
AI大模型之旅——LangChain基础组件
封装好的基础聊天模型和其他组件。LangChain集成包,目前LangChain会将一些重要的集成包单独拆分出来(例如langchain-openai , langchain-anthropic 等),让集成包更轻量级,这些包将会由LangChain团队和集成包的开发者共同维护。构成AI应用的链、AI agent和检索器。社区维护的第三方集成包。⽐如:Model I/O、Retrieval、Too
文章目录
AI大模型之LangChain基础组件(Langchain1.2.8)
一、基础概念
1.LangChain是什么?
LangChain中的“Lang”是指language,即⼤语⾔模型,“Chain”即“链”,也就是将⼤模型与外部数据&各种组件连接成链,以此构建AI应⽤程序。
LangChain 之于 LLMs,类似 Spring 之于 Java
LangChain 之于 LLMs,类似 Django、Flask 之于 Python
2.为什么需要langchain?
它将 大语言模型(LLM)如 ChatGPT、Claude、DeepSeek 等灵活集成到自己的应用中 ,实现更强大的对话能力、检索增强生成 (RAG)、工具调用(Tool Calling)、多轮推理等功能
3.Langchain模块介绍
langchain-core :封装好的基础聊天模型和其他组件。integrations:LangChain集成包,目前LangChain会将一些重要的集成包单独拆分出来(例如langchain-openai , langchain-anthropic 等),让集成包更轻量级,这些包将会由LangChain团队和集成包的开发者共同维护。langchain :构成AI应用的链、AI agent和检索器。
langchain-community :社区维护的第三方集成包。⽐如:Model I/O、Retrieval、Tool & Toolkit;合作伙伴包 langchain-openai,langchainanthropic等。
langgraph :LangGraph 专门用于构建能处理 复杂任务流程的 AI 应用。它的核心思想是用 “图”(Graph)
来管理任务流程,就像画一张路线图,让 AI 知道何时该执行什么操作、何时需要循环或分支判断,还能自动记住执行到哪一步了。
langsmith:LangSmith 是 LLM应用的全生命周期管理平台,覆盖开发→测试→部署→监控全流程,可以观察到AI应用运行的每一个步骤,它与LangChain深度集成,但它不仅适用于 LangChain,也可以用于监控任何使用 LLM 的应用。
4.官网地址
官网地址:https://www.langchain.com/langchain官网文档:https://python.langchain.com/docs/introduction/API文档:https://python.langchain.com/api_reference/github地址:https://github.com/langchain-ai/langchainLangChain 中文文档:https://langchain.ichuangpai.com/Langchain教程:https://docs.langchain.org.cn/oss/python/langchain/overview
5.安装Langchain
pip install langchain
查看Langchain版本
pip show langchain
安装openAI
pip install -qU langchain-openai
二、Langchain组件之Model I/O
2.1 定义
Model I/O:标准化各个大模型的输入和输出,包含输入模版,模型本身和格式化输出。 就是输⼊、模型处理、输出这三个步骤
2.2 分类
大语言模型的分类,按照模型功能的不同:
- 非对话模型(LLMs、Text Model)
- 对话模型(Chat Models)( 推荐 )
- 嵌入模型(Embedding Models)
具体调用的API
- OpenAI提供的API
- 其它大模型自家提供的API
- LangChain的统一方式调用API( 推荐 )
对话模型:
from langchain_community.chat_models import ChatOpenAI
dotenv.load_dotenv()
chat_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
前提是这里使用配置文件加载环境变量,即在项目根目录下有个文件.env,里面内容如下:
OPENAI_API_KEY="sk-uKUuuPdyjY8ft9CU0EoX6uqy0cRA60FKnYDhIMeIH******"
OPENAI_BASE_URL="https://api.openai-proxy.org/v1"
对话模型:
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
###########核心代码############
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗") # 直接输入字符串
print(str)
注意:LangGraph推荐使用init_chat_model
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="gpt-3.5-turbo",
temperature=0
)
2.3 在构建ChatModels时,我们有一些标准化参数
model:模型名称temperature:采样温度,是 控制模型输出“随机性”的超参数,在生成文本时决定模型多偏向于探索性回答还是保守回答。
越低 → 概率尖锐 → 输出越确定、保守。
越高 → 概率平坦 → 输出越随机、创意更丰富timeout:请求超时max_tokens:生成的最大令牌数max_retries:请求重试的最大次数api_key:大模型供应商的API密钥base_url:发送请求的端
2.4 invoke 与 stream
| 方法 | 用法 | 特点 | 使用场景 |
|---|---|---|---|
| invoke | response = llm.invoke(messages) | 一次性生成完整输出,直到模型返回完整回答才返回 | 大多数问答、客服场景,输出不大,等待一次生成即可 |
| stream | response = llm.invoke(messages) for token in llm.stream(messages) print(token, end=“”) |
流式输出,模型生成每个 token 就可立即处理 | 需要实时显示模型输出(网页聊天、终端进度条、SSE)或处理超长回答 |
代码示例
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
llm = init_chat_model("gpt-4o-mini", temperature=0.2)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个礼貌的电商客服"),
("human", "{input}")
])
messages = prompt.invoke({"input": "请告诉我订单12345的状态"})
# 方式一: 一次性生成完整答案
response = llm.invoke(messages)
print("客服回答:", response.content)
print("客服回答(流式输出):")
# 方式二: 流式输出,每生成一个 token 就打印
for token in llm.stream(messages):
print(token, end="")
三、Langchain组件之Prompt Template
现在,我们将消息列表直接传递给语言模型。这些信息列表从何而来?通常,它是由用户输入和应用程序逻辑组合而成的。此应用程序逻辑通常接受原始用户输入,并将其转换为准备传递给语言模型的消息列表。 常见的转换包括添加系统消息或使用用户输入格式化模板。
PromptTemplates是LangChain中的一个概念,旨在帮助进行这种转换。它们接收原始用户输入并返回准备递给语言模型的数据(提示符)。
让我们在这里创建一个PromptTemplate。它将接受两个用户变量:
language:将文本翻译成的语言text:要翻译的文本
安装:from langchain_core.prompts import ChatPromptTemplate
Prompt三个常用方法区别:
format:格式化提示词模板为字符串
partial:格式化提示词模板为一个新的提示词模板,可以继续进行格式化
invoke:格式化提示词模板为PromptValue
LangChain 提供了多种不同的提示词模板,下面介绍几种常用的提示词模板:
PromptTemplate:文本生成模型提示词模板,用字符串拼接变量生成提示词
ChatPromptTemplate:聊天模型提示词模板,适用于如 gpt-3.5-turbo、gpt-4 等聊天模型
HumanMessagePromptTemplate:人类消息提示词模板
SystemMessagePromptTemplate:系统消息提示词模板
FewShotPromptTemplate:少量示例提示词模板,自动拼接多个示例到提示词中,例:1+1=2,2+2=4,让大模型去计算5+5等于多少。
from langchain_core.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的律师,请你回答我提出的法律问题,并给出法律条文依据"),
("human", "{question}")
])
prompt_value = chat_prompt.invoke({"question":"工地摔伤算工伤吗?能赔多少?"})
print(prompt_value)
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的律师,请你回答我提出的法律问题,并给出法律条文依据"),
("human", "{question}")
])
prompt_value = prompt.format(question="工地摔伤算工伤吗?能赔多少?")
print(prompt_value)
四、Langchain组件之Chain链
Chain链是 LangChain 的核心思想之一,一个 Chain就是将多个模块串起来完成一系列操作,Chain链可以将上一步操作的结果交给下一步进行执行,比如用提示词模板生成Prompt,将渲染后的提示词交给大模型生成回答,再将大模型的回答将结果输出到控制台,Chain和Linux中的管道符十分类似,每一步的输出自动作为下一步输入,实现模块串联
现在我们可以使用pipe(|)操作符将它与上面的模型和输出解析器结合起来:chain = prompt_template | model | parser
from datetime import datetime
import dotenv
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
# 1.加载环境变量
dotenv.load_dotenv()
# 2.构建提示词模板
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的大语言模型,对我的提问进行回答"),
MessagesPlaceholder("memory"),
("human", "{question}"),
("human", "{currentTime}")
]).partial(currentTime=datetime.now())
# 3.构建大模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 4.构建输出解析器
parser = StrOutputParser()
# 5.构建链
chain = chat_prompt | llm | parser
# 6.调用
prompt_value = chain.invoke({"question": "你是谁,现在是哪年哪月哪日,请问今年最好的手机品牌是什么?",
"memory": [HumanMessage("你是小米公司的雷军,你扮演雷军的身份和我对话"),
AIMessage("好的我是小米公司的雷军,下面将会以雷军的身份和口吻回答你的问题")]})
# 7.输出
print(prompt_value)
五、Langchain组件之OutputParsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望
model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时, LangChain提供的 输出解析器 就派上用场了。
输出解析器(Output Parser)负责获取 LLM 的输出并将其转换为更合适的格式。这在应用开发中及其 重要
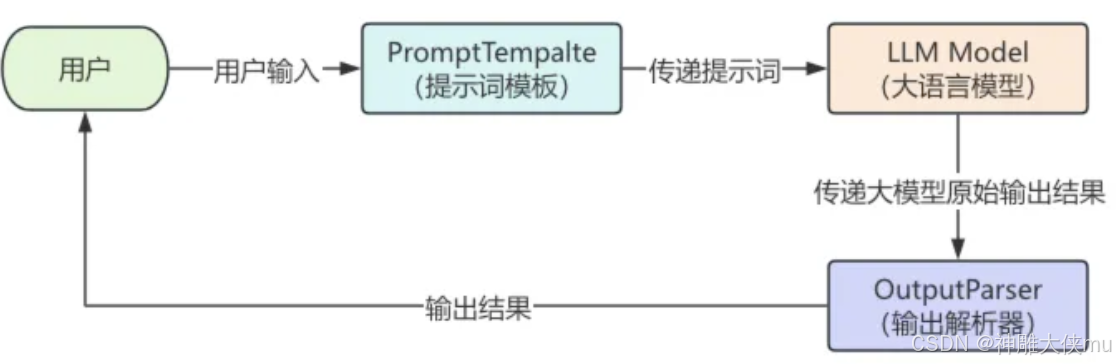
分类
| 解析器类型 | 适用场景 | 输出格式 |
|---|---|---|
| StrOutputParser | 简单文本输出 | 字符串 |
| JsonOutputParser | JSON格式数据 | 字典/列表 |
| PydanticOutputParser | 复杂结构化数据 | Pydantic模型对象 |
| ListOutputParser | 列表数据 | Python列表 |
| DatetimeOutputParser | 时间日期数据 | datetime对象 |
| BooleanOutputParser | 布尔值输出 | True/False |
输出解析器核心方法:
parse:将大模型输出的内容,格式化成指定的格式返回。
format_instructions:它会返回一段清晰的格式说明字符串,告诉 LLM 希望输出成什么格式(比如 JSON,或者特定格式)。
示例
import dotenv
from langchain_core.output_parsers.base import BaseOutputParser
from langchain_core.exceptions import OutputParserException
import re
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
class BookTitleParser(BaseOutputParser):
"""自定义书名号内容解析器,用于提取《书名》格式的文本内容"""
def get_format_instructions(self) -> str:
return """请将输入的文本内容提取出《书名》中的内容,并返回一个列表,列表中的元素为提取出的内容。"""
def parse(self, text: str) -> list[str]:
"""解析输入的文本内容,返回一个列表,列表中的元素为提取出的内容"""
pattern = r"《(.*?)》"
matches = re.findall(pattern, text)
if not matches:
raise OutputParserException(f"无法从输入的文本中提取《书名》中的内容")
return matches
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业书籍信息提取专家"),
("human", "请你推荐5本关于{subject}的好书\n{format_instructions}")
])
llm = ChatOpenAI(model="gpt-3.5-turbo")
parser = BookTitleParser()
chain = prompt | llm | parser
result = chain.invoke({"subject": "Python编程", "format_instructions": parser.get_format_instructions()})
print(f"输出类型: {type(result)}")
print(f"输出内容: {result}")
六、Langchain组件之记忆组件(Memory)
大语言模型本质上是经过大量数据训练出来的自然语言模型,用户给出输入信息,大语言模型会根据训练的数据进行预测给出指定的结果,大语言模型本身是“无状态的”,因此大语言模型是没有记忆能力的。
Memory,是LangChain中用于多轮对话中保存和管理上下文信息(比如文本、图像、音频等)的组
件。它让应用能够记住用户之前说了什么,从而实现对话的 上下文感知能力 ,为构建真正智能和上下文
感知的链式对话系统提供了基础。
使用redis作为记忆组件使用示例
# 使用redis作为会话存储
import os
import urllib.parse
import dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
# ----------------------------
# 1. 加载环境变量并配置连接
# ----------------------------
dotenv.load_dotenv()
redis_password = os.getenv("REDIS_PASSWORD")
openai_api_key = os.getenv("OPENAI_API_KEY")
# 构建 Redis URL(带密码)
encoded_password = urllib.parse.quote(redis_password, safe="")
redis_url = f"redis://:{encoded_password}@192.168.174.198:6379/0"
# ----------------------------
# 2. 定义会话历史工厂函数
# ----------------------------
def get_session_history(session_id: str):
return RedisChatMessageHistory(
session_id=session_id,
url=redis_url,
key_prefix="chat:",
ttl=900 # 15分钟自动过期
)
# ----------------------------
# 3. 构建带记忆的对话链
# ----------------------------
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有记忆的 AI 助手。请根据对话历史友好、准确地回答用户问题。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key=openai_api_key)
chain = prompt | llm
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
# ----------------------------
# 4. 交互式人机对话循环
# ----------------------------
SESSION_ID = "user_session_001" # 可替换为动态用户ID(如从登录获取)
print("💬 欢迎使用 AI 助手!输入 '退出' 结束对话。\n")
while True:
try:
user_input = input("👤 用户: ").strip()
# 退出条件
if user_input.lower() in ["退出", "exit", "quit", "q"]:
print("👋 再见!")
break
if not user_input:
continue
# 调用带历史的链
response = chain_with_history.invoke(
{"input": user_input},
config={"configurable": {"session_id": SESSION_ID}}
)
print(f"🤖 助手: {response.content}\n")
except KeyboardInterrupt:
print("\n👋 对话已中断,再见!")
break
except Exception as e:
print(f"❌ 发生错误: {e}\n")
ConversationSummaryBufferMemory:ConversationSummaryBufferMemory 是 LangChain 中一种混合型记忆机制,它结合了ConversationBufferMemory(完整对话记录)和ConversationSummaryMemory(摘要记忆)的优
点,在保留最近 对话原始记录 的同时,对较早的对话内容进行 智能摘要 。
特点: 保留最近N条原始对话:确保最新交互的完整上下文
摘要较早历史:对超出缓冲区的旧对话进行压缩,避免信息过载 平衡细节与效率:既不会丢失关键细节,又能处理长对话
from langchain_classic.memory import ConversationSummaryBufferMemory
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import RedisChatMessageHistory
# -----------------------------
# 1. 初始化大语言模型
# -----------------------------
dotenv.load_dotenv()
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.5,
max_tokens=500,
api_key=os.getenv("OPENAI_API_KEY") # 建议从环境变量读取
)
# -----------------------------
# 2. 定义提示模板
# -----------------------------
prompt = ChatPromptTemplate.from_messages([
("system", "你是电商客服助手,用中文友好回复用户问题。保持专业但亲切的语气。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
# -----------------------------
# 3. 创建基础链(无记忆)
# -----------------------------
chain = prompt | llm
# -----------------------------
# 4. 实现带摘要缓冲的会话历史管理器
# -----------------------------
SESSION_ID = "ecommerce_user_001"
# 我们用一个全局变量模拟内存中的摘要状态(生产环境建议存数据库)
summary_memory_store = {}
def get_summarized_history(session_id: str):
"""返回当前会话的摘要+近期消息列表(符合 MessagesPlaceholder 要求)"""
if session_id not in summary_memory_store:
# 初始化空记忆
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=400,
return_messages=True,
memory_key="chat_history"
)
summary_memory_store[session_id] = memory
return summary_memory_store[session_id]
def get_message_history_for_runnable(session_id: str):
"""为 RunnableWithMessageHistory 提供消息列表(只读)"""
memory = get_summarized_history(session_id)
return memory.chat_memory # 这是一个 BaseChatMessageHistory 实例
def update_memory_with_new_exchange(session_id: str, input_msg: str, output_msg: str):
"""手动更新摘要记忆(因为新 API 不自动管理 memory)"""
memory = get_summarized_history(session_id)
memory.save_context({"input": input_msg}, {"output": output_msg})
# -----------------------------
# 5. 包装为带历史的可运行对象
# -----------------------------
chain_with_history = RunnableWithMessageHistory(
chain,
get_message_history_for_runnable,
input_messages_key="input",
history_messages_key="chat_history",
)
# -----------------------------
# 6. 模拟多轮对话
# -----------------------------
dialogue = [
"你好,我想查询订单12345的状态",
"这个订单是上周五下的",
"我现在急着用,能加急处理吗",
"等等,我可能记错订单号了,应该是12346",
"对了,你们退货政策是怎样的"
]
print("=== 开始对话 ===\n")
for user_input in dialogue:
# 调用链
response = chain_with_history.invoke(
{"input": user_input},
config={"configurable": {"session_id": SESSION_ID}}
)
# 手动更新摘要记忆(关键步骤!)
update_memory_with_new_exchange(SESSION_ID, user_input, response.content)
print(f"用户: {user_input}")
print(f"客服: {response.content}\n")
# -----------------------------
# 7. 查看当前记忆状态
# -----------------------------
print("\n=== 当前记忆内容 ===")
final_memory = get_summarized_history(SESSION_ID)
mem_vars = final_memory.load_memory_variables({})
print(mem_vars)
七、Langchain组件之Tools
要构建更强大的AI工程应用,只有生成文本这样的“ 纸上谈兵 ”能力自然是不够的。工具Tools不仅仅是“肢体”的延伸,更是为“大脑”插上了想象力的“翅膀”。借助工具,才能让AI应用的能力真正具备无限的可能,才能从“ 认识世界 ”走向“ 改变世界 ”。
Tools 用于扩展大语言模型(LLM)的能力,使其能够与外部系统、API 或自定义函数交互,从而完成
仅靠文本生成无法实现的任务(如搜索、计算、数据库查询等)
1.通过函数创建工具
from langchain_core.tools import tool
from pydantic.v1 import Field, BaseModel
"""这里起参数校验的作用"""
class AddNumberInput(BaseModel):
"""Input for add_number"""
num1: int = Field(description="The first number")
num2: int = Field(description="The second number")
@tool("add_tool", args_schema=AddNumberInput, return_direct=True)
def add(num1: int, num2: int):
"""两数相加"""
return num1 + num2
print(f"工具名称:{add.name}")
print(f"工具描述:{add.description}")
print(f"工具参数:{add.args}")
print(f"是否直接返回:{add.return_direct}")
print("1+1=" + str(add.invoke({"num1": 1, "num2": 1})))
2.StructuredTool 来创建工具
StructuredTool.from_function 类方法相比 @tool注解提供了更多配置项,并且不需要额外编写代码。其中,func 参数用于传入同步执行的函数,coroutine参数则用于传入异步执行的函数,其余参数的作用与前面介绍的相同
import asyncio
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
class AddNumberInput(BaseModel):
num1: int = Field(description="The first number")
num2: int = Field(description="The second number")
def add(num1: int, num2: int):
return num1 + num2
async def add_async(num1: int, num2: int):
return num1 + num2
add_tool = StructuredTool.from_function(
func=add,
name="add_tool",
description="两数相加",
args_schema=AddNumberInput,
coroutine=add_async,
)
print("1+1 =", add_tool.invoke({"num1": 1, "num2": 1}))
async def async_main():
result = await add_tool.ainvoke({"num1": 3, "num2": 5})
print("3+5 =", result)
def safe_run(coro):
try:
loop = asyncio.get_running_loop()
except RuntimeError:
asyncio.run(coro)
else:
loop.create_task(coro)
if __name__ == "__main__":
safe_run(async_main())
3.通过Runnables创建工具
通过可运行组件(Runnable)的 as_tool() 方法也可以创建工具。由于由多个可运行组件组成的链(Chain)本身也是一个 Runnable,因此可以直接调用 chain.as_tool() 方法,将整个链包装成一个工具
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
dotenv.load_dotenv()
class RandomInput(BaseModel):
"""Input for random_number"""
count: int = Field(description="The number of random numbers")
prompt = ChatPromptTemplate.from_messages([
("system", "请生成{count}个随机数")
])
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
parser = StrOutputParser()
chain = prompt | llm | parser
random_tool = chain.as_tool(name="random_tool", description="生成随机数",args_schema=RandomInput)
print("生成的随机数:\n",random_tool.invoke({"count": 5}))
综合示例:
使用工具:调用高德IP定位API(环境变量添加 GAODE_API_KEY="2dcbdfd56b965b671**c4cd")
import os
import dotenv
import requests
from langchain_core.messages import ToolMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
dotenv.load_dotenv()
# 1.================= 工具定义 =================
class GaoDeIpLocationInput(BaseModel):
ip: str = Field(description="The ip address")
def safe_str(value) -> str:
if isinstance(value, list):
return "".join(value)
if value is None:
return ""
return str(value)
class GaoDeIpLocationTool(BaseTool):
name: str = "ip_location_tool"
description: str = "高德IP定位API"
args_schema: type[BaseModel] = GaoDeIpLocationInput
def _run(self, ip: str):
url = f"https://restapi.amap.com/v3/ip?ip={ip}&output=json&key={os.getenv('GAODE_API_KEY')}"
res = requests.get(url).json()
if res.get("status") != "1":
return f"IP定位失败:{res.get('info', '未知错误')}"
province = safe_str(res.get("province"))
city = safe_str(res.get("city"))
return province + city if province or city else "无法定位该 IP"
class AddNumberInput(BaseModel):
num1: int
num2: int
class AddNumberTool(BaseTool):
name: str = "add_number_tool"
description: str = "两数相加"
args_schema: type[BaseModel] = AddNumberInput
def _run(self, num1: int, num2: int):
return num1 + num2
tools = {
"ip_location_tool": GaoDeIpLocationTool(),
"add_number_tool": AddNumberTool(),
}
# 2.================= Prompt & LLM =================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个智能助手,必须通过工具获取事实,不允许编造。"),
("human", "{query}")
])
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
llm_with_tools = llm.bind_tools(list(tools.values()))
# ================= 3.对话状态 =================
messages = []
print("💬 对话开始(输入 exit 退出)")
# ================= 4.主循环 =================
while True:
user_input = input("\n👤 ")
if user_input.lower() in {"exit", "quit"}:
break
# 用户消息
user_msg = prompt.invoke({"query": user_input}).to_messages()[-1]
messages.append(user_msg)
# LLM 判断是否调用工具
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
if ai_msg.tool_calls:
for tool_call in ai_msg.tool_calls:
tool = tools[tool_call["name"]]
print(f"🤖 调用工具:{tool.name}")
result = tool.invoke(tool_call["args"])
tool_msg = ToolMessage(
tool_call_id=tool_call["id"],
content=str(result)
)
messages.append(tool_msg)
# 基于工具结果生成最终回复
final_msg = llm.invoke(messages)
messages.append(final_msg)
print("🤖", final_msg.content)
else:
print("🤖", ai_msg.content)
八、本地安装AI大模型
8.1 windows安装大模型
8.11 ollama官网地址
https://ollama.com/
下载并安装ollama
8.12 设置AI模型安装路径
打开ollama,点击settings --> Model Location
这一步很重要,因为大模型很大,如果不设置好存储位置,电脑很快内存不足
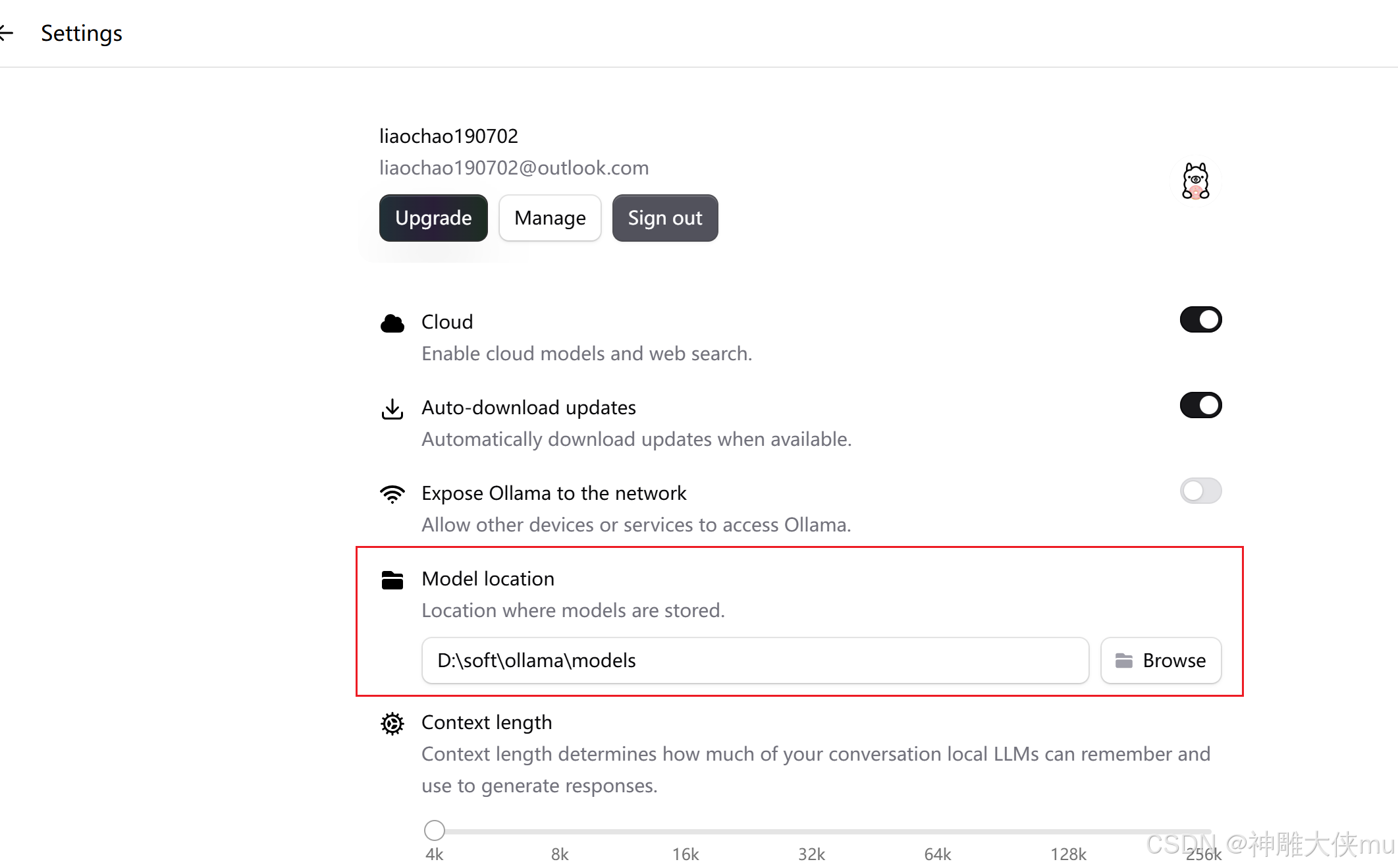
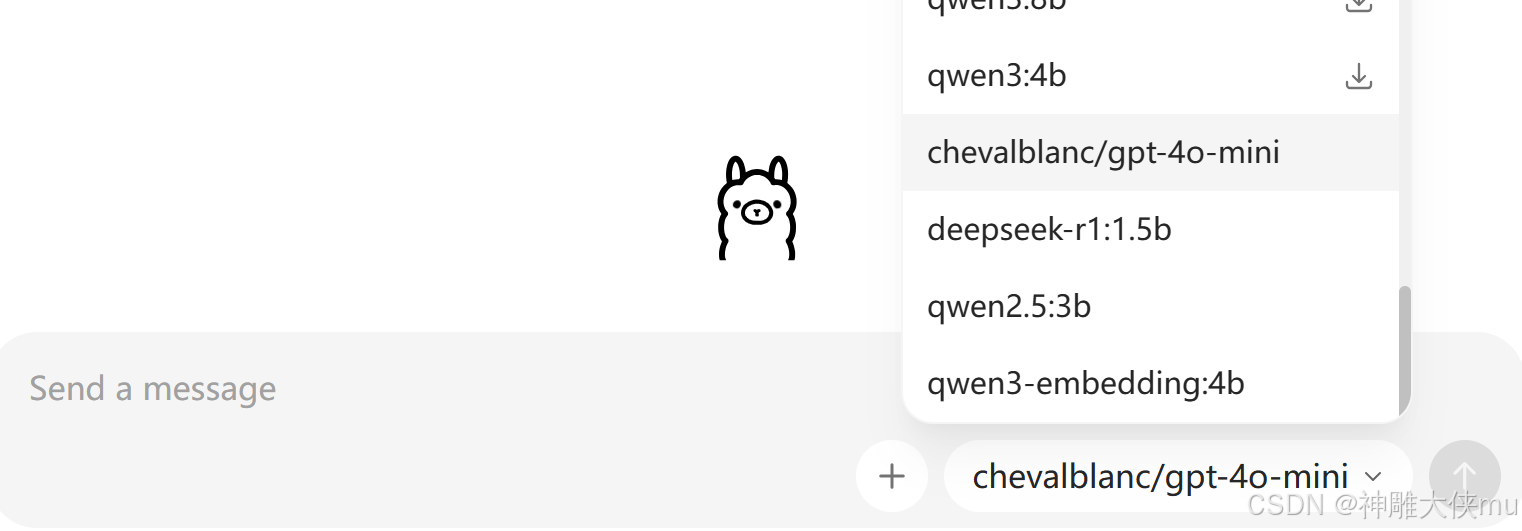
8.13 安装大模型
方式一,直接重ollama对话框下载
方式二,从命令行下载
查询大模型名字:https://ollama.com/search
打开命令行窗口:ollama pull 大模型名字
例如:ollama pull qwen3.5:27b
8.2 linux安装大模型
8.21 安装ollama
docker run -d \
- name ollama \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollama
8.22 进入ollama内部:
docker exec -it 3c64a52f59e1 /bin/bash
8.23 下载deepseek模型:
ollama pull 模型名ollama pull deepseek-r1:7b
8.24 卸载:
ollama rm 模型名ollama rm deepseek-r1:7b
8.25 运行:
ollama run 模型名ollama run deepseek-r1:1.5b
8.26 访问
[root@localhost ~]# curl -X POST http://192.168.174.198:11434/api/chat -H "Content-Type: application/json" -d '{
> "model": "deepseek-r1:1.5b",
> "messages": [{"role": "user", "content": "你好"}],
> "stream": false
> }'
{"model":"deepseek-r1:1.5b","created_at":"2026-03-13T05:28:34.809642192Z","message":{"role":"assistant","content":"你好!很高兴见到你,有什么我可以帮忙的吗?"},"done":true,"done_reason":"stop","total_duration":16919552045,"load_duration":15993640401,"prompt_eval_count":4,"prompt_eval_duration":112654402,"eval_count":17,"eval_duration":760324163}[root@localhost ~]#
8.27 代码中使用本地模型
llm = init_chat_model(model="qwen2.5:3b",model_provider="ollama",base_url="http://localhost:11434",api_key=SecretStr("ollama"))

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)