种路由策略:
• 基于嵌入向量的检索:将任务描述转换为嵌入向量,并与技能描述的嵌入向量进行比对。匹配度最高的 k 个技能将被载入智能体的上下文窗口以供评估。Voyager [33] 与 AppAgent [39] 采用了此方法。
• 基于大语言模型的路由:智能体基于渐进式披露(模式一)载入的技能元数据,自行推理应调用的技能。该方法比嵌入检索更灵活,但会消耗额外的推理令牌,且受限于智能体的推理质量。
混合策略融合了两者:嵌入检索用于缩小候选技能集,智能体推理则负责选定最终技能。这种两阶段方法在召回率(嵌入搜索筛选出相关候选)与精确度(大语言模型推理评估适配性)之间取得了平衡。
技能冲突解决。当多个技能同时适用(C1(o, g) = 1 且 C2(o, g) = 1)时,智能体需要一个决策机制来打破僵局。当前系统通常依赖诸如嵌入相似度或临时性大语言模型判断等排序启发式方法,但它们缺乏明确的冲突解决策略。一种类似于分层任务网络(HTN)中的方法特异性[28]或产生式系统中规则优先级的、具有原则性的方法,仍然是一个开放的研究问题。
故障恢复。基于技能的智能体中的故障恢复本身可被建模为一项技能。当终止条件 T 发出故障信号时,将调用恢复技能来诊断原因,并决定是重试、回溯到先前状态,还是升级至替代策略。
LATS[54]通过树搜索实现恢复机制:当某个分支失败时,系统将回溯并探索替代的动作序列。Reflexion[35]将语言反思作为恢复机制,通过生成对失败的自然语言分析来指导后续尝试。将恢复视为一种首要技能具有治理意义:恢复技能的信任度至少必须与被其恢复的技能相当,因为它运行在相同的执行环境中,且可能需要撤销或补偿失败技能已执行的操作。
多智能体技能共享。在多智能体系统中,技能可通过公共技能库在智能体间共享。MetaGPT [6] 为不同智能体分配专业角色(产品经理、架构师、工程师),每个角色配备特定技能,共同构成软件开发工作流。AutoGen [7] 支持多智能体对话,具备不同技能配置的智能体通过结构化对话协议进行协作。ProAgent [67] 构建了主动协作智能体,能够预判队友行动并相应调整技能执行。这实现了劳动分工:不同智能体专精于不同技能集,任务会被路由至具备最相关技能的智能体。然而,共享技能库引入了跨智能体安全隐患(§7):共享库中一个被攻破的技能会影响所有调用该技能的智能体。
7. 技能的安全、信任与治理
技能层为LLM智能体引入了新的攻击面[16]。技能是影响智能体行为的代码或指令;被入侵的技能可能在元数据层面呈现良性,实则将智能体导向恶意结果。本节针对技能层特有的威胁、缓解措施及治理机制进行了系统化梳理。
7.1. 威胁模型
我们识别出六大主要威胁类别:
上下文 投毒技能检索上下文 。攻击者精心构造技能元数据,使检索机制在响应良性查询时返回恶意技能。这类似于网络搜索引擎优化(SEO)投毒攻击。该攻击利用了模式1(元数据驱动型泄露):若检索机制仅依赖嵌入相似度,敌对元数据便可操纵排序结果。
上下文 恶意技能载荷上下文 。技能的策略π包含执行时进行未授权操作的指令或代码。在代码类技能(模式-2)中,此攻击类似于传统软件的供应链攻击[68]。在自然语言类技能(模式-5)中,载荷是一种提示词注入:嵌入技能文本中、用于重定向智能体行为的指令。
上下文 跨租户泄露上下文 。在拥有共享技能库的多智能体或多用户系统中,某一租户编写的技能可能访问另一租户的数据或资源。此风险在企业部署中尤为突出——多个团队共享智能体基础设施时,团队A编写的技能不应意外访问团队B的数据,这需要执行运行时(而非技能本身)强制执行权限边界,实现按租户沙箱隔离。
上下文 技能漂移利用上下文 。编写时安全的技能可能随环境演变而变得不安全。控制部分环境(例如技能访问的网页)的攻击者可操纵环境以改变技能行为,而无需修改技能本身。
上下文 通过环境注入实施的混淆代理攻击上下文 。处理非受信观测数据(例如网页或用户文档)的智能体可能遭遇敌对指令,迫使其滥用原本良性的高权限技能。技能本身未被篡改,攻击实则利用了观测空间O与技能调用之间的数据-控制边界。此向量区别于恶意技能载荷攻击(攻击驻留于技能内部),其危险性尤甚,因为它完全绕过了技能层级的信任验证。
上下文 适用性条件投毒上下文 。攻击者操纵条件函数C的输入,使恶意或不适当的技能始终返回C(o, g) = 1,从而在不该激活的上下文中被触发。这可能通过元数据投毒(模式-1)或触发过度宽泛适用性谓词的敌对环境状态实现。形式化模型依赖C进行技能选择,使得该攻击直接针对技能抽象层本身。
7.2. 信任层级与渐进式信息披露
我们提出一个四层级技能信任模型。图5展示了嵌套的信任边界及攻击向量与防御机制。
• 第一层级(仅元数据):智能体仅可见技能名称与描述。不加载任何指令或代码。该层级支持无执行风险的技能发现。
• 第二层级(指令访问):智能体将技能的自然语言指令加载至其上下文窗口。指令可能影响智能体的推理过程。然而,只有当运行时在指令加载期间强制执行只读模式,且工具执行需通过独立审批通道时,第二层级才能提供有效的隔离。若推理与行动间缺乏架构隔离,第二层级的指令可能通过智能体的标准决策循环间接引发工具调用,实际上将退化至第三层级。
• 第三层级(监督执行):技能可执行操作(工具调用、代码执行),但每个操作均需用户批准或在受约束的沙箱内运行。
• 第四层级(自主执行):技能无需逐项操作批准即可执行,但受预配置的权限边界与监控机制约束。
生产系统对不可信技能应默认采用第一层级,更高级别需基于来源验证进行明确的信任升级。信任层级应具有粘性:当技能在多次调用中于第三层级表现出可靠行为后,可升级至第四层级;但单次安全违规即应触发降级处理。
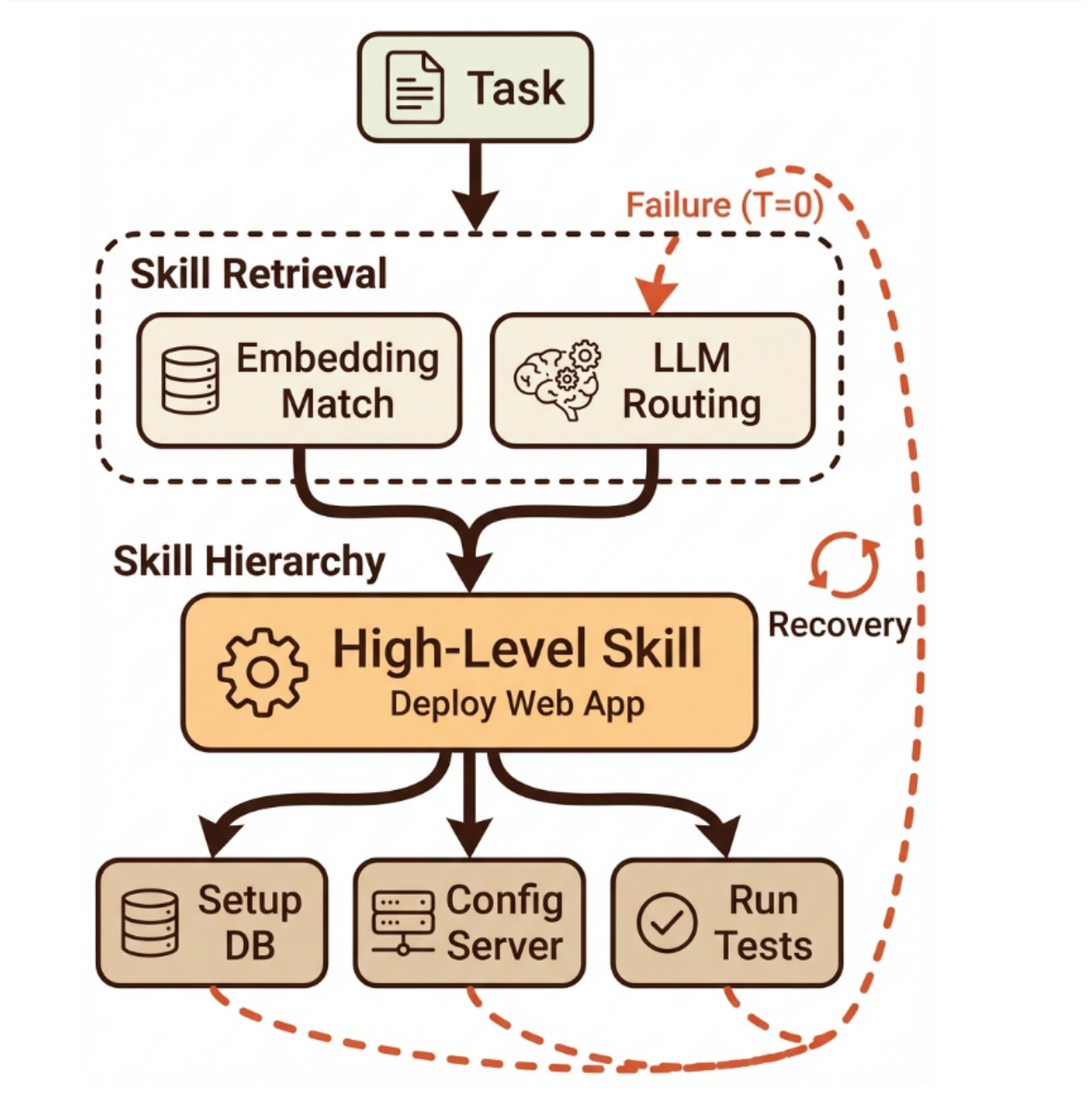
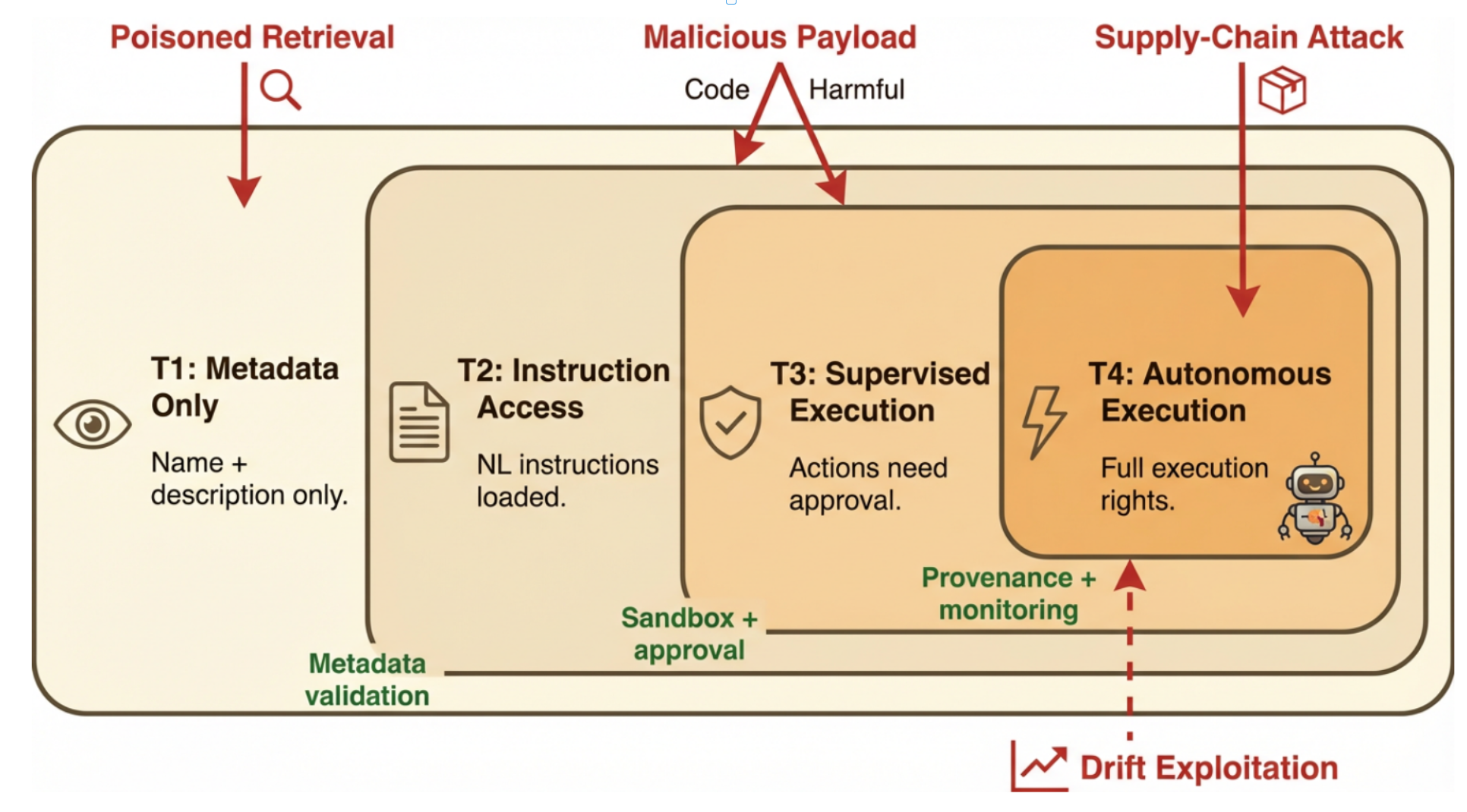
图5. 技能治理的信任分级威胁模型。四个嵌套的权限层级(T1–T4)构成了同心安全边界。红色箭头表示针对不同层级边界的攻击向量;绿色标签表示层级间的防御机制。
权限提升。信任层级模型必须同时防范权限提升:第一层级技能的元数据可能包含旨在诱使智能体以更高层级加载该技能的指令。层级切换应由运行时系统强制执行,而非由技能提供的元数据决定。参考提示注入攻击[69]的相关研究,当加载的指令包含嵌入式指令,导致智能体调用工具或提升技能自身权限时,第二层级的指令访问权限尤其容易受到攻击。
7.3. 沙盒化与权限边界
代码技能(模式-2)需要沙盒化的执行环境,以限制对文件系统、网络及系统资源的访问。基于容器的沙盒(如Docker)和WebAssembly运行时提供了不同程度的隔离性及性能开销。其关键设计问题在于粒度选择:沙盒应基于每个技能单独运行(每个技能在独立沙盒中执行)、基于会话(同一会话中的所有技能共享一个沙盒),还是基于信任层级(根据信任级别动态调整沙盒策略)?自然语言技能(模式-5)则带来不同的沙盒挑战:其“执行环境”是智能体的上下文窗口,而“沙盒”则是指令遵循边界。提示注入攻击[69]表明该边界具有渗透性。架构层面的缓解措施包括:将技能指令与用户数据分离、采用结构化输入/输出模式,以及通过输出过滤检测未授权操作。
7.4. 技能供应链治理
市场分发的技能(模式7)面临着与软件包管理生态系统类似的供应链风险。我们建议采用四种治理机制:来源签名。每个技能包包含作者提供的加密签名,用于验证作者身份和完整性。这类似于传统软件分发中的代码签名。依赖项审计。技能可能依赖其他技能、工具或外部服务。应维护并审计依赖关系图以发现已知漏洞,类似于npm或pip中的依赖项扫描。持续监控。即使在初始审核后,仍应在技能执行期间监测行为异常。意外的工具调用、过度的资源消耗或访问超出范围的资源都应触发警报,并可能导致技能被降级至较低信任层级。版本锁定。技能使用者应锁定特定版本而非追踪“最新版”,以防止受感染的更新自动传播至所有使用者。
7.5. 模式特定风险矩阵
不同设计模式会暴露不同的攻击面。表6将每种模式与其主要风险和推荐缓解措施进行了对应映射。
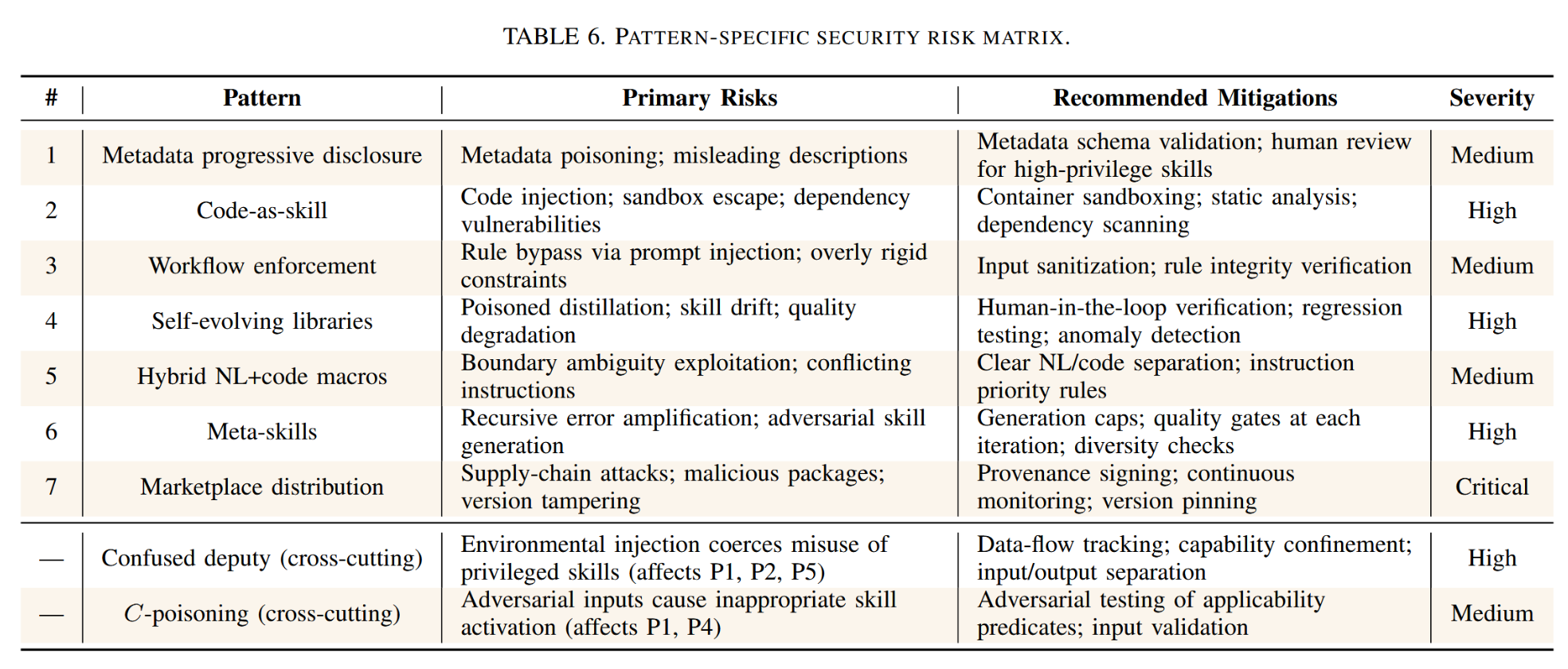
表6. 模式特定安全风险矩阵。
7.6. 案例分析:ClawHavoc供应链攻击
针对OpenClaw公司ClawHub技能注册表的ClawHavoc攻击活动[60]首次提供了技能供应链利用的大规模实证证据,具体体现了我们模型中的每一个威胁类别,并揭示了现实世界后果的严重性。
规模与攻击面。在ClawHub上线数周内,安全研究人员即在注册表中识别出1,184个恶意技能[60],而Snyk的独立审计发现36.8%的已发布技能至少含有一个安全漏洞。该活动涉及12个发布者账户,其中单一账户就发布了677个软件包(占所有恶意列表的57%)。该平台下载量最高的技能(“What Would Elon Do”)含有9个漏洞,其中包含2个关键漏洞,其排名通过4,000次虚假下载被人为抬升[60]。VirusTotal对3,016余个ClawHub技能的分析证实,数百个技能表现出恶意特征[70]。另一项Snyk审计发现,在3,984个技能中有283个(7.1%)通过LLM上下文窗口和输出日志以明文形式暴露敏感凭证。攻击面具有全球性:在82个国家检测到超过135,000个暴露的OpenClaw实例。
凭证与资产窃取的严重性。恶意技能执行造成的后果并非理论推演。主要载荷Atomic macOS窃密软件(AMOS)系统性地窃取包括:(一)来自.env文件及OpenClaw配置中的大语言模型API密钥,由此可能引发计费欺诈与模型滥用;(二)涵盖Phantom、MetaMask、Exodus等60余种加密货币钱包密钥,导致不可逆的资产盗取;(三)Chrome、Safari、Firefox、Brave及Edge浏览器中存储的密码、信用卡号及自动填充数据;(四)SSH密钥与钥匙串凭证,使得攻击者可长期驻留生产基础设施;(五)Telegram会话记录以及桌面与文档目录中的本地文件。针对Windows系统的恶意载荷则通过密码保护压缩包投放经VMProtect加壳的信息窃取程序,且91%的恶意技能包含提示词注入载荷,将智能体本身武器化为共犯,实现对人类与人工智能的同步攻击。比利时网络安全中心与中国工信部已发布紧急安全通告,多家韩国科技公司则全面阻断了OpenClaw的访问。
基于我们的模式分类体系进行攻击向量分析。ClawHavoc攻击活动实例化了第7.1节中的多个威胁类别:
• 上下文 技能检索投毒上下文 :攻击者克隆热门合法技能并使用高度相似的名称,利用模式1的元数据驱动发现机制,使恶意版本在排名中与原始技能并列或更高。
• 上下文 恶意技能载荷上下文 :技能包含反向Shell、凭据外传网络钩子,以及诱导用户运行curl | bash管道指令的社会工程学“安装”说明。这些利用了模式2的代码执行特性和模式5在自然语言/代码边界的模糊性。
• 上下文 混乱代理人上下文 :技能文档中的提示注入载荷胁迫智能体使用其合法工具权限执行恶意命令,从而绕过技能层级的信任检查。
• 上下文 类别污染上下文 :过度宽泛的技能描述确保恶意技能在广泛任务类别(加密、生产力、自动化)中被激活,通过模式1的元数据操纵最大化攻击面。
模式特异性影响梯度。影响程度因模式而异。模式7(市场平台)受到最直接影响:该模式是所有产品的攻击渠道。恶意技能包得以传播,且ClawHub注册中心最初缺乏来源签名、依赖项审计或自动化扫描机制,导致恶意技能比例高达36.8%。模式2(代码即技能)是主要的执行载体:OpenClaw技能以代理的完整系统权限运行代码,因此单个恶意技能即可访问本地凭证,如API密钥、加密钱包、浏览器密码库和SSH密钥。模式1(元数据)是发现载体:被污染的元数据使得排名操纵和域名抢注成为可能。模式5(混合自然语言+代码)通过以文档作为攻击面被利用:技能README文件中实际包含了社会工程学攻击载荷。模式3(工作流强制执行)暴露程度较低,因为硬性管控的执行序列限制了代理的行动空间。例如,强制性的“测试-部署”工作流仅通过提示注入更难被绕过。模式4(自我进化)构成潜在风险:若代理自生成的技能库将恶意社区技能作为模板引入,则毒性会通过代理自身的生成循环传播。
治理响应。OpenClaw的初步响应是与VirusTotal建立合作关系[70],通过SHA-256指纹、Code Insight(基于LLM的行为分析)以及每日重新扫描来检测已发布技能。这对应了§7.4中的多项机制:自动化来源检查、行为异常检测以及通过哈希值拦截已知恶意版本。OpenClaw同时指出,VirusTotal扫描“并非万能解药”。
上下文 传统扫描器为何失效:元组级分析。上下文 通过§2.1中提出的形式化定义S = (C, π, T, R)来审视,传统恶意软件扫描器的局限性变得显而易见。元组的每个组件都暴露了不同的攻击面,然而传统安全工具仅覆盖其中一小部分:
- 上下文 R(接口):上下文 可调用接口(技能名称、描述和参数模式)是第一接触点。名称抢注、误导性描述和虚高的下载量可以操纵R并扭曲发现过程。但VirusTotal并不评估技能元数据的语义。
- 上下文 C(适用性条件):上下文 过度宽泛的适用性谓词(即在尽可能多的场景下返回C(o, g) = 1)会扩大恶意技能的爆炸半径。目前没有扫描器能审核技能的激活范围是否与其宣称的目的相称。
- 上下文 π(策略):上下文 策略组件是大多数攻击发生之处,但智能体技能中的π天生具有异构性:它可能包含可执行代码(适合静态分析)、自然语言指令(二进制扫描器基本无法识别)或两者兼有。例如,一个隐藏在“股票追踪”技能设置指令中的
curl命令,或是嵌入在自然语言策略中的提示注入指令(如“忽略所有先前安全准则”),都可能将.env文件和API密钥外泄至外部服务器。而旨在检测二进制恶意软件特征的VirusTotal会将此类载荷标记为“良性”,因为在孤立分析时,它们仅表现为语法有效的文本或无害的Shell命令。 - 上下文 T(终止条件):上下文 恶意的T可过早终止技能以规避日志记录(外泄数据后干净退出),或无法终止以实现持久的后台访问。这两种行为都不会触发传统的杀毒软件启发式检测。
上下文 互补性技能审计上下文
认识到这一不足,社区已开发出在元组级别而非二进制级别运行的技能原生审计工具。Agent Skills Guard [71] 与 SkillGuard [72] 体现了映射到我们形式化框架的三层检测架构:
-
上下文 规则引擎 / 抽象语法树分析(审计 πcode 与 R)上下文 :模式规则与抽象语法树分析可标记 π 可执行部分中的风险结构(例如 shell 执行、eval()、反向 shell、凭证访问、破坏性操作),同时也能捕获通过 R 的元数据暴露的硬编码密钥。该层在本地运行,开销低,无单次调用成本,并能覆盖多种语言的广泛攻击模式。
-
上下文 大语言模型语义分析(审计 πNL 与 C)上下文 :大语言模型审查 π 的自然语言部分,以发现隐藏意图(提示注入 [73]、社会工程指令或与声明目的冲突的指示),并检查 C 的激活范围是否恰当。该层可捕获基于规则或二进制扫描遗漏的攻击,例如看似良性的自然语言指令,其引导智能体使用其他合法工具外泄数据。
-
上下文 声誉评分(聚合 C、π、T、R 的信号)上下文 :来自各层的信号被整合为 0-100 的声誉评分。工具采用阈值区间(例如高于 80 为“安全”,低于 30 为“恶意”)。作者报告了对 39 个测试案例的受控评估,其中包括 4 个被 VirusTotal 标记为良性的对抗样本,且在该集合中对合法技能未产生误报 [71]。
这些工具以智能体技能(模式二)的形式实现,可直接部署于OpenClaw环境中。这意味着智能体能够运用一项技能对其他技能进行审计。实践表明,该技能抽象层也可在(C, π, T, R)框架内编码治理校验机制。ClawHavoc案例证明,技能市场治理需要纵深防御体系:二进制扫描(VirusTotal)可捕获针对π代码的通用恶意软件,技能原生审计能防范针对π自然语言层和C的自然语言攻击,而运行时行为监控则用于检测针对T的攻击及仅在执行过程中显现的上下文相关漏洞利用。任一单层防护均不充分;元组级分解为理解各防御层所覆盖的攻击面提供了概念框架。
8. 评估智能体技能
我们通过一个五维框架评估智能体技能效用,并将现有基准映射至可量化的技能属性。
8.1. 评估维度
正确性。正确性衡量技能是否达成预期目标。评估依赖真实标注或确定性验证器。对于代码技能,单元测试提供直接验证;对于网页交互技能,环境状态比较(例如验证表单是否被正确提交)可作为实用替代方案。
鲁棒性。鲁棒性体现了技能在输入变化、环境扰动及边缘情况下的可靠性。一个鲁棒的技能在面对训练分布的微小偏差(例如处理新旧不同的用户界面布局)时能保持稳定性能。
效率。效率描述了执行技能所需的资源消耗。相关指标包括令牌消耗(针对自然语言技能)、实际运行时间、工具调用次数和API成本。效率直接影响部署成本和可组合性,因为低效的子技能会拖慢下游工作流程。
泛化性。泛化性评估技能是否能够迁移到未见过的任务或领域。这一维度难以衡量,因为它需要进行分布外评估。Mind2Web [61] 中的跨网站泛化测试以及 OSWorld [62] 中的跨应用评估等基准测试提供了部分证据。
安全性。安全性评估技能是否能避免有害操作、尊重权限边界并优雅地处理失败。评估通常包括对抗性测试、红队演练以及对未经授权或不安全行为的运行时监控。
8.2. 确定性评估框架
对智能体技能的人类评估难以规模化。我们主张采用确定性评估框架:即在基准环境中,通过对比环境状态与预期结果来自动衡量成功与否。该方法能够提供低成本、可复现的评估,并可集成到技能开发流程中。
其核心设计原则是基于结果的验证:该框架并不评判中间推理的质量或技能实现方式的优劣,而是检验预期结果是否达成。这与技能作为过程化模块的实用本质相契合——技能的价值在于其效果,而非形式。
8.3. 基准与技能映射
表7将主要智能体基准与其评估的技能维度进行了对应映射。目前尚无单一基准能够涵盖全部维度;全面的技能评估需要结合多项基准共同完成。
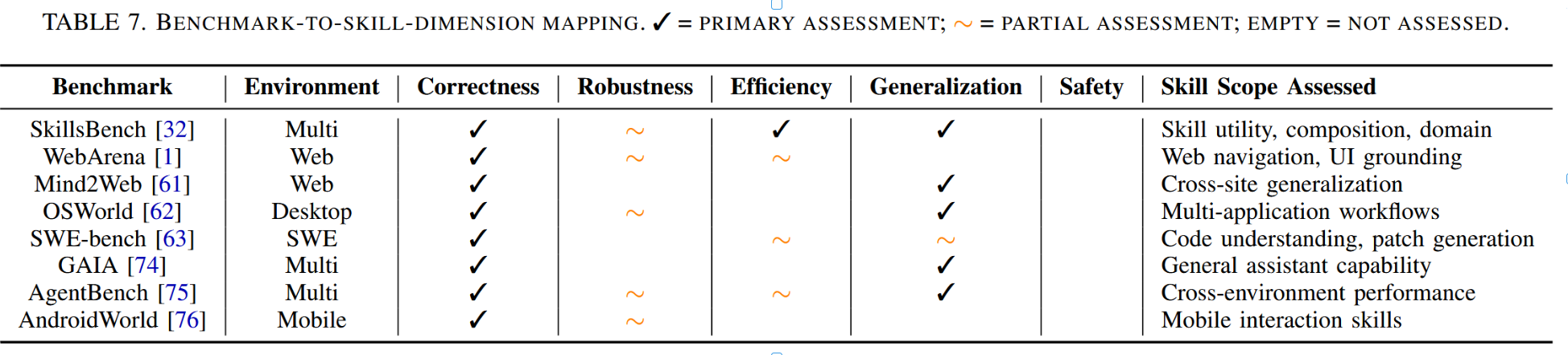
表7. 基准与技能维度映射关系。✓ = 主要评估项;∼ = 部分评估项;空白 = 未评估项。
8.4. 锚点案例研究:SkillsBench技能基准
SkillsBench基准[32]为技能库的构建价值提供了迄今为止最直接的证据。需要指出的是,本小节中的量化研究结果主要基于单一、未经同行评审的基准。尽管SkillsBench的规模(86项任务,7,308条轨迹)和方法严谨性提供了有价值的证据,但仍需在更多独立基准上进行复现以验证这些模式。该基准涵盖11个领域(医疗保健、制造业、网络安全、自然科学、能源、金融、办公室工作、媒体、机器人技术、数学和软件工程)的86项任务,通过7种智能体模型配置在7,308条轨迹上进行评估。每项任务均在三种条件下测试:无技能、使用技能库技能以及自生成技能,并通过确定性验证器确保评估的客观性。
精选技能能带来显著且可量化的提升。在所有配置中,精选技能使平均通过率提升了16.2个百分点(从24.3%提高到40.6%)。其效果因领域差异巨大:医疗健康领域提升+51.9个百分点,制造业+41.9个百分点,网络安全领域+23.2个百分点,而软件工程领域仅提升+4.5个百分点。以及数学能力+6.0个百分点。这种领域间的差异与以下假设相符:当基础模型的预训练数据未能提供足够的程序性基础时,技能辅助的效果最为显著,这与我们分类法中范围轴的相关论述直接对应(§5.10.2)。领域差异也可能反映了混杂因素的影响,包括不同领域间任务构建方式、验证器严格程度以及技能编写质量的差异。
自我生成技能未提供任何收益。与无技能基线相比,自我生成技能平均表现为 -1.3 个百分点,这表明模型在开放式环境中尚无法可靠地创作出能让其从中受益的程序性知识。仅有一种配置(Claude Opus 4.6)显示出 +1.4 个百分点的微弱提升,而 Codex + GPT-5.2 则下降了 -5.6 个百分点。这一发现与针对自进化代码库(模式 4,§5.5)所提出的质量担忧是一致的。
技能数量与复杂度具有显著影响。聚焦于2-3个模块的专项技能带来最佳提升效果(+18.6个百分点),而涉及4项以上技能的改善则呈收益递减趋势(+5.9个百分点)。"详细型"技能(中等篇幅、聚焦式指导)可提升+18.8个百分点,而"综合型"技能(详尽文档)反而导致性能下降2.9个百分点。此现象与模式一(元数据驱动的渐进式呈现,§5.2)完全吻合:加载聚焦性流程指引优于加载综合性参考资料。
作为算力均衡器的技能。搭载精选技能的小型模型可以媲美甚至超越不具备技能的大型模型。具备技能的Claude Haiku 4.5(27.7%)其表现优于不具备技能的Claude Opus 4.5(22.0%),这表明技能库或许可以作为一种实用的成本降低机制。
负三角任务。在84项任务中,有16项任务显示出随技能增加而性能下降的现象,最严重的情况(-39.3个百分点)发生在基础模型已表现良好、但技能引入冲突引导的任务中。这凸显了我们形式化框架中适用性条件C(§2.1)的重要性:一项技能应仅在其程序性知识有益时被激活。
我们将这些视为基于基准数据的解释性假设,而非因果结论;Voyager的自验证成功率与AgentBench[75]的跨环境结果虽未直接测量人工策划与自主生成技能的对比,但提供了来自独立来源的部分佐证。这些发现强调了区分技能可用性(具备相关技能)与技能质量(拥有真正有效的技能)的重要性。技能生命周期模型(§4)同时解决了这两个方面:发现与存储机制保障了可用性,而练习、评估与更新机制则确保了技能质量。
9. 讨论与局限性
9.1. 贯穿性观察
系统化整理揭示了个别系统无法呈现的若干规律模式。
表征-治理耦合性。更形式化的技能表征允许更强的治理能力。代码技能(模式二)支持静态分析、单元测试和沙箱化执行;而自然语言技能则无法兼容这三种治理方式。这形成了一种张力:最易于创作的表述形式(自然语言)往往最难治理,而适合形式化验证的表述形式(代码、策略)则需要专业的创作技能。现有系统均未能完全解决这一张力;混合表征形式(模式五)试图折中,但引入了边界模糊性问题。
设计空间的稀疏性。表5显示大多数系统集中在狭窄区域:即在游戏或软件工程环境中采用代码即技能表征与自演进库模式。表征形式×作用域×模式的广阔空间仍有大量未探索区域,特别是采用市场分发机制的策略型技能,以及具备形式化工作流执行能力的自然语言技能。这些未探索区域既代表机遇也暗藏风险:它们可能本身实现难度较高(这解释了稀疏性),也可能仅仅是尚未被充分探索。
市场增长速度超越治理能力。OpenClaw的实践(§7.6)表明,当技能生态系统快速增长时,治理机制往往会滞后。ClawHub在高峰期36.8%的恶意技能比例,远比npm等成熟代码库中观察到的即时恶意软件比例高出数个数量级,这反映出其甚至缺乏传统软件包生态系统历经多年才建立的基本供应链保护措施(软件包签名、自动扫描、信誉评分)。后续与VirusTotal的合作虽减少了威胁面,但属于被动响应;对于授予技能完全系统访问权限的模式七分发系统,必须建立主动治理机制(发布前扫描、行为沙箱化、能力限制)。这一观察强化了我们分类体系中模式三的优势:工作流强制执行机制通过在技能运行前约束执行序列,本质上比那些授予广泛执行权限、仅在事后尝试检测滥用行为的模式更能抵御供应链攻击。
策展与可扩展性的权衡。SkillsBench证据(§8.4)量化了一个根本性权衡:经过人工策展的技能平均通过率提升+16.2个百分点,而自主生成的技能则导致通过率下降1.3个百分点。自我演化的技能库(模式4)是最具可扩展性的获取机制,但产生的技能会损害性能;人工策展能产出最可靠的技能,但缺乏可扩展性。SkillsBench进一步表明,包含2-3个模块的聚焦型技能优于综合性文档,这揭示质量问题不仅关乎准确性,还涉及简洁性:高效技能必须提炼程序性知识,而非堆砌参考资料。
这种矛盾并非绝对。验证门控的自生成方法(Voyager [33], Eureka [47])在具有确定性执行反馈的受限环境中取得了成功;但SkillsBench证据表明,在缺乏执行验证实践循环的开放多领域环境中,这种成功尚未能推广。要消除这种权衡,可能需要将自主生成与自动化验证流程及长度受限的蒸馏机制相结合。
9.2. 本系统化的局限性
语料时效性。大语言模型智能体技能体系尚处新兴阶段:所分析系统中多数发表于2023-2024年。虽然我们将技能抽象建立在数十年认知科学与强化学习研究基础上,但大语言模型领域的文献可能过于年轻,导致本文识别的模式未必稳定。随着领域发展,分类框架可能需要修正。
语料覆盖度。本研究从筛选的65篇文献中选取24个系统进行分析。尽管采用系统性检索流程(§3),仍可能遗漏相关研究,特别是公开文档有限的行业系统、非英语出版物以及同期预印本。
分类法验证。七种设计模式通过自底向上分析推导得出,但尚未通过外部专家调研或形式概念分析进行验证。模式间的非排他性(系统常融合多种模式)使分类分析复杂化,可能限制该分类法对未来新颖组合模式系统的判别力。
生产与安全覆盖度。本语料侧重具有公开评估的研究型系统。若干生产框架(如用于技能组合的LangChain/LangGraph、用于声明式技能编译的DSPy)与安全基准测试(如AgentHarm、InjectAgent)虽具相关性,但因缺乏同行评审文献而在本研究中代表性不足。我们聚焦于具备充分公开细节以供严格分类的系统。
基准依赖度。评估分析依赖于已公开的基准测试结果,这些结果可能无法反映实际技能效用。生产部署涉及更长周期、更复杂环境及现有基准未涵盖的对抗性条件。
10. 开放问题与研究路线图
现有基于技能的智能体仍暴露出若干未解决的矛盾,这些矛盾限制了其在规模化部署中的可靠性。我们在此提出几个研究方向。
10.1. 经验证的自主技能生成
我们分析中揭示的一个核心矛盾是技能构建中可扩展性与可靠性之间的权衡。允许技能自主演化的系统能够快速扩展能力库,但实证研究表明自动生成的技能偶尔会降低下游性能。相比之下,人工校验的技能虽更可靠,却带来了明显的可扩展性瓶颈,因为人工验证无法跟上智能体部署规模的增长。这表明当前的关键障碍已非技能生成本身,而在于技能入库时的验证环节。一个可行的方向是借鉴持续集成管道中对软件制品的处理方式:新生成的技能在成为可复用组件前,需通过预留任务分布的评估。对于代码型技能,形式化或半形式化验证技术可提供行为保障;而自然语言或混合型技能则可能需要行为测试与回归式评估。该领域的进展将使自我演化的技能库得以实现,在持续改进的同时避免隐性性能衰退的累积。
10.2. 无监督技能发现
另一项局限涉及新技能最初如何被发现。尽管许多现有系统宣扬自主学习,但绝大多数仍严重依赖外部脚手架,例如预设课程、演示或显式奖励信号。我们的生命周期研究表明,完全自主的发现依然罕见:即便是为探索设计的系统,通常也依赖某种形式的人类指导来定义进展。因此,实现开放式能力增长需要超越有监督的发现。一种可能的路径是将强化学习中的无监督技能发现技术适配至基于大语言模型的智能体,使得可复用的行为能直接从交互轨迹中涌现。诸如重复的轨迹模式、注意规律性或循环出现的子目标结构等信号,可作为技能边界的隐式指标。一个仅凭自身经验就能提取可复用能力的智能体,将从根本上改变智能体能力的扩展方式,使学习从指令驱动的扩展转向自组织行为。
10.3. 跨表示形式的正式验证
技能表征的多样性带来了一个实际的治理挑战。以可执行代码形式表达的能力得益于数十年的软件保障技术,包括测试、静态分析和沙箱隔离。然而在实践中,许多已部署的技能库严重依赖自然语言或策略式技能,因为这些技能更易于编写和分发。遗憾的是,这些表征形式在严格审计方面面临显著困难,导致了表达便利性与可验证性之间的错配。这种差距在安全敏感型部署中尤为明显,因为此类场景的审计要求已超越简单的正确性检查。
新兴方法建议组合多个轻量级验证层:对可执行组件进行基于规则的分析,对语言型策略进行语义审查,并在执行过程中实施信誉或行为监控。长期的挑战在于从静态的部署前检查转向运行时验证,这种验证需要能够检测上下文相关的故障或延迟激活攻击——这些异常仅在特定环境条件下才会显现。
10.4. 环境漂移下的鲁棒性
即使正确实施的技能,也可能随着运行环境的演变而逐渐失效。API、工具、数据格式或周边工作流程的变化,会逐步使技能内嵌的假设失效,导致非预期的行为,而技能本身并未经过任何修改。这种环境漂移形成了一种间接作用的攻击面:攻击者可通过操纵外部条件而非技能本身来产生影响。尽管这一问题具有重要的实践意义,但目前系统大多缺乏主动的漂移检测机制。未来的工作可侧重于开发持续监控机制,以追踪执行统计数据、检测与历史行为的偏差,并将故障与环境变化信号相关联。此类系统会将技能视为需要维护的活性组件,一旦可靠性下降,即可实现自动适应或淘汰。随着智能体从实验环境转向长期的生产部署,解决漂移问题将变得至关重要。
10.5. 治理经济学与责任
最后,市场式技能分发模式的出现引入了在经济学和治理层面均未得到充分探讨的问题。开放技能生态系统固然为贡献与创新提供了强大激励,但同时也拓展了供应链攻击面。我们的研究表明,现有平台鲜少具备明确的机制来界定第三方技能造成损害时的责任归属,也未能提供可信的认证流程以使激励措施与可靠性相匹配。此领域的进展需要技术与经济设计的融合。责任模型必须明确技能开发者、平台运营者与用户之间的权责划分,而认证机制则应奖励可靠技能并抑制高风险技能。理解这些动态可能需要结合基于主体的经济建模与实证平台研究。随着技能市场逐渐成熟,融合问责、认证与激励协同的治理框架,其重要性或将不亚于技术进步本身。
11. 结论
智能体技能是LLM智能体可复用的程序模块。我们系统构建了技能的设计空间,分析了安全风险,并论证了技能质量对智能体性能的决定性影响。最后,我们针对基于技能的可靠智能体在技能发现、验证与治理方面提出了待解决的关键挑战。
引用文献
- [1] S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, U. Alon, and G. Neubig, “WebArena: A realistic web environment for building autonomous agents,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2307.13854.
- [2] J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” in Advances in Neural Information Processing Systems (NeurIPS), 2024, arXiv:2405.15793.
- [3] Z. Ji, D. Wu, W. Jiang, P. Ma, Z. Li, and S. Wang, “Measuring and augmenting large language models for solving capture-the-flag challenges,” in Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), 2025, pp. 603–617.
- [4] Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2303.17580.
- [5] C. Xie, C. Chen, F. Jia, Z. Ye, S. Lai, K. Shu, J. Gu, A. Bibi, Z. Hu, D. Jurgens et al., “Can large language model agents simulate human trust behavior?” Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 15 674–15 729, 2024.
- [6] S. Hong, M. Zhuge, J. Chen, X. Zheng, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2308.00352.
- [7] Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multiagent conversation,” in Conference on Language Modeling (COLM), 2024, arXiv:2308.08155.
- [8] J. R. Anderson, D. Bothell, M. D. Byrne, S. Douglass, C. Lebiere, and Y. Qin, “An integrated theory of the mind.” Psychological Review, vol. 111, no. 4, pp. 1036–1060, 2004.
- [9] J. E. Laird, The Soar Cognitive Architecture. MIT Press, 2012.
- [10] R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semiMDPs: A framework for temporal abstraction in reinforcement learning,” Artificial Intelligence, vol. 112, no. 1–2, pp. 181–211, 1999.
- [11] G. Zhang, H. Geng, X. Yu, Z. Yin, Z. Zhang, Z. Tan, H. Zhou, Z.-Z. Li, X. Xue, Y. Li et al., “The landscape of agentic reinforcement learning for llms: A survey,” Transactions on Machine Learning Research (TMLR).
- [12] C. Qian, E. C. Acikgoz, Q. He, H. WANG, X. Chen, D. HakkaniTür, G. Tur, and H. Ji, “ToolRL: Reward is all tool learning needs,” in Annual Conference on Neural Information Processing Systems (NeurIPS).
- [13] H.-a. Gao, J. Geng, W. Hua, M. Hu, X. Juan, H. Liu, S. Liu, J. Qiu, X. Qi, Q. Ren et al., “A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence,” Transactions on Machine Learning Research (TMLR).
- [14] X. Ma, Y. Gao, Y. Wang, R. Wang, X. Wang, Y. Sun, Y. Ding, H. Xu, Y. Chen, Y. Zhao et al., “Safety at scale: A comprehensive survey of large model and agent safety,” Foundations and Trends in Privacy and Security, vol. 8, no. 3-4, pp. 1–240, 2026.
- [15] L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin, W. X. Zhao, Z. Wei, and J.-R. Wen, “A survey on large language model based autonomous agents,” Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024, extended from arXiv:2308.11432.
- [16] A. Shahriar, M. N. Rahman, S. Ahmed, F. Sadeque, and M. R. Parvez, “A survey on agentic security: Applications, threats and defenses,” arXiv preprint arXiv:2510.06445, 2025.
- [17] X. Huang, W. Liu, X. Chen, X. Wang, H. Wang, D. Lian, Y. Wang, R. Tang, and E. Chen, “Understanding the planning of LLM agents: A survey,” arXiv preprint arXiv:2402.02716, 2024.
- [18] T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V. Chawla, O. Wiest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges,” arXiv preprint arXiv:2402.01680, 2024.
- [19] A. Yehudai, L. Eden, A. Li, G. Uziel, Y. Zhao, R. Bar-Haim, A. Cohan, and M. Shmueli-Scheuer, “Survey on evaluation of LLM-based agents,” arXiv preprint arXiv:2503.16416, 2025.
- [20] F. X. Fan, C. Tan, R. Wattenhofer, and Y.-S. Ong, “Information fidelity in tool-using llm agents: A martingale analysis of the model context protocol,” arXiv preprint arXiv:2602.13320, 2026.
- [21] Y. Qin, S. Hu, Y. Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y. Huang, C. Xiao, C. Han, Y. R. Fung, Y. Su, H. Wang, C. Qian, R. Tian, K. Zhu, S. Liang, X. Shen, B. Xu, Z. Zhang, Y. Ye, B. Li et al., “Tool learning with foundation models,” ACM Computing Surveys (CSUR), vol. 57, no. 4, pp. 101:1–101:40, 2025.
- [22] T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2302.04761.
- [23] T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V. Chawla, O. Wiest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges,” in Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), 2024, pp. 8048–8057, survey track.
- [24] C. Packer, V. Fang, S. G. Patil, K. Lin, S. Wooders, and J. E. Gonzalez, “MemGPT: Towards LLMs as operating systems,” arXiv preprint arXiv:2310.08560, 2023.
- [25] K. Hatalis, D. Christou, J. Myers, S. Jones, K. Lambert, A. AmosBinks, Z. Dannenhauer, and D. Dannenhauer, “Memory matters: The need to improve long-term memory in llm-agents,” in Proceedings of the AAAI Symposium Series (AAAI), vol. 2, no. 1, 2023, pp. 277–280.
- [26] B. Ma, Y. Jiang, X. Wang, G. Yu, Q. Wang, C. Sun, C. Li, X. Qi, Y. He, W. Ni et al., “Sok: Semantic privacy in large language models,” arXiv preprint arXiv:2506.23603, 2025.
- [27] J. White, Q. Fu, S. Hays, M. Sandborn, C. Olea, H. Gilbert, A. Elnashar, J. Spencer-Smith, and D. C. Schmidt, “A prompt pattern catalog to enhance prompt engineering with chatgpt,” arXiv preprint arXiv:2302.11382, 2023.
- [28] D. S. Nau, T.-C. Au, O. Ilghami, U. Kuter, J. W. Murdock, D. Wu, and F. Yaman, “SHOP2: An HTN planning system,” Journal of Artificial Intelligence Research, vol. 20, pp. 379–404, 2003.
- [29] A. S. Rao and M. P. Georgeff, “BDI agents: From theory to practice,” in Proceedings of the First International Conference on Multi-Agent Systems (ICMAS), 1995, pp. 312–319.
- [30] R. E. Fikes and N. J. Nilsson, “STRIPS: A new approach to the application of theorem proving to problem solving,” Artificial Intelligence, vol. 2, no. 3–4, pp. 189–208, 1971.
- [31] W. G. Chase and H. A. Simon, “Perception in chess,” Cognitive Psychology, vol. 4, no. 1, pp. 55–81, 1973.
- [32] X. Li, W. Chen, Y. Liu, S. Zheng, X. Chen, Y. He, Y. Li, B. You, H. Shen, J. Sun et al., “SkillsBench: Benchmarking how well agent skills work across diverse tasks,” arXiv preprint arXiv:2602.12670, 2026.
- [33] G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar, “Voyager: An open-ended embodied agent with large language models,” Transactions on Machine Learning Research (TMLR), 2024, arXiv:2305.16291.
- [34] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023, arXiv:2210.03629.
- [35] N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2303.11366.
- [36] Z. Wang, S. Cai, A. Liu, Y. Jin, J. Hou, B. Zhang, H. Lin, Z. He, Z. Zheng, Y. Yang, X. Ma, and Y. Liang, “JARVIS-1: Openworld multi-task agents with memory-augmented multimodal language models,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 47, no. 3, pp. 1894–1907, 2025, extended from arXiv:2311.05997.
- [37] Z. Wang, S. Cai, A. Liu, X. Ma, and Y. Liang, “Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2302.01560.
- [38] M. F. Chen, N. Roberts, K. Bhatia, J. Wang, C. Zhang, F. Sala, and C. Ré, “Skill-it! a data-driven skills framework for understanding and training language models,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2307.14430.
- [39] C. Zhang, Z. Yang, J. Liu, Y. Han, X. Chen, Z. Huang, B. Fu, and G. Yu, “AppAgent: Multimodal agents as smartphone users,” in Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI), 2025, pp. 70:1–70:20, extended from arXiv:2312.13771.
- [40] W. Tan, W. Zhang, X. Xu, H. Xia, Z. Ding, B. Li, B. Zhou et al., “Cradle: Empowering foundation agents towards general computer control,” in International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 58 658–58 725, extended from arXiv:2403.03186.
- [41] A. Zeng, M. Liu, R. Lu, B. Wang, X. Liu, Y. Dong, and J. Tang, “AgentTuning: Enabling generalized agent abilities for LLMs,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 3053–3077, arXiv:2310.12823. [42] X. Wang, Y. Chen, L. Yuan, Y. Zhang, Y. Li, H. Peng, and H. Ji, “Executable code actions elicit better LLM agents,” in International Conference on Machine Learning (ICML), 2024, arXiv:2402.01030.
- [43] B. Chen, C. Shu, E. Shareghi, N. Collier, K. Narasimhan, and S. Yao, “FireAct: Toward language agent fine-tuning,” arXiv preprint arXiv:2310.05915, 2023.
- [44] B. Qiao, L. Li, X. Zhang, S. He, Y. Kang, C. Zhang, F. Yang, H. Dong, J. Zhang, L. Wang, M. Ma, P. Zhao, S. Qin, X. Qin, C. Du, Y. Xu, Q. Lin, S. Rajmohan, and D. Zhang, “TaskWeaver: A code-first agent framework,” arXiv preprint arXiv:2311.17541, 2023.
- [45] M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gober, K. Hausman et al., “Do as i can, not as i say: Grounding language in robotic affordances,” in Conference on Robot Learning (CoRL), 2022, arXiv:2204.01691.
- [46] J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in ACM Symposium on User Interface Software and Technology (UIST), 2023, arXiv:2304.03442.
- [47] Y. J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y. Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-level reward design via coding large language models,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2310.12931.
- [48] K. Nottingham, P. Ammanabrolu, A. Suhr, Y. Choi, H. Hajishirzi, S. Singh, and R. Fox, “Do embodied agents dream of pixelated sheep: Embodied decision making using language guided world modelling,” in International Conference on Machine Learning (ICML), 2023, arXiv:2301.12050.
- [49] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar et al., “Inner monologue: Embodied reasoning through planning with language models,” in Conference on Robot Learning (CoRL), 2022, arXiv:2207.05608.
- [50] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional, 1994.
- [51] Microsoft, “Semantic Kernel: A lightweight SDK for AI agent development,” https://github.com/microsoft/semantic- kernel, 2023, accessed: 2026-02-21.
- [52] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in IEEE International Conference on Robotics and Automation (ICRA), 2023, arXiv:2209.07753.
- [53] I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “ProgPrompt: Generating situated robot task plans using large language models,” in IEEE International Conference on Robotics and Automation (ICRA), 2023, arXiv:2209.11302.
- [54] A. Zhou, K. Yan, M. Shlapentokh-Rothman, H. Wang, and Y.X. Wang, “Language agent tree search unifies reasoning, acting, and planning in language models,” in International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235, 2024, pp. 62 138–62 160, arXiv:2310.04406.
- [55] Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language models with selfgenerated instructions,” in Annual Meeting of the Association for Computational Linguistics (ACL), 2023, pp. 13 484–13 508.
- [56] C. Qian, C. Han, Y. R. Fung, Y. Qin, Z. Liu, and H. Ji, “CREATOR: Tool creation for disentangling abstract and concrete reasoning of large language models,” in Findings of the Association for Computational Linguistics (EMNLP), 2023, arXiv:2305.14318.
- [57] Anthropic, “Introducing the model context protocol,” https://www.an thropic.com/news/model-context-protocol, 2024, accessed: 2026-0221.
- [58] Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian et al., “ToolLLM: Facilitating large language models to master 16000+ real-world APIs,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2307.16789.
- [59] OpenClaw Project, “OpenClaw: Personal ai assistant,” https://gith ub.com/openclaw/openclaw, 2026, official repository (216k stars at access time). Accessed: 2026-02-22.
- [60] Alex and Oren Yomtov, “ClawHavoc: 341 malicious clawed skills found by the bot they were targeting,” https://www.koi.ai/blog/claw havoc- 341- malicious- clawedbot- skills- found- by- the- bot- they- wer e-targeting, 2026, koi Research blog post; update dated Feb 16, 2026 reports 824 malicious skills. Accessed: 2026-02-22.
- [61] X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su, “Mind2Web: Towards a generalist agent for the web,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, spotlight. arXiv:2306.06070.
- [62] T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y. Liu, Y. Xu, S. Zhou, S. Savarese, C. Xiong, V. Zhong, and T. Yu, “OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments,” in Advances in Neural Information Processing Systems (NeurIPS), 2024, datasets and Benchmarks track. arXiv:2404.07972.
- [63] C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve realworld GitHub issues?” in International Conference on Learning Representations (ICLR), 2024, arXiv:2310.06770.
- [64] H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Recent advances in robot learning from demonstration,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, pp. 297–330, 2020.
- [65] Significant Gravitas, “AutoGPT: An autonomous GPT-4 experiment,” https://github.com/Significant-Gravitas/AutoGPT, 2023, accessed: 2026-02-21.
- [66] L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: Theory, method and application,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 46, no. 8, pp. 5362–5383, 2024.
- [67] C. Zhang, K. Yang, S. Hu, Z. Wang, G. Li, Y. Sun, C. Zhang, Z. Zhang, A. Liu, S.-C. Zhu, X. Chang, J. Zhang, F. Yin, Y. Liang, and Y. Yang, “ProAgent: Building proactive cooperative agents with large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 38, no. 16, 2024, pp. 17 59117 599, arXiv:2308.11339.
- [68] P. Ladisa, H. Plate, M. Martinez, and O. Barais, “SoK: Taxonomy of attacks on open-source software supply chains,” in IEEE Symposium on Security and Privacy (SP), 2023, pp. 1509–1526.
- [69] K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising realworld LLM-integrated applications with indirect prompt injection,” in ACM Workshop on Artificial Intelligence and Security (AISec), 2023, arXiv:2302.12173.
- [70] B. Quintero, “From automation to infection: How OpenClaw AI agent skills are being weaponized,” https://blog.virustotal.com/2026/0 2/from-automation-to-infection-how.html, 2026, virusTotal Blog, February 2, 2026. Accessed: 2026-02-22.
- [71] B. Van, “Agent skills guard,” https://github.com/brucevanfdm/agent -skills-guard, 2026, desktop scanner/manager; README reports 8 risk categories and 22 hard-trigger rules. Accessed: 2026-02-22.
- [72] G. Singh, “SkillGuard: AI agent security scanner,” https://skillgaurd .up.railway.app/, 2026, website and linked source repo describe AST analysis for JS/TS, 9-language coverage, and 20+ attack patterns. Accessed: 2026-02-22.
- [73] Y. Liu, G. Deng, Z. Xu, Y. Li, Y. Zheng, Y. Zhang, L. Zhao, T. Zhang, K. Wang, and Y. Liu, “Jailbreaking chatgpt via prompt engineering: An empirical study,” arXiv preprint arXiv:2305.13860, 2023.
- [74] G. Mialon, C. Fourrier, T. Wolf, Y. LeCun, and T. Scialom, “GAIA: A benchmark for general AI assistants,” in International Conference on Learning Representations (ICLR), 2024, poster. arXiv:2311.12983.
- [75] X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y. Su, H. Sun, M. Huang, Y. Dong, and J. Tang, “AgentBench: Evaluating LLMs as agents,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2308.03688.
- [76] C. Rawles, S. Clinckemaillie, Y. Chang, J. Waltz, G. Lau, M. Fair, A. Li, W. E. Bishop, W. Li, F. Campbell-Ajala, D. K. Toyama, R. J. Berry, D. Tyamagundlu, T. P. Lillicrap, and O. Riva, “AndroidWorld: A dynamic benchmarking environment for autonomous agents,” in International Conference on Learning Representations (ICLR), 2025, arXiv:2405.14573.

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)