
OpenClaw的工程化困局:1.28亿Token灾难背后的架构反思
OpenClaw 20万Star的光鲜背后,运营者发现90%的时间花在工程问题上。Heartbeat与Cron双调度系统互相污染、Session熵增死亡螺旋、子Agent回调烧掉1.28亿Token——本文用5个确认Bug和4起灾难事件,深度拆解"用工程约束驯服模型"这条路为什么走不通。
文章目录
- 1、前言:90%的时间花在工程问题上,而非AI问题
- 2、OpenClaw 是什么
- 3、Heartbeat + Cron 双调度系统:设计初衷与实际冲突
- 4、SOUL.md / AGENTS.md:用Markdown配置约束LLM的本质矛盾
- 5、Session 持久化的熵增死亡螺旋
- 6、Token 灾难案例:当调度失控遇上缺失的熔断机制
- 7、安全漏洞:ClawJacked RCE 与恶意 Skills
- 8、与 Claude Code "渐进式信任"哲学的对比
- 9、核心洞见:当模型能力足够强时,工程约束从"保护"变成"枷锁"
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹
1、前言:90%的时间花在工程问题上,而非AI问题
先抛结论:OpenClaw 试图用工程约束驯服模型的"过度智能",结果工程本身成了最大问题。
这不是一句情绪化的吐槽,而是跑了半个月、6个Agent、对照了5个已确认Bug、4起Token灾难事件之后,社区运营者给出的精确总结:
“90% 的时间花在工程问题上,不是 AI 问题上。”
OpenClaw——这个上线数周破13万Star、目前已超20万Star的开源AI伴侣框架——暴露了一个AI Agent工程化的核心悖论:
- 产品诉求是"智能"、“自主”、“进化”
- 工程现实是"智能"在生产环境中经常是灾难——需要精确、可预测输出的场景里,"智能"反而是负面特性
本文将从架构设计、已确认Bug、Token灾难案例、安全漏洞四个维度,深度拆解 OpenClaw 的工程约束困境,并与 Claude Code 的"渐进式信任"哲学形成对比,探讨一个更宏观的问题:当模型能力足够强时,工程约束究竟是"保护"还是"枷锁"?
2、OpenClaw 是什么
OpenClaw(原名 Clawdbot / Moltbot)是一个开源的个人AI助手框架,GitHub 超过 20 万 Star,口号是 “Your own personal AI assistant. Any OS. Any Platform. The lobster way.”
核心定位:不具备推理能力的自主 Agent 框架——它自身没有大脑,需外接 Claude、GPT-4o、DeepSeek、Kimi 等 LLM 作为推理引擎,通过 WhatsApp / Telegram / Discord / 飞书 / 钉钉等消息渠道与用户交互。
2.1 架构全景:Hub-and-Spoke 中心辐射式
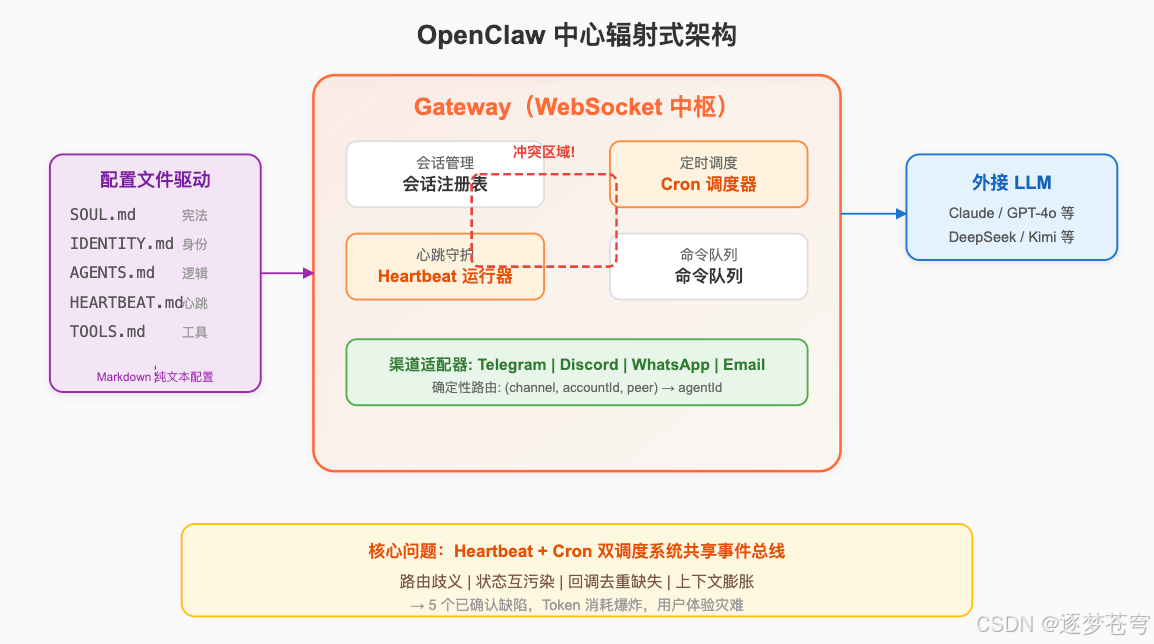
OpenClaw 以 Gateway(WebSocket 网关)为核心中枢,所有子系统通过标准化接口与其通信。Gateway 充当控制平面,负责:消息路由、Session 注册、Command Queue、Heartbeat Runner、Cron Scheduler。
2.2 “Workspace-First” 配置驱动
OpenClaw 的"身份系统"完全由 Markdown 配置文件驱动:
| 文件 | 作用 |
|---|---|
SOUL.md |
Agent 的"宪法"——核心价值观、对话风格、行为准则,每次唤醒时第一个加载 |
IDENTITY.md |
Agent 的姓名、自我认知、背景设定 |
AGENTS.md |
处理任务的逻辑、工具使用规则、工作流定义 |
HEARTBEAT.md |
心跳检查清单 |
TOOLS.md |
可用能力列表 |
这个设计的假设是:通过 Markdown 配置文件给模型足够的约束和上下文,模型就能自主运行。 后文会详细分析为什么这个假设在实践中崩塌。
3、Heartbeat + Cron 双调度系统:设计初衷与实际冲突
这是 OpenClaw 工程实践中暴露最多问题的领域。
3.1 两套调度系统的设计初衷
Heartbeat(心跳):
- 每隔 30 分钟(默认)自动唤醒 Agent 执行一轮完整推理
- 在主 Session 中运行,拥有完整的主会话上下文
- 读取
HEARTBEAT.md执行预定义检查(系统运行状态?日志报错?) - 设计意图:将多个周期性检查批量合并到单次心跳,利用完整上下文做智能判断
Cron(定时任务):
- 支持一次性定时、固定间隔、标准五字段 cron 表达式
- 可在主 Session 或隔离 Session 独立运行
- 持久化到
~/.openclaw/cron/jobs.json,跨重启保留
两套系统各有定位,但共享同一个 Gateway 事件总线——这正是灾难的起点。
3.2 五个已确认Bug详解
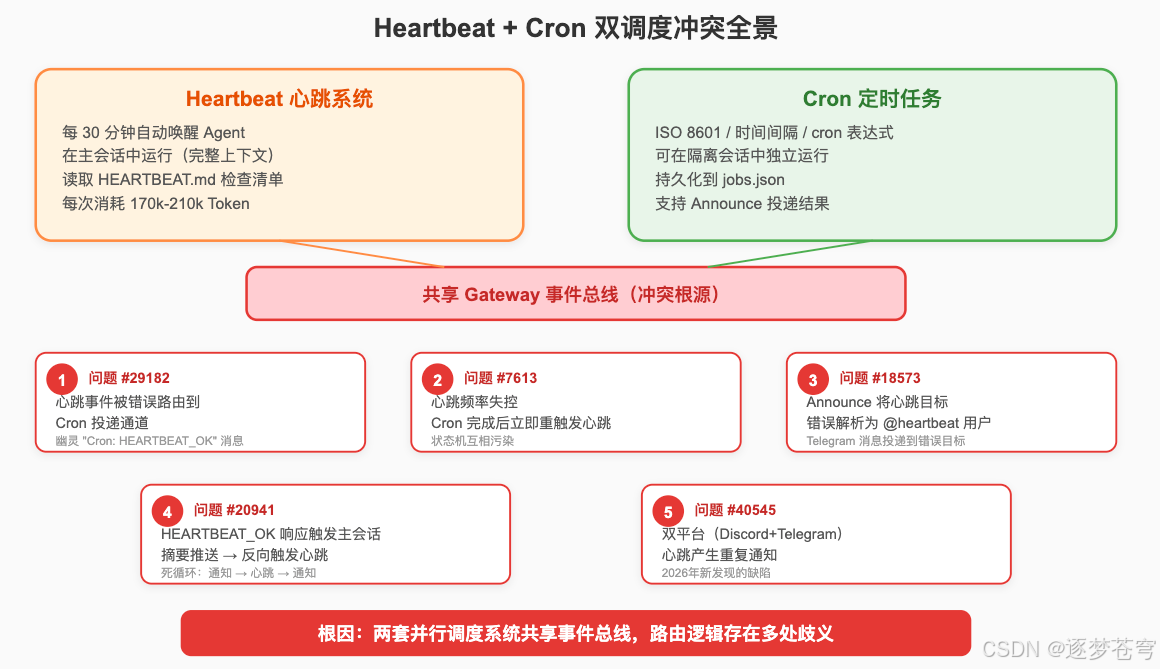
3.2.1 Bug #1:心跳事件被错误路由到 Cron 通道 (Issue #29182)
现象:心跳 Poll 事件被错误地通过 Cron 投递通道传递,而非通过原生心跳机制。隔离 Session 中出现幽灵 "Cron: HEARTBEAT_OK" 系统消息。
根因:网关 Session 事件处理器中的路由/投递路径错误——两套系统的事件类型没有被正确区分。
这个Bug看似简单,实则暴露了架构层面的问题:两套调度系统的事件标识符在 Gateway 层面没有严格隔离。
3.2.2 Bug #2:心跳触发频率失控,与 Cron 相互干扰 (Issue #7613)
现象:心跳机制在数秒到数分钟内反复触发,完全不遵守配置的 every 间隔。更诡异的是——切换到 Cron 调度方式后问题依然存在。
关键观察:10:02 时刻出现了一个不同 Cron 任务的系统消息前缀,但实际收到的 Prompt 是心跳 Prompt——两套调度系统的状态机互相污染。
这意味着两套系统不仅共享事件总线,还共享了某些状态变量。一个系统的完成事件会错误地触发另一个系统的执行。
3.2.3 Bug #3:Announce 投递把心跳目标解析为字面量 (Issue #18573)
现象:隔离 Cron 任务带 announce delivery 完成时,网关尝试将结果投递到 telegram:heartbeat——Telegram API 把 heartbeat 解释为用户名 @heartbeat,而不是解析心跳配置。
在投递 JSON 中显式添加 channel 和 to 字段无效,announce 机制完全忽略这些字段。
这是一个经典的标识符语义歧义:heartbeat 在系统内部是一个功能标识符,在 Telegram 生态中却是一个用户名。两套语义空间没有做任何隔离。
3.2.4 Bug #4:HEARTBEAT_OK 触发主 Session 摘要推送 (Issue #20941)
现象:隔离 Cron 任务以 announce 投递方式返回 HEARTBEAT_OK 时,网关会向主 Session 推送摘要,进而触发心跳系统,导致多余的用户通知。
死循环链条:Cron 完成 → HEARTBEAT_OK → 推送摘要 → 触发心跳 → 再次推送。
3.2.5 Bug #5:双平台心跳重复通知 (Issue #40545, 2026年新Bug)
现象:同时启用 Discord 和 Telegram 时,Cron/Heartbeat 产生重复的主动消息推送。
这个Bug在2026年才被发现,说明随着用户将 OpenClaw 部署到更复杂的多渠道场景,调度系统的冲突只会越来越多。
3.3 官方自己也承认:原生心跳是 “Token 黑洞”
在官方 Discussion #11042 中,核心贡献者建议:
- 禁用原生 Heartbeat,改用隔离 Cron Session 运行心跳逻辑
- 配合
openclaw-mem只加载最小必要状态 - 实现轻量级上下文模式
背景数据触目惊心:原生 Heartbeat 每次运行消耗约 170k–210k tokens(携带完整主 Session 上下文),且因触发频率失控(实测 ~10-20 秒触发一次),实际 token 消耗远超预期。
当官方都建议你禁用自己的核心功能时,这已经不是一个Bug的问题,而是架构设计层面的失败。
4、SOUL.md / AGENTS.md:用Markdown配置约束LLM的本质矛盾
4.1 设计理想
SOUL.md 被定位为 Agent 的"不可变宪法":
- 每次 Agent 唤醒时第一个加载
- Skills 和 Tools 必须在 SOUL.md 约束范围内运行
- 设计为不可被运行时覆盖(immutable principles)
AGENTS.md 定义任务处理逻辑和工具使用规则。
这套设计的核心假设是:只要配置文件写得足够精确,LLM就会严格遵守。
4.2 实践中的崩塌
来自真实用户6个Agent半个月运营的反馈:
| 现象 | 分析 |
|---|---|
| Agent 在"反思迭代"后自发给自己加了"AI/科技内容不超过40%"的配额限制 | LLM 的"智能"产生了未预期的自我约束——SOUL.md 没有这条规则,是模型自己加的 |
| Agent “智能压缩” Discord 消息时砍掉了关键数据表格 | 模型认为表格"不重要",但对用户来说是核心数据 |
| Agent "智能修复"自己的配置文件导致工具名错误 | 模型试图"优化"配置,反而引入了新错误 |
| 管家类 Agent 在 Session 膨胀后越界执行投资分析 | 上下文过长导致模型"遗忘"了 SOUL.md 的职责边界 |
核心矛盾:配置文件是文本,LLM 对文本的理解是概率性的,不是确定性的。你写了"不要做X",模型在上下文足够长、推理链足够复杂的情况下,完全可能"忘记"这条约束,甚至主动"优化"它。
这不是Prompt Engineering能解决的问题——调度系统的精确性要求与 LLM 的随机性本质冲突。
5、Session 持久化的熵增死亡螺旋
5.1 一个极端案例:7,069条消息的 Session
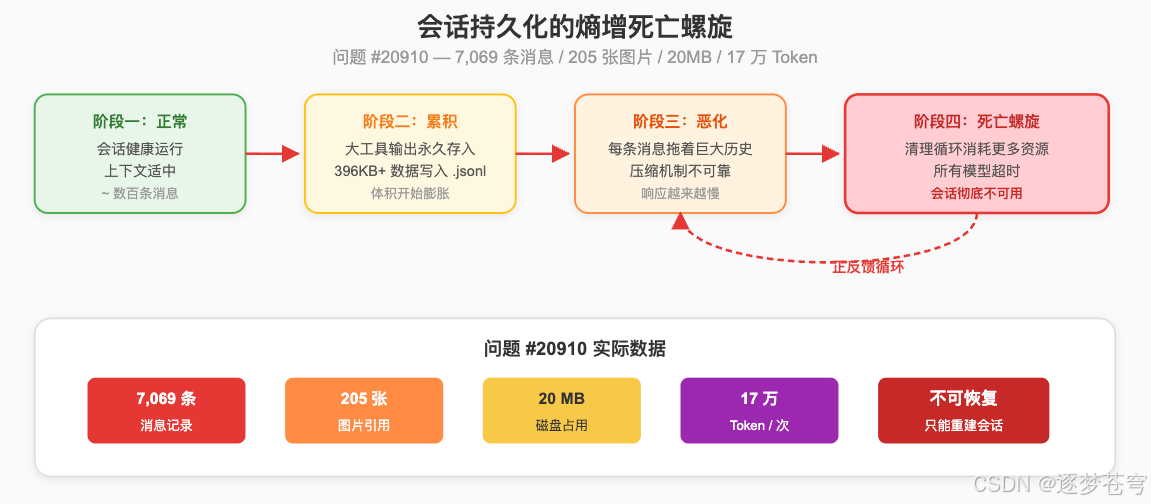
Issue #20910 记录了一个典型案例:Session 积累了 7,069 条消息、205 张图片引用、20MB 磁盘占用、17 万 token——网关进入死亡螺旋。
死亡螺旋的形成路径:
- 阶段一:正常运行,Session 健康
- 阶段二:大工具输出(例如
gateway config.schema返回 396KB+ JSON)被永久存入 Session.jsonl文件 - 阶段三:此后每条消息都拖着这个巨大历史块,Compaction 机制不可靠时问题急剧恶化
- 阶段四:每条新消息触发有问题的清理循环,消耗更多资源,所有模型超时——Session 彻底不可用
核心洞见:这不是Bug,是热力学——持续运行的 Agent 系统会确定性地走向崩溃。配置堆积、记忆过长、Session 膨胀不是"可能"发生,是"一定"发生,只是时间问题。
5.2 为什么这个问题在 OpenClaw 上特别严重
OpenClaw 的设计原则之一是本地优先存储 + 永久 Session,所有状态本地持久化。这意味着:
- 没有服务端的自动清理机制
- 没有 Session TTL(生存时间)
- Compaction(压缩/摘要)完全依赖 LLM 的"智能"——但 LLM 的摘要可能丢失关键信息
- 用户只有手动重建 Session 一条路
6、Token 灾难案例:当调度失控遇上缺失的熔断机制

6.1 Case 1:子Agent回调无限循环 — 1.28 亿 Token (Issue #17442)
这是最触目惊心的案例:
- 根本原因:隔离 Cron Session 中子 Agent 完成回调从不被标记为"已投递"
- 后果:约每 3 秒无限重注入回调,每次回调携带完整 Session 历史(指数级增长)
- 实际损失:2,258 次相同回调投递,消耗约 1.28 亿 token($100+),如不手动终止会无限持续
一个简单的布尔标记缺失,导致了上亿 token 的浪费。
6.2 Case 2:单日 2150 万 Token — 静默的配置不兼容
- Config 不兼容导致 Compaction 静默禁用
- 超大历史记录被持续重放:cacheRead 占比 79.4%,output 仅占 0.4%
- 用户看不到任何异常——因为系统没有 token 消耗告警机制
6.3 Case 3:16 分钟 $4.85 — 无熔断的失控
- Agent 卡在失败的 AppleScript Chrome 自动化任务中反复重试
- 16 分钟内 123 次 Opus 4.5 API 调用,每次约 80K cached tokens + extended thinking
- 直到触及 Anthropic 速率限制才停止——系统没有任何 runaway session 熔断机制
6.4 Case 4:Cron 脚本无限重试 — 750 万+ Token (Issue #28533)
- Cron 任务的
agentTurnpayload 运行 Bash 脚本超时 - Agent 进入无限重试循环,每约 2 秒重新执行同一命令
- 498 次 turn × 不断增长的上下文 = 750万+ Token 浪费
四个案例的共同根因:缺乏 runaway session 熔断机制 + 回调/重试去重缺失。这不是个别Bug,是系统级的设计缺陷。
7、安全漏洞:ClawJacked RCE 与恶意 Skills
2026 年初,OpenClaw 连续爆出严重安全漏洞:
7.1 ClawJacked — WebSocket 劫持远程代码执行
CVE-2026-25253:Control UI 对 URL 参数无验证,允许跨站 WebSocket 劫持,实现一键远程代码执行(RCE)。
Censys 检测到 21,639 个公开暴露的 OpenClaw 实例——这些都是潜在的攻击目标。
7.2 恶意 Skills 泛滥
ClawHub 市场中发现 335 个恶意 Skills,伪装成正常工具,实际安装键盘记录器或 Atomic Stealer 恶意软件。
7.3 提示注入 + 数据泄露
Telegram/Discord 的链接预览功能被利用,触发 Agent 向攻击者控制的 URL 发送用户机密数据。
安全问题的根因:OpenClaw 作为本地守护进程长期运行,暴露 WebSocket 端口,且其"开放生态"(Skills 市场)缺乏足够的安全审查。这与 Claude Code 的终端交互模式形成鲜明对比——后者不暴露网络端口,攻击面天然更小。
8、与 Claude Code "渐进式信任"哲学的对比
8.1 Claude Code 的核心设计理念
Claude Code 的管理者 Ben Mann 的一句话奠定了整个产品方向:
“Don’t build for today’s model, build for the model six months from now.”
这意味着:不用大量工程化约束弥补当前模型的不足,而是相信模型能力会持续提升,为更强的模型留出空间。
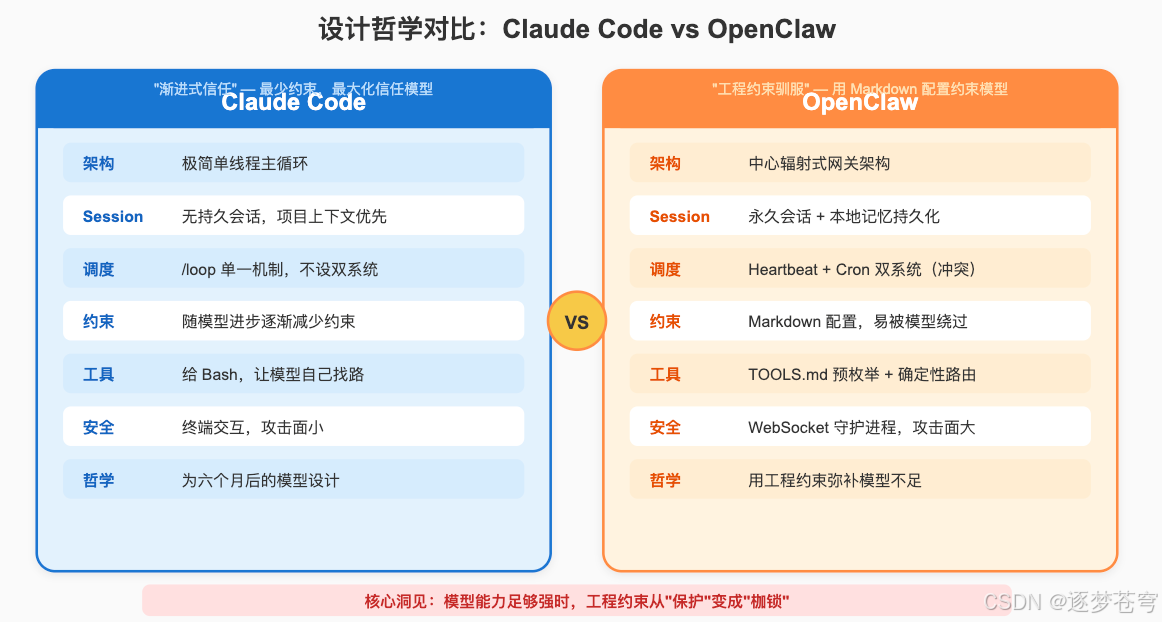
关键设计决策:
| 决策 | 说明 |
|---|---|
| 极简单线程主循环 | while (model produces tool_call) { execute; feed back; } 循环自然结束 |
| 最多一层子Agent | 防止不受控的 Agent 增殖,子 Agent 不能再生成子 Agent |
| 给 bash,不造专用工具 | 模型会自发用 bash 查 git 历史——glob + grep 超过了精心设计的 RAG |
| 无持久 Session | 不累积历史包袱,每次对话从项目上下文出发 |
8.2 "渐进式信任"的实证
对 Claude Code 1.x 到 2.0 系统提示词的详细对比,揭示了清晰规律——约束在持续减少:
| 版本 1.x(强制) | 版本 2.0(弱化或删除) |
|---|---|
"You MUST answer concisely with fewer than 4 lines" |
"A concise response is generally less than 4 lines" |
"One word answers are best" |
"Brief answers are best, but provide complete information" |
"VERY IMPORTANT: You MUST avoid using search commands" |
"Avoid using Bash with find, grep... unless explicitly instructed" |
| 关于代码风格的整个章节 | 已删除 |
有趣的反例:Git 安全约束(force push 等高风险操作)反而被加强了。
这说明策略是精准的:模型能自主掌握的行为从提示词中删除;真正高风险的操作持续强化明确约束。 而 OpenClaw 的做法恰好相反——试图用更多的 Markdown 配置来约束模型的一切行为。
8.3 核心差异总结
| 维度 | Claude Code | OpenClaw |
|---|---|---|
| 持久化 | 无持久Session,项目上下文优先 | 永久Session + 本地记忆 |
| 调度 | /loop 单一机制 |
Heartbeat + Cron 双系统 |
| 约束哲学 | 随模型进步减少约束 | 用配置累积约束 |
| 安全模型 | 终端交互,攻击面小 | WebSocket守护进程,攻击面大 |
| 工具设计 | 给bash,让模型自己找路 | 预枚举工具 + 确定性路由 |
9、核心洞见:当模型能力足够强时,工程约束从"保护"变成"枷锁"
回到文章开头的结论。OpenClaw 的问题不在于功能太少,而在于:
试图用文本配置约束 LLM 的"过度自主性",导致工程问题远多于 AI 问题。
这映射了 AI Agent 工程化的更宏观规律:
当模型能力不够强时,工程化约束是弥补手段;当模型能力足够强时,工程化约束变成负担。
OpenClaw 的六大工程设计原则——默认串行执行、本地优先存储、单进程架构、纯文本配置——每一条在理论上都是合理的。但当这些原则组合在一起,并且需要支撑一个持续运行、自主决策的 Agent 系统时,复杂度呈指数级增长:
- 双调度系统的 5 个已确认 Bug → 调度精确性 vs LLM 随机性的冲突
- Session 熵增死亡螺旋 → 永久持久化 vs 有限上下文窗口的冲突
- SOUL.md 被"智能"绕过 → 文本约束 vs 概率性理解的冲突
- Token 灾难无熔断 → 自主运行 vs 成本控制的冲突
- ClawJacked RCE → 开放生态 vs 安全边界的冲突
发挥模型能力的关键,不是让模型管理自己的调度和约束,而是在精确的执行边界内给模型充分的推理空间。Claude Code 选择了极简的架构——单线程循环、无持久Session、bash即工具——把复杂度留给模型而非工程。而 OpenClaw 选择了工程化的重武器——双调度系统、永久Session、Markdown宪法——试图用工程手段驯服模型。
结果证明:工程越重,工程问题越多。
从装好 OpenClaw 到系统流畅运作再到 Agent 自主进化之间,有巨大的鸿沟。不加约束,entropy 只增不减。持续运行的 Agent 系统会确定性地走向崩溃——不是"可能",是"一定"。
而这,恰恰是 AI Agent 工程化最深刻的教训。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注公众号 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)