
这个 Plugin 让 OpenClaw 减少Skill 90%Token消耗
本文介绍了如何通过Elasticsearch语义搜索和OpenClaw插件大幅减少Skill列表的Token消耗。传统方法会将所有Skill描述注入SystemPrompt,导致95个Skill消耗约5000个Token/次对话。新方案采用Jina Embeddings v5模型和Elasticsearch的semantic_text字段,实现按需加载相关Skill,将Token消耗降低92%,延
别让 Skill 列表烧光你的 Token——用一个 Plugin 让 OpenClaw 瘦身 90%
95 个 Skill,每轮对话就消耗 5000 多个 Token?本文将分享我们如何通过 Elasticsearch 语义搜索和一个 OpenClaw Plugin,将 Skill 列表从“全量注入”变为“按需加载”,将 Token 消耗减少 92%,并且即时生效。
一、你的 OpenClaw,正被 Skill 列表“偷走”Token
玩 OpenClaw 的人都知道:安装 Skill 一时爽,Token 消耗火葬场。
起初,你只装了 5 个 Skill,体验非常好。但随着你不断添加天气、GitHub、飞书文档、企业微信、腾讯云、Elasticsearch等功能,系统中逐渐堆积了 50 个、80 个,甚至 100 个 Skill。
你可能觉得“多就是好”,但 OpenClaw 每次对话都会将所有 Skill 的名称和描述放入 System Prompt。我们的实测结果是:
- • 95 个 Skill → System Prompt 占用 ~5,238 Token
- • 用户即使只说一句“你好”,这 5000 个 Token 也先被耗掉
- • 按 OpenRouter 的价格计算,每轮对话仅 Skill 列表就烧掉约 $0.005
更要命的是——无关的 Skill 还会干扰 LLM 的判断,导致“幻觉率上升”。明明是问天气,模型却在纠结是否应该用 GitHub Skill。

二、思路:为 OpenClaw 安装一个“智能筛子”
解决方案非常直观——按需供给。
用户问天气,就只提供天气相关的 Skill。用户问代码,就只提供 GitHub 相关的 Skill。其他 90 个 Skill 不注入,Token 自然节省。
这本质上就是 RAG(检索增强生成)的思路:先用语义搜索筛选,再将结果提供给 LLM。
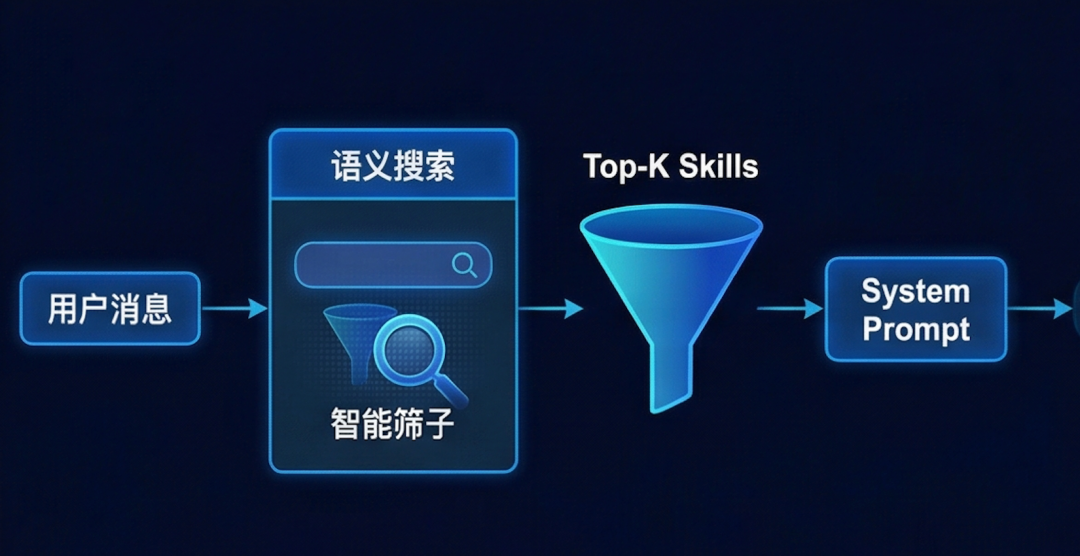
但这里面临一个技术选型的问题:用什么做语义检索?用什么 Embedding 模型?
三、技术选型:为什么选择 Elasticsearch + Jina v5?
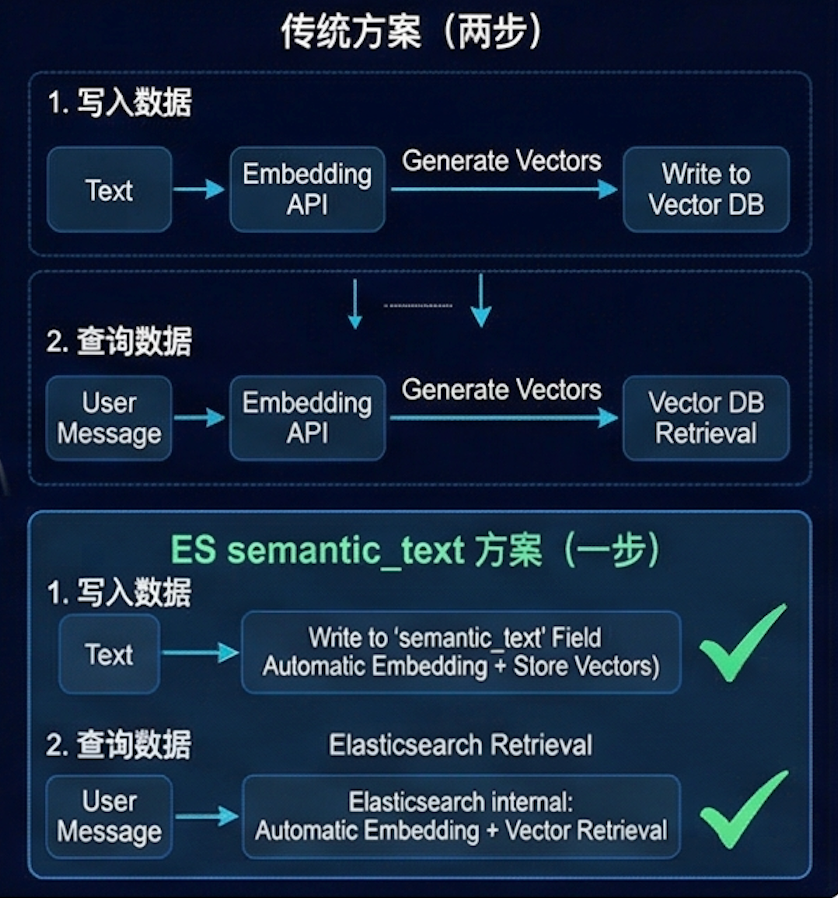
市面上有一些方案——基于本地 ONNX 模型和对象存储向量桶。它们的思路是:使用本地量化模型生成向量,写入对象存储,查询时再次生成向量进行检索。整个流程需要:Embedding API、向量存储和手动管理维度与距离度量。
我们选择了 Elasticsearch semantic_text + Jina Embeddings v5,原因如下:
1. 一步到位,零 Embedding 管理
传统方案需要两步:先调用 Embedding API 生成向量,然后写入向量存储。查询时也需两步:先将用户消息向量化,再去向量库检索。
而 ES 的 semantic_text 字段类型自动处理一切——只需写入文本,ES 会在内部自动调用推理端点生成向量。查询时也一样,直接传文本,ES 内部完成 Embedding 和向量检索。不需要外部 Embedding API,也不需要管理向量维度。
2. Jina Embeddings v5:紧凑型顶尖多语言模型
我们的 Embedding 推理端点使用的是 Jina Embeddings v5——由 Jina AI 和 Elastic 联合发布的新一代文本嵌入模型,在多语言 MTEB(MMTEB)基准测试中同级别第一。
jina-embeddings-v5-text-small 的核心数据:
- • 677M 参数,远小于许多同类模型
- • 32,768 Token 输入上下文窗口
- • 1024 维嵌入向量
- • 支持 211 种语言,中英文均衡,不偏科
它的杀手锏是 LoRA 插件架构:一个基础模型加上四个任务专用的 LoRA 插件(检索、文本匹配、聚类、分类),在不增加模型体积的前提下,每个任务都能做到最优。ES 在索引和检索时会自动选择合适的 LoRA 插件。
更进一步,Jina v5 支持 Matryoshka 表示学习——嵌入截断。默认 1024 维可以截断到 512 甚至 256 维,存储和计算成本成倍下降,精度损失极小。加上 二进制量化,嵌入大小可以从 2KB 压缩到 128 字节(减少 94%),性能几乎无损。
对我们的场景意味着什么? 95 个 Skill 描述的语义索引,即使全量存储也只需极小的空间。而且因为 Jina v5 原生多语言,中文查询“企业微信发消息”能精准匹配英文 description 的 wecom-msg Skill,不偏科。
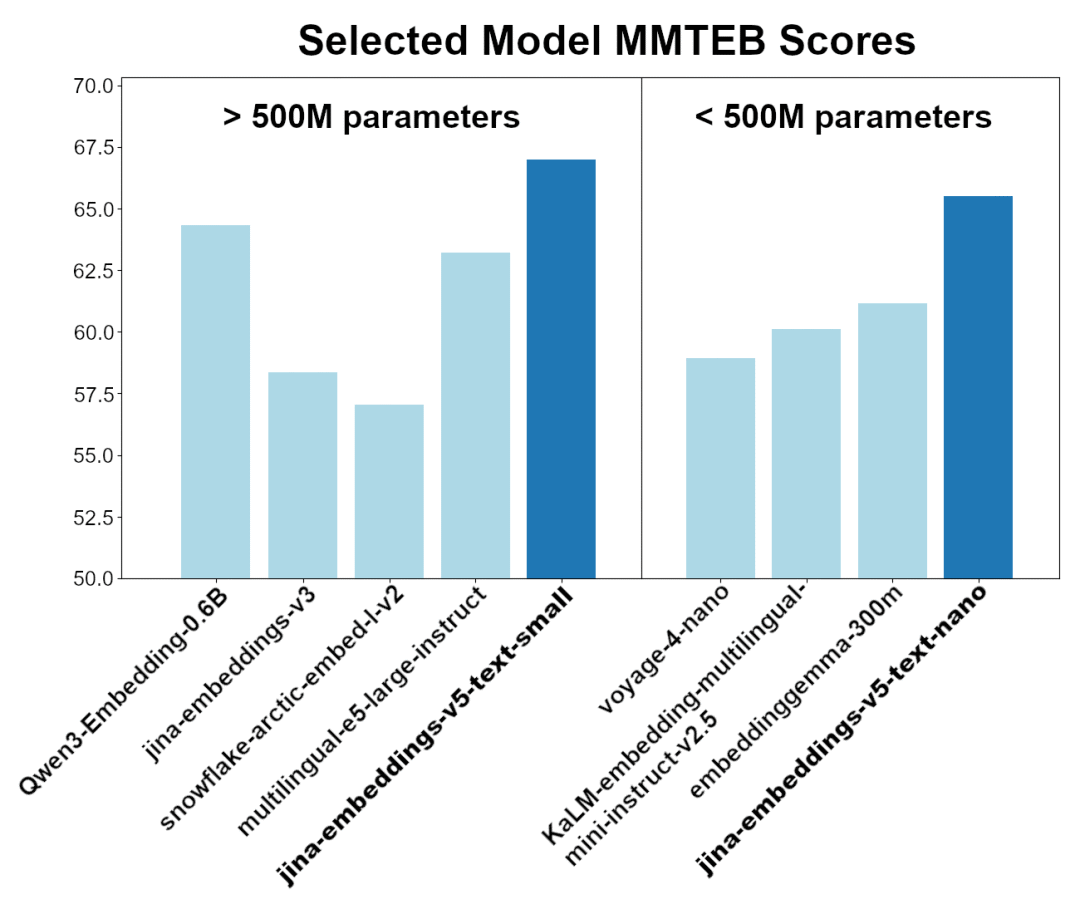
jina-embeddings-v5-text MMTEB 得分
3. 检索延迟从秒级降到百毫秒级
基于本地模型和对象存储的方案,链路是:用户消息 → 本地模型推理(500ms)→ 网络请求到向量存储(500ms)→ 返回结果。总计 ~1-2 秒。
ES 方案:用户消息 → ES 集群内完成 Embedding 和检索(~100ms)。推理在集群内完成,没有额外的网络往返。用户几乎无感知。
4. 关键发现——异步 Hook 方案存在“永远差一轮”的致命缺陷
我们在深入研究过程中发现了一个严重问题:很多方案使用 message:received 事件 Hook 来做路由——这个 Hook 在 Gateway 层面异步执行,与 Agent Loop 是并行的。
代码语言:javascript
AI代码解释
1
2
3
4
时间线:
00:00 消息到达,Agent 开始加载 Skill(用旧的配置)
00:20 Hook 才完成向量检索,写入配置文件
00:21 SIGUSR1 热重载——但 Agent 已经在运行了!结果是:Agent 永远用的是上一轮的 Skill 配置,当前轮永远失效。 而且因为每轮都会覆盖配置,连续对话时 Skill 列表一直在变,Agent 永远追不上。
我们的方案绕过了这个问题:使用 OpenClaw 的 Plugin 机制,注册 before_prompt_build Hook。这个 Hook 在 Agent Loop 内部同步执行——检索、过滤、注入,一气呵成,当轮就生效。

四、效果实测
我们在 95 个 Skill 的环境下测试:
|
指标 |
无 Router |
有 ES Skill Router |
变化 |
|---|---|---|---|
|
System Prompt Token |
~5,238 |
~391 |
-92.5% |
|
单轮成本 |
$0.0053 |
$0.0004 |
-92.5% |
|
Top-1 Skill 命中率 |
N/A |
80%+ |
— |
|
检索延迟 |
N/A |
~100ms |
零感知 |
几个真实场景:
场景 A:查天气
- • 用户:“深圳明天天气怎么样”
- • Router 推荐:[weather, tavily-search, gemini, ...]
- • Token 节省:97.8%
场景 B:企业微信发消息
- • 用户:“企业微信发消息”
- • Router 推荐:[wecom-msg, bluebubbles, wacli, ...](wecom-msg 命中,0.87 分)
- • Token 节省:92%
场景 C:创建飞书文档
- • 用户:“创建飞书文档”
- • Router 推荐:[feishu-doc, wecom-doc-manager, tencent-docs, ...](feishu-doc 命中,0.83 分)
- • Token 节省:92%
场景 D:中文查英文 Skill
- • 用户:“腾讯云开发者社区任务”
- • Router 推荐:[tencent-cloud-community, tencent-cos-skill, ...](0.81 分命中)
- • 跨语言语义理解,零配置
[图片位置6:Token 消耗对比柱状图——95 Skills vs 5 Skills]
五、5 分钟安装教程
前置条件
- • 一个 Elasticsearch 集群(Elastic Cloud 或自建)
- • 集群已配置
.jina-embeddings-v5-text-small推理端点(Elastic Cloud 默认可用) - • Python 3 +
pip install elasticsearch pyyaml
步骤 1:安装 Plugin
代码语言:javascript
AI代码解释
1
2
git clone https://github.com/oldcodeoberyn/es-skill-router.git
openclaw plugins install -l ./es-skill-router步骤 2:配置 ES 连接
编辑 ~/.openclaw/openclaw.json,在 plugins.entries 中添加:
代码语言:javascript
AI代码解释
{
"plugins": {
"entries": {
"es-skill-router": {
"enabled": true,
"config": {
"esUrl": "https://your-cluster:9243",
"esUser": "elastic",
"esPassword": "your-password",
"index": "openclaw-skills",
"topK": 5,
"minScore": 0.5
}
}
}
}
}也可以用环境变量(ES_URL、ES_USER、ES_PASSWORD)。
步骤 3:索引你的 Skill
代码语言:javascript
AI代码解释
export ES_URL="https://your-cluster:9243"
export ES_USER="elastic"
export ES_PASSWORD="your-password"
python3 es-skill-router/skills/es-vector-skill/scripts/index_skills.py \
--index openclaw-skills --recreate输出:
代码语言:javascript
AI代码解释
Found 95 skills
Created index: openclaw-skills
{"success": true, "indexed": 95, "errors": 0}步骤 4:重启 Gateway
代码语言:javascript
AI代码解释
1
openclaw gateway restart步骤 5:验证
发一条消息给你的 Agent,然后检查日志:
代码语言:javascript
AI代码解释
1
grep "es-skill-router\|ready.*index" /tmp/openclaw/openclaw-$(date +%Y-%m-%d).log你应该看到:
代码语言:javascript
AI代码解释
1
2
ready: index=openclaw-skills topK=5 minScore=0.5
"message_id": "om_x100b53fc8" → [tencent-cloud-community(0.74), tlon-skill(0.71), session-logs(0.71), wecom-msg(0.71), tencent-cos-skill(0.69)]
大功告成!
六、进阶配置
|
参数 |
默认值 |
说明 |
|---|---|---|
|
topK |
5 |
保留的 Skill 数量,建议 3-10 |
|
minScore |
0.5 |
最低相关度分数,低于此值的 Skill 不注入 |
|
index |
openclaw-skills |
ES 索引名 |
|
enabled |
true |
开关,设 false 可临时禁用 |
安装新 Skill 后,重新运行索引脚本即可(增量更新,不会覆盖已有的):
代码语言:javascript
AI代码解释
1
python3 es-skill-router/skills/es-vector-skill/scripts/index_skills.py --index openclaw-skills七、总结
|
传统本地+对象存储方案 |
ES Skill Router(本文) |
|
|---|---|---|
|
Embedding |
需要外部 API 或本地模型 |
ES 内置(Jina v5) |
|
路由机制 |
异步 Hook + SIGUSR1 |
同步 Plugin Hook |
|
生效时序 |
永远差一轮 |
当轮生效 |
|
部署复杂度 |
Embedding 服务 + 向量存储 + Hook |
一个 Plugin |
|
延迟 |
1-2 秒 |
~100ms |
|
多语言 |
取决于模型选择 |
Jina v5 原生 211 语言 |
|
Token 节省 |
~92% |
~92% |
一句话:做减法才是工程功底的试金石。 为大模型减轻上下文负担,它反而会表现得更聪明。
开源地址:github.com/oldcodeoberyn/es-skill-router

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)