
AI Agent理论学习(一)
AI Agent理论学习随笔(主要学习了AI Agent的主要技术发展路线、核心组件架构与实践技巧)与学习资料整理
在人工智能领域,智能体被定义为任何能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过执行器(Actuators)采取行动(Action)以达成特定目标的实体。
一、Agent发展主要技术路线
- 编排类Agent(Orchestration-based Agents):编排类Agent采用“外挂式”架构,将大语言模型作为中央决策器,通过预定义的代码路径编排LLM与外部工具、API的交互,实现复杂任务的分解与执行。基础模型的推理能力提升是编排类Agent可用性质变的根本驱动力(从实验走向生产),基础模型的推理能力提升较为重要的是规划能力的内化,早期的编排框架需要通过复杂的提示工程来引导模型进行任务拆解,而新一代模型已经将这种能力内置。
- 端到端Agent模型(End-to-End Agent Models):端到端Agent模型则采用“内化式”架构,通过强化学习等技术将推理、规划、工具使用等能力直接训练到模型内部,让模型能够动态指导自己的过程和工具使用。
编排类Agent和端到端Agent模型在技术实现和应用场景上存在本质差异,这种差异决定了它们将长期并行发展而非相互替代。编排类Agent强调可控性与透明度,开发者可以精确控制每个步骤的执行逻辑,工具调用过程完全可见,这种特性使其在企业级应用中具有不可替代的优势。端到端Agent模型追求智能化与自主性,将决策过程内化到模型的推理中,减少了外部干预的需求,但这种内化也带来了可解释性和控制性的挑战。上述内容引自:企业白皮书与行业分析报告—共生伙伴:2025人工智能十大趋势|腾讯研究院。
核心概念解释:
- 规划能力(Planning Capability):指Agent在面对一个模糊或复杂的任务时,能够自主地将其分解为子任务、确定执行顺序、预测潜在问题并动态调整策略的能力(例如:ReAct、CoT、ToT等思维链技术)。
- 内化(Internalization):指将原本由外部框架、显式规则或人类预设流程承担的“规划与调度”逻辑,转化为模型内部的参数知识或推理机制。
注意事项:
1. 在早期的Agent框架(如LangChain的某些简单模式或硬编码的工作流)中,“编排”往往是由外部代码逻辑(Hard-coded workflows)、状态机或固定的模板决定的;
2. 当某个工具调用失败或环境发生了变化(遇到未预设的情况)时,内化了规划能力的Agent可以自动重新规划路径(Replanning),而硬编码容易报错或停滞。
二、AI Agent核心组件架构
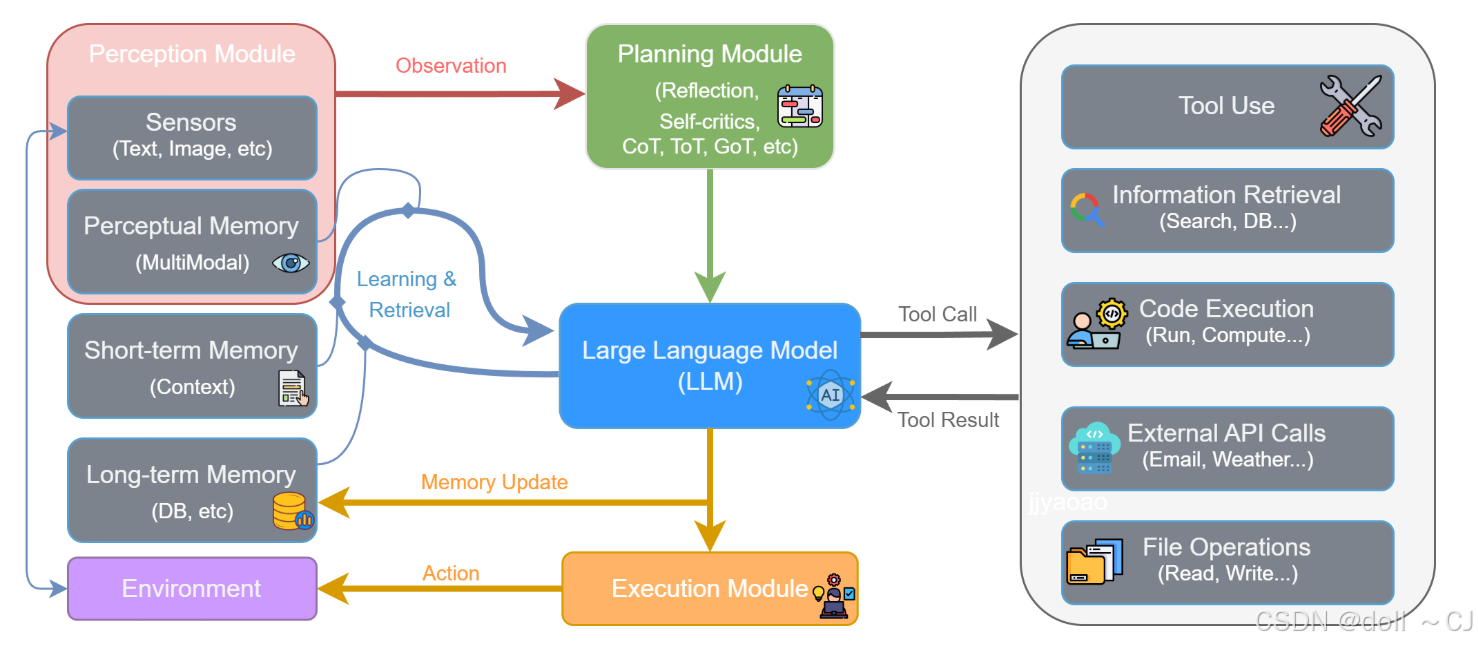
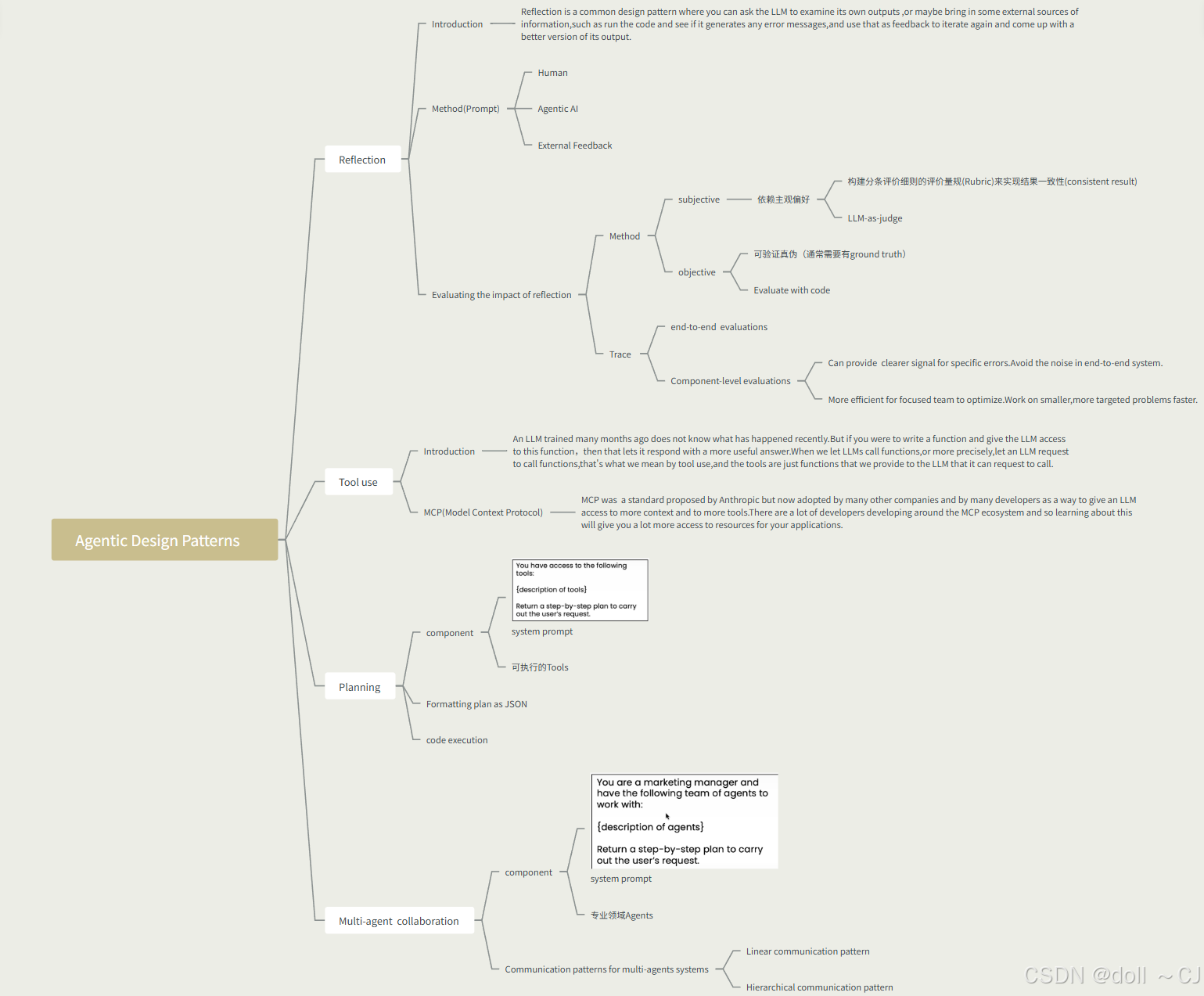
三、开发实践技巧
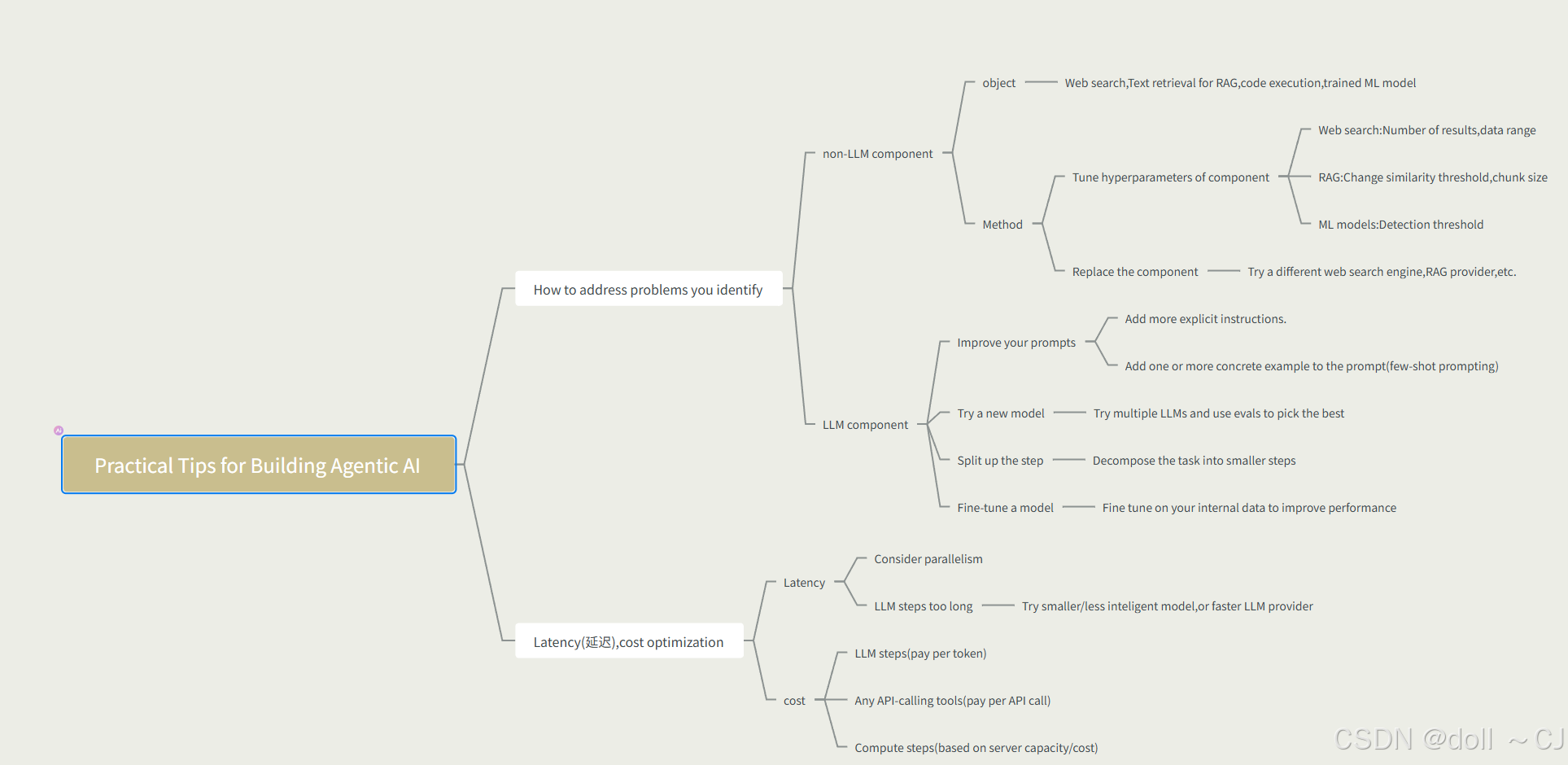
Tips for designing end-to-end evals
- Quick and dirty is ok to start.
- As you find places where your evals fail to capture human judgement as to what system is better,use that as an opportunity to improve the metric.
- Look for places where performance is worse than humans.
Tips for error analysis
- Develop a habit of looking at traces.
- Carry out error analysis to figure out what component performed poorly,leading to a poor final output.
- Use error analysis output to decide where to focus efforts.
Developing intuition for model intelligence
Play with models often.Having a personal set of evals might be helpful.
LLM模型的选择
选择大语言模型并非简单地追求“最大、最强”,而是一个在性能、成本、速度和部署方式之间进行权衡的决策过程。
(Arena Leaderboard | Compare & Benchmark the Best Frontier AI Models,由LMSys团队创建和维护的评估和比较大语言模型在开放对话场景中表现的大规模、众包式排行榜)
业界组织智能体的“思考”与“行动”过程最具代表性的三大经典架构范式
ReAct(Reasoning and Acting):一种将“思考”和“行动”紧密结合的范式,让智能体边想边做,动态调整。
Plan-and-Solve:一种“三思而后行”的范式,智能体首先生成一个完整的行动计划,然后严格执行。
Reflection:一种赋予智能体“反思”能力的范式,通过自我批判和修正来优化结果。
企业白皮书与行业分析报告
关键学习文档:
[4] langchain(Course Resources)
网络参考资料:
- https://github.com/Shubhamsaboo/awesome-llm-apps(Collection of awesome LLM apps with AI Agents and RAG)
- https://github.com/datawhalechina/hello-agents(Hello-Agents,从零开始构建智能体)
- https://happycapy.ai/(OpenClaw alternative.No setup.No security risks.)
商业竞品

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)