
OpenClaw 多 Agent 协作架构实战:构建自动化研发流水线
提供了一种新的解决思路:通过构建独立的 AI Agent 集群,每个 Agent 承担特定工程角色,通过任务编排实现研发流程的自动化流转。在传统的软件开发流程中,一个需求从提出到交付往往需要经历需求分析、架构设计、编码实现、代码审查、测试验证等多个环节。通过将软件工程中的角色分离原则应用到 AI Agent 架构中,我们能够构建出可扩展、可观测、成本可控的自动化研发系统。:Sub-agents 统
大家好,我是玄姐。
PS:
OpenClaw 火了,那么 OpenClaw 在企业如何落地?有哪些使用场景?具体的实践经验是什么?下周二会开场直播详细讲解,欢迎点击预约,直播见。
引言:当软件开发遇上多 Agent 架构
在传统的软件开发流程中,一个需求从提出到交付往往需要经历需求分析、架构设计、编码实现、代码审查、测试验证等多个环节。对于独立开发者或小团队而言,这意味着频繁的角色切换与上下文切换成本。
OpenClaw 的多 Agent 协作架构提供了一种新的解决思路:通过构建独立的 AI Agent 集群,每个 Agent 承担特定工程角色,通过任务编排实现研发流程的自动化流转。本文将从架构设计、实现方案到生产实践,深度解析这套多 Agent 协作系统。
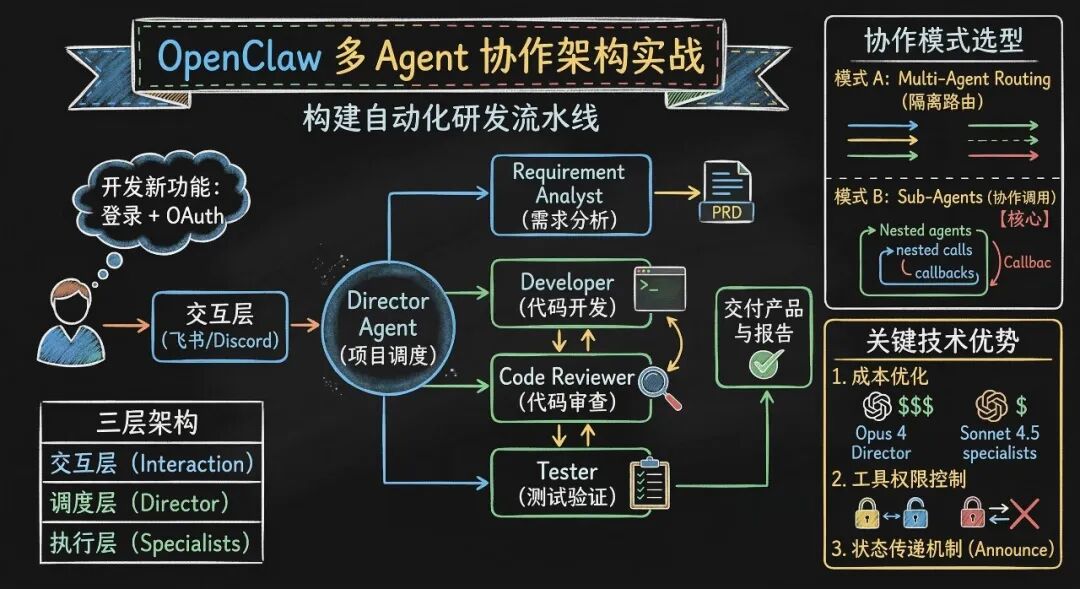
一、架构设计:三层协作模型
1.1 核心架构概念
OpenClaw 的多 Agent 架构基于以下核心抽象:
|
组件 |
职责 |
隔离级别 |
|---|---|---|
| Agent |
独立执行单元,拥有专属工作空间、记忆、配置 |
完全隔离 |
| Multi-Agent Routing |
基于消息路由的多 Agent 并行机制 |
逻辑隔离 |
| Sub-Agents |
主从协作模式,支持任务派发与结果回调 |
协作隔离 |
| Skills |
Agent 专属能力模块(脚本、API 调用) |
功能复用 |
| Bindings |
消息路由规则(用户/群组 → Agent 映射) |
访问控制 |
1.2 三层架构设计
生产环境推荐采用交互层-调度层-执行层的三层架构:
交互层 (Interaction Layer)├── 飞书群组/Discord/Slack (用户接入点)└── 消息网关 (Message Gateway)
调度层 (Orchestration Layer) └── Director Agent (项目调度) ├── 任务分发器 (Task Dispatcher) ├── 状态监控器 (State Monitor) └── 结果聚合器 (Result Aggregator)
执行层 (Execution Layer)├── Requirement Analyst (需求分析)├── Developer (代码开发)├── Code Reviewer (代码审查)└── Tester (测试验证)二、协作模式选型:Routing vs Sub-Agents
OpenClaw 提供两种多 Agent 协作模式,适用场景不同:
模式 A:Multi-Agent Routing(隔离路由)
核心机制:基于消息路由的分流策略
适用场景:
-
多租户隔离(不同客户数据隔离)
-
多身份管理(工作/个人身份分离)
-
简单流量分发(按群组/频道路由)
配置示例:
{ "agents": { "list": [ { "id": "work", "workspace": "~/.openclaw/workspace-work" }, { "id": "personal", "workspace": "~/.openclaw/workspace-personal" } ] }, "bindings": [ { "agentId": "work", "match": { "channel": "feishu", "accountId": "company" } }, { "agentId": "personal", "match": { "channel": "feishu", "accountId": "personal" } } ]}特征:Agent 间完全隔离,无调用关系,无状态共享。
模式 B:Sub-Agents(协作调用)
核心机制:基于sessions_spawn的任务派发与回调
适用场景:
-
研发流水线(需求 → 开发 → 审查 → 测试)
-
内容生产链(采集 → 创作 → 审核 → 发布)
-
数据分析管道(采集 → 清洗 → 分析 → 可视化)
调用范式:
{ "task": "分析用户登录需求并生成 PRD 文档", "agentId": "analyst", "mode": "run", "runTimeoutSeconds": 600}特征:支持嵌套调用(最多 2 层),支持结果回调,适合复杂工作流编排。
选型建议:研发协作场景推荐 Sub-Agents 模式,需要强隔离场景选择 Routing 模式。
三、生产级部署方案
3.1 目录结构设计
~/.openclaw/├── openclaw.json # 主配置文件├── skills/ # 共享 Skills 库│ ├── code-analyzer/│ └── test-runner/└── agents/ # Agent 状态目录 ├── director/agent/ ├── analyst/agent/ ├── developer/agent/ ├── reviewer/agent/ └── tester/agent/3.2 核心配置详解
openclaw.json关键配置:
{ "agents": { "list": [ { "id": "director", "name": "项目调度", "default": true, "workspace": "~/.openclaw/workspace-director", "agentDir": "~/.openclaw/agents/director/agent" } // ... 其他 Agent 配置 ], "defaults": { "subagents": { "maxSpawnDepth": 2, // 允许 2 层嵌套调用 "maxChildrenPerAgent": 5, // 单 Agent 并发限制 "maxConcurrent": 8, // 全局并发上限 "model": "anthropic/claude-sonnet-4-5", // Sub-agents 使用轻量级模型 "runTimeoutSeconds": 900 // 15 分钟超时 } } }, "bindings": [ { "agentId": "director", "match": { "channel": "feishu", "accountId": "dev-team" } } ]}关键参数说明:
-
maxSpawnDepth: 2:Director (L0) → Specialist (L1) → Tool (L2)
-
model配置:Sub-agents 使用 Sonnet 4.5 相比 Opus 4 成本降低80%
-
runTimeoutSeconds:防止长时间挂起,确保资源释放
3.3 Agent 角色定义(SOUL.md 配置)
Director(项目调度中心)
# Director - 项目调度
## 核心职责1. 需求解析:理解用户自然语言需求,识别任务类型2. 任务编排:将需求拆解为可并行/串行的子任务3. 资源调度:基于任务类型调用对应 Specialist Agent4. 质量控制:监控子任务状态,处理异常与重试5. 结果聚合:整合多 Agent 输出,生成统一报告
## 可调用的 Specialist Agents
| Agent ID | 角色 | 输入 | 输出 ||---------|------|------|------|| analyst | 需求分析师 | 用户原始需求 | PRD 文档、API 规范 || developer | 开发者 | PRD 文档 | 代码实现 || reviewer | 代码审查员 | 代码文件 | 审查报告 || tester | 测试工程师 | 代码 + PRD | 测试报告 |
## 标准工作流
### 新功能开发流程1. 调用 analyst 生成 PRD(timeout: 600s)2. 调用 developer 实现代码(timeout: 900s)3. 并行调用 reviewer + tester(timeout: 600s)4. 聚合结果,生成交付报告
## 输出格式规范✅ 任务完成摘要📋 各阶段产出清单 🔍 质量检查结果⚠️ 风险提示⏱️ 耗时与成本统计其他 Specialist Agents 需独立配置 SOUL.md,核心要素包括:
-
明确职责边界:避免能力重叠导致的职责不清
-
输入输出规范:定义标准的数据交换格式
-
质量检查清单:明确交付物验收标准
四、完整工作流实战
4.1 需求提出
用户在飞书群组输入:
"开发一个用户登录功能,支持邮箱密码登录和 GitHub OAuth,要求包含 JWT Token 刷新机制"
4.2 系统执行流程
Step 1:Director 接收与解析
-
识别任务类型:新功能开发
-
拆解子任务:需求分析 → 代码开发 → 代码审查 → 测试验证
Step 2:调用 Analyst(需求分析)
{ "task": "分析登录功能需求(邮箱密码 + GitHub OAuth + JWT 刷新),生成 PRD 和 API 设计", "agentId": "analyst", "mode": "run"}产出:
-
PRD 文档(用户故事、功能清单、非功能性需求)
-
API 规范(3 个端点:POST /auth/login, POST /auth/refresh, GET /auth/github/callback)
Step 3:调用 Developer(代码实现)
{ "task": "基于 PRD 实现登录功能,技术栈:Python/FastAPI,数据库:PostgreSQL", "agentId": "developer", "mode": "run", "runTimeoutSeconds": 900}产出:
-
src/api/auth.py(路由层)
-
src/services/auth_service.py(业务逻辑)
-
src/models/user.py(数据模型)
-
src/utils/jwt_handler.py(JWT 工具)
Step 4:并行审查与测试
Director 同时发起:
// 调用 Reviewer{ "task": "审查代码安全性和规范", "agentId": "reviewer" }// 调用 Tester { "task": "编写并执行测试用例", "agentId": "tester" }Step 5:结果聚合与交付
Director 生成最终报告:
✅ 任务完成:用户登录功能开发
📋 需求分析(Analyst)- PRD 文档:已生成(含 3 个 API 规范)- 安全要求:OAuth 2.0 + JWT 刷新机制- 风险评估:中(涉及第三方 OAuth 集成)
💻 代码开发(Developer)- 交付文件:4 个模块,共 320 行代码- 技术栈:FastAPI + SQLAlchemy + PyJWT- 依赖包:fastapi, httpx, python-jose, passlib
🔍 代码审查(Reviewer)- 严重问题:1 处(SQL 注入风险 @auth.py:42)- 中等问题:2 处(异常处理不完善)- 建议:使用参数化查询,增加限流装饰器
✅ 测试验证(Tester)- 测试用例:15 个(单元测试 8,集成测试 7)- 通过率:93%(14/15 通过)- 失败项:OAuth 回调异常处理分支未覆盖
⚠️ 交付前必须修复:1. [高危] SQL 注入风险(使用 SQLAlchemy 参数化查询)2. [中危] JWT Secret 硬编码(改用环境变量读取)
⏱️ 总耗时:18 分钟💰 估算成本:$0.28(Sub-agents 使用 Sonnet 4.5 节省 82%)五、关键技术细节
5.1 工具权限控制
Sub-agents 默认继承主 Agent 工具集,但可通过策略限制:
{ "tools": { "subagents": { "tools": { "deny": ["gateway", "cron", "write"] // 禁止子 Agent 操作网关和文件写入 } } }}5.2 状态传递机制
Sub-agents 通过 Announce 协议向父节点报告结果:
-
L2 Worker 完成 → Announce →L1 Orchestrator
-
L1 Orchestrator 聚合 → Announce →L0 Director
-
Director 整合 → 用户界面
Announce Payload 包含:
-
source: subagent | cron
-
status:success | error | timeout
-
result: 结构化输出内容
-
metrics: token 消耗、执行时长、成本估算
5.3 成本优化策略
|
Agent 类型 |
推荐模型 |
成本指数 |
适用场景 |
|---|---|---|---|
|
Director |
Claude Opus 4 |
1.0x |
复杂决策、最终审查 |
|
Analyst/Developer |
Claude Sonnet 4.5 |
0.2x |
代码生成、文档编写 |
|
Tester/Reviewer |
Claude Sonnet 4.5 |
0.2x |
批量测试、模式化审查 |
生产建议:Sub-agents 统一使用 Sonnet 4.5,仅在 Director 层使用 Opus 4,整体成本可降低75%-80%。
六、最佳实践与避坑指南
6.1 设计原则
✅ 推荐做法:
-
单一职责:每个 Agent 专注一个工程环节
-
明确契约:定义清晰的输入输出接口(建议使用 JSON Schema)
-
失败隔离:单个子任务失败不影响整体流程,Director 负责错误聚合
-
超时控制:设置合理的runTimeoutSeconds(建议 600-900s)
❌ 常见陷阱:
-
Agent 职责重叠导致重复处理
-
未设置并发限制导致资源耗尽
-
所有 Agent 使用顶级模型造成成本失控
-
Sub-agents 直接操作生产环境(应通过 Director 审核)
6.2 调试技巧
# 查看 Sub-agents 运行状态openclaw subagents list
# 实时跟踪特定 Agent 日志openclaw logs --follow --agent analyst
# 终止异常任务openclaw subagents kill <session-id>6.3 安全建议
-
权限最小化:Sub-agents 默认禁用write和exec权限
-
敏感信息隔离:API Keys、数据库密码通过环境变量注入,不出现在 SOUL.md
-
人工审核节点:对于生产环境部署,建议增加人工确认环节
七、架构演进思考
OpenClaw 的多 Agent 架构代表了 AI 原生研发流程的一种实现范式:
-
从单体 AI 到分布式 AI:通过角色专业化提升单环节质量
-
从对话式到工作流式:从简单的问答转向结构化工程交付
-
从通用模型到专用模型:通过轻量级 Specialist 模型降低成本
这种架构特别适合:
-
独立开发者:一人管理完整研发流水线
-
远程协作团队:异步自动化处理重复性工作
-
标准化流程:如代码审查、文档生成、数据 ETL
八、结语
OpenClaw 的多 Agent 协作系统不仅是一个工具框架,更是一种工程组织范式的实验。通过将软件工程中的角色分离原则应用到 AI Agent 架构中,我们能够构建出可扩展、可观测、成本可控的自动化研发系统。
未来随着 Agent 能力的增强和成本的进一步降低,这种模式或将成为软件开发的默认配置。
PS:
OpenClaw 火了,那么 OpenClaw 在企业如何落地?有哪些使用场景?具体的实践经验是什么?下周二会开场直播详细讲解,欢迎点击预约,直播见。
好了,这就是我今天想分享的内容。如果你对构建企业级 AI 原生应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)