
英伟达GTC 2026:剑指万亿美元订单,算力封神与龙虾狂欢
加州圣何塞的阳光依旧明媚。当地时间2026年3月18日上午11点18分,身穿标志性黑色皮衣的黄仁勋准时登场。英伟达GTC大会的舞台上,全场超过30000名观众屏息凝神,等待一场科技盛宴的开席。英伟达豪掷200亿美元收购的Groq核心技术、引发全民狂欢的OpenClaw智能体、Vera Rubin旗舰AI计算平台,共同将智能体时代推向高潮。让我们从英伟达最新5大机架系统与7款量产芯片,开放智能体生态
加州圣何塞的阳光依旧明媚。
当地时间2026年3月18日上午11点18分,身穿标志性黑色皮衣的黄仁勋准时登场。

英伟达GTC大会的舞台上,全场超过30000名观众屏息凝神,等待一场科技盛宴的开席。
英伟达豪掷200亿美元收购的Groq核心技术、引发全民狂欢的OpenClaw智能体、Vera Rubin旗舰AI计算平台,共同将智能体时代推向高潮。
让我们从英伟达最新5大机架系统与7款量产芯片,开放智能体生态的演进,L4级别自动驾驶,近地轨道数据中心的物理世界扩展蓝图等,一窥英伟达的庞大生态帝国。
算力盛宴与技术狂飙
2025年英伟达的订单额约为5000亿美元,黄仁勋笃定地预估,到2027年,数字将翻倍至1万亿美元。
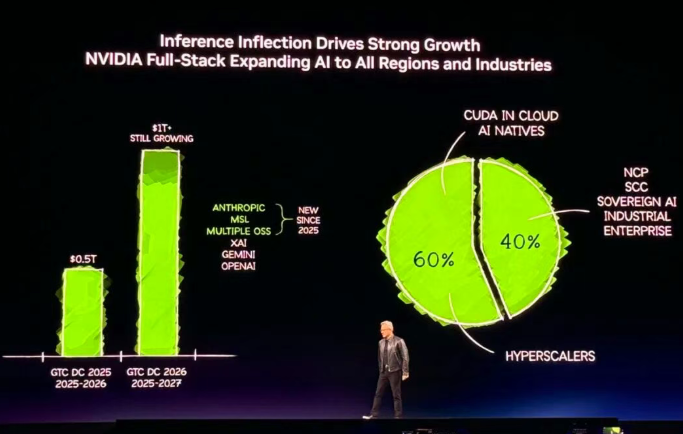
20年前的2006年,英伟达顶着巨大的财务压力,消耗公司绝大部分利润发明了CUDA。历经13代产品更迭,如今CUDA已经无处不在。

过去两年间,ChatGPT、生成式大模型以及Claude Code等技术应用持续推动产业浪潮。
庞大的计算需求彻底引爆市场,现货算力价格飞涨。
英伟达与IBM达成了深度合作,同时向谷歌云、AWS、微软Azure等云服务巨头输出算力。


把OpenAI带到AWS,成为今年最让黄仁勋兴奋的合作案例之一。
五大机架组出终极超算
黄仁勋笃信,只有在人工智能工厂里安置最好的计算系统,才能获得最低的Token成本。
依靠极致的协同设计,英伟达做到了全球最低且不可超越的成本控制。
全新Vera Rubin平台正是瞄准推理计算市场的王牌。仅仅用了10年时间,算力被提升了4000万倍。

7款全新芯片、5种机架级计算机以及1台革命性超算,构成了专为智能体打造的基础设施。

在架构路线图方面,Oberon系统采用铜缆纵向扩展,并且可以使用光学扩展,将NVLink扩展到576。铜缆与光学两种扩展方式均被采纳。
Rubin Ultra芯片正在流片,即将问世。全新的LP35芯片将首次融入NVFP4计算结构,带来数倍的速度提升。
Oberon之后的Kyber系统,除了采用铜缆纵向扩展,还会推出Kyber CPO纵向扩展,首次同时支持铜缆和共封装光学的纵向扩展。
计划在2028年发布的扛鼎之作也同步曝光,包括采用定制HBM的Feynman GPU、LP40 NVLink、Rosa CPU、Bluefield-5 DPU、NVLink 8 CPO、Spectrum7 204T CPO以及ConnectX-10 SuperNIC。

目前7款全新芯片已全面量产,可在超大型人工智能工厂中规模化部署。基于Rubin的产品将从下半年开始由合作伙伴提供。
现场一口气发布的5款机架级系统,以统一的MGX模块化架构进行深度协同设计,能够按负载密度和价格梯度灵活组合。
Vera Rubin NVL72 GPU机架集成了由NVLink 6链接的72颗GPU与36颗Vera CPU,外加ConnectX-9和BlueField-4。
相比前代Blackwell平台,训练大型混合专家模型所需的GPU数量大幅减少至四分之一。推理吞吐量提升10倍,单位成本降至十分之一。
混合专家模型通过引入门控网络,每次只激活最擅长处理当前任务的部分神经网络,极大节省了计算资源。
不同模型尺寸、智能程度、速度和上下文长度对应不同的价格区间。英伟达力求在每一个细分层级都大幅提升吞吐量。
大会现场展示的数据图表清晰划分了多个性能层级。
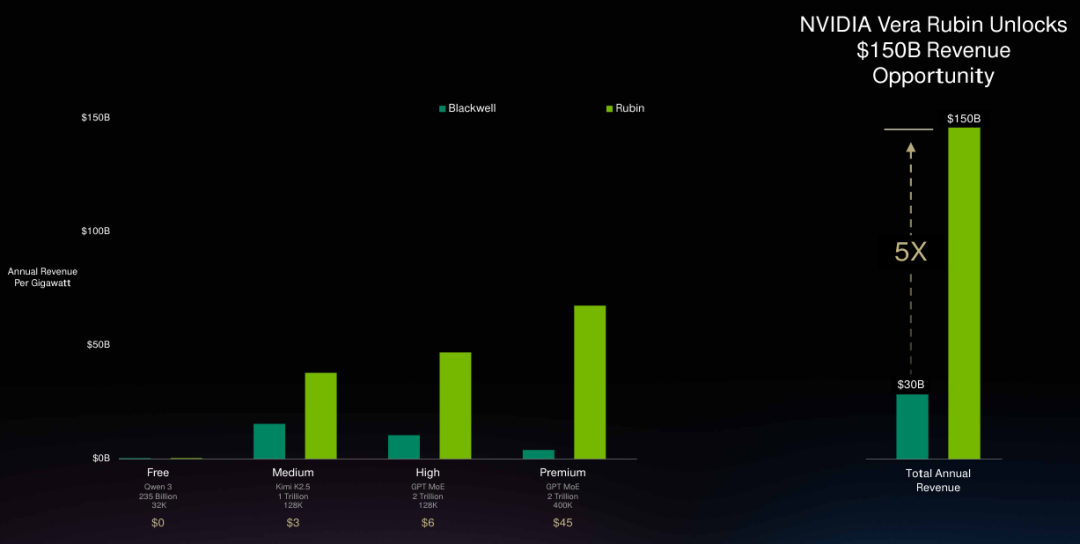
免费层以千问3 235B 32K模型为代表,中级层对应Kimi K2.5 1T 128K模型,高级层处理GPT MoE 2T 128K模型,旗舰层则剑指GPT MoE 2T 400K模型的极限带宽与低延迟需求。
吞吐量需要海量算力支撑,延迟与交互性则需要巨大的带宽。芯片面积终究有限,追求高吞吐量与追求低延迟天然冲突。
为此,英伟达祭出了杀手锏。去年12月,英伟达斥资200亿美元拿下创企Groq的非独家协议和核心团队。
业界曾担忧Groq的LPU会威胁GPU的地位。如今谜底揭开,LPU完美融入了GPU生态。Rubin性能强悍,LPU带宽高且延迟低,二者优势互补。
全新集成的Groq 3 LPU实现了超强算力与超高带宽的融合。

数据对比极为悬殊,一张Rubin GPU拥有3360亿颗晶体管、288GB内存容量、每秒22TB带宽、50PFLOPs(千万亿次浮点运算每秒)算力。
一张Groq 3 LPU仅有980亿颗晶体管、500MB片上SRAM(静态随机存取存储器),内存容量只是前者的五百分之一,算力为1.2PFLOPS。
LPU的SRAM带宽高达每秒150TB,大约是Rubin的7倍。SRAM如同直接放置在工人手边的工具箱,虽然容量小,但存取速度极快且没有延迟波动,彻底消除了外部高带宽内存带来的数据拥堵。
NVIDIA Groq 3 LPX推理加速器机架应运而生。

新机架支持256张Groq 3 LPU,拥有128GB片上SRAM、315PFLOPS算力以及每秒640TB扩展带宽,甚至可扩展至超过1000张LPU。
Groq的计算系统是一种确定性数据流处理器。系统通过编译器预先排布好一切,数据何时到达、何时计算都在软件中静态预排,没有动态调度。海量SRAM专为推理这一单一负载设计。
由于受限于SRAM容量,必须使用大量Groq芯片才能存储模型的庞大参数以及必须配套的KV Cache。英伟达利用Dynamo软件重新构建推理管线,把适合的工作放在Vera Rubin上运行,将低延迟、带宽受限的解码生成部分卸载到Groq上。
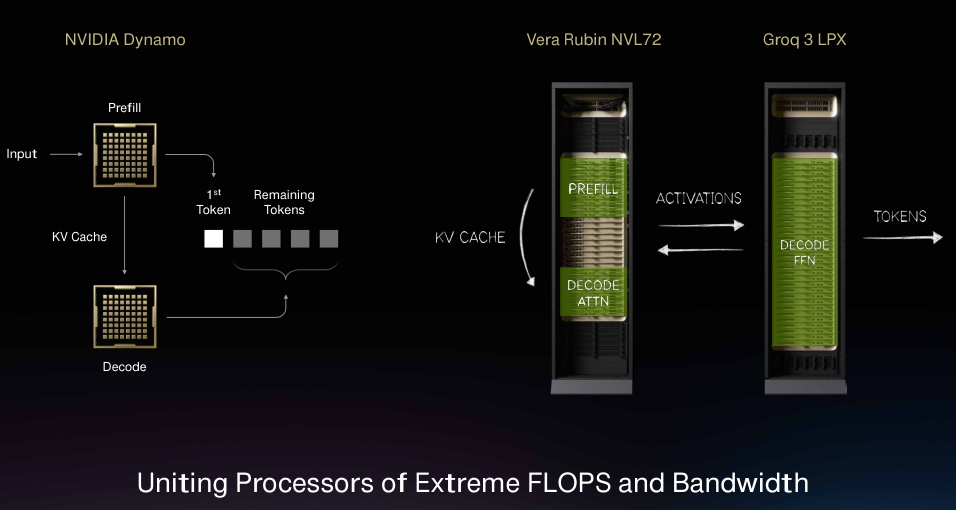
两者协同,在运行万亿参数模型时,可将每兆瓦推理吞吐量提升35倍。三星代工的Groq 3 LPU已进入量产,预计下半年出货。
智能体的训练和部署推理同样离不开CPU。GPU需要调用CPU执行工具调用、查询和代码编译等任务。
NVIDIA Vera CPU机架搭载256台液冷Vera CPU,提供400TB内存、每秒300TB内存带宽,集成64颗BlueField-4,全面兼容生态系统。
Vera搭载全新Olympus核心,是全球唯一使用LPDDR5的数据中心处理器。
相比传统x86架构,Vera单线程性能提升50%,每核心内存带宽提升至3倍,能效直接翻倍。
初步芯片测试显示,Vera在各类负载上的性能提升从2倍到超过5倍不等。
随着智能体应用规模扩大,上下文窗口增长,传统存储会拖慢推理速度。
NVIDIA BlueField-4 STX存储机架作为一个原生基础设施,结合Vera CPU和网卡,将内存无缝扩展至计算集群。
STX提供高带宽共享层,专门用于存储和检索海量键值缓存数据。能效比提升至4倍,企业数据翻页速率提升至2倍,让记忆处理速率快5倍。
所有的系统都需要网络连接。NVIDIA Spectrum-6 SPX以太网机架用于全数据中心横向扩展。带有共封装光学器件的以太网光子技术,实现了多达5倍的光学功率效率和10倍的弹性。
为了帮助数据中心生态系统提升效能,英伟达发布了Vera Rubin DSX参考设计。
这是一套基础设施蓝图,指导如何设计、构建和操作整个堆栈。基于Rubin平台部署架构后,人工智能工厂能在固定功耗下实现能效比提升30%,并增加30%的算力部署规模。
NVIDIA Omniverse DSX蓝图为大型工厂设计和模拟提供数字孪生。开发者通过各种API接入。
DSX Sim用于物理、电气、热力和网络仿真。DSX Exchange用于运营数据交换。DSX Flex用于电网与数据中心之间安全的动态功率管理。DSX Max-Q用于动态最大化Token吞吐量。
会议期间同步发布的NVIDIA RTX PRO 4500 Blackwell服务器版,为全球企业数据中心和边缘计算平台带来多工作负载加速功能。
计算的边界并未止步于地球。
黄仁勋自豪地宣布人类的算力已经进入太空。英伟达拥有抗辐射的GPU,并在卫星上进行成像处理。未来还将在太空中建造数据中心。
太空环境十分复杂,没有传导,没有对流,只能依靠辐射散热。冷却系统成为巨大的挑战。英伟达正与合作伙伴研发新型计算机NVIDIA Space-1 Vera Rubin Module。

面向太空优化的计算模块支持实时感知、决策和自主运作,将数据中心级的性能带到轨道、地理空间智能以及自主空间运营领域。
龙虾出圈与智能体生态
红色龙虾出现在大屏幕的刹那,观众席瞬间沸腾。
今年领域的头号顶流,开源智能体框架OpenClaw,黄仁勋给予了极高评价,称其为人类历史上最受欢迎的开源项目。
OpenClaw仅仅几周内就超越了Linux操作系统用30年取得的成就。
OpenClaw本质上就是智能体计算机的操作系统。就如同Windows系统使得个人电脑得以普及,OpenClaw让个人智能体的创建变得触手可及。
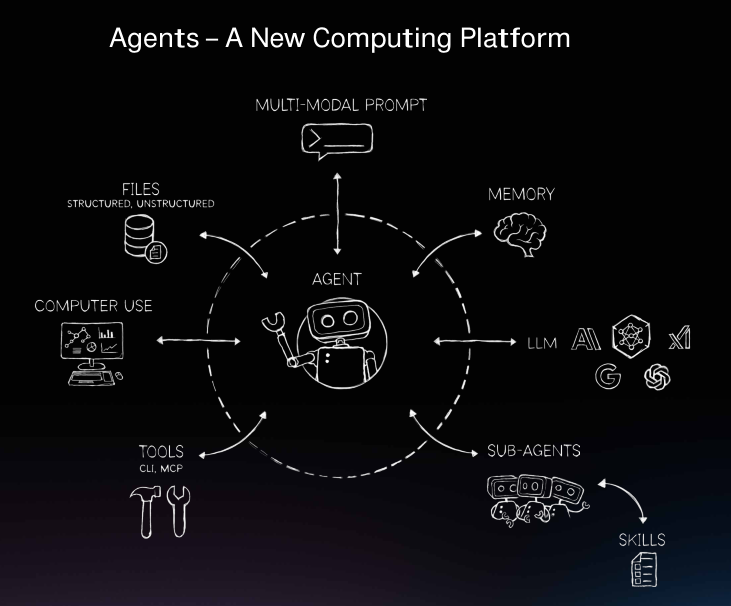
全民养虾热潮正推动算力需求呈数量级增长。开发者将部署OpenClaw戏称为养龙虾。随之而来的风险不容忽视,智能体可能自主访问敏感数据、滥用已连接的工具或自行提升权限。
英伟达贴心地端出养龙虾全家桶。软件涵盖英伟达版龙虾NemoClaw、基础模型Nemotron 3 Ultra以及工具包。
硬件则有个人AI电脑DGX Spark和桌面级超算DGX Station。
大会期间的GTC Park每天都在举办部署活动。参会者带上自己的笔记本电脑,在专家的帮助下本地部署智能体,打造专属助手。
英伟达与OpenClaw创始人团队紧密合作,汇聚全球顶尖安全和计算专家,将开源版本改造为具备企业级安全性和隐私能力的参考设计。
该设计被称为英伟达OpenClaw参考设计。只需一条命令,NemoClaw就能完成优化安装。NVIDIA OpenShell提供开放模型和增强隐私安全性的独立沙盒环境,按照预定护栏开发新技能、完成任务,使用户能在企业内部安全地约束龙虾的执行。运行平台涵盖云端、本地部署以及各类专用超算设备。
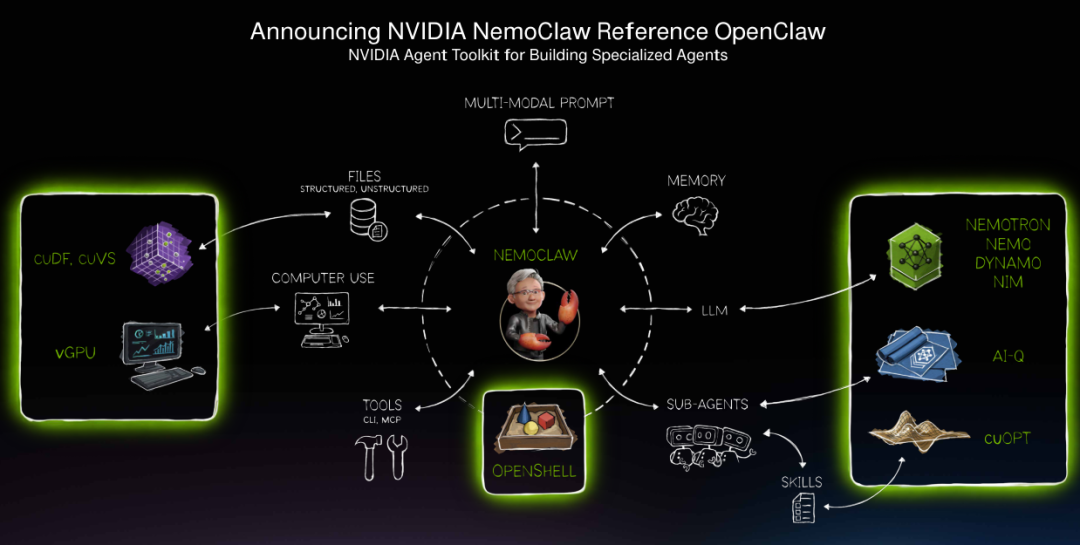
英伟达智能体工具包是一套开放模型、运行时和蓝图的集合。以Nemotron为起点,配备NeMo用于性能分析与优化,NIM提供推理服务,Dynamo负责规模化扩展。
AI-Q作为一个开源蓝图,融合前沿与开放模型的智能,打造全球领先的面向长期工作流的研究型智能体。
软件的世界已经改变。每一家软件即服务公司都将被重塑为智能体即服务公司。企业停止销售传统软件工具,转而向客户出租智能体服务。
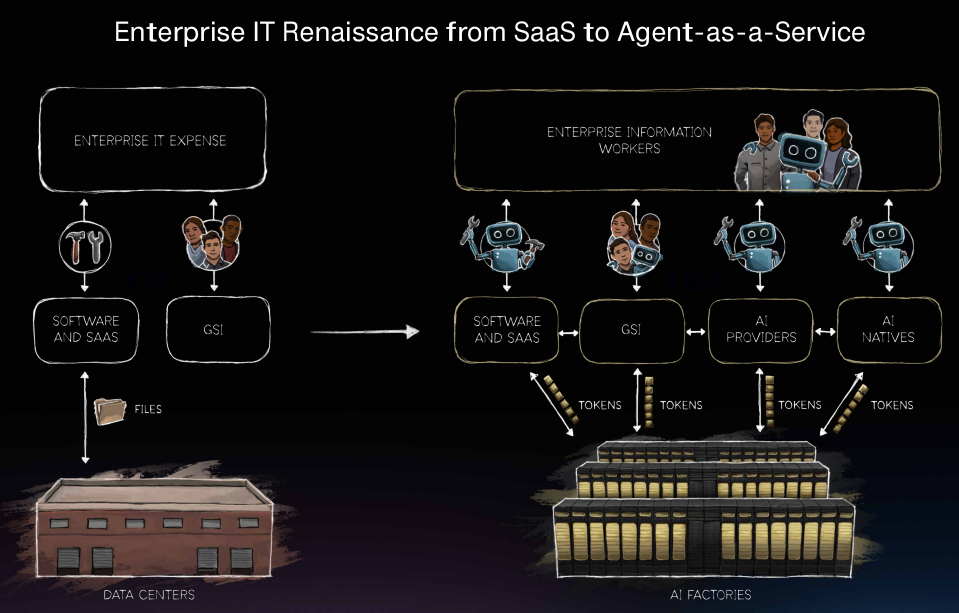
下载量超过10亿次的LangChain宣布推出与英伟达合作构建的企业级平台。
很多开发者倾向于在完全可控的本地环境中开发。
DGX Spark旨在让云端开发更具普惠性,可以运行安全、常驻的自治智能体,支持最多4个系统集群到统一配置中,并兼容最新模型。
基于GB10的DGX Spark及合作伙伴系统正式在全球开售。DGX Station作为终极云端开发平台,开发者只需在自己的机器上直接构建、微调和运行前沿模型,全程保持本地化,实现完整掌控与安全保障。
模型开源与物理世界
英伟达构建并发布了六大系列的开放前沿模型及训练数据配方和框架。
Nemotron 3 Ultra在自有基础设施上完成预训练,吞吐量是此前最佳开放模型的2倍。
Nemotron 3 Omni具备音频、视觉和语言理解能力,支持从视频和文档中高效提取信息。
Nemotron 3 VoiceChat支持实时对话,把自动语音识别、大模型处理和文本转语音功能结合在一个系统中。
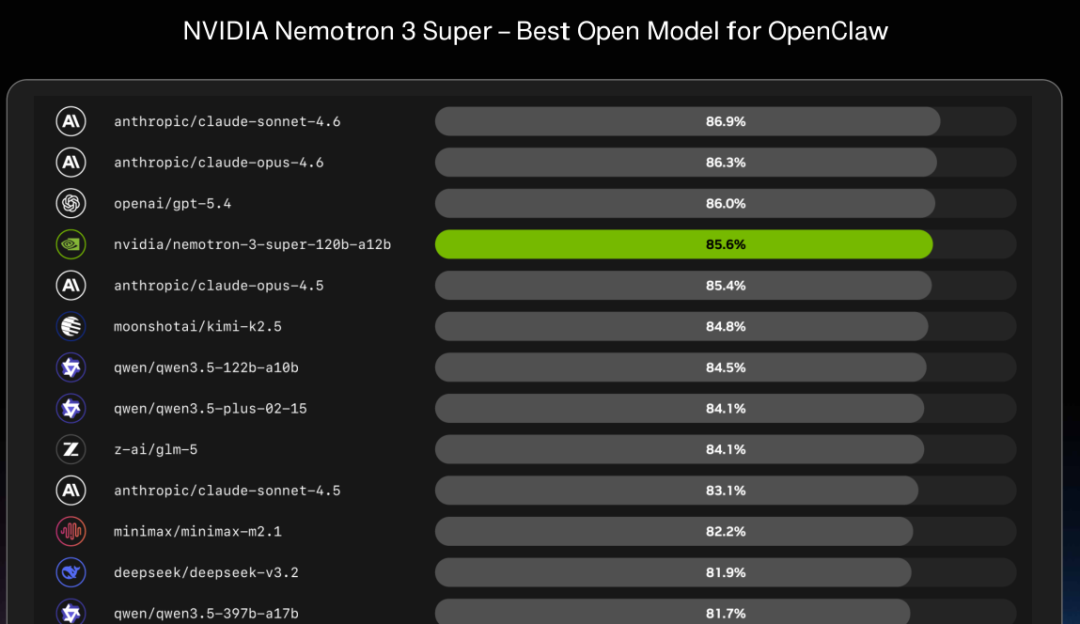
上周先一步发布的Nemotron 3 Super是迄今最强推理模型,在评估智能体大脑能力的伯克利函数调用排行榜中登顶开源模型第一,综合排名全球第四。
面向物理世界和医疗健康领域的模型同样出色。
NVIDIA Cosmos 3是第一个统一合成世界生成、物理推理和动作模拟的基础模型。
NVIDIA GR00T N1.7专为人形机器人构建,在现实世界中部署具有商业可行性。
NVIDIA Alphamayo 1.5面向自动驾驶汽车。
NVIDIA BioNeMo Proteina-Complexa用于蛋白质结合体设计,可加速基于结构的药物发现。
以上模型均已发布在开源社区。
基于DreamZero研究的下一代基础模型GR00T N2预计于年底发布,帮助机器人在新环境中成功完成新任务的频率是领先模型的2倍多。
Nemotron联盟正式成立。各大顶尖实验室汇聚专业知识、数据、评估体系和开发能力。

英伟达使用内部DGX Cloud算力统一承担训练工作,避免重复投入,共同构建开放的共享基础。开发者和企业随后可针对各自的行业、地区和应用场景进行专项定制。
联盟的第一个项目正在训练中,将成为即将发布的Nemotron 4系列的基础。
整个信息技术行业产值约2万亿美元,世界上其他所有行业都需要能与真实世界交互的物理模型。
从桌面到机器人、自动驾驶汽车,从工厂到电信网络,底层基础设施已无处不在。
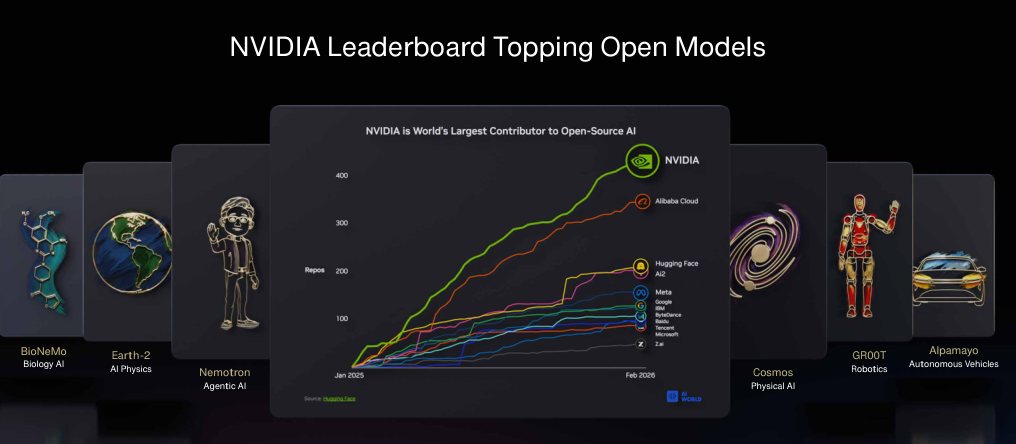
在机器人领域,算力即数据。针对数据生成工作流严重碎片化的问题,英伟达推出物理AI数据工厂蓝图。
基于Cosmos世界模型和Osmo机器人算力编排系统的开放参考架构,让用仿真数据大规模训练机器人的管线走向标准化。
微软Azure等云服务商成为首批采用者。
黄仁勋放出了一张有30多台机器人的大合照。比亚迪、库卡、智元、小鹏、吉利的机器人齐聚一堂。

机器人是一个50万亿美元的制造业大市场,英伟达在此深耕十年,本届大会现场展示了110台机器人,全球几乎每一家机器人公司都在与其合作。
自动驾驶汽车是物理模型大规模落地的第一个场景。
英伟达构建了覆盖训练与验证的NVIDIA DRIVE平台。核心的DRIVE Hyperion架构集成计算、传感器和软件,供整个生态系统构建。
统一软件安全基础NVIDIA Halos OS、全新版本的Alphamayo 1.5以及用于仿真的Omniverse NuRec普遍可用。
生态系统持续扩大,比亚迪、吉利、日产等车企加入开发下一代程序。
Uber全球无人驾驶出租车网络计划于2027年在洛杉矶和旧金山启动试点,2028年底前扩展至四大洲28座城市。
西门子等全球工业软件巨头将加速工具带到现代、本田、台积电等公司,加速设计与制造,并推出由英伟达驱动的智能体解决方案。
本田使用相关软件运行空气动力学模拟,速度快了34倍。
电信网络也在演变。T-Mobile等公司合作将应用部署到AI-RAN基础设施。独立5G网络提供了广泛的覆盖和服务质量保证,解决了扩展瓶颈。
收购顶尖技术增强推理优势,用开源顶尖模型激励更广泛的算力需求,以全栈布局和提高工具易用性来垒高用户的迁移成本,每一步棋都堪称教科书级别。
坚持做基础设施建设者,绝不触碰下游客户的利益。
英伟达以高明的长期主义,把各行各业的头部企业引入自己的生态轨道,把客户的成功变成自己的护城河。
黄仁勋演讲官方视频:
https://www.youtube.com/watch?v=jw_o0xr8MWU

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)