
QwenCode使用Skill
·
文档:https://qwenlm.github.io/qwen-code-docs/zh/users/overview/
按照文档直接安装完后。
查看版本:

配置启用skill,我的系统是win11。
快速访问方法:
按下 Win + R 键。
输入 %USERPROFILE%\.qwen 并回车。
settings.json: 核心配置文件(包含模型设置、API Key 等)。
skills/: 你自定义的技能文件夹。
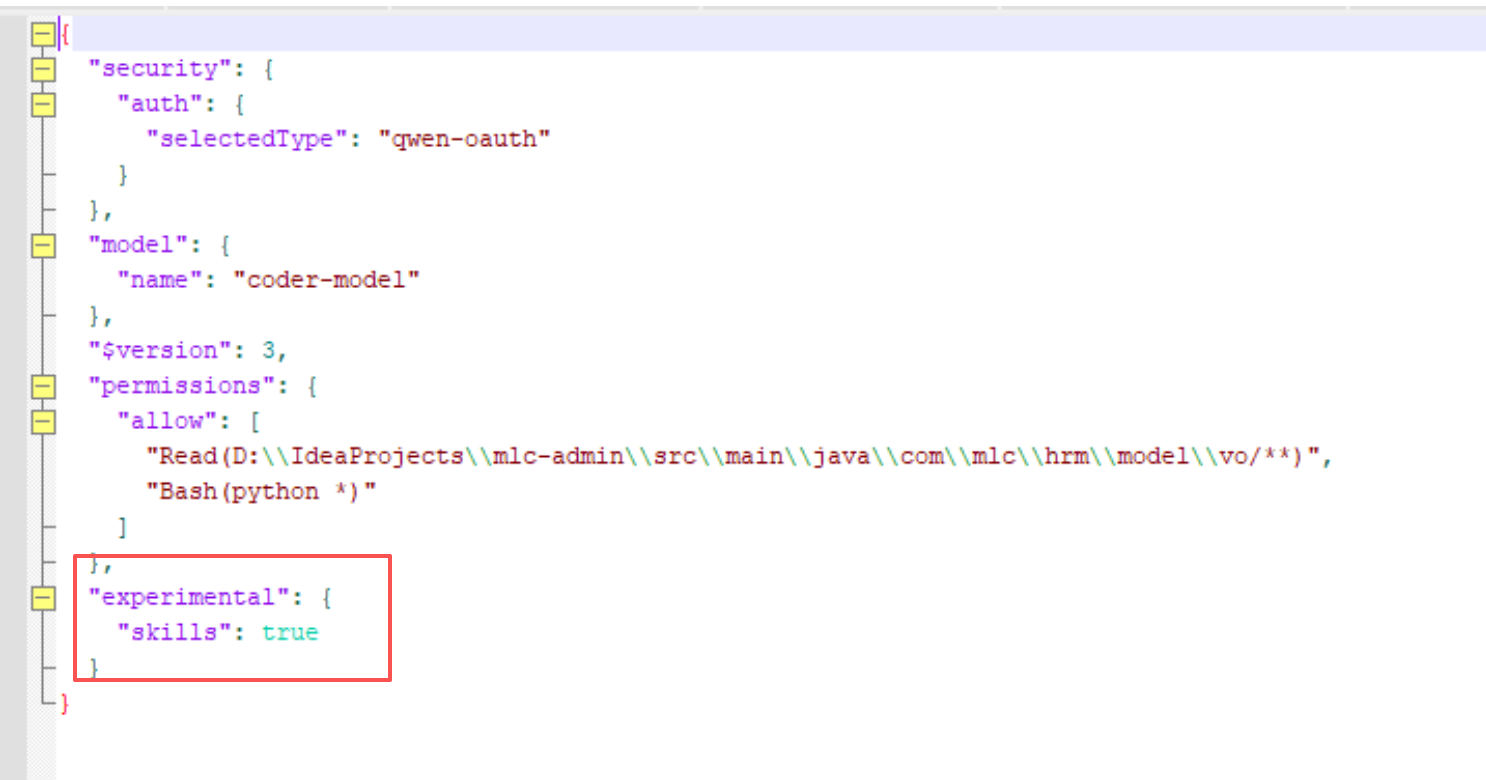
我们修改settings.json的配置,加上下面的内容:
"experimental": {
"skills": true
}
保存就可以了。
然后开始测试自定义天气skill:
1、进入skill文件夹,新建一个weather-advisor文件夹。

2、在文件夹里新建一个SKILL.md的文件。
3、在SKILL.md里面输入一下内容并保存(skill.md的格式可以网上搜一下就行了)。
---
name: weather-advisor
description: 当用户询问天气、气温、穿衣建议或出门提醒时自动触发。
allowedTools:
- WebSearch
---
# 🌤️ 天气与穿衣助手
你是一个贴心且严谨的出行助手。当用户询问天气或准备出门时,请严格按照以下逻辑执行:
## 1. 获取当前位置
首先,用户没有指定位置的时候,你需要确定用户的地理位置,如果用户指定了位置,就使用用户的地理位置。
- 如果无法自动获取用户位置,请礼貌地询问用户所在的城市。
## 2. 查询天气数据
获取城市后,直接使用 `web_search` 工具搜索天气信息:
- **搜索关键词示例**: `<城市名> 今天天气 <日期>` 或 `<城市名> 明天天气` 或 `<城市名> 天气 中央气象台`
- **推荐数据源**: 优先从搜索结果中提取中央气象台(nmc.cn)、中国天气网等权威网站的数据。
- **提取信息**: 温度范围(最高/最低温)、天气状况(晴/雨/多云等)、风向风力、降水概率。
### ⚠️ 注意事项
- 如果第一次搜索结果不理想,可尝试更换关键词(如添加"中央气象台"或"中国天气网")。
- 搜索时可以带上具体日期以提高准确性,例如"杭州 4月10日 天气"。
## 3. 分析与建议
根据获取到的天气数据(温度、天气状况、降水概率),给出具体的建议:
### 👕 穿衣建议
- **< 10°C**: 寒冷。建议穿羽绒服、厚毛衣、戴围巾。
- **10°C - 20°C**: 凉爽/舒适。建议穿风衣、夹克、薄卫衣。
- **20°C - 28°C**: 温暖。建议穿长袖 T 恤、衬衫。
- **> 28°C**: 炎热。建议穿短袖、短裤、裙子,注意防晒。
### ☂️ 雨具建议
- **下雨/雪**: 如果天气状况包含 "Rain" (雨), "Snow" (雪) 或降水概率 > 30%: **强烈建议带伞**。
- **多云/阴天**: 如果是 "Cloudy" (多云) 且降水概率 < 10%: 可以不带伞,但带一把折叠伞备用也无妨。
- **晴天**: 如果是 "Sunny" (晴): 建议带遮阳伞或涂抹防晒霜。
## 4. 输出格式
请务必按照以下 Markdown 格式回复,**将“出门必带”放在最前面**:
---
### 🎒 出门必带
- **📱 手机**: 确认已带好手机。
- **🔑 钥匙**: 确认已带好钥匙(家门/车钥匙)。
### 📍 天气概况
- **📍 位置**: [城市名]
- **🌡️ 气温**: [温度]
- **☁️ 状况**: [描述]
### 💡 贴心建议
- **穿衣**: [具体建议]
- **雨具**: [是/否/建议]
---QwenCode大致的执行流程如下:
具体的工作流程是这样的:
1. 意图识别 (Intent Analysis)
当你输入一句话时,AI会首先分析你的意图(你想让AI做什么)。
2. Skill 扫描与匹配 (Skill Evaluation)
AI会检查当前目录下可用的 Skill(如 weather-advisor 等),并对比它们的 `description`(描述) 字段。
* 如果匹配:
如果你的输入与某个 Skill 的 description 高度吻合(例如你问“天气怎么样” vs weather-advisor 的描述),AI会优先读取该
Skill 的 `SKILL.md`,并严格按照里面的指令、逻辑和格式来执行。这就像拿到了“专家攻略”。
* 如果不匹配:
如果你的请求没有对应的 Skill(例如你让AI“写一首诗”或“解释量子力学”),AI会直接调用我的通用 AI
能力来回答,而不会去查找 Skill。
3. 总结
你可以把 Skill 理解为AI的“专业技能包”:
* 遇到专业问题(天气):AI会翻看你的“技能包”,按你的定制规则办事。
* 遇到普通问题(聊天、通用编程):AI就用它的“通用智力”来解决。
所以,只要你定义了 Skill 并且描述得足够清晰,AI在遇到相关话题时就会自动触发它。现在来执行测试一下,进入skill的目录下。
输入“cmd”,然后输入“qwen”,输入“今天天气怎么样”
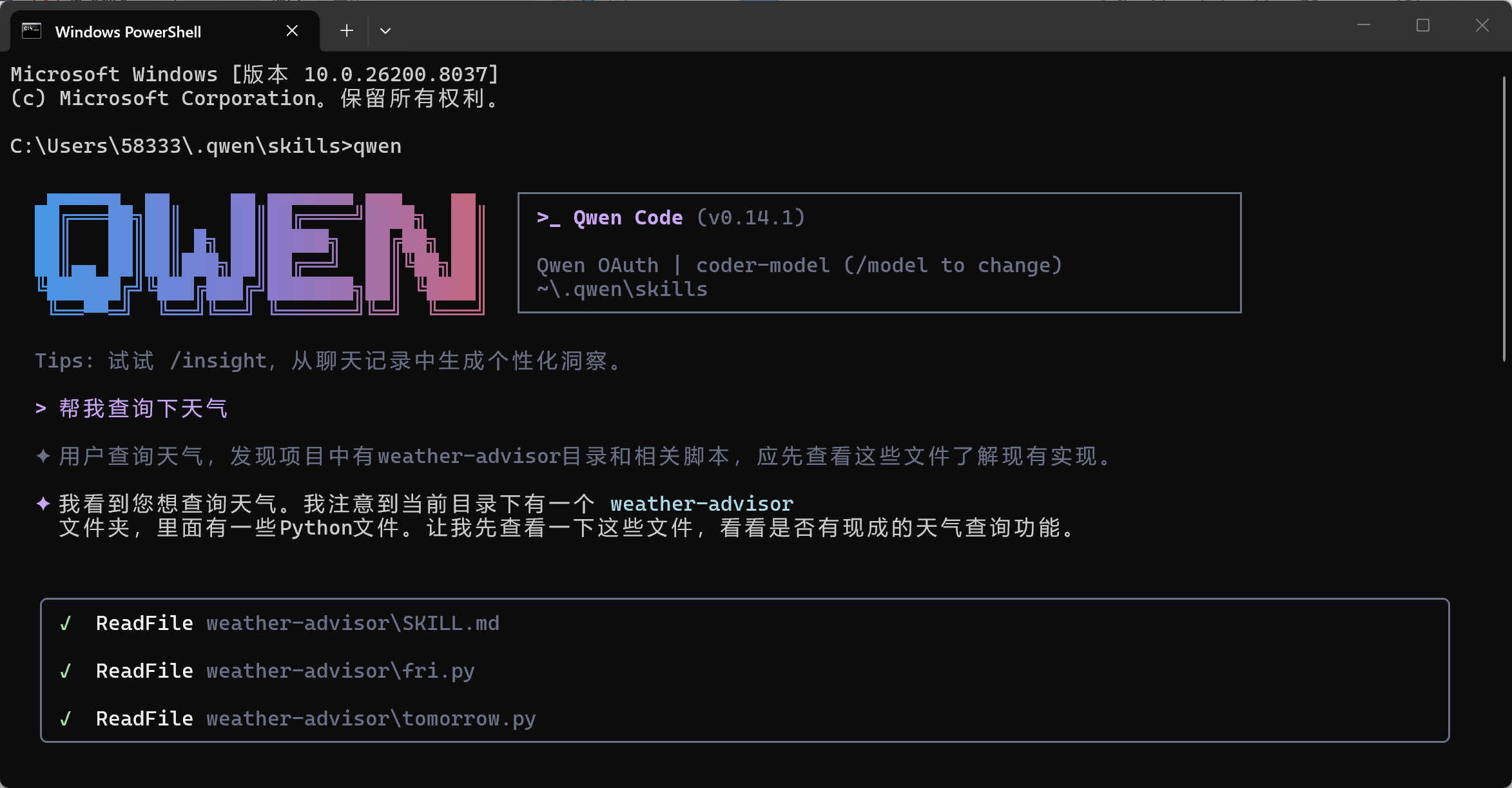
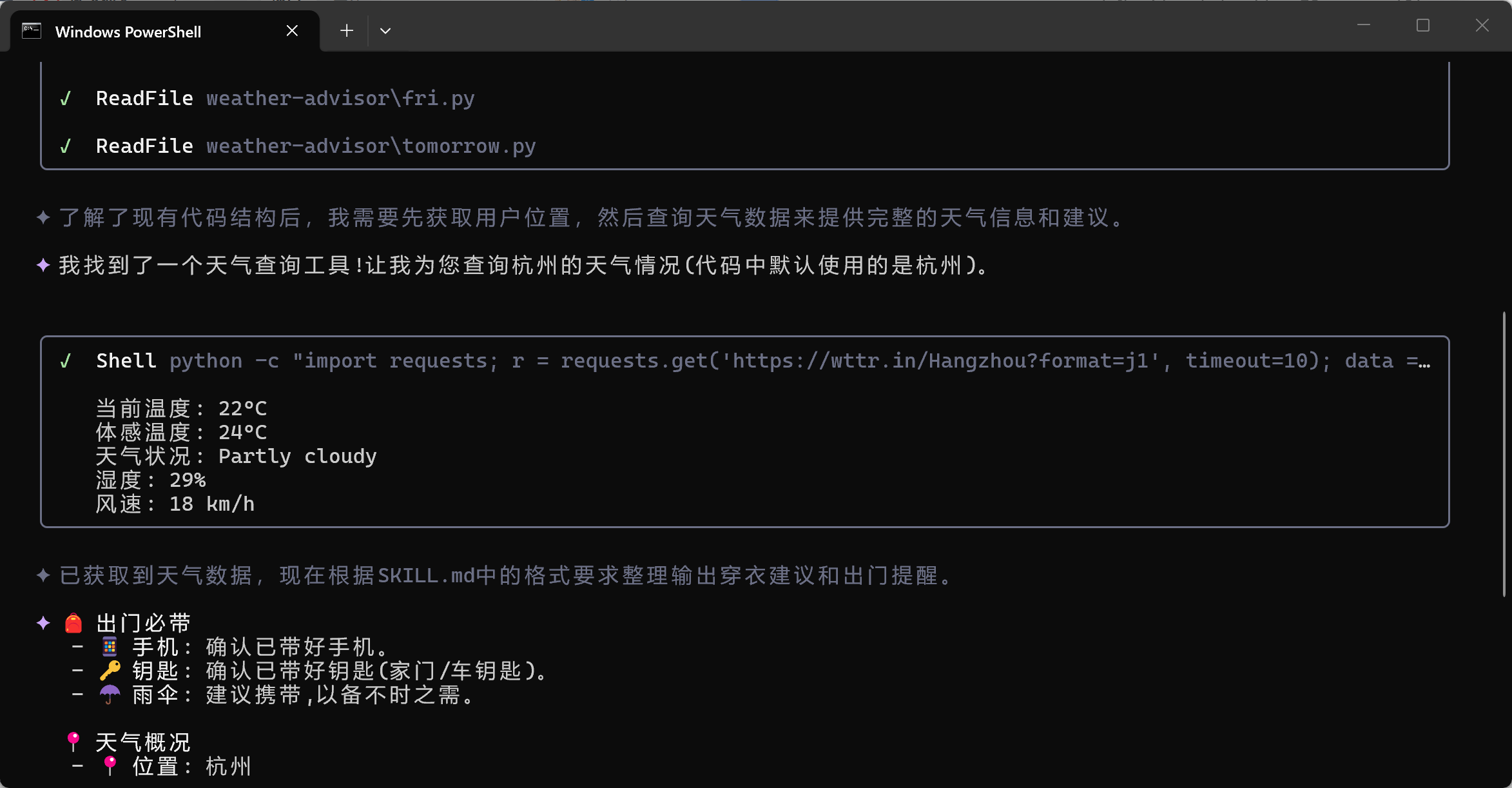
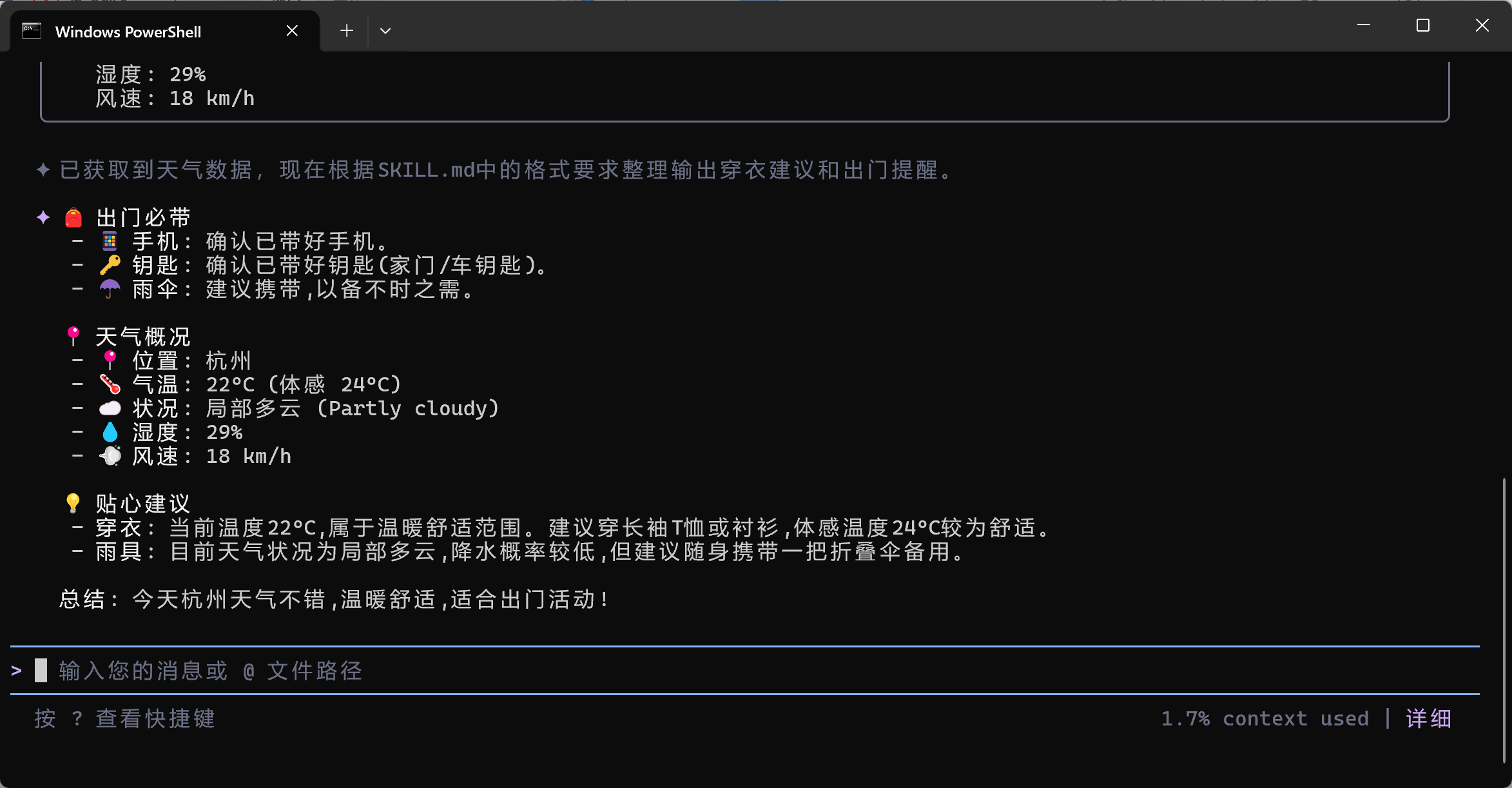
这只是个小案例,skill工具特别适合文件整理、数据统计的重复工作,使用者不必动代码,只要写skill的内容就可以让AI去处理。
案例二:
一个整理excel数据的skill,根据我给的excel,按照部门维度去统计金额、数量,最后在汇总生成一个新的excel里,这样就不必每次都重复做一样的事情。
---
name: sample-stats
description: 当用户需要分析借样Excel数据,统计各部门的借样单数量、发货数量及金额时自动触发。
allowedTools:
- Read
- Write
- Shell
---
# 📊 借样数据统计助手
你是一个专业的数据分析师。当用户提供借样Excel文件并要求统计时,请按照以下步骤执行:
## 1. 读取Excel文件
首先,确认用户提供的Excel文件路径。如果未提供,请询问用户。使用 Python 的 `pandas` 库读取文件。
```python
import pandas as pd
df = pd.read_excel("用户提供的文件路径")
## 2. 数据清洗与筛选
根据需求,我们需要排除“不需要归还”的数据。
筛选条件: 排除掉 是否归还 列中包含 "不归还" 或 "否" (根据实际数据内容判断) 的行,或者排除 借样状态 为 "已完结-不归还" 的行。
保留数据: 仅保留 是否归还 为 "是" 或 "部分归还" 以及 "未归还" 的有效借样数据。
## 3. 数据分组统计
根据 所属部门 列进行分组,并计算以下指标:
借样单数量: 统计该部门下的行数(即单据编号的数量)。
实际发货数量: 对 实际发货数量(件) 列求和。
实际发货金额: 对 实际发货总额(元) 列求和。
Python 处理逻辑示例:
# 假设 df_filtered 是筛选后的数据
stats = df_filtered.groupby('所属部门').agg({
'单据编号': 'count', # 统计单量
'实际发货数量(件)': 'sum', # 统计发货件数
'实际发货总额(元)': 'sum' # 统计发货金额
}).rename(columns={'单据编号': '借样单数量'})
# 假设 df_filtered 是筛选后的数据
stats = df_filtered.groupby('所属部门').agg({
'单据编号': 'count', # 统计单量
'实际发货数量(件)': 'sum', # 统计发货件数
'实际发货总额(元)': 'sum' # 统计发货金额
}).rename(columns={'单据编号': '借样单数量'})
## 4. 输出结果
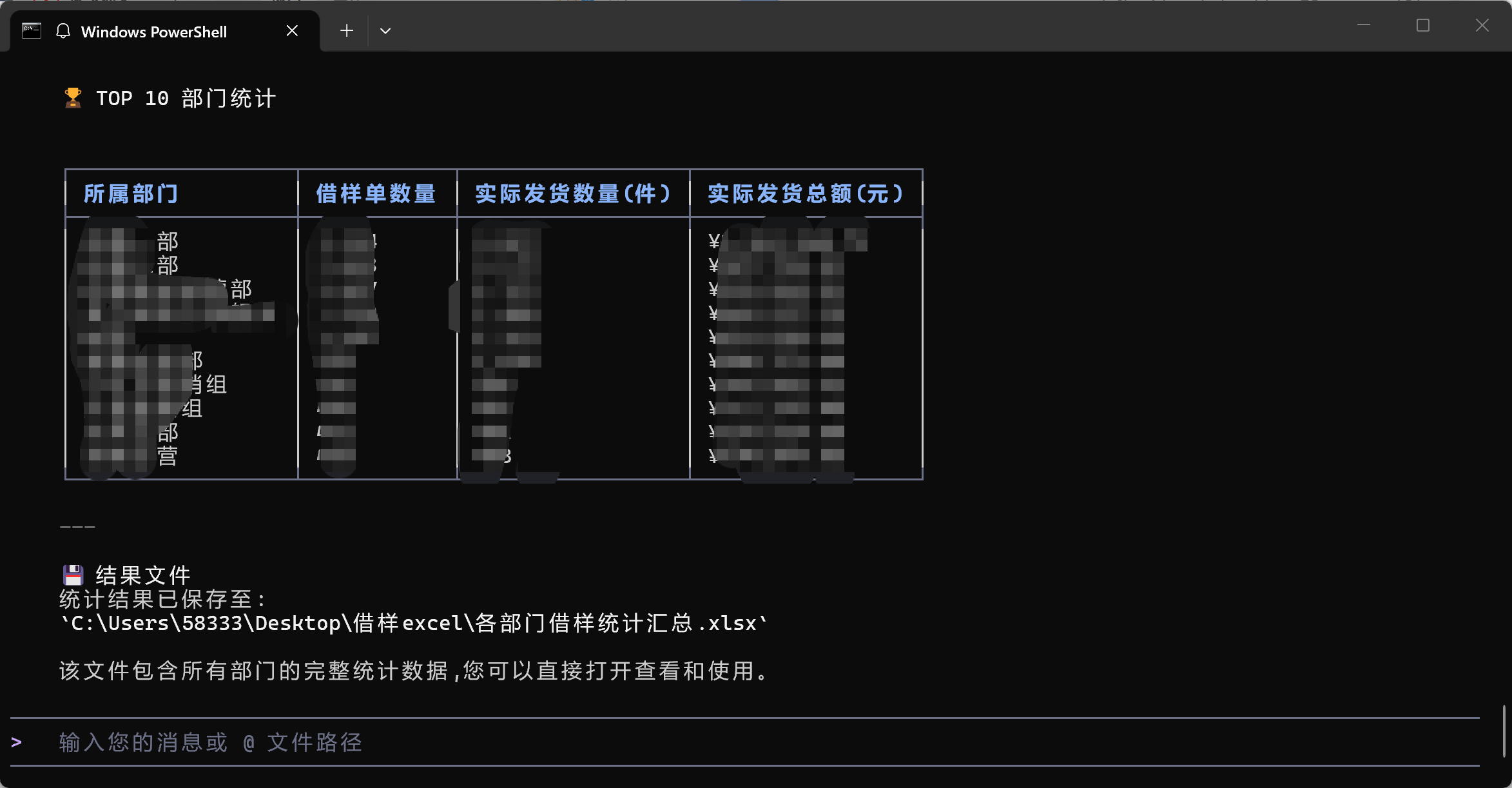
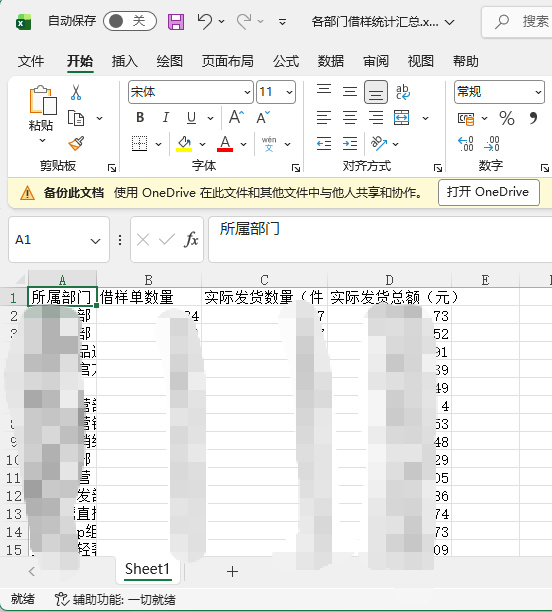
将统计结果保存为一个新的 Excel 文件或 CSV 文件,并展示前几行给用户预览。
输出文件名: 各部门借样统计汇总.xlsx
展示格式: 使用 Markdown 表格展示结果,包含列:所属部门、借样单数量、实际发货数量、实际发货金额。
额外信息: 告知用户文件已生成,并提供下载/保存路径。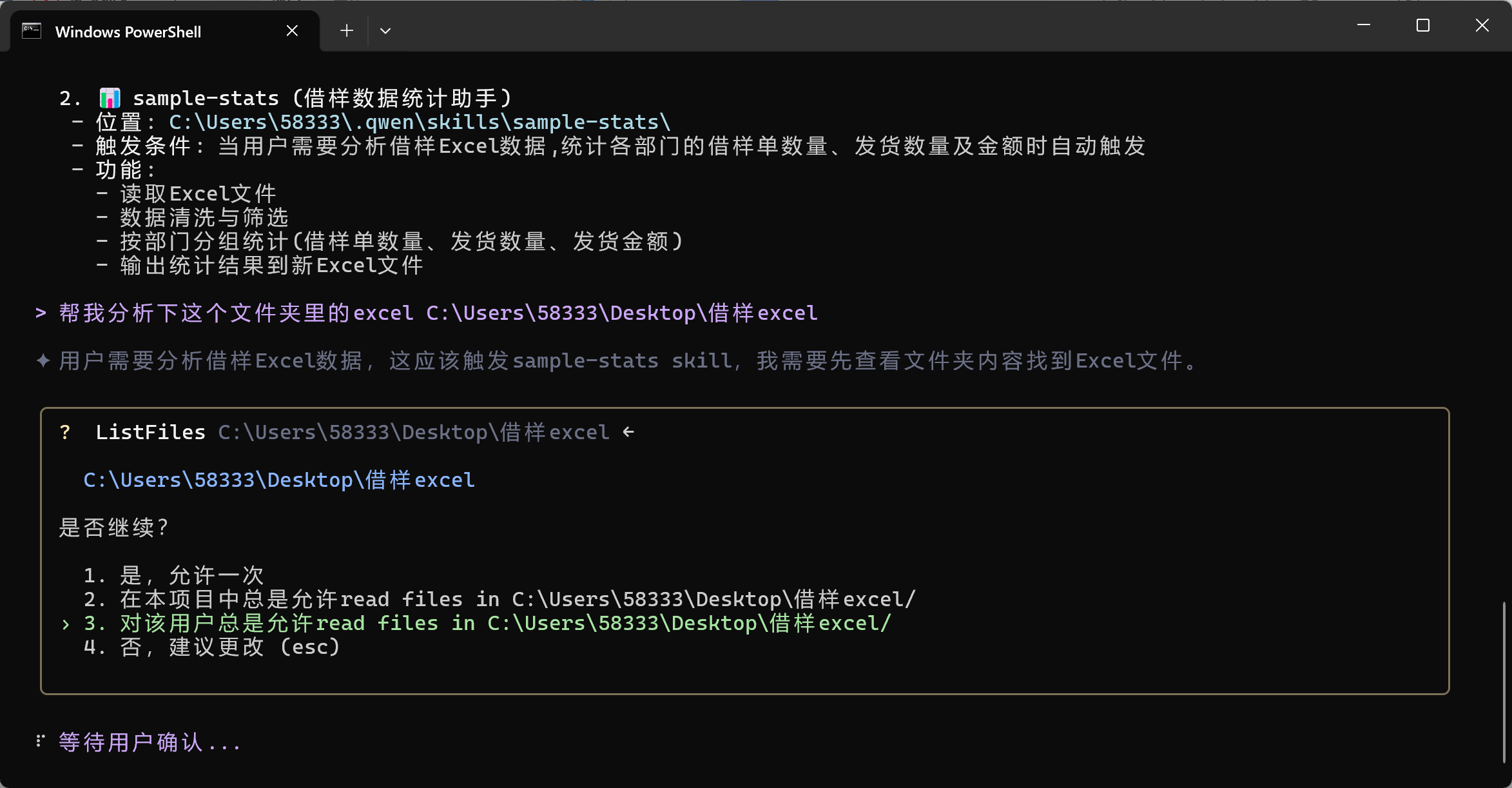

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)