
win11本地部署openclaw实操第12集:ollama出现不认GPU的故障处理
Ollama服务出现GPU识别问题导致对话无响应。日志显示系统检测到CPU计算资源(62.7GiB内存)但未正确识别GPU设备,警告信息提示用户可能覆盖了可见设备设置(CUDA_VISIBLE_DEVICES=0)。服务尝试使用CPU运行模型,加载了25层架构为gptoss的模型,采用MXFP4量化格式,最终在无GPU加速的情况下完成了模型加载和内存分配。建议检查GPU驱动设置或尝试重置环境变量重
·
1.小龙虾突然出故障,对话没反应了,查看ollama日志发现是ollama出现不认显卡GPU问题
(base) gpu3090@DESKTOP-8IU6393:~/llama.cpp$ time=2026-03-12T21:04:04.146+08:00 level=INFO source=routes.go:1663 msg="server config" env="map[CUDA_VISIBLE_DEVICES:0 GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY:http://127.0.0.1:7897 HTTP_PROXY:http://127.0.0.1:7897 NO_PROXY:172.31.*,172.30.*,172.29.*,172.28.*,172.27.*,172.26.*,172.25.*,172.24.*,172.23.*,172.22.*,172.21.*,172.20.*,172.19.*,172.18.*,172.17.*,172.16.*,10.*,192.168.*,127.*,localhost,<local> OLLAMA_CONTEXT_LENGTH:32768 OLLAMA_DEBUG:INFO OLLAMA_EDITOR: OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:12346 OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/gpu3090/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NO_CLOUD:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_REMOTES:[ollama.com] OLLAMA_SCHED_SPREAD:false OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES: http_proxy:http://127.0.0.1:7897 https_proxy:http://127.0.0.1:7897 no_proxy:172.31.*,172.30.*,172.29.*,172.28.*,172.27.*,172.26.*,172.25.*,172.24.*,172.23.*,172.22.*,172.21.*,172.20.*,172.19.*,172.18.*,172.17.*,172.16.*,10.*,192.168.*,127.*,localhost
,<local>]"
time=2026-03-12T21:04:04.146+08:00 level=INFO source=routes.go:1665 msg="Ollama cloud disabled: false"
time=2026-03-12T21:04:04.172+08:00 level=INFO source=images.go:473 msg="total blobs: 5"
time=2026-03-12T21:04:04.187+08:00 level=INFO source=images.go:480 msg="total unused blobs removed: 0"
time=2026-03-12T21:04:04.208+08:00 level=INFO source=routes.go:1718 msg="Listening on [::]:12346 (version 0.16.3)"
time=2026-03-12T21:04:04.209+08:00 level=INFO source=runner.go:67 msg="discovering available GPUs..."
time=2026-03-12T21:04:04.209+08:00 level=WARN source=runner.go:485 msg="user overrode visible devices" CUDA_VISIBLE_DEVICES=0
time=2026-03-12T21:04:04.209+08:00 level=WARN source=runner.go:489 msg="if GPUs are not correctly discovered, unset and try again"
time=2026-03-12T21:04:04.211+08:00 level=INFO source=server.go:431 msg="starting runner" cmd="/usr/local/bin/ollama runner --ollama-engine --port 45679"
time=2026-03-12T21:04:04.269+08:00 level=INFO source=types.go:60 msg="inference compute" id=cpu library=cpu compute="" name=cpu description=cpu libdirs=ollama driver="" pci_id="" type="" total="62.7 GiB" available="59.9 GiB"
time=2026-03-12T21:04:04.269+08:00 level=INFO source=routes.go:1768 msg="vram-based default context" total_vram="0 B" default_num_ctx=4096
time=2026-03-12T21:04:21.135+08:00 level=INFO source=server.go:247 msg="enabling flash attention"
time=2026-03-12T21:04:21.136+08:00 level=INFO source=server.go:431 msg="starting runner" cmd="/usr/local/bin/ollama runner --ollama-engine --model /home/gpu3090/.ollama/models/blobs/sha256-e7b273f9636059a689e3ddcab3716e4f65abe0143ac978e46673ad0e52d09efb --port 46427"
time=2026-03-12T21:04:21.137+08:00 level=INFO source=sched.go:491 msg="system memory" total="62.7 GiB" free="60.9 GiB" free_swap="16.0 GiB"
time=2026-03-12T21:04:21.137+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=25 requested=-1
time=2026-03-12T21:04:21.154+08:00 level=INFO source=runner.go:1411 msg="starting ollama engine"
time=2026-03-12T21:04:22.096+08:00 level=INFO source=runner.go:1446 msg="Server listening on 127.0.0.1:46427"
time=2026-03-12T21:04:22.102+08:00 level=INFO source=runner.go:1284 msg=load request="{Operation:fit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:32768 KvCacheType: NumThreads:12 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-12T21:04:22.235+08:00 level=INFO source=ggml.go:136 msg="" architecture=gptoss file_type=MXFP4 name="" description="" num_tensors=459 num_key_values=32
time=2026-03-12T21:04:22.235+08:00 level=INFO source=ggml.go:104 msg=system CPU.0.LLAMAFILE=1 compiler=cgo(gcc)
time=2026-03-12T21:04:22.328+08:00 level=INFO source=runner.go:1284 msg=load request="{Operation:alloc LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:32768 KvCacheType: NumThreads:12 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-12T21:04:23.489+08:00 level=INFO source=runner.go:1284 msg=load request="{Operation:commit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:32768 KvCacheType: NumThreads:12 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-12T21:04:23.489+08:00 level=INFO source=ggml.go:482 msg="offloading 0 repeating layers to GPU"
time=2026-03-12T21:04:23.489+08:00 level=INFO source=ggml.go:486 msg="offloading output layer to CPU"
time=2026-03-12T21:04:23.489+08:00 level=INFO source=ggml.go:494 msg="offloaded 0/25 layers to GPU"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=device.go:245 msg="model weights" device=CPU size="12.8 GiB"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=device.go:256 msg="kv cache" device=CPU size="876.0 MiB"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=device.go:267 msg="compute graph" device=CPU size="131.2 MiB"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=device.go:272 msg="total memory" size="13.8 GiB"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=sched.go:566 msg="loaded runners" count=1
time=2026-03-12T21:04:23.490+08:00 level=INFO source=server.go:1350 msg="waiting for llama runner to start responding"
time=2026-03-12T21:04:23.490+08:00 level=INFO source=server.go:1384 msg="waiting for server to become available" status="llm server loading model"
time=2026-03-12T21:04:51.632+08:00 level=INFO source=server.go:1388 msg="llama runner started in 29.58 seconds"
2.想在wsl的ollama里面进行处理,但处理了好几天没解决
太失败了,可能是ubuntu的知识不扎实,反正问了豆包,照做总是遇到各种奇怪的问题。
3.今天灵光一现,wsl不行,就试试win11系统的ollama行不行
发现这个ollama也不认gpu了,刚好试试通过解决这个问题是否可行。
4.解决方案
4.1 通过系统环境变量配置
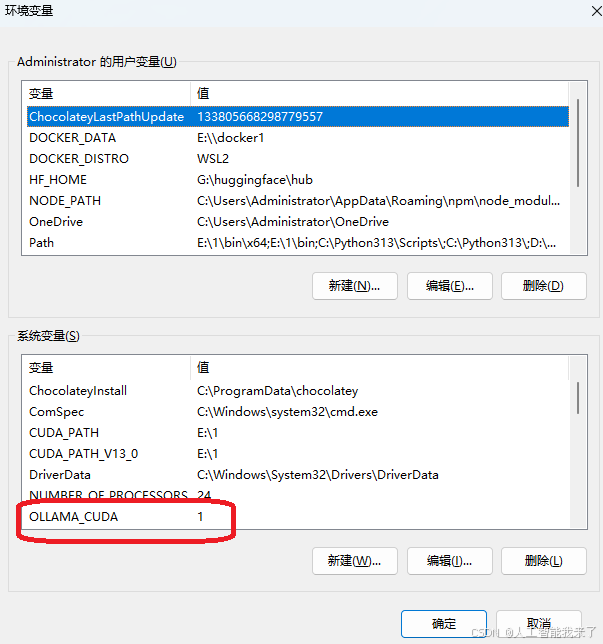
- 按下 Win + R → 输入 sysdm.cpl → 切换到「高级」→「环境变量」。
- 在「系统变量」中点击「新建」:
◦ 变量名:OLLAMA_CUDA
◦ 变量值:1(1 = 启用 CUDA,0 = 禁用) - 重启命令提示符 / 终端,重新运行模型即可。
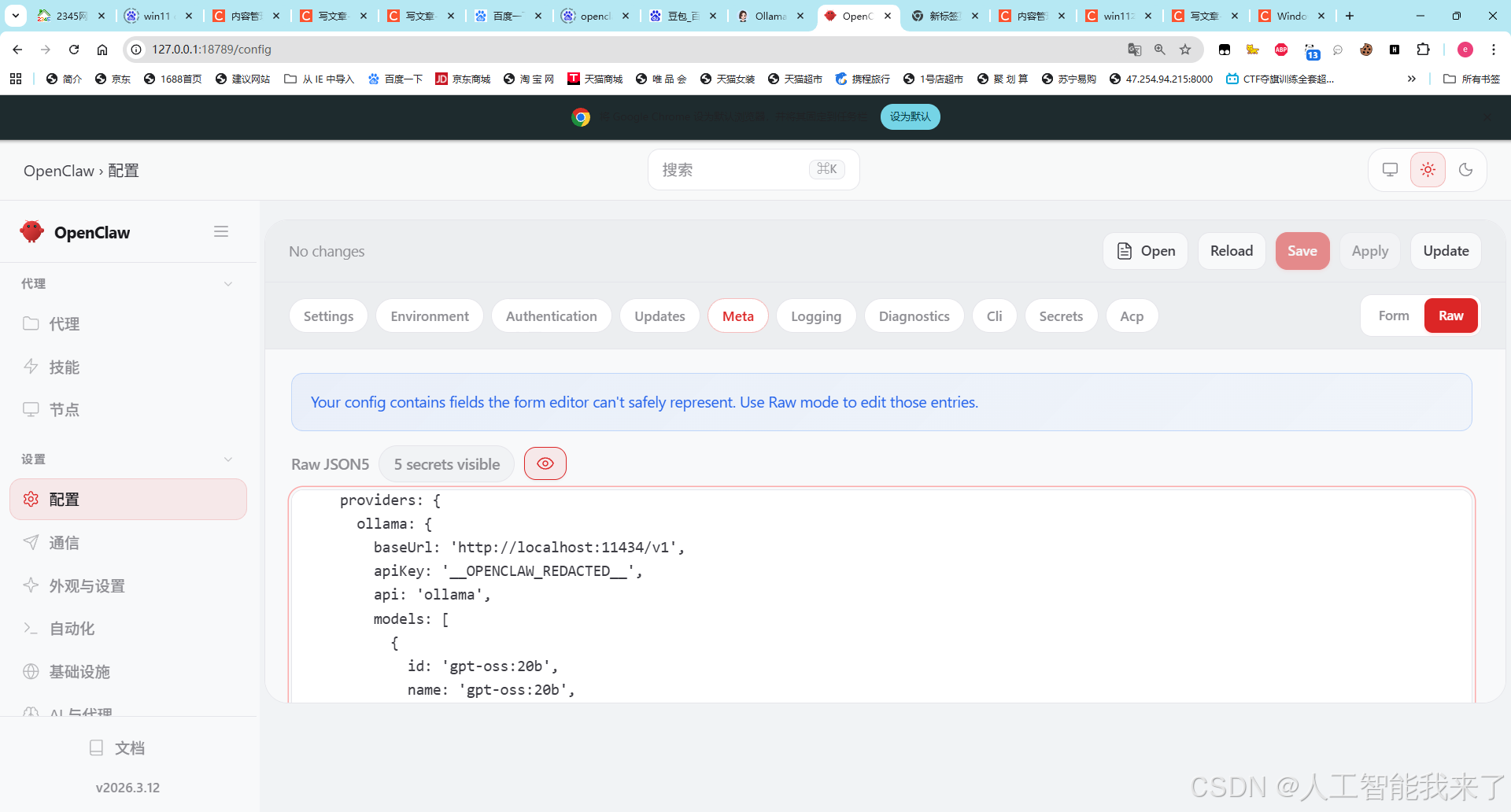
4.2 修改openclaw的ollama的配置
修改ollama端口到11434,这是windows11 ollama的端口
ollama: {
baseUrl: 'http://localhost:11434/v1',
5.测试恢复正常,问题完美解决
5.1 查看ollama日志
日志如下
time=2026-03-15T18:59:06.178+08:00 level=INFO source=routes.go:1658 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:65536 OLLAMA_DEBUG:INFO OLLAMA_EDITOR: OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:E:\\AI\\Ollama OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NO_CLOUD:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_REMOTES:[ollama.com] OLLAMA_SCHED_SPREAD:false OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES:]"
time=2026-03-15T18:59:06.205+08:00 level=INFO source=routes.go:1660 msg="Ollama cloud disabled: false"
time=2026-03-15T18:59:06.301+08:00 level=INFO source=images.go:477 msg="total blobs: 5"
time=2026-03-15T18:59:06.302+08:00 level=INFO source=images.go:484 msg="total unused blobs removed: 0"
time=2026-03-15T18:59:06.302+08:00 level=INFO source=routes.go:1713 msg="Listening on 127.0.0.1:11434 (version 0.17.7)"
time=2026-03-15T18:59:06.304+08:00 level=INFO source=runner.go:67 msg="discovering available GPUs..."
time=2026-03-15T18:59:06.352+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 4510"
time=2026-03-15T18:59:08.436+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 4905"
time=2026-03-15T18:59:11.019+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 5375"
time=2026-03-15T18:59:11.446+08:00 level=INFO source=runner.go:106 msg="experimental Vulkan support disabled. To enable, set OLLAMA_VULKAN=1"
time=2026-03-15T18:59:11.452+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 5445"
time=2026-03-15T18:59:11.452+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 5446"
time=2026-03-15T18:59:11.762+08:00 level=INFO source=types.go:42 msg="inference compute" id=GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc filter_id="" library=CUDA compute=8.9 name=CUDA0 description="NVIDIA GeForce RTX 4090 D" libdirs=ollama,cuda_v13 driver=13.0 pci_id=0000:07:00.0 type=discrete total="24.0 GiB" available="23.1 GiB"
time=2026-03-15T18:59:11.762+08:00 level=INFO source=routes.go:1763 msg="vram-based default context" total_vram="24.0 GiB" default_num_ctx=32768
[GIN] 2026/03/15 - 18:59:11 | 200 | 0s | 127.0.0.1 | GET "/api/version"
time=2026-03-15T19:01:54.967+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 3747"
time=2026-03-15T19:01:55.209+08:00 level=INFO source=cpu_windows.go:148 msg=packages count=1
time=2026-03-15T19:01:55.209+08:00 level=INFO source=cpu_windows.go:195 msg="" package=0 cores=12 efficiency=0 threads=24
time=2026-03-15T19:01:55.329+08:00 level=INFO source=server.go:246 msg="enabling flash attention"
time=2026-03-15T19:01:55.331+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --model E:\\AI\\Ollama\\blobs\\sha256-e7b273f9636059a689e3ddcab3716e4f65abe0143ac978e46673ad0e52d09efb --port 3756"
time=2026-03-15T19:01:55.372+08:00 level=INFO source=sched.go:489 msg="system memory" total="127.9 GiB" free="105.8 GiB" free_swap="111.5 GiB"
time=2026-03-15T19:01:55.372+08:00 level=INFO source=sched.go:496 msg="gpu memory" id=GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc library=CUDA available="22.5 GiB" free="22.9 GiB" minimum="457.0 MiB" overhead="0 B"
time=2026-03-15T19:01:55.372+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=25 requested=-1
time=2026-03-15T19:01:55.412+08:00 level=INFO source=runner.go:1429 msg="starting ollama engine"
time=2026-03-15T19:01:55.425+08:00 level=INFO source=runner.go:1464 msg="Server listening on 127.0.0.1:3756"
time=2026-03-15T19:01:55.428+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:fit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:01:55.476+08:00 level=INFO source=ggml.go:136 msg="" architecture=gptoss file_type=MXFP4 name="" description="" num_tensors=459 num_key_values=32
load_backend: loaded CPU backend from C:\Users\Administrator\AppData\Local\Programs\Ollama\lib\ollama\ggml-cpu-haswell.dll
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090 D, compute capability 8.9, VMM: yes, ID: GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc
load_backend: loaded CUDA backend from C:\Users\Administrator\AppData\Local\Programs\Ollama\lib\ollama\cuda_v13\ggml-cuda.dll
time=2026-03-15T19:01:55.573+08:00 level=INFO source=ggml.go:104 msg=system CPU.0.SSE3=1 CPU.0.SSSE3=1 CPU.0.AVX=1 CPU.0.AVX2=1 CPU.0.F16C=1 CPU.0.FMA=1 CPU.0.BMI2=1 CPU.0.LLAMAFILE=1 CPU.1.LLAMAFILE=1 CUDA.0.ARCHS=750,800,860,870,890,900,1000,1030,1100,1200,1210 CUDA.0.USE_GRAPHS=1 CUDA.0.PEER_MAX_BATCH_SIZE=128 compiler=cgo(clang)
time=2026-03-15T19:01:56.310+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:alloc LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:commit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=ggml.go:482 msg="offloading 24 repeating layers to GPU"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=ggml.go:489 msg="offloading output layer to GPU"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=ggml.go:494 msg="offloaded 25/25 layers to GPU"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:240 msg="model weights" device=CUDA0 size="11.8 GiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:245 msg="model weights" device=CPU size="1.1 GiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:251 msg="kv cache" device=CUDA0 size="1.6 GiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:262 msg="compute graph" device=CUDA0 size="273.1 MiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:267 msg="compute graph" device=CPU size="5.6 MiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=device.go:272 msg="total memory" size="14.7 GiB"
time=2026-03-15T19:01:56.684+08:00 level=INFO source=sched.go:565 msg="loaded runners" count=1
time=2026-03-15T19:01:56.684+08:00 level=INFO source=server.go:1350 msg="waiting for llama runner to start responding"
time=2026-03-15T19:01:56.685+08:00 level=INFO source=server.go:1384 msg="waiting for server to become available" status="llm server loading model"
time=2026-03-15T19:02:57.772+08:00 level=WARN source=server.go:1357 msg="client connection closed before server finished loading, aborting load"
time=2026-03-15T19:02:57.772+08:00 level=ERROR source=sched.go:571 msg="error loading llama server" error="timed out waiting for llama runner to start: context canceled"
[GIN] 2026/03/15 - 19:02:57 | 499 | 1m3s | 127.0.0.1 | POST "/v1/chat/completions"
ggml_backend_cuda_device_get_memory device GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc utilizing NVML memory reporting free: 9468776448 total: 25757220864
time=2026-03-15T19:02:58.061+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 4720"
time=2026-03-15T19:03:17.464+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --port 12158"
time=2026-03-15T19:03:17.671+08:00 level=INFO source=cpu_windows.go:148 msg=packages count=1
time=2026-03-15T19:03:17.671+08:00 level=INFO source=cpu_windows.go:195 msg="" package=0 cores=12 efficiency=0 threads=24
time=2026-03-15T19:03:17.785+08:00 level=INFO source=server.go:246 msg="enabling flash attention"
time=2026-03-15T19:03:17.786+08:00 level=INFO source=server.go:430 msg="starting runner" cmd="C:\\Users\\Administrator\\AppData\\Local\\Programs\\Ollama\\ollama.exe runner --ollama-engine --model E:\\AI\\Ollama\\blobs\\sha256-e7b273f9636059a689e3ddcab3716e4f65abe0143ac978e46673ad0e52d09efb --port 12165"
time=2026-03-15T19:03:17.823+08:00 level=INFO source=sched.go:489 msg="system memory" total="127.9 GiB" free="107.1 GiB" free_swap="112.6 GiB"
time=2026-03-15T19:03:17.823+08:00 level=INFO source=sched.go:496 msg="gpu memory" id=GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc library=CUDA available="22.4 GiB" free="22.8 GiB" minimum="457.0 MiB" overhead="0 B"
time=2026-03-15T19:03:17.823+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=25 requested=-1
time=2026-03-15T19:03:17.869+08:00 level=INFO source=runner.go:1429 msg="starting ollama engine"
time=2026-03-15T19:03:17.881+08:00 level=INFO source=runner.go:1464 msg="Server listening on 127.0.0.1:12165"
time=2026-03-15T19:03:17.889+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:fit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:03:17.940+08:00 level=INFO source=ggml.go:136 msg="" architecture=gptoss file_type=MXFP4 name="" description="" num_tensors=459 num_key_values=32
load_backend: loaded CPU backend from C:\Users\Administrator\AppData\Local\Programs\Ollama\lib\ollama\ggml-cpu-haswell.dll
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090 D, compute capability 8.9, VMM: yes, ID: GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc
load_backend: loaded CUDA backend from C:\Users\Administrator\AppData\Local\Programs\Ollama\lib\ollama\cuda_v13\ggml-cuda.dll
time=2026-03-15T19:03:18.043+08:00 level=INFO source=ggml.go:104 msg=system CPU.0.SSE3=1 CPU.0.SSSE3=1 CPU.0.AVX=1 CPU.0.AVX2=1 CPU.0.F16C=1 CPU.0.FMA=1 CPU.0.BMI2=1 CPU.0.LLAMAFILE=1 CPU.1.LLAMAFILE=1 CUDA.0.ARCHS=750,800,860,870,890,900,1000,1030,1100,1200,1210 CUDA.0.USE_GRAPHS=1 CUDA.0.PEER_MAX_BATCH_SIZE=128 compiler=cgo(clang)
time=2026-03-15T19:03:18.501+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:alloc LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=runner.go:1302 msg=load request="{Operation:commit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:65536 KvCacheType: NumThreads:12 GPULayers:25[ID:GPU-67135303-3c02-f35c-3e58-dc2c1b4892fc Layers:25(0..24)] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=ggml.go:482 msg="offloading 24 repeating layers to GPU"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=ggml.go:489 msg="offloading output layer to GPU"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=ggml.go:494 msg="offloaded 25/25 layers to GPU"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:240 msg="model weights" device=CUDA0 size="11.8 GiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:245 msg="model weights" device=CPU size="1.1 GiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:251 msg="kv cache" device=CUDA0 size="1.6 GiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:262 msg="compute graph" device=CUDA0 size="273.1 MiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:267 msg="compute graph" device=CPU size="5.6 MiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=device.go:272 msg="total memory" size="14.7 GiB"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=sched.go:565 msg="loaded runners" count=1
time=2026-03-15T19:03:18.870+08:00 level=INFO source=server.go:1350 msg="waiting for llama runner to start responding"
time=2026-03-15T19:03:18.870+08:00 level=INFO source=server.go:1384 msg="waiting for server to become available" status="llm server loading model"
time=2026-03-15T19:05:34.344+08:00 level=INFO source=server.go:1388 msg="llama runner started in 136.52 seconds"
[GIN] 2026/03/15 - 19:05:38 | 200 | 2m21s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:08:18 | 200 | 2.0834518s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:10:41 | 200 | 0s | 127.0.0.1 | GET "/api/version"
[GIN] 2026/03/15 - 19:10:41 | 200 | 417.068ms | 127.0.0.1 | POST "/api/me"
[GIN] 2026/03/15 - 19:10:41 | 200 | 459.5844ms | 127.0.0.1 | POST "/api/me"
[GIN] 2026/03/15 - 19:10:44 | 200 | 1.0183ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:10:44 | 200 | 0s | 127.0.0.1 | GET "/api/version"
[GIN] 2026/03/15 - 19:10:44 | 200 | 189.4395ms | 127.0.0.1 | POST "/api/show"
[GIN] 2026/03/15 - 19:10:47 | 200 | 0s | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:10:48 | 200 | 179.1186ms | 127.0.0.1 | POST "/api/show"
[GIN] 2026/03/15 - 19:10:48 | 200 | 168.9014ms | 127.0.0.1 | POST "/api/show"
[GIN] 2026/03/15 - 19:10:49 | 200 | 928.6963ms | 127.0.0.1 | POST "/api/chat"
[GIN] 2026/03/15 - 19:11:18 | 200 | 505.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:11:45 | 200 | 4.0027847s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:11:48 | 200 | 525µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:11:48 | 200 | 1.8039178s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:12:04 | 200 | 1.5593168s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:12:05 | 200 | 1.0768014s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:12:06 | 200 | 962.6144ms | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:12:18 | 200 | 555.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:12:48 | 200 | 571.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:13:18 | 200 | 502.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:13:21 | 200 | 4.832001s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:13:49 | 200 | 2.0755ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:14:20 | 200 | 504.8µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:14:51 | 200 | 551.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:15:22 | 200 | 1.0254ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:15:53 | 200 | 1.029ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:16:24 | 200 | 504.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:16:55 | 200 | 506.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:17:26 | 200 | 1.0216ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:17:57 | 200 | 504µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:18:19 | 200 | 2.2245343s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:18:28 | 200 | 504.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:18:59 | 200 | 504.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:19:30 | 200 | 510.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:20:01 | 200 | 505.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:20:12 | 200 | 0s | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:20:12 | 200 | 0s | 127.0.0.1 | GET "/api/version"
[GIN] 2026/03/15 - 19:20:14 | 200 | 1.9851715s | 127.0.0.1 | POST "/api/me"
[GIN] 2026/03/15 - 19:20:42 | 200 | 2.035ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:21:12 | 200 | 504.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:21:42 | 200 | 504.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:22:10 | 200 | 10.2153225s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:22:12 | 200 | 504µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:22:42 | 200 | 504.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:23:12 | 200 | 504.8µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:23:21 | 200 | 4.299649s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:23:42 | 200 | 503.1µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:24:12 | 200 | 503.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:24:42 | 200 | 506.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:25:12 | 200 | 504.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:25:42 | 200 | 1.0665ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:26:12 | 200 | 505.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:26:42 | 200 | 507.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:27:12 | 200 | 508.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:27:42 | 200 | 539.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:28:12 | 200 | 505.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:28:20 | 200 | 3.0400031s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:28:42 | 200 | 506µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:29:12 | 200 | 503.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:29:42 | 200 | 508.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:30:12 | 200 | 504.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:30:42 | 200 | 546.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:31:12 | 200 | 634.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:31:39 | 200 | 5.7882554s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:31:42 | 200 | 503.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:31:51 | 200 | 10.9746831s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:32:12 | 200 | 504µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:32:42 | 200 | 1.0339ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:33:12 | 200 | 503.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:33:20 | 200 | 3.7179592s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:33:42 | 200 | 537.1µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:33:48 | 200 | 8.5519162s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:34:12 | 200 | 503.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:34:26 | 200 | 5.4765224s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:34:42 | 200 | 505.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:35:12 | 200 | 504.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:35:30 | 200 | 10.2513899s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:35:38 | 200 | 5.6513111s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:35:42 | 200 | 505.8µs | 127.0.0.1 | GET "/api/tags"
time=2026-03-15T19:35:46.801+08:00 level=WARN source=harmonyparser.go:482 msg="harmony parser: no reverse mapping found for function name" harmonyFunctionName=execute
[GIN] 2026/03/15 - 19:35:46 | 200 | 6.2721814s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:35:53 | 200 | 6.3393239s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:36:12 | 200 | 505.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:36:42 | 200 | 504.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:37:05 | 200 | 7.9986111s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:37:12 | 200 | 511µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:37:42 | 200 | 505.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:38:06 | 200 | 22.8652503s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:38:12 | 200 | 506.1µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:38:22 | 200 | 4.9581516s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:38:42 | 200 | 503.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:39:12 | 200 | 527.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:39:42 | 200 | 531µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:40:12 | 200 | 503.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:40:42 | 200 | 590.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:40:51 | 200 | 33.3299627s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:41:12 | 200 | 503.8µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:41:42 | 200 | 504µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:42:12 | 200 | 505.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:42:42 | 200 | 554.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:43:12 | 200 | 507.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:43:15 | 200 | 17.4875858s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:43:21 | 200 | 4.0780473s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:43:30 | 200 | 15.0223209s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:43:38 | 200 | 6.9010401s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:43:42 | 200 | 586.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:43:55 | 200 | 7.1744802s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:03 | 200 | 7.3898171s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:11 | 200 | 7.8415285s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:12 | 200 | 505µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:44:19 | 200 | 7.9599512s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:28 | 200 | 8.8427626s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:39 | 200 | 10.1696879s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:44:42 | 200 | 504.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:44:50 | 200 | 10.1920748s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:45:08 | 200 | 17.8239522s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:45:12 | 200 | 504.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:45:17 | 200 | 8.970323s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:45:27 | 200 | 10.0304019s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:45:37 | 200 | 9.6274665s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:45:42 | 200 | 506.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:45:49 | 200 | 10.8062729s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:46:03 | 200 | 14.3516166s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:46:12 | 200 | 593.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:46:14 | 200 | 10.7069778s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:46:20 | 200 | 4.0263638s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:46:33 | 200 | 18.2243272s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:46:42 | 200 | 508.1µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:46:55 | 200 | 21.4721977s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:47:05 | 200 | 9.3307543s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:47:09 | 200 | 3.4946805s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:47:12 | 200 | 504.8µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:47:42 | 200 | 1.0035ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:48:12 | 200 | 505.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:48:22 | 200 | 4.2364553s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:48:42 | 200 | 566.6µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:48:54 | 200 | 27.7687421s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:49:12 | 200 | 10.6083277s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:49:12 | 200 | 1.006ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:49:42 | 200 | 503.8µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:50:04 | 200 | 18.1315857s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:50:12 | 200 | 505µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:50:15 | 200 | 10.7485729s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:50:42 | 200 | 504.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:50:45 | 200 | 9.0363122s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:51:12 | 200 | 505.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:51:17 | 200 | 1.5462383s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:51:42 | 200 | 504.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:51:56 | 200 | 5.8700742s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:52:12 | 200 | 504.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:52:31 | 200 | 6.7321626s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:52:34 | 200 | 2.6440099s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:52:42 | 200 | 613.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:53:12 | 200 | 518.2µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:53:42 | 200 | 998.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:54:12 | 200 | 1.2464ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:54:40 | 200 | 30.861869s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:54:42 | 200 | 727.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:54:51 | 200 | 20.0029482s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:55:07 | 200 | 26.2687997s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:55:12 | 200 | 548.5µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:55:42 | 200 | 503.4µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:55:55 | 200 | 20.9342996s | 127.0.0.1 | POST "/v1/chat/completions"
[GIN] 2026/03/15 - 19:56:12 | 200 | 506.3µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:56:42 | 200 | 536.7µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:57:12 | 200 | 507.9µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2026/03/15 - 19:57:43 | 200 | 1.0269ms | 127.0.0.1 | GET "/api/tags"
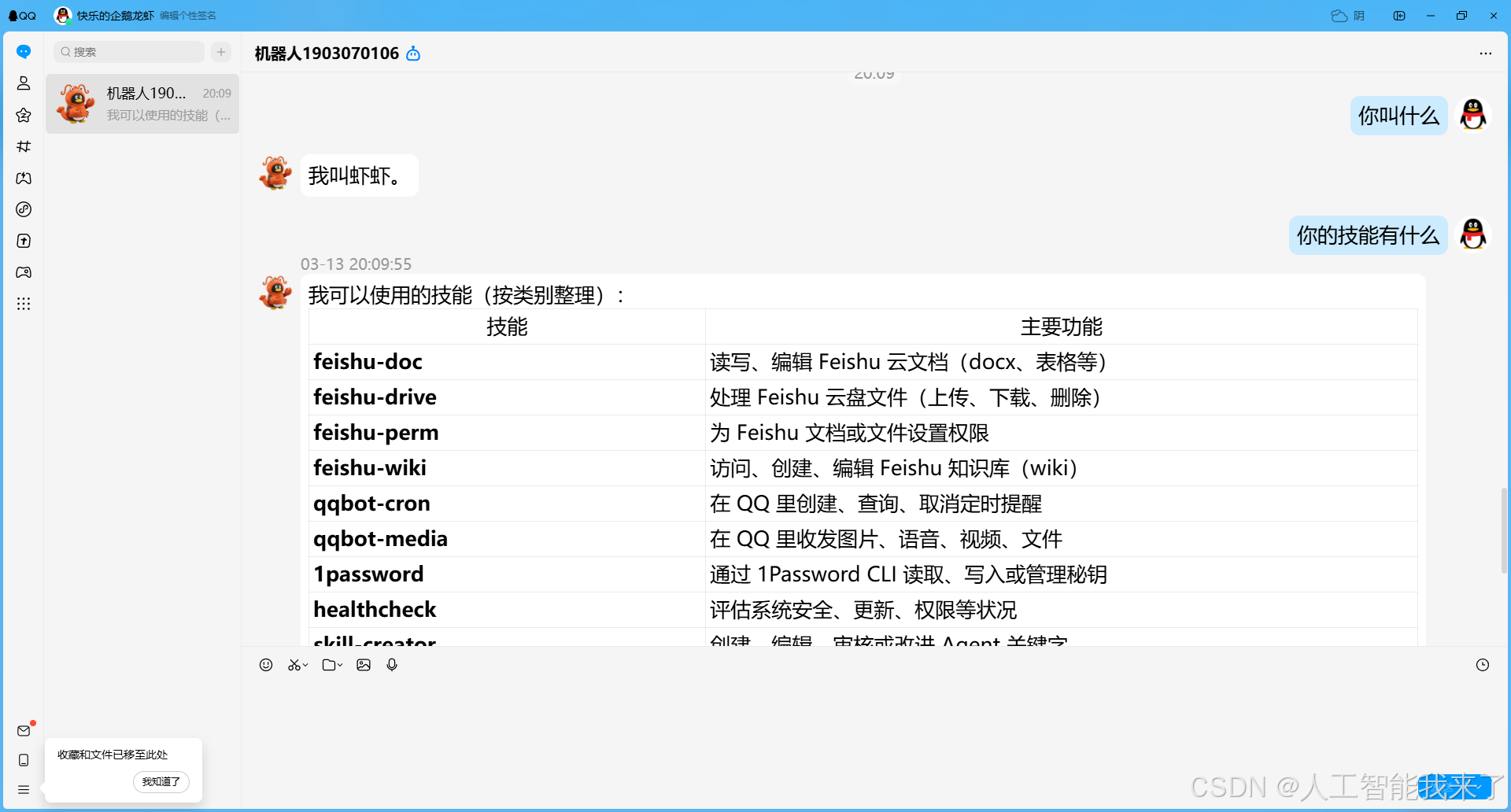
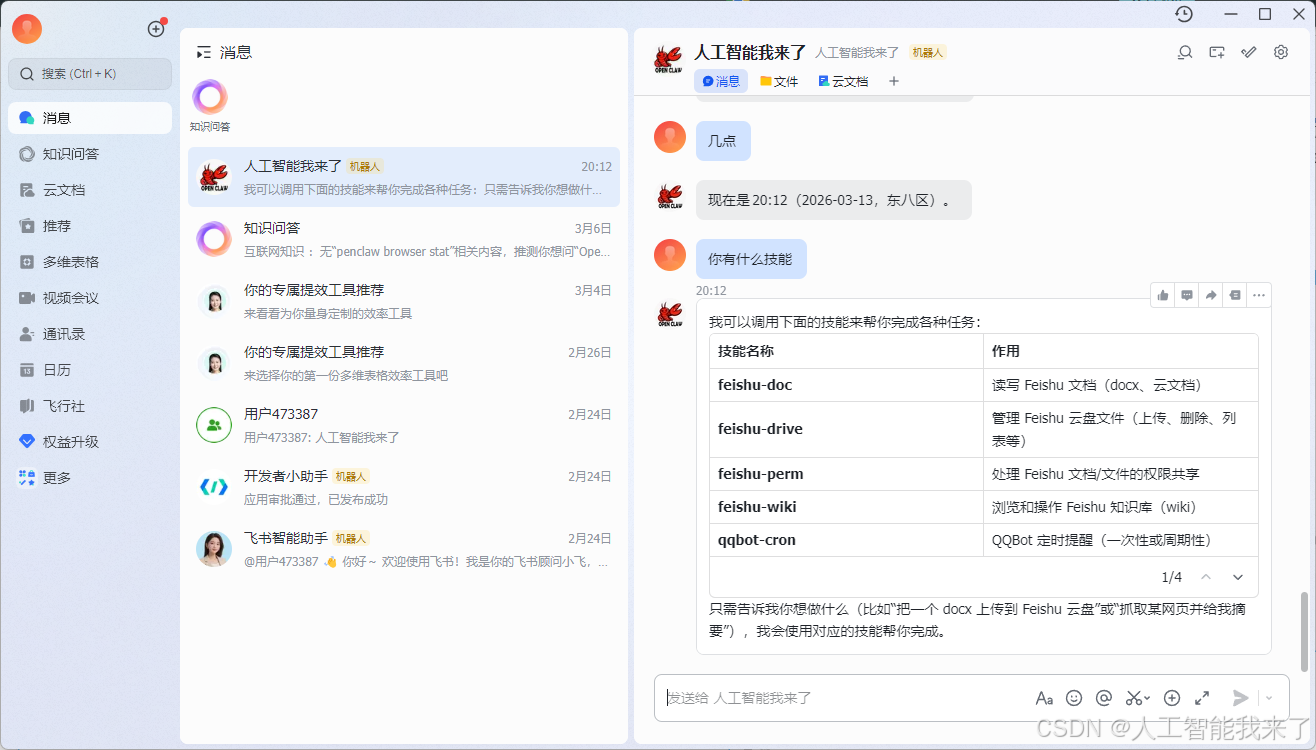
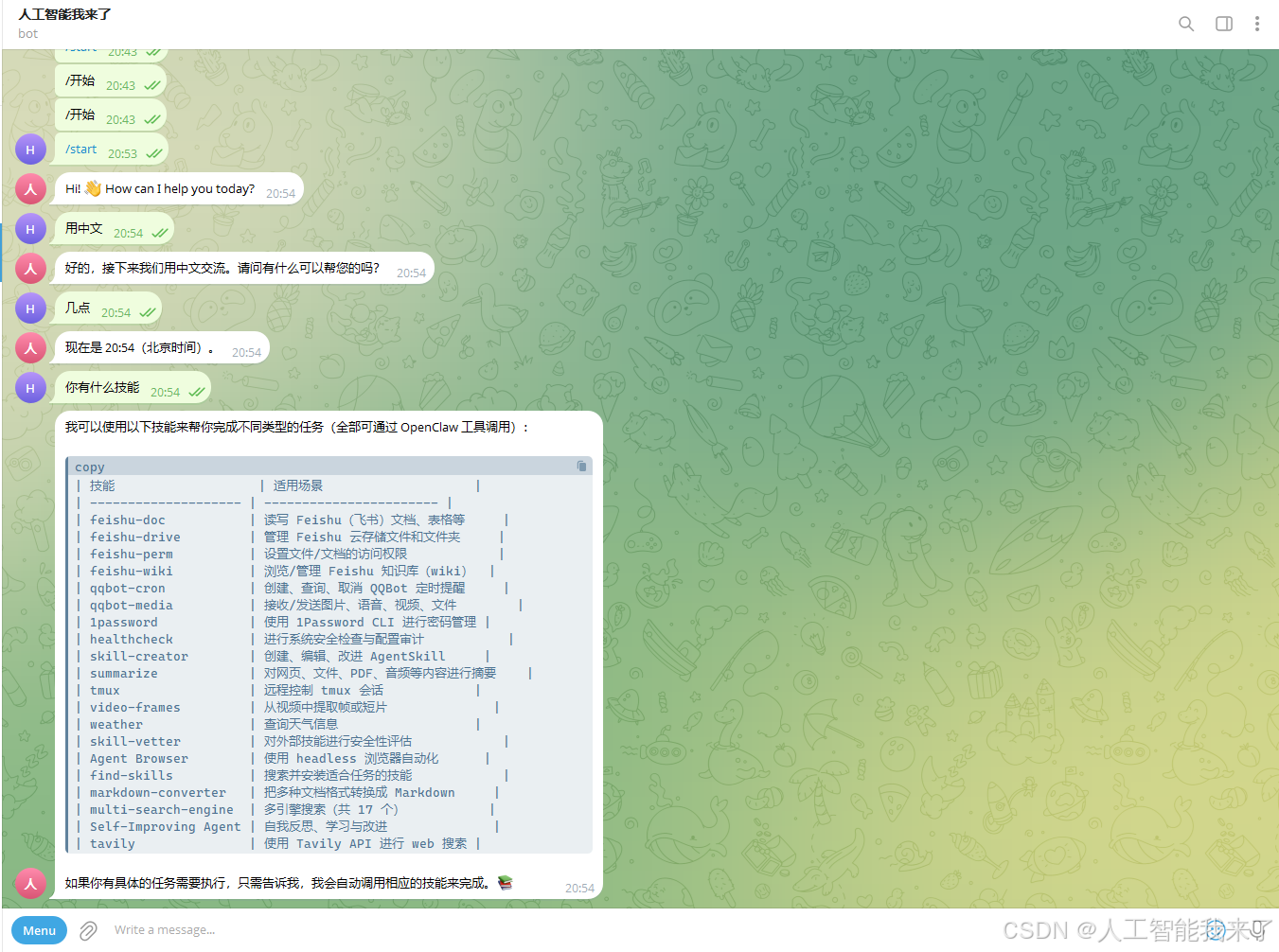
6.小龙虾立马复活了
6.1 QQ正常
6.2 飞书正常
6.3 telegram正常

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 42
42 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)