
【Code with SOLO 续篇】集成 ooderAgent SceneEngine 3.0.3 — 一句话引入,商业级 LLM 能力即刻可用
是 ooder.cn 开源平台推出的轻量级场景引擎,专为 Java 应用快速集成 LLM 能力而设计。当前最新版本为3.0.3,采用 MIT 开源协议。让 Java 应用一句话引入 LLM 能力,无需从零搭建对话管理、工具编排、检索增强等基础设施。SkillFlow 是 BPM Designer 的核心理念 —— 将传统的 BPM 流程设计与 AI 的 Skills 能力结合,通过自然语言对话生成
上篇我们用 SOLO 在 2 小时内完成了 18,928 行代码的 BPM 流程设计器。本篇重点介绍如何通过集成 ooder.cn SceneEngine 3.0.3(MIT 开源),为 APD 项目快速赋予多轮对话、上下文管理、Function Calling 等商业级 LLM 能力。
1. SceneEngine 3.0.3 — ooderAgent 轻量级场景引擎
1.1 什么是 SceneEngine
SceneEngine 是 ooder.cn 开源平台推出的轻量级场景引擎,专为 Java 应用快速集成 LLM 能力而设计。当前最新版本为 3.0.3,采用 MIT 开源协议。
它的核心理念是:让 Java 应用一句话引入 LLM 能力,无需从零搭建对话管理、工具编排、检索增强等基础设施。
SceneEngine 提供了企业级 LLM 应用所需的全部核心模块:

1.2 一句话引入,直接使用
SceneEngine 3.0.3 已托管在 Maven 中央仓库,只需在 pom.xml 中添加一行依赖,即可在项目中使用全部能力:
<dependency>
<groupId>net.ooder</groupId>
<artifactId>scene-engine</artifactId>
<version>3.0.3</version>
</dependency>
没有繁琐的 SDK 安装、没有复杂的配置文件、没有外部服务依赖。引入依赖后,SceneEngine 的所有模块即刻可用。
技术栈要求极低:Java 8+、Maven 3.6+,与 Spring Boot 无缝集成。支持从单机 SQLite 到分布式 Milvus 的弹性部署架构。
1.3 为什么选择 SceneEngine
在为 APD 项目选择 LLM 集成方案时,我们对比了三种路径:
| 方案 | 多轮对话 | Function Calling | RAG | 集成工作量 | 维护成本 |
|---|---|---|---|---|---|
| 直接调用 LLM API | 需自行实现 | 需自行实现 | 需自行实现 | 中 | 高 |
| 自建 LLM 中间层 | 需自行实现 | 需自行实现 | 需自行实现 | 高(约 2 人周) | 高 |
| SceneEngine 3.0.3 | 内置 | 内置 | 内置 | 极低(1 行依赖) | 低(社区维护) |
选择 SceneEngine 的理由很简单:它把 LLM 商业级应用的核心能力封装好了,我们只需要"接上管子"。
2. APD 项目中的 SceneEngine 集成
2.1 集成架构
在 APD(AI Process Designer)项目中,我们利用 SceneEngine 3.0.3 的以下核心能力:
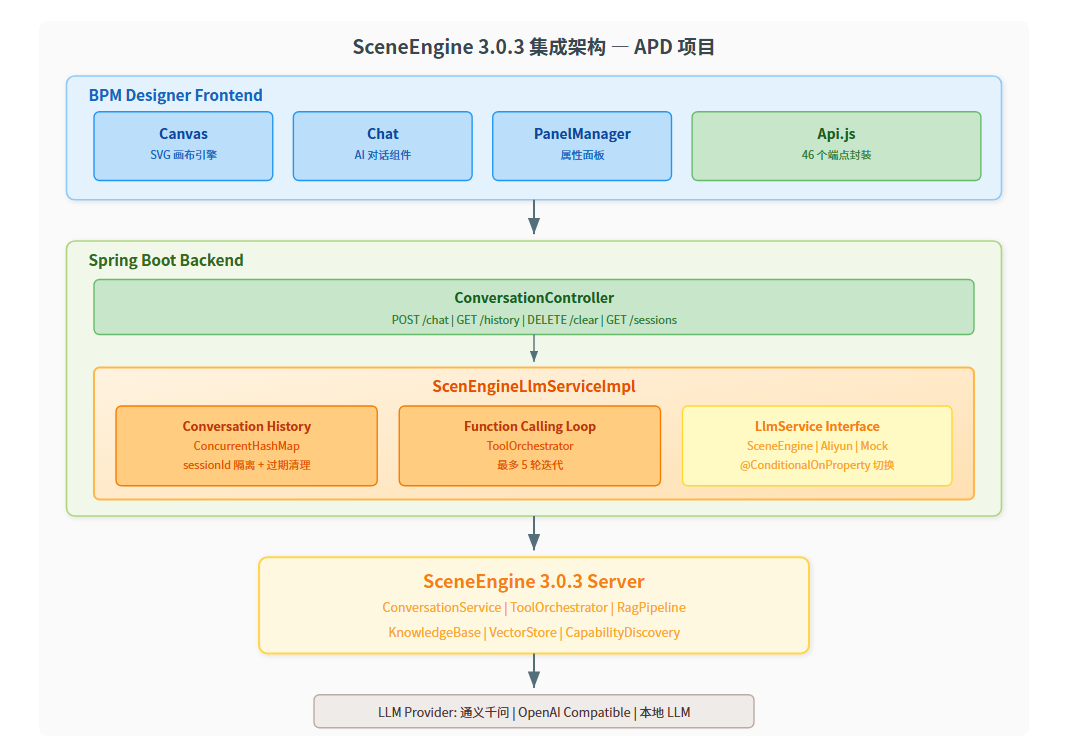
关键设计决策:
- ScenEngineLlmServiceImpl 实现 LlmService 接口 — 与 AliyunLlmServiceImpl、MockLlmServiceImpl 平级,通过
@ConditionalOnProperty切换 - ConcurrentHashMap 会话上下文管理 — 线程安全的 sessionId → 消息历史映射
- Function Calling 循环执行 — 检测到函数调用后自动执行,最多 5 轮迭代
- 会话过期自动清理 — 可配置超时时间,避免内存泄漏
2.2 利用 SceneEngine 的核心能力
在 APD 项目中,我们深度利用了 SceneEngine 3.0.3 的以下能力:
ConversationService — 多轮对话管理
通过 SceneEngine 的会话管理能力,APD 的 AI 对话功能支持:
- 用户不需要一次性描述完所有需求,AI 通过多轮追问补全信息
- 每个会话通过 sessionId 隔离,不同用户的对话互不干扰
- 历史消息自动维护,支持滑动窗口控制上下文长度
- 会话超时自动清理,避免内存泄漏
ToolOrchestrator — Function Calling 工具编排
我们定义了 14 个 BPM 专用函数(DesignerFunctionDefinition),通过 SceneEngine 的 ToolOrchestrator 自动编排:
| 领域 | 函数数量 | 示例函数 |
|---|---|---|
| 执行者推导 | 5 | search_performers_by_role、get_performer_workload |
| 能力匹配 | 5 | match_capability_by_requirement、test_capability |
| 表单匹配 | 4 | match_form_by_fields、get_form_preview |
AI 理解用户需求后,自动调用这些函数获取执行者推荐、能力匹配和表单设计信息。
RAG Pipeline — 检索增强(预留)
SceneEngine 的 RAG Pipeline 能力为后续集成预留了接口。计划上传企业历史流程定义和最佳实践文档,AI 在设计新流程时自动参考已有模式。
2.3 核心代码展示
ScenEngineLlmServiceImpl — 多轮对话核心方法
@Service
@ConditionalOnProperty(prefix = "scenengine", name = "enabled", havingValue = "true")
public class ScenEngineLlmServiceImpl implements LlmService {
private final RestTemplate restTemplate;
private final ScenEngineConfig scenEngineConfig;
// 会话上下文管理 - sessionId -> 消息历史
private final Map<String, List<Map<String, String>>> conversationHistory
= new ConcurrentHashMap<>();
// 会话超时管理 - sessionId -> 最后活跃时间
private final Map<String, Long> sessionLastActive = new ConcurrentHashMap<>();
/**
* 带会话上下文的多轮对话
*/
public String chatWithFunctionsAndContext(String sessionId, String userMessage,
String systemPrompt,
List<Map<String, Object>> functions) {
// 初始化会话历史
List<Map<String, String>> history = conversationHistory
.computeIfAbsent(sessionId, k -> new ArrayList<>());
// 清理过期会话
cleanupExpiredSessions();
// 构建消息列表(包含历史上下文)
List<Map<String, String>> messages = new ArrayList<>();
// 系统提示
if (systemPrompt != null && !systemPrompt.isBlank()) {
messages.add(Map.of("role", "system", "content", systemPrompt));
}
// 添加历史消息(受 maxHistory 限制)
int maxHistory = scenEngineConfig.getConversation().getMaxHistory();
int startIdx = Math.max(0, history.size() - maxHistory * 2);
for (int i = startIdx; i < history.size(); i++) {
messages.add(history.get(i));
}
// 添加当前用户消息
messages.add(Map.of("role", "user", "content", userMessage));
// 调用 SceneEngine API
// ... (HTTP 调用逻辑)
// 保存到会话历史
history.add(Map.of("role", "user", "content", userMessage));
history.add(Map.of("role", "assistant", "content", content));
sessionLastActive.put(sessionId, System.currentTimeMillis());
// 检查是否为 Function Call 响应
if (isFunctionCallResponse(responseBody)) {
return handleFunctionCall(sessionId, responseBody, functions);
}
return content;
}
}
Function Calling 循环执行逻辑
/**
* 执行 Function Calling 循环
*/
public String executeFunctionCallingLoop(String sessionId, String userMessage,
String systemPrompt,
List<Map<String, Object>> functions,
FunctionExecutor functionExecutor) {
String currentMessage = userMessage;
int maxIterations = 5; // 防止无限循环
int iteration = 0;
while (iteration < maxIterations) {
iteration++;
String response = chatWithFunctionsAndContext(
sessionId, currentMessage, systemPrompt, functions);
// 检查是否需要执行函数
Map<String, Object> functionCall = parseFunctionCall(response);
if (functionCall == null) {
return response; // 没有函数调用,返回最终响应
}
// 执行函数
String functionName = (String) functionCall.get("name");
Map<String, Object> arguments =
(Map<String, Object>) functionCall.get("arguments");
log.info("[SceneEngine] Executing function: {} with args: {}",
functionName, arguments);
String functionResult;
try {
functionResult = functionExecutor.execute(functionName, arguments);
} catch (Exception e) {
functionResult = "{\"error\": \"" + e.getMessage() + "\"}";
}
// 将函数结果作为下一轮输入
currentMessage = "函数 " + functionName + " 的执行结果: "
+ functionResult + "\n请基于以上结果继续回答。";
}
log.warn("[SceneEngine] Function calling loop reached max iterations");
return chatWithFunctionsAndContext(sessionId, currentMessage,
systemPrompt, null);
}
ConversationController — 多轮对话 REST API
@RestController
@RequestMapping("/api/bpm/conversation")
@ConditionalOnProperty(prefix = "scenengine", name = "enabled", havingValue = "true")
public class ConversationController {
@Autowired(required = false)
private ScenEngineLlmServiceImpl scenEngineLlmService;
/** 发送多轮对话消息 */
@PostMapping("/chat")
public ApiResponse<Map<String, Object>> chat(
@RequestBody Map<String, Object> body) {
String sessionId = (String) body.getOrDefault("sessionId", "default");
String message = (String) body.get("message");
String response = scenEngineLlmService
.chatWithFunctionsAndContext(sessionId, message, systemPrompt, null);
Map<String, Object> result = new LinkedHashMap<>();
result.put("sessionId", sessionId);
result.put("response", response);
result.put("history",
scenEngineLlmService.getConversationHistory(sessionId));
return ApiResponse.success(result);
}
/** 获取会话历史 */
@GetMapping("/history/{sessionId}")
public ApiResponse<List<Map<String, String>>> getHistory(
@PathVariable String sessionId) { ... }
/** 清除会话历史 */
@DeleteMapping("/history/{sessionId}")
public ApiResponse<Void> clearHistory(
@PathVariable String sessionId) { ... }
/** 获取活跃会话列表 */
@GetMapping("/sessions")
public ApiResponse<Set<String>> getActiveSessions() { ... }
}
2.4 配置化集成
SceneEngine 的集成完全通过配置驱动,一行配置即可启用:
# application.yml
scenengine:
enabled: ${SCENENGINE_ENABLED:false}
endpoint: ${SCENENGINE_ENDPOINT:http://localhost:9090}
api-key: ${SCENENGINE_API_KEY:}
conversation:
max-history: 20
timeout: 30000
通过 @ConditionalOnProperty 注解,当 scenengine.enabled=true 时,ScenEngineLlmServiceImpl 和 ConversationController 自动激活;否则系统回退到 AliyunLlmServiceImpl 或 MockLlmServiceImpl。
这种设计实现了 三模式 LLM 提供商切换:
# 模式 1:Mock(开发调试,零外部依赖)
# 默认模式,无需任何配置
# 模式 2:阿里云 DashScope(直连)
LLM_ENABLED=true LLM_API_KEY=sk-xxx
# 模式 3:SceneEngine(商业级,推荐生产环境)
SCENENGINE_ENABLED=true SCENENGINE_ENDPOINT=http://localhost:9090
3. SkillFlow 可视化定义:从对话到流程
3.1 什么是 SkillFlow
SkillFlow 是 BPM Designer 的核心理念 —— 将传统的 BPM 流程设计与 AI 的 Skills 能力结合,通过自然语言对话生成可视化的业务流程定义。
传统的 BPM 流程设计器需要用户手动拖拽节点、连线、配置属性。SkillFlow 的目标是让用户通过自然语言描述业务需求,AI 自动理解需求并生成完整的流程定义。
传统方式:用户 → 手动拖拽 → 配置属性 → 连线 → 调试
SkillFlow:用户 → 自然语言描述 → AI 理解 → 自动生成 → 可视化编辑
3.2 SceneEngine 如何赋能 SkillFlow
SceneEngine 在 SkillFlow 中扮演了"大脑"的角色:
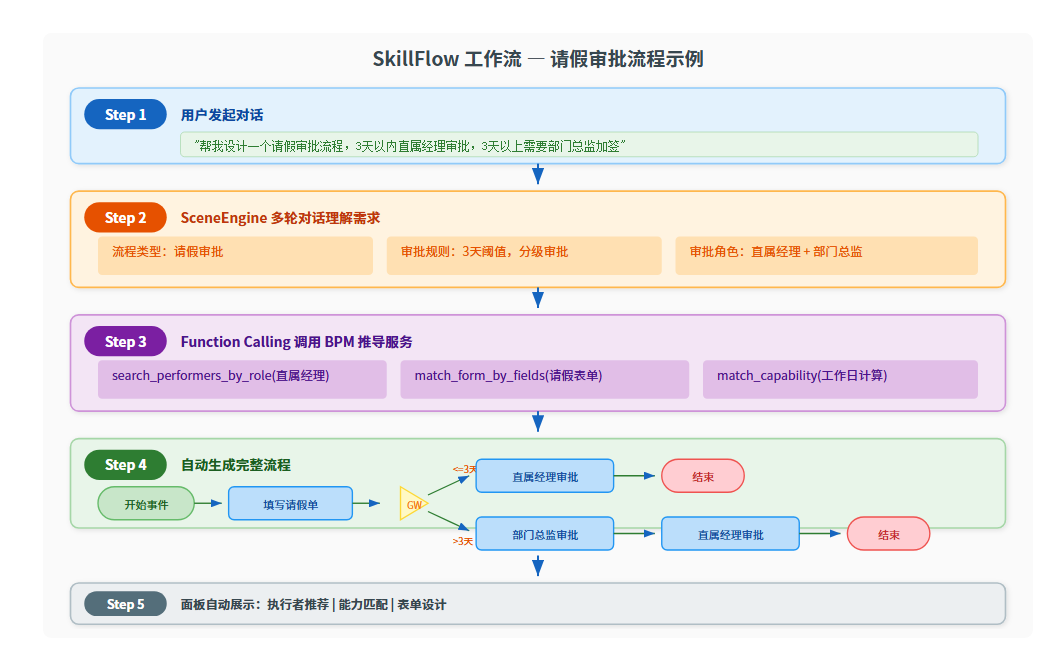
多轮对话理解业务需求
用户不需要一次性描述完所有需求。SceneEngine 的 ConversationService 支持多轮对话,AI 会通过追问来补全信息:
用户:帮我设计一个请假审批流程
AI:好的,请问这是哪种类型的请假?(事假/病假/年假/婚假...)
用户:主要是事假和年假
AI:请问审批流程需要几级审批?是否需要部门经理和 HR?
用户:3天以内直属经理审批,3天以上需要部门总监加签
AI:明白了,我来为您生成流程...
Function Calling 自动映射到 BPM 节点类型
我们定义了 14 个 BPM 专用函数(DesignerFunctionDefinition),覆盖三大领域。当 AI 理解用户需求后,会自动调用这些函数来获取执行者推荐、能力匹配和表单设计信息。
上下文管理保持流程设计的一致性
在多轮对话中,SceneEngine 自动维护会话上下文。用户可以在设计过程中随时修改之前的决策,AI 会基于完整上下文进行增量更新,而不是从头重新生成。
推导服务自动填充节点属性
通过 Function Calling 调用后端推导服务,自动为每个流程节点填充:
- 执行者推荐:根据角色和部门智能推荐审批人
- 能力匹配:根据任务需求匹配最合适的服务能力
- 表单设计:根据业务场景推荐表单字段和布局
3.3 实际场景演示
以"请假审批流程"为例,完整的 SkillFlow 工作流如下:
4. 技术对比:有 SceneEngine vs 无 SceneEngine
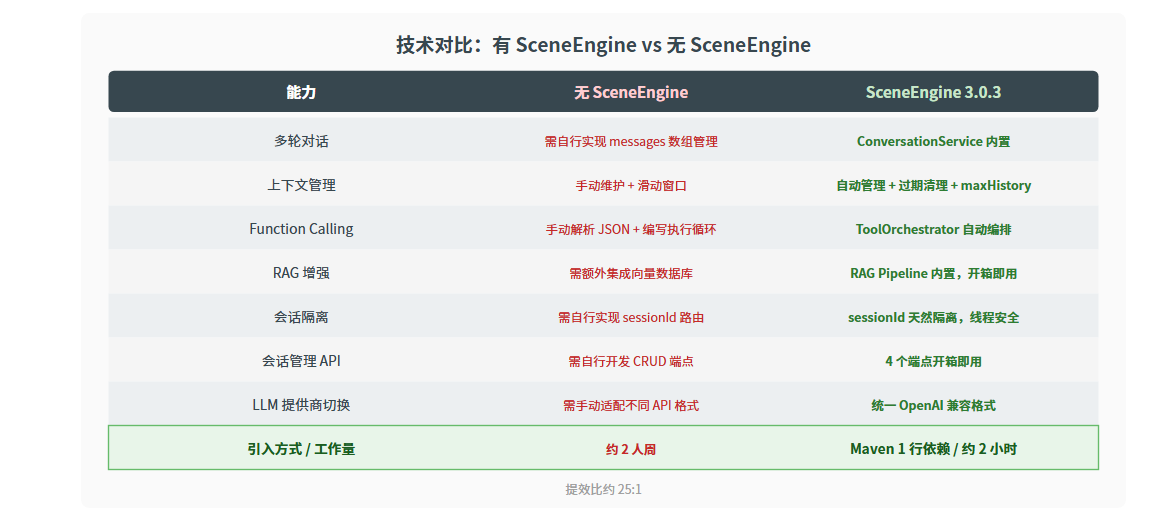
核心结论:SceneEngine 把 LLM 商业级应用的"最后一公里"问题解决了。不需要自己造轮子,专注于业务逻辑即可。
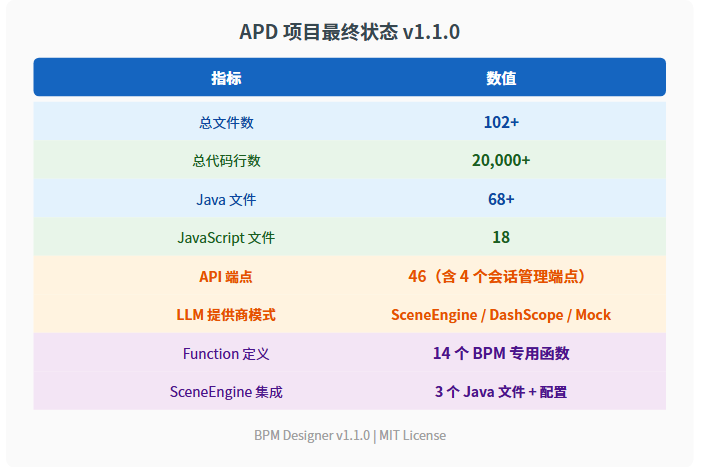
5. 成果总结
项目最终状态
关键收获
1. SceneEngine 的"一句话引入"极大降低了 LLM 集成门槛
从决定集成到完成,只用了约 2 小时(含 SOLO 辅助编码)。SceneEngine 的 @ConditionalOnProperty 设计让集成代码与现有系统完全解耦,不启用时零开销。
2. 轻量级不等于功能弱
SceneEngine 虽然定位为"轻量级场景引擎",但提供了从对话管理到工具编排再到 RAG 增强的全栈 LLM 能力。对于 APD 这样的中型项目来说,SceneEngine 的能力覆盖度已经完全够用。
3. SOLO 的并行子 Agent 能力让集成任务可在 1 轮对话中完成
SceneEngine 的集成(3 个 Java 文件 + 配置 + 前端 API)没有分多轮对话逐步完成,而是通过并行子 Agent 在 1 轮对话中一次性处理。
4. SkillFlow = BPM + AI Skills,是流程设计器的未来方向
传统的 BPM 流程设计器已经发展了 20+ 年,但用户体验几乎没有本质提升。SkillFlow 通过将 AI 的自然语言理解能力与 BPM 的流程建模能力结合,让流程设计从"画图"变成了"对话"。
6. 展望
SceneEngine 3.0.3 的集成为 BPM Designer 打开了新的可能性。接下来我们计划:
-
SceneEngine RAG Pipeline 深度集成 — 基于企业知识库的流程设计推荐。上传历史流程定义和最佳实践文档,AI 在设计新流程时自动参考已有模式。
-
SkillFlow 模板市场 — 共享和复用流程设计模式。用户可以将自己设计的流程保存为模板,其他用户通过自然语言搜索和复用。
-
多人协作编辑 — 基于 WebSocket + CRDT 的实时协作。多个用户同时编辑同一个流程定义,支持冲突自动合并。
-
流程仿真与执行引擎 — 从"设计"到"运行"的闭环。在 SceneEngine 的 ToolOrchestrator 编排下,流程定义可以直接驱动业务执行。
项目地址:ooderCN/ade
SceneEngine 3.0.3:Maven 中央仓库 —
net.ooder:scene-engine:3.0.3(MIT License)作者:ooder | 发布于 TRAE 论坛

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 6
6 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)