
vLLM本地大模型部署实战:OpenClaw 与 OpenAI 兼容 API 的深度集成
vLLM本地大模型部署实战:OpenClaw 与 OpenAI 兼容 API 的深度集成
开头:咱们自己搭 AI 的好日子来了
到 2026 年,跑大模型早就不是大厂的专利了,咱们在自家电脑上也能玩得转。随着开源模型越来越多,硬件性能也蹭蹭往上涨,大家伙儿都开始琢磨怎么在本地整一套 AI 环境。这么干不仅是因为数据在自己手里安全,关键是能随便折腾,还不用给云厂商交那些冤枉钱。
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
在这波浪潮里,vLLM 绝对是带头大哥。它推理速度极快,内存管得好,最重要的是它能假装自己是 OpenAI 的接口,用起来特别省心。而 OpenClaw 就像是个全能的遥控器,跟 vLLM 配搭起来,简直是强强联手。
第一章:扒一扒 vLLM 的家底和长处
1.1 vLLM 为什么跑得这么快?
vLLM 之所以能在大模型圈子里站稳脚跟,全靠它的“PagedAttention”黑科技。以前跑模型的时候,显存经常乱糟糟的,全是碎片,导致长对话一多就卡死。vLLM 聪明地借鉴了电脑操作系统的思路,把显存像切蛋糕一样切成一小块一小块的“分页”,哪里空了塞哪里,一点儿都不浪费。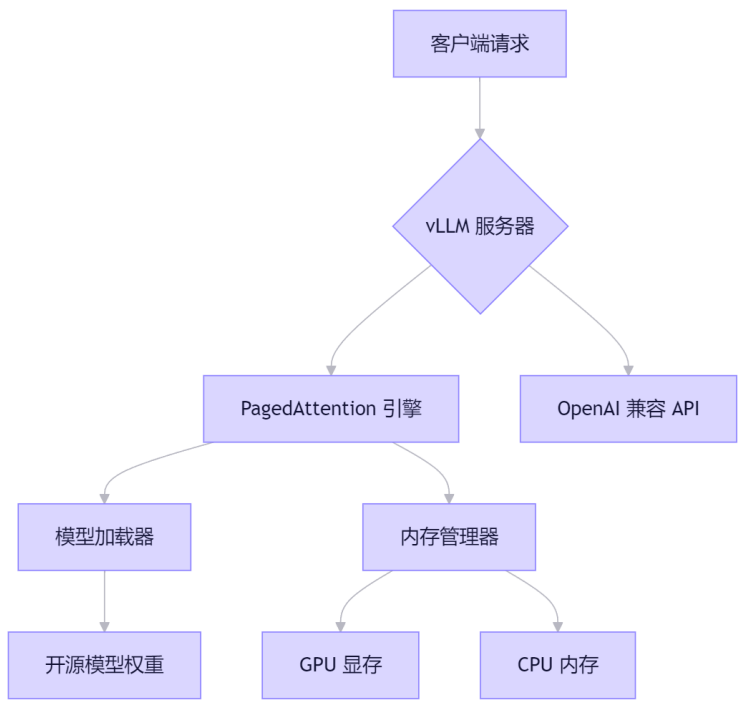
1.1.1 显存分页是怎么玩转的?
- 切分显存:把 KV 缓存拆成几 KB 的小块。
- 随用随给:模型需要多少就给多少,不用就赶紧收回来。
- 乱序存储:显存不需要连成一片,哪里有空钻哪里。
- 大家伙儿一起用:多个请求可以共用同一块显存,效率翻倍。
1.1.2 到底比别人强多少?
| 考核项 | 老法子 | vLLM (PagedAttention) | 进步了多少 |
|---|---|---|---|
| 出词速度 | 1倍速 | 3-5倍速 | 飞一样的感觉 |
| 显存利用率 | 6成左右 | 9成5以上 | 挤干了水分 |
| 同时处理人数 | 10个人 | 50多个人 | 战斗力翻倍 |
| 长文本抗压力 | 挺吃力的 | 12万字也不在话下 | 质的飞跃 |
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
1.2 假装自己是 OpenAI 的 API
vLLM 还有一个绝活:它提供的接口跟 OpenAI 是一模一样的。这意味着你以前写给 ChatGPT 的代码,现在改个地址就能直接用到本地模型上。
1.2.1 该有的接口全都有
它完全照搬了标准:
/v1/models:看看家里现在跑着几个模型。/v1/chat/completions:正儿八经的对话聊天。/v1/completions:老式的文本补全。/v1/embeddings:把文字转成数字向量。
1.2.2 格式长得也一样
请求的样子:
{
"model": "你的模型名字",
"messages": [
{"role": "system", "content": "你是个聪明的助手。"},
{"role": "user", "content": "你好呀!"}
],
"temperature": 0.7,
"max_tokens": 1000
}
回复的样子:
{
"id": "对话编号-123",
"object": "chat.completion",
"created": 1677652288,
"model": "你的模型名字",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "你好!今天有什么我能帮你的吗?"
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 25,
"completion_tokens": 15,
"total_tokens": 40
}
}
1.3 它能跑哪些模型?
基本上目前市面上火的开源模型,vLLM 都能跑得顺溜:
1.3.1 热门模型列表
- Llama 大家族:最新的 3.1 还有老版本的 Code Llama 等。
- 通义千问 Qwen:Qwen2.5 到老版本 Qwen1.5 全覆盖。
- Mistral 系列:从 7B 到超大的 8x22B 都能搞定。
- DeepSeek 深度求索:V3 和代码模型都能跑。
- 其他:像 Google 的 Gemma 和微软的 Phi 系列也不在话下。
1.3.2 怎么让配置要求更低?
如果显卡内存不够,vLLM 还支持变通方案:
- AWQ 量化:把模型体积压缩到 4-bit,质量还没怎么降。
- GGUF 格式:显卡和 CPU 一起分担工作。
- FP16/BF16:主流的半精度模式,性能和效果最平衡。
第二章:OpenClaw 怎么和 vLLM 配合?
2.1 聪明的自动识别
OpenClaw 挺机灵的,它能自动帮你把 vLLM 找出来,省得你手动填一堆乱七八糟的参数。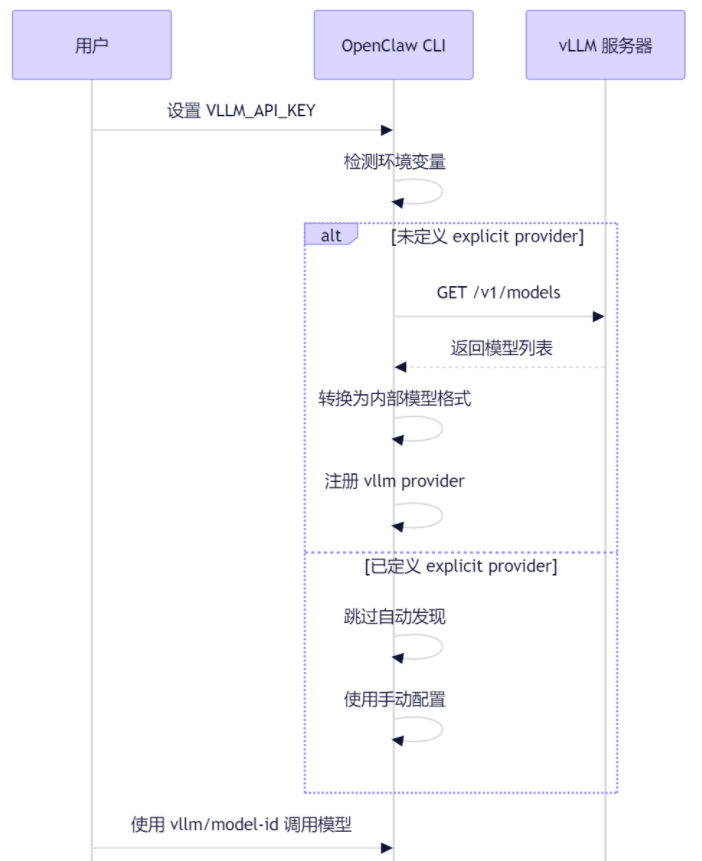
2.1.1 什么时候会启动自动识别?
只要满足下面这几个条件,它就自己动了:
- 你在环境变量里设了
VLLM_API_KEY。 - 配置文件里没写死 vLLM 的信息。
- vLLM 正好跑在默认的
http://127.0.0.1:8000/v1地址上。
2.1.2 名字是怎么变的?
为了方便管理,OpenClaw 会给模型改个名:
- 原本叫:
meta-llama/Llama-3.1-70B-Instruct - 进 OpenClaw 叫:
vllm/meta-llama/Llama-3.1-70B-Instruct
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
2.2 门禁和安全防范
虽然自家用的 vLLM 默认不锁门,但要是放到外网上,还是得加把锁。
2.2.1 设个暗号(环境变量)
最简单的办法就是设个密钥:
# 随便写一个也行
export VLLM_API_KEY="我的本地密钥"
2.2.2 认真配置一下
如果你想搞得正规点,就在配置文件里这么写:
{
models: {
providers: {
vllm: {
baseUrl: "http://127.0.0.1:8000/v1",
apiKey: "${VLLM_API_KEY}", // 从系统变量里拿
api: "openai-completions"
}
}
}
}
2.2.3 安全小贴士
- 别乱写密码:别把密码直接敲在文件里,容易泄露。
- 圈子缩小点:只让内网的人访问。
- 加个加密:正式用的时候套个 HTTPS。
第三章:快速上手配置
3.1 把 vLLM 服务器搭起来
咱们先把地基打好。
3.1.1 用 Docker 部署(最推荐)
这种法子最省心:
# 先把镜像拽下来
docker pull vllm/vllm-openai:latest
# 把 70B 的 Llama 跑起来
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--shm-size 1g \
vllm/vllm-openai:latest \
--model meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 4 \
--max-model-len 128000
3.1.2 直接在电脑上装
# 用 pip 装一下
pip install vllm
# 命令行启动
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 4 \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 128000
3.1.3 看看跑起来没
用 curl 试探一下:
curl http://127.0.0.1:8000/v1/models
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
3.2 配置 OpenClaw
地基打好了,现在来连线。
3.2.1 设个暗号
export VLLM_API_KEY="vllm-local"
3.2.2 定个默认模型
去改一下 ~/.openclaw/config.json5:
{
agents: {
defaults: {
model: {
primary: "vllm/meta-llama/Llama-3.1-70B-Instruct"
}
}
}
}
3.2.3 简单试一下
# 看看列表里有它没
openclaw models list
# 随便问它一句
openclaw agent --message "嘿,你是什么模型?"
3.3 遇到坑了怎么办?
3.3.1 连不上
症状:提示拒绝连接或者超时。
检查:
- 看看 vLLM 进程还在不在。
- 看看 8000 端口是不是被占了。
- 用 curl 在本地再试一次。
3.3.2 找不到模型
症状:报错说 Model not found。
检查:
- 确定
VLLM_API_KEY设好了没。 - 如果你改了端口,得去配置文件里显式写出来。
第四章:进阶玩家的显式配置
4.1 什么时候需要手动写配置?
自动识别虽然好,但有些特殊情况还得手动来。
4.1.1 端口改了
你要是没用默认的 8000 端口:
{
models: {
providers: {
vllm: {
baseUrl: "http://192.168.1.100:8080/v1",
apiKey: "${VLLM_API_KEY}",
api: "openai-completions"
}
}
}
}
4.1.2 想要精细控制
比如限制模型说话的长度:
{
models: {
providers: {
vllm: {
baseUrl: "http://127.0.0.1:8000/v1",
models: [
{
id: "meta-llama/Llama-3.1-70B-Instruct",
contextWindow: 128000,
maxTokens: 8192,
cost: { input: 0, output: 0 }
}
]
}
}
}
}
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
4.2 参数都代表啥?
baseUrl:服务器地址,记得最后带个/v1。api:给 vLLM 用的时候一定要写"openai-completions"。contextWindow:模型能记住多少之前的对话。cost:既然是自家的,全都填 0 爽歪歪。
4.3 到底听谁的?(优先级)
如果配置冲突了,OpenClaw 这么排位:
- 你临时敲的命令(最高级)。
- 你在配置文件里写的。
- 程序自己搜到的(最低级)。
第五章:多模型管理,想换就换
5.1 同时跑好几个模型
现在的显卡强,完全可以多开。
# 0号显卡跑模型1,1号显卡跑模型2
docker run --gpus '"device=0"' -p 8001:8000 vllm-model-1
docker run --gpus '"device=1"' -p 8002:8000 vllm-model-2
5.2 给模型派任务
你可以根据任务难易程度来分派:
- 杀鸡用小刀:简单的任务给 Mistral 7B 这种跑得快的。
- 攻坚用大炮:难缠的问题交给 Llama 70B。
{
agents: {
defaults: {
model: {
primary: "vllm-强大/Llama-3.1-70B",
fallback: "vllm-均衡/Qwen-32B",
backup: "vllm-快速/Mistral-7B"
}
}
}
}
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
5.3 盯着点性能
模型跑得累不累,得经常看看。
- 看显卡:敲个
nvidia-smi。 - 看日志:直接看 Docker 里的输出。
- 看成本:虽然不花钱买 token,但电费也是钱,还得考虑显卡坏了咋办。
第六章:公司里怎么整?
6.1 搞个像样的架构
在公司里用,不能像在自家电脑上那么随便。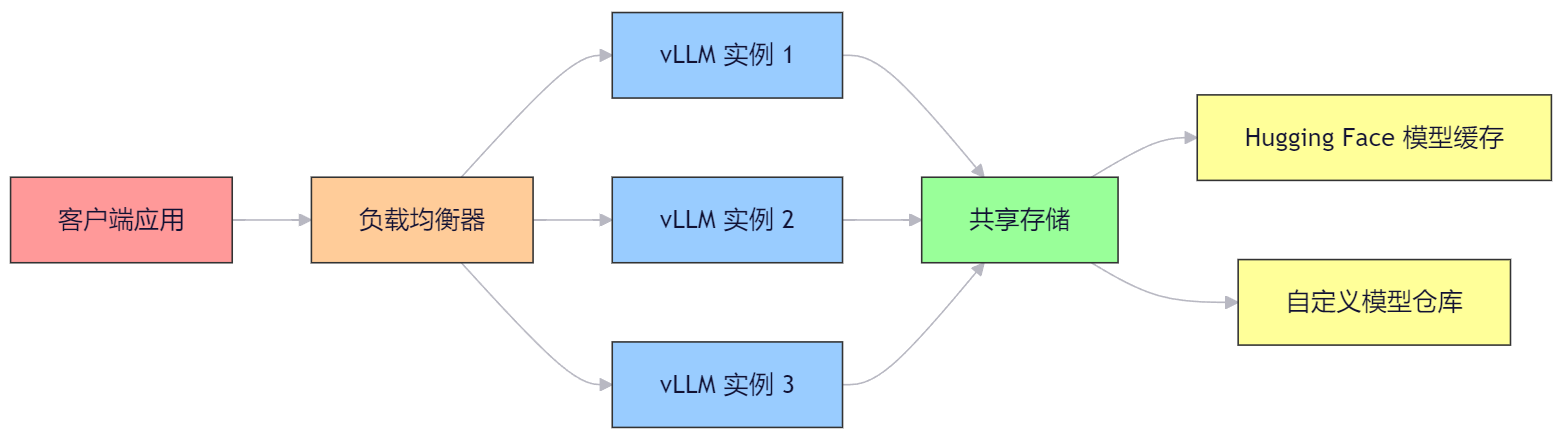
得用上 Kubernetes 搞容器编排,这样一个坏了另一个能顶上,还能根据人多人少自动增减机器。
6.2 墙得厚一点
- 不许乱看:把服务藏进公司内网。
- 查下成分:模型吐出来的东西要过一遍审核,别说些不该说的话。
- 日志脱敏:别把老板的秘密悄悄记到日志里去。
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
6.3 报警系统不能少
要是响应太慢或者老是报错,得赶紧让管理员知道。
第七章:vLLM 和其他方案比一比
7.1 大乱斗矩阵
| 方案 | 速度 | 省不省内存 | 兼不兼容 OpenAI | 好不好上手 |
|---|---|---|---|---|
| vLLM | 杠杠的 | 极好 | 满分 | 还可以 |
| TGI | 不错 | 挺好 | 差不多 | 略难 |
| llama.cpp | 一般 | 最好 | 能用 | 挺简单 |
| Ollama | 慢点 | 一般 | 能用 | 傻瓜式 |
7.2 怎么选?
- 追求高性能:选 vLLM,特别是公司用。
- 电脑配置一般:试试 llama.cpp,它能磨洋工。
- 就想赶紧跑起来:用 Ollama,几分钟搞定。
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定!
总结:掌握 AI 的主动权
把 vLLM 和 OpenClaw 凑一对,就是目前本地玩 AI 的最优解。这么干不只是为了省钱或者显摆,更重要的是把主动权握在自己手里。
随着开源大模型越来越厉害,这种“自己动手丰衣足食”的模式肯定会变成主流。现在就开始折腾起来,给未来搭个好梯子。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)