
OpenClaw 记忆召回系统:置信度计算与混合搜索机制
OpenClaw的记忆召回系统采用混合搜索策略,结合向量相似度和关键词匹配计算置信度分数
一、记忆召回置信度计算与使用
1.1置信度计算方法
OpenClaw 的记忆召回系统使用多种方法计算置信度,主要包括:
1. 向量搜索置信度
- 基于嵌入向量相似度:使用余弦相似度计算查询向量与文档向量之间的相似性
- 实现位置:
src/memory/manager-search.ts中的searchVector函数 - 范围:0-1,值越高表示相似度越高
2. 关键词搜索置信度
- 基于 BM25 算法:通过
bm25RankToScore函数将 BM25 排名转换为 0-1 之间的分数 - 实现位置:
src/memory/hybrid.ts中的bm25RankToScore函数 - 范围:0-1,值越高表示关键词匹配度越高
3. 混合搜索置信度
- 加权平均:结合向量搜索和关键词搜索的结果
- 权重配置:
- 向量权重 (
vectorWeight):默认为 0.7 - 文本权重 (
textWeight):默认为 0.3
- 向量权重 (
- 实现位置:
src/memory/hybrid.ts中的mergeHybridResults函数
置信度的使用方式
1. 阈值过滤
- 最小置信度阈值:默认为 0.35 (
DEFAULT_MIN_SCORE) - 过滤逻辑:搜索结果会过滤掉低于此阈值的条目
- 实现位置:
src/memory/manager.ts中的search方法
2. 搜索模式处理
- 混合模式:同时使用向量和关键词搜索,结合两者的置信度
- 仅 FTS 模式:当没有嵌入提供者时,仅使用关键词搜索
- 向量模式:当 FTS 不可用时,仅使用向量搜索
3. 结果排序与限制
- 排序:按置信度分数降序排列
- 限制:最多返回
maxResults个结果(默认为 6) - 候选结果:先获取更多候选结果(
maxResults * candidateMultiplier),然后进行过滤
4. 特殊处理
- 关键词匹配调整:当混合模式下没有符合阈值的结果时,会适当放宽阈值以保留纯关键词匹配的结果
- 时间衰减:可选启用时间衰减功能,降低旧文档的置信度
1.2配置参数
| 参数 | 默认值 | 说明 | 位置 |
|---|---|---|---|
minScore |
0.35 | 最小置信度阈值 | src/agents/memory-search.ts:93 |
vectorWeight |
0.7 | 向量搜索权重 | src/agents/memory-search.ts:95 |
textWeight |
0.3 | 关键词搜索权重 | src/agents/memory-search.ts:96 |
maxResults |
6 | 最大结果数 | src/agents/memory-search.ts:92 |
candidateMultiplier |
4 | 候选结果乘数 | src/agents/memory-search.ts:97 |
搜索流程
- 查询处理:清理查询文本
- 同步检查:如果启用了搜索时同步,执行内存同步
- 模式判断:
- 无嵌入提供者:使用仅 FTS 模式
- FTS 不可用:使用仅向量模式
- 两者都可用:使用混合模式
- 执行搜索:
- 向量搜索:计算嵌入向量并执行相似性搜索
- 关键词搜索:使用 FTS 执行关键词匹配
- 结果合并:
- 混合模式:加权合并两种结果
- 单一模式:直接使用对应结果
- 置信度过滤:过滤掉低于
minScore的结果 - 结果限制:返回前
maxResults个结果
通过这些机制,OpenClaw 的记忆召回系统能够有效地评估搜索结果的相关性,并根据置信度过滤和排序结果,确保返回最相关的记忆内容。
二、时间衰减功能
2.1核心实现原理
OpenClaw 的时间衰减功能通过指数衰减模型实现,用于降低旧文档的置信度,使搜索结果更加偏向于近期内容。
1. 衰减计算模型
export function calculateTemporalDecayMultiplier(params: {
ageInDays: number;
halfLifeDays: number;
}): number {
const lambda = toDecayLambda(params.halfLifeDays);
const clampedAge = Math.max(0, params.ageInDays);
if (lambda <= 0 || !Number.isFinite(clampedAge)) {
return 1;
}
return Math.exp(-lambda * clampedAge);
}
关键公式:
- 衰减率计算:
lambda = ln(2) / halfLifeDays - 衰减乘数:
decay = exp(-lambda * ageInDays)
工作原理:
- 每经过一个半衰期(
halfLifeDays),文档的权重会减少一半 - 例如:如果半衰期设置为30天,60天前的文档权重会变为原来的1/4
2. 时间戳提取
系统通过以下方式确定文档的时间戳:
-
日期命名的记忆文件:
- 从文件名提取日期,如
memory/2024-01-01.md - 使用正则表达式
/(?:^|\/)memory\/(\d{4})-(\d{2})-(\d{2})\.md$/匹配
- 从文件名提取日期,如
-
常青知识文件:
- 根级记忆文件(如
MEMORY.md) - 非日期命名的记忆文件
- 这些文件被视为"常青"知识,不应用时间衰减
- 根级记忆文件(如
-
其他文件:
- 使用文件系统的修改时间(mtime)
2.2配置参数
| 参数 | 默认值 | 说明 |
|---|---|---|
enabled |
false | 是否启用时间衰减 |
halfLifeDays |
30 | 半衰期(天),每经过这个时间,文档权重减少一半 |
2.3工作流程
- 搜索执行:执行向量搜索和关键词搜索
- 结果合并:计算混合分数(向量得分 * 向量权重 + 文本得分 * 文本权重)
- 时间衰减应用:
- 提取每个结果的时间戳
- 计算文档年龄(以天为单位)
- 计算衰减乘数
- 将衰减乘数应用到混合分数上
- 结果排序:按衰减后的分数降序排列
- MMR重排序:如果启用,进行多样性重排序
2.4时间衰减的影响
示例:半衰期为30天的情况
| 文档年龄 | 衰减乘数 | 原始分数 | 衰减后分数 |
|---|---|---|---|
| 0天(今天) | 1.0 | 0.8 | 0.8 |
| 30天 | 0.5 | 0.8 | 0.4 |
| 60天 | 0.25 | 0.8 | 0.2 |
| 90天 | 0.125 | 0.8 | 0.1 |
特殊处理
- 常青知识:根级记忆文件和非日期命名的记忆文件不应用时间衰减
- 无时间戳文件:无法确定时间戳的文件不应用时间衰减
- 时间戳提取失败:如果无法提取时间戳,保持原始分数不变
2.5总结
OpenClaw 的时间衰减功能通过指数衰减模型,根据文档的年龄动态调整其置信度分数,使搜索结果更加偏向于近期内容。这对于需要保持信息新鲜度的场景非常重要,如项目文档、会议记录等。
时间衰减的实现考虑了不同类型文件的特点,对常青知识文件不应用衰减,同时通过灵活的配置参数,允许用户根据具体需求调整衰减速度。
三、记忆召回触发时机与流程分析
3.1触发时机
OpenClaw 的记忆召回主要在以下情况下触发:
1. 显式工具调用
- 用户查询触发:当用户提出涉及以下内容的问题时,系统会调用
memory_search工具- 先前的工作
- 决策历史
- 日期和时间
- 人员信息
- 偏好设置
- 待办事项
2. 系统自动触发
- 强制召回步骤:根据工具描述,记忆搜索是一个"强制召回步骤",在回答问题前自动执行
- 搜索时同步:当启用
sync.onSearch配置时,搜索前会自动同步内存
3. 配置相关触发
- 会话启动同步:当启用
sync.onSessionStart配置时,会话开始时会预热内存 - 定时同步:当设置了
sync.intervalMinutes时,会定期同步内存
3.2召回流程
记忆召回的完整流程如下:
1. 工具注册与初始化
- 工具注册:
memory_search工具在tool-catalog.ts中注册到 “memory” 部分 - 工具创建:通过
createMemorySearchTool函数创建记忆搜索工具实例 - 上下文解析:解析配置和代理会话信息,确定是否启用记忆搜索
2. 搜索执行
- 参数处理:解析查询文本、最大结果数、最小分数等参数
- 管理器获取:调用
getMemorySearchManager获取内存搜索管理器 - 同步检查:如果启用了搜索时同步,执行内存同步
- 搜索执行:
- 向量搜索:计算查询的嵌入向量,执行相似性搜索
- 关键词搜索:使用 FTS 执行关键词匹配
- 混合模式:结合向量和关键词搜索结果,应用权重计算
- 时间衰减:如果启用,应用时间衰减降低旧文档的置信度
- MMR重排序:如果启用,进行多样性重排序
3. 结果处理
- 引用添加:根据配置添加来源引用
- 结果限制:根据字符预算限制结果大小
- 状态收集:收集搜索状态信息(提供者、模型、模式等)
- 结果返回:返回处理后的搜索结果
4. 错误处理
- 管理器不可用:返回内存搜索不可用的错误信息
- 搜索失败:捕获并处理搜索过程中的错误
- 配额错误:特殊处理嵌入提供者配额耗尽的情况
3.3技术实现细节
1. 搜索模式
- 混合模式:同时使用向量和关键词搜索,结合两者的优势
- 仅 FTS 模式:当没有嵌入提供者时,仅使用关键词搜索
- 向量模式:当 FTS 不可用时,仅使用向量搜索
2. 结果排序与过滤
- 置信度过滤:过滤掉低于
minScore的结果(默认 0.35) - 结果排序:按置信度分数降序排列
- 结果限制:最多返回
maxResults个结果(默认 6)
3. 内存同步
- 自动同步:在搜索前和会话启动时自动同步
- 文件监听:监控记忆文件的变化,及时更新索引
- 会话同步:同步会话记录到内存中
3.4总结
OpenClaw 的记忆召回系统是一个强大的功能,通过语义搜索和关键词搜索的结合,为用户提供了快速访问历史信息的能力。它在用户提出相关问题时自动触发,通过多层次的搜索和处理,返回最相关的记忆内容。
记忆召回的触发时机主要是用户查询涉及历史信息时,流程包括工具调用、搜索执行、结果处理和错误处理等步骤。系统通过灵活的配置选项,允许用户根据具体需求调整记忆搜索的行为。
四、指数衰减模型
关键公式:
- 衰减率计算:
lambda = ln(2) / halfLifeDays - 衰减乘数:
decay = exp(-lambda * ageInDays)
这是一个经典的指数衰减模型,广泛应用于放射性衰变、药代动力学、缓存过期等领域。
4.1核心思想
半衰期(Half-life):物质衰减到原来一半所需的时间。
公式设计的目标是:每经过一个半衰期,数值恰好减半。
4.2公式拆解
第一步:衰减率 λ 的推导
lambda = ln(2) / halfLifeDays
为什么用 ln(2)?
指数衰减的通式是:N(t) = N₀ * e^(-λt)
要让 t = halfLifeDays 时 N(t) = N₀ / 2:
N₀/2 = N₀ * e^(-λ * halfLifeDays)
1/2 = e^(-λ * halfLifeDays)
ln(1/2) = -λ * halfLifeDays
-ln(2) = -λ * halfLifeDays
λ = ln(2) / halfLifeDays ≈ 0.693 / halfLifeDays
ln(2) ≈ 0.693 是确保"减半"这个特性的数学常数。
第二步:衰减乘数的计算
decay = exp(-lambda * ageInDays)
= e^(-ln(2)/halfLifeDays * ageInDays)
= 2^(-ageInDays/halfLifeDays)
4.3直观理解(以 halfLifeDays = 30 为例)
| 文档年龄 | 计算过程 | 衰减乘数 |
|---|---|---|
| 0天 | 2^(-0/30) = 2^0 | 1.0(100%) |
| 30天 | 2^(-30/30) = 2^(-1) | 0.5(50%) |
| 60天 | 2^(-60/30) = 2^(-2) | 0.25(25%) |
| 90天 | 2^(-90/30) = 2^(-3) | 0.125(12.5%) |
规律:每过一个半衰期,权重乘以 1/2。
4.4在 OpenClaw 中的应用
// 原始置信度 * 衰减乘数 = 最终置信度
finalScore = hybridScore * decayMultiplier
效果:
- 新文档(0-30天):置信度几乎不受影响
- 30天前文档:置信度打 5 折
- 60天前文档:置信度打 2.5 折
- 90天前文档:置信度仅剩 12.5%
这样系统会优先返回近期记忆,但旧文档不会完全消失(只是权重降低)。
绘制 halfLifeDays=30 时的指数衰减曲线图,展示文档年龄与衰减乘数的关系。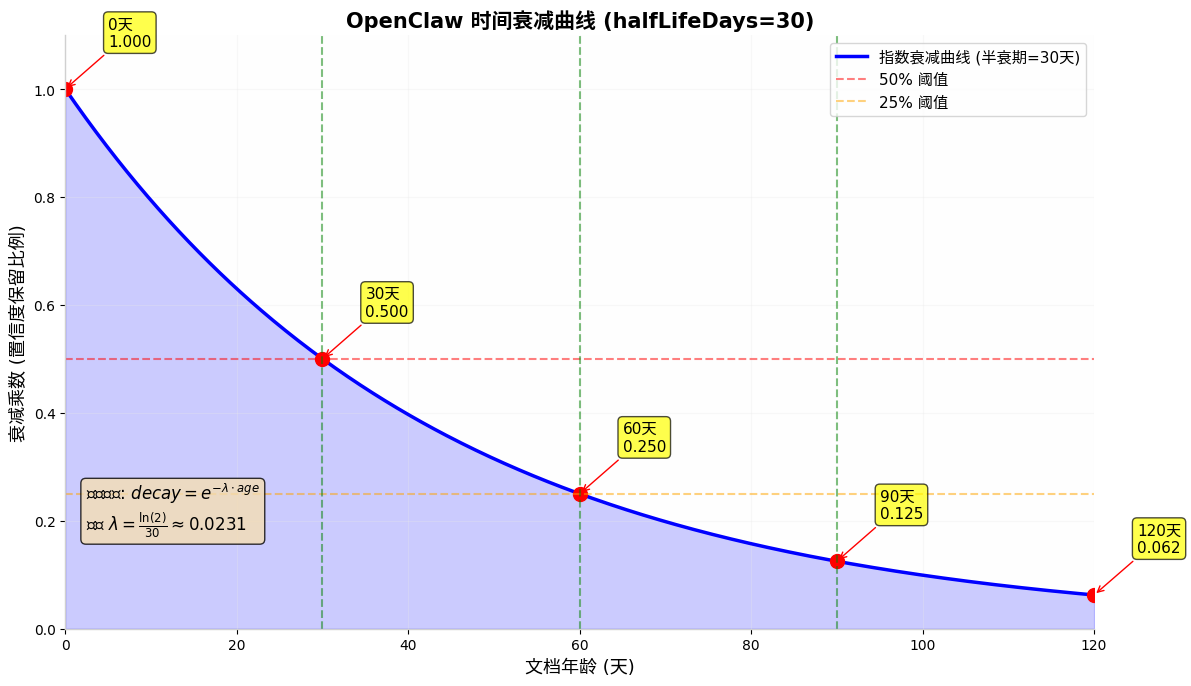
曲线特征解读
| 时间节点 | 衰减乘数 | 置信度保留 | 直观理解 |
|---|---|---|---|
| 0天 | 1.000 | 100% | 新文档,权重不变 |
| 30天 | 0.500 | 50% | 恰好减半(第一个半衰期) |
| 60天 | 0.250 | 25% | 再减半(第二个半衰期) |
| 90天 | 0.125 | 12.5% | 继续减半(第三个半衰期) |
| 120天 | 0.062 | 6.2% | 4个月前的文档权重极低 |
曲线形状特点
- 初始平缓(0-15天):近期文档权重几乎不受影响,保护"新鲜"记忆
- 快速下降(15-60天):进入主要衰减期,斜率最大
- 尾部平缓(60天+):旧文档权重趋近于0但不会归零,仍有机会被召回
这种**“先慢后快再慢”**的曲线符合人类遗忘规律——近期事记得清,远期事逐渐模糊。
4.5为什么选指数衰减而非线性
| 特性 | 指数衰减 | 线性衰减 |
|---|---|---|
| 近期保护 | 新文档权重几乎不变 | 新文档也会被削 |
| 远期处理 | 旧文档缓慢趋近于0 | 到某天后直接归零 |
| 数学性质 | 连续、平滑、可导 | 有拐点 |
| 物理意义 | 符合遗忘曲线规律 | 人为硬性截断 |
指数衰减更符合艾宾浩斯遗忘曲线——人脑也是先快后慢地遗忘。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)