
永久免费 OpenClaw 部署(续):踩坑记录和实操指南
本文分享了`永久免费 OpenClaw 部署`的续集:踩坑记录和实战指南。希望本文,能帮你建立对`OpenClaw`的全面认识。
前文,分享的OpenClaw教程火了:
永久免费 OpenClaw 部署和实战,7x24在线,手把手教程
评论区,还有很多朋友,遇到了不少卡点。
今日分享,先把前文的坑填上,让更多朋友先上车。
其次,梳理下这段时间在OpenClaw上的实践和思考。
因此,全文略长,共 9 部分,各位按需取用:
- 免费API申领
OpenClaw容器化部署- 消息通道接入指南
- 技能系统接入指南
- 两层记忆机制剖析
- 定时任务机制剖析
- 智能体和会话机制
- 浏览器自动化指南
- 节点接入指南
1. 免费API申领
前文带大家申领NVIDIA的API,虽完全免费,但有速率限制-40RPM。
白嫖的多了,架不住平台进一步限速。
反应慢,大概率是LLM请求被限速了。
因此,本文继续分享两款国内API平台,有免费额度,方便大家快速体验OpenClaw。
1.1 硅基流动
注册:https://cloud.siliconflow.cn/i/DrgxdqSF,+16元免费额度。
模型广场:https://cloud.siliconflow.cn/me/models。推荐用Pro/系列:
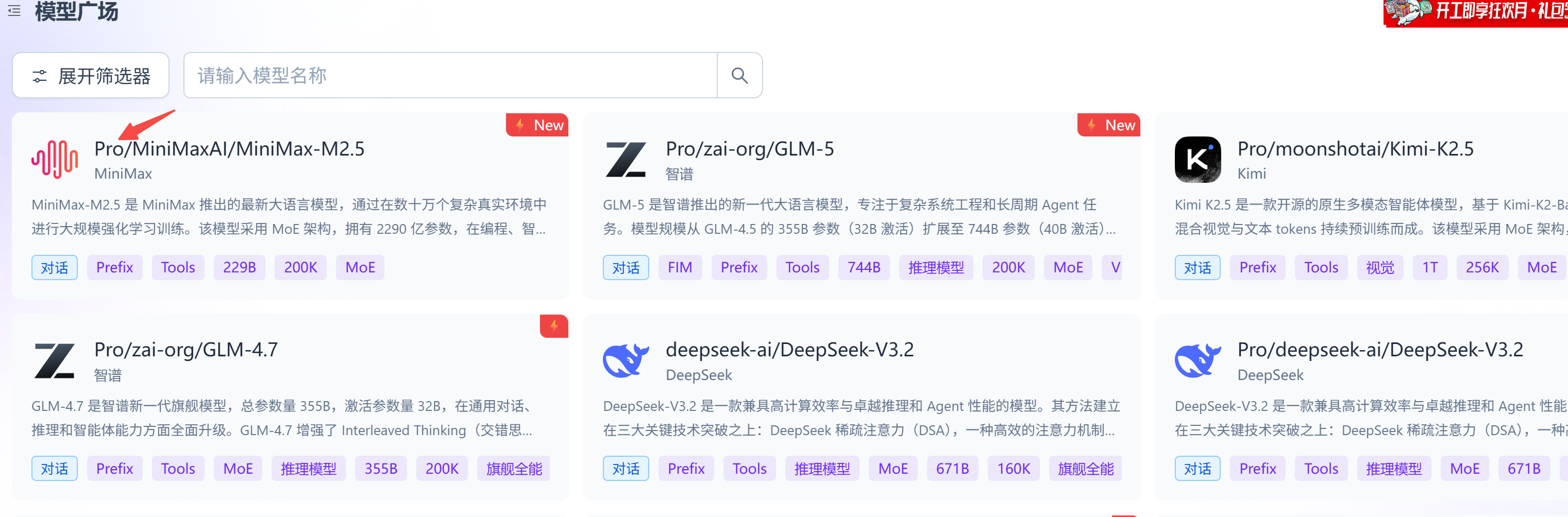
拿到 api_key 后,同时保存请求地址:
OPENAI_API_BASE:https://api.siliconflow.cn/v1
1.2 七牛云
注册:https://s.qiniu.com/YBVZ73,+1000万Token免费额度。
模型广场:https://portal.qiniu.com/ai-inference/model
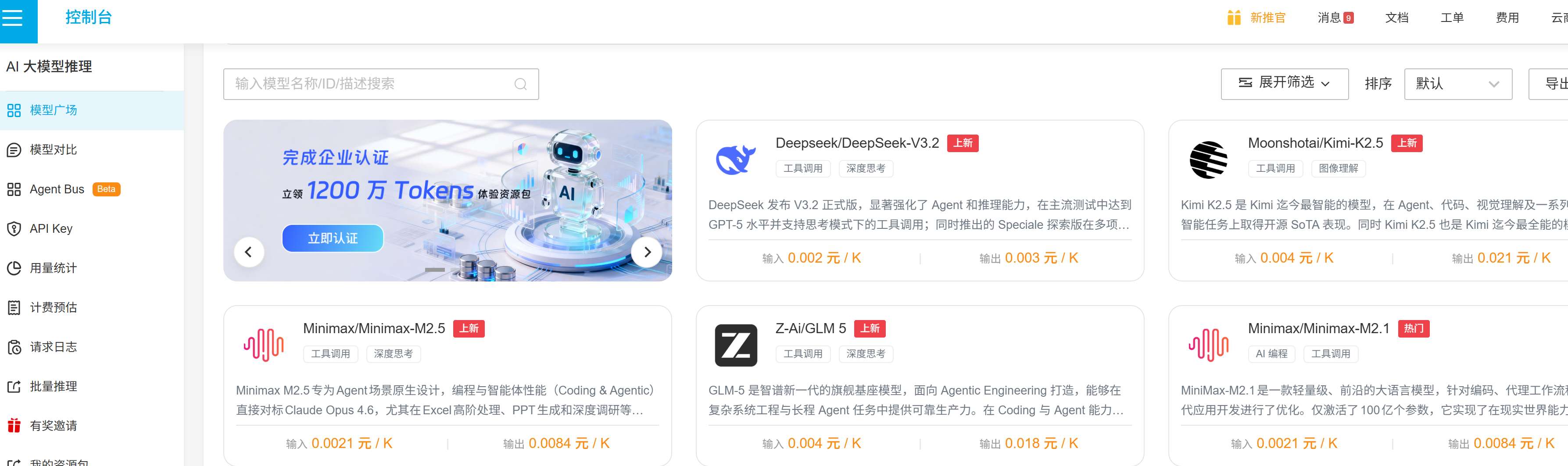
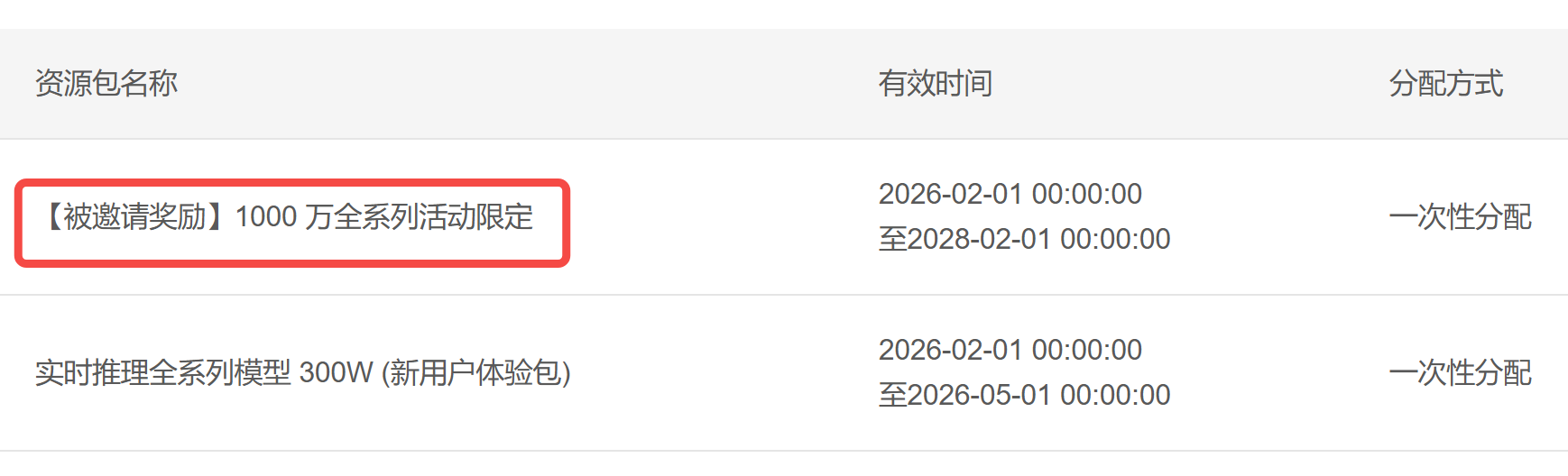
使用邀请奖励:
拿到 api_key 后,同时保存请求地址:
OPENAI_API_BASE:https://api.qnaigc.com/v1
2. OpenClaw容器化部署
2.0 最低资源配置
笔者在一台2c2g的机器上测试过:
# free -m
total used free shared buff/cache available
Mem: 1966 1479 164 1 497 487
Swap: 4095 743 3352
OpenClaw gateway启动后,内存占用1500M左右,结合虚拟内存,可以无压力运行。
因此,HuggingFace上免费的2c16g实例绰绰有余。
前文,分享了如何在HuggingFace上新建Space和Dataset,以实现持久运行和状态保存。
具体步骤,参考前文,不再赘述。
这里笔者重新梳理了Space的文件,方便大家配置:
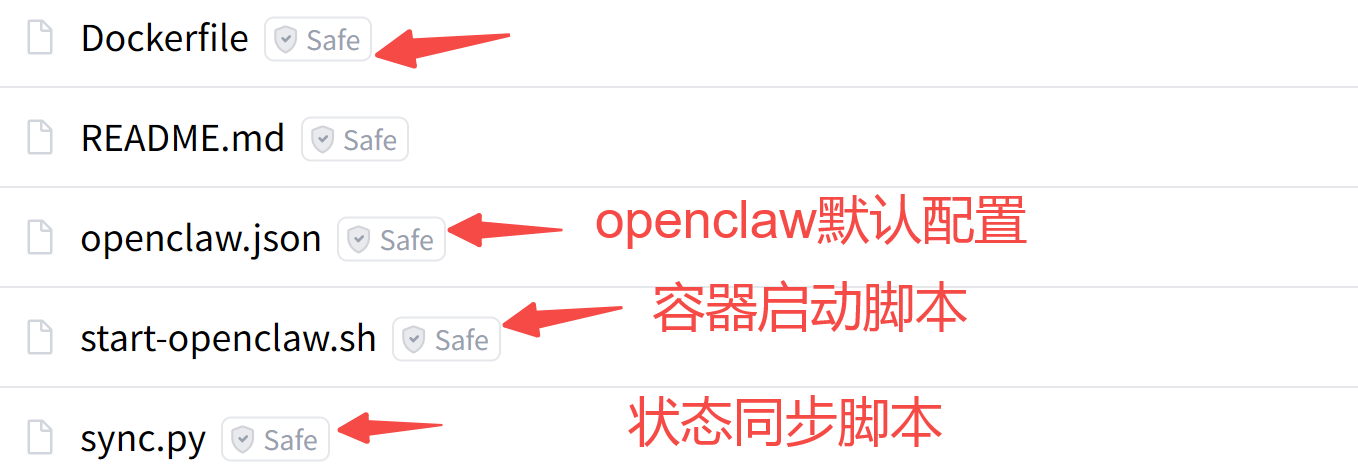
注:所有文件已打包,需要的朋友,文末自取。
下面,梳理下这些文件的具体作用。
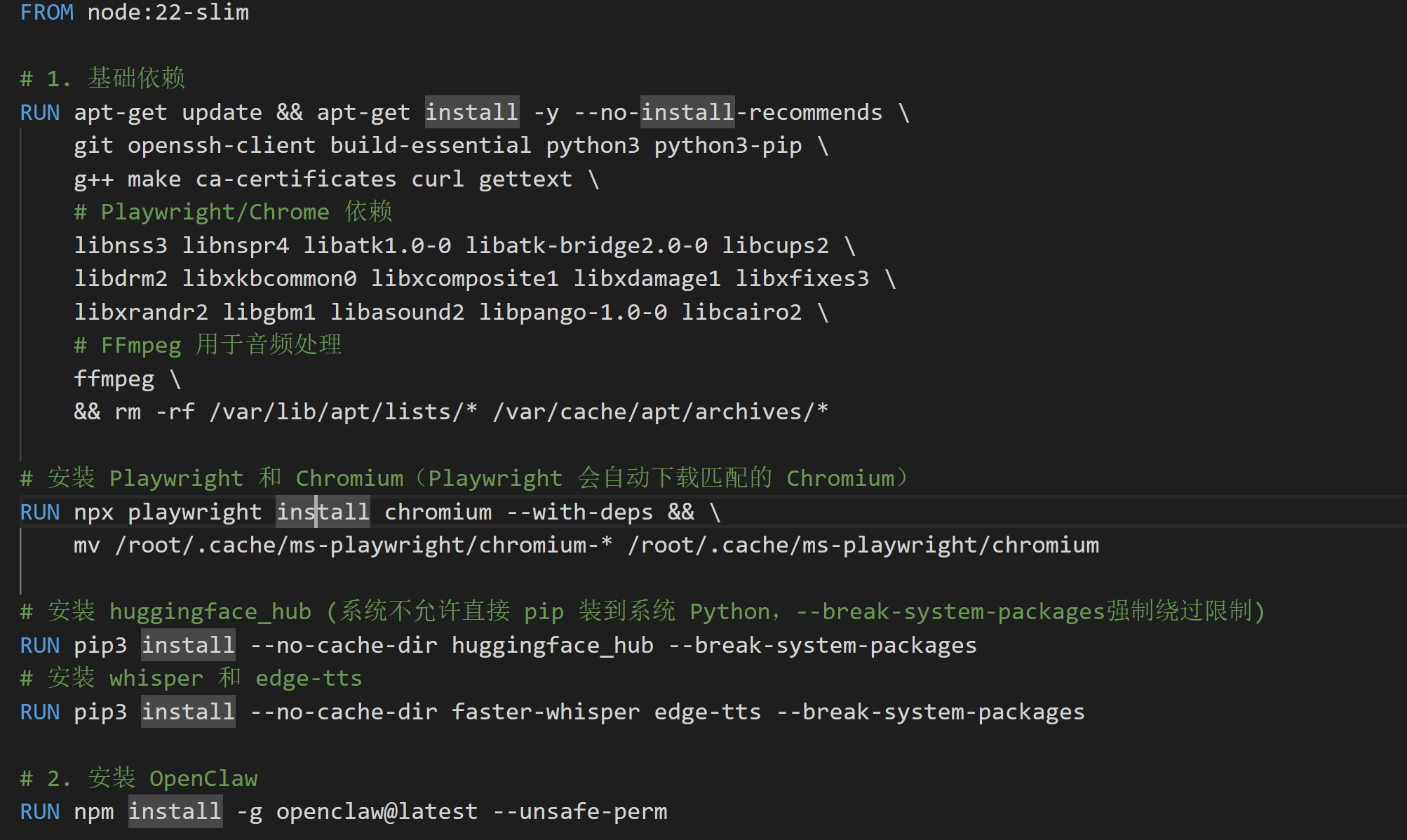
2.1 镜像构建文件
Dockerfile,容器运行的基础环境,Space启动时先构建镜像,然后才会拉起一个容器。
在上一版镜像的基础上,这里集成了更多基础能力:
- 浏览器自动化
- 语音识别和语音合成
- 视频处理
大家可按需修改:
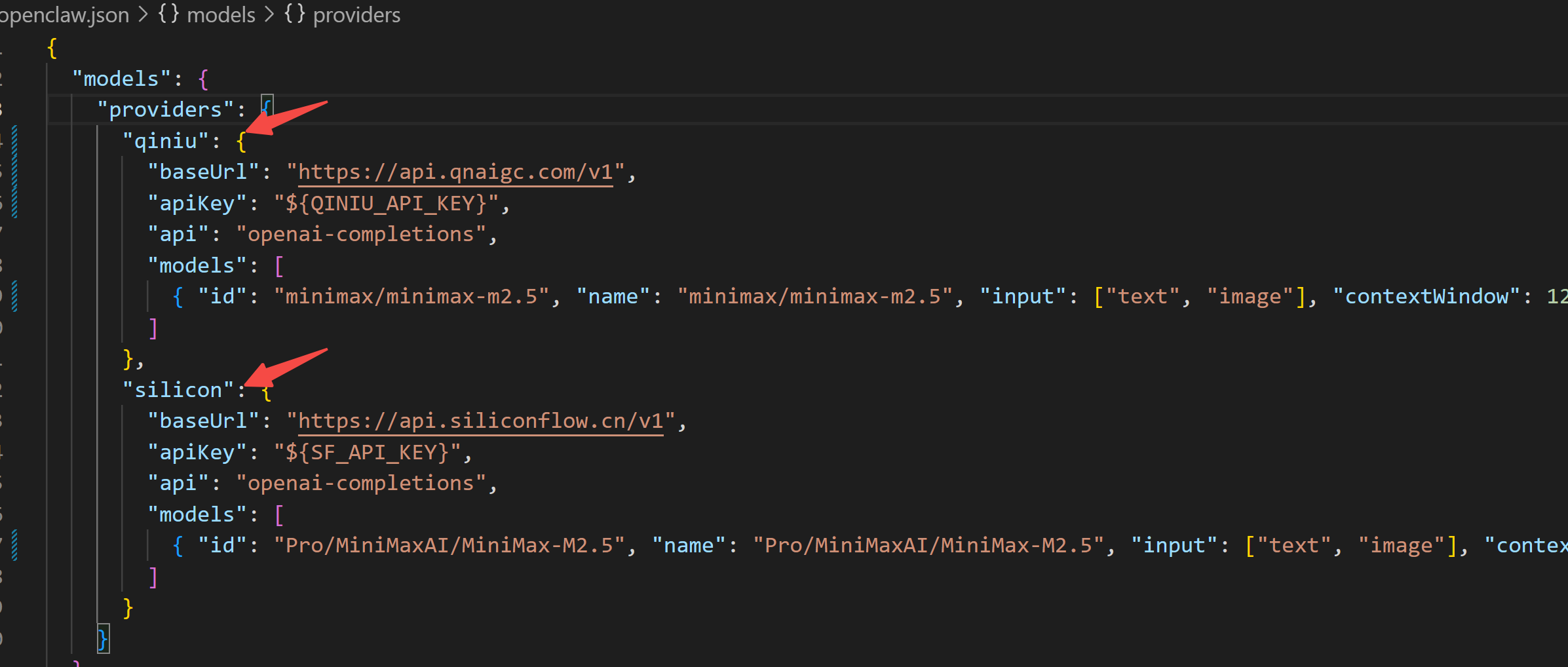
2.2 openclaw默认配置
openclaw依靠根目录下的openclaw.json配置文件运行。
为此,独立出来编辑,填入不需要变动的默认配置。
比如,接入不同的模型供应商:
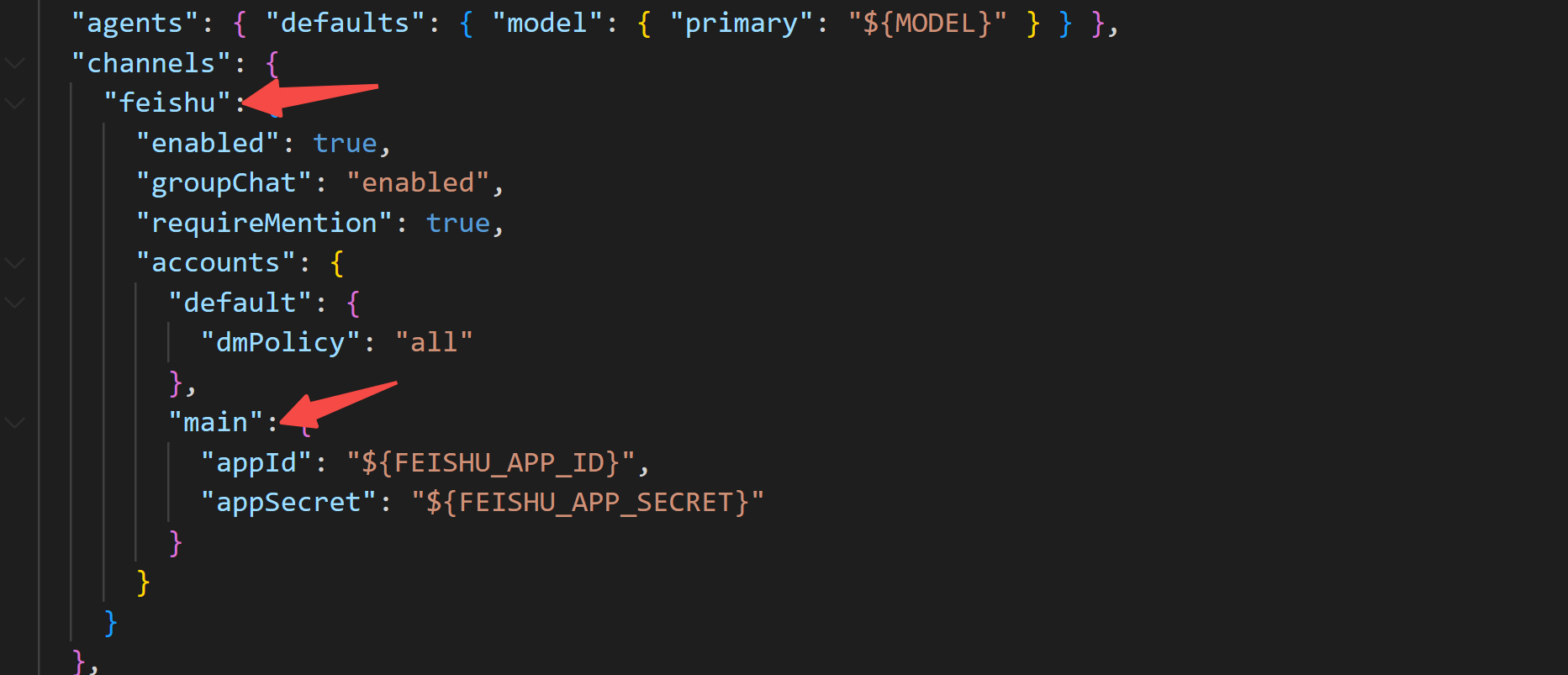
再比如,接入不同的消息通道:
我们把 api_key 等敏感参数,通过环境变量配置,在space设置中添加。
2.3 状态同步脚本
/root/.openclaw包含了所有和openclaw交互的数据,需要永久保存。
我们新建 sync.py,负责和 Dataset 同步数据。
- 容器启动时:从
Dataset上拉取数据 - 容器运行时:定时把数据上传到
Dataset
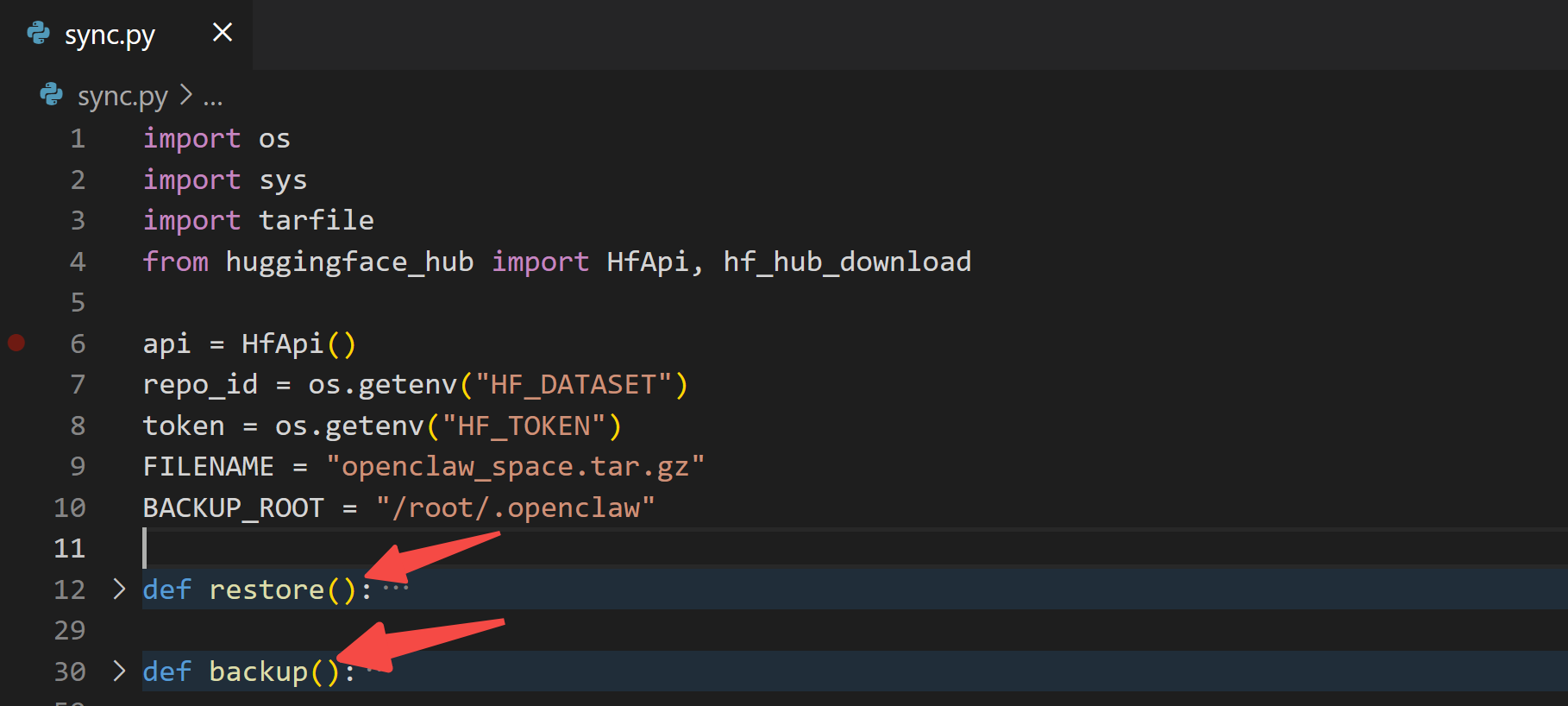
2.4 容器启动脚本
这个脚本决定容器如何运行:
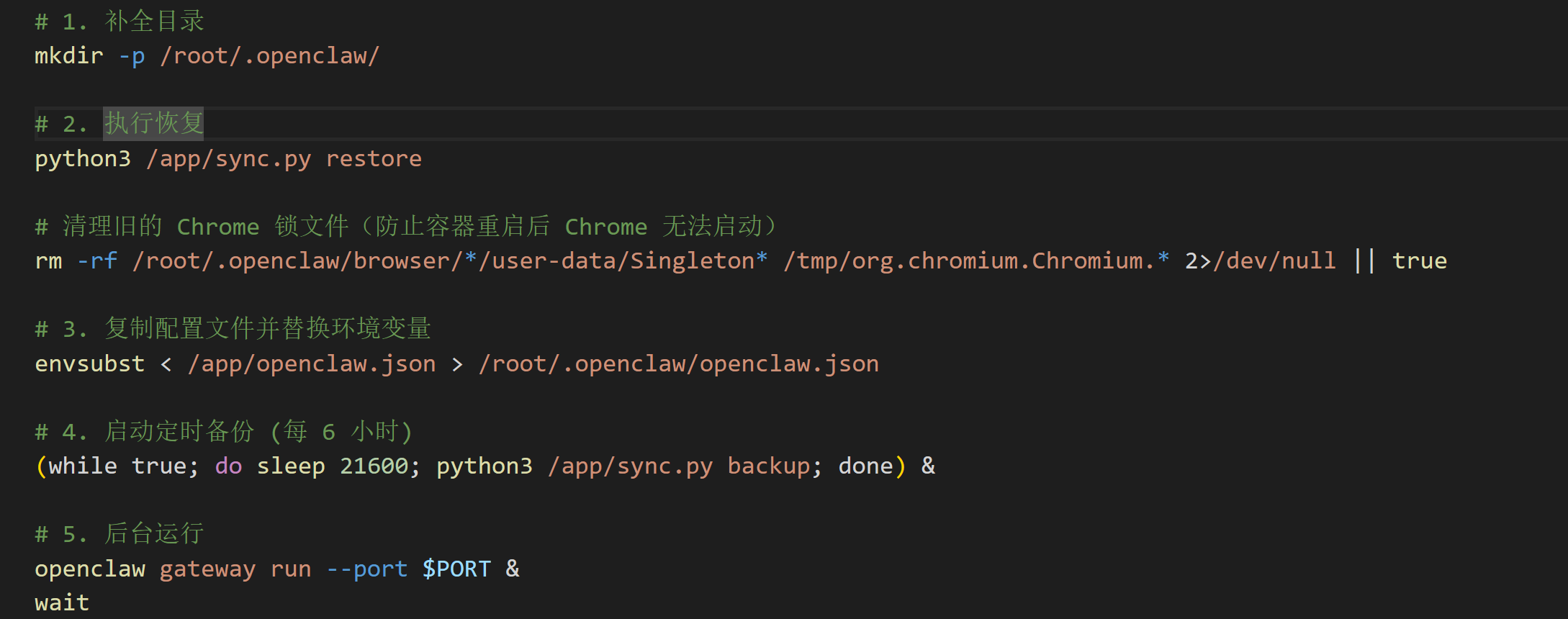
最后一步,将openclaw放到后台运行,避免gateway重启,导致容器挂掉、数据丢失。
2.5 配置 Space
回到你的 Space,右上角点击 Settings,拉到最下面找到 Variables and Secrets,把刚才openclaw.json中的所有环境变量都填进去。
重点:找到 Space visibility,将space置为公开:

当space的运行状态变成running,恭喜你,你的openclaw已成功启动!
打开你的 Space 地址看看吧:
https://{user}-{space}.hf.space
注:私有
space,只有在登录时才能访问上述地址,所以要把space置为公开。
3. 消息通道接入指南
OpenClaw 的核心亮点:一个 Gateway 连接所有消息通道。
本文主要分享如何接入国内的三个通道:
- 飞书
- 企业微信
- 微信
3.1 接入飞书
最新版openclaw已接入飞书,不需要额外安装插件。
你只需要前往飞书开发平台,创建一个应用:
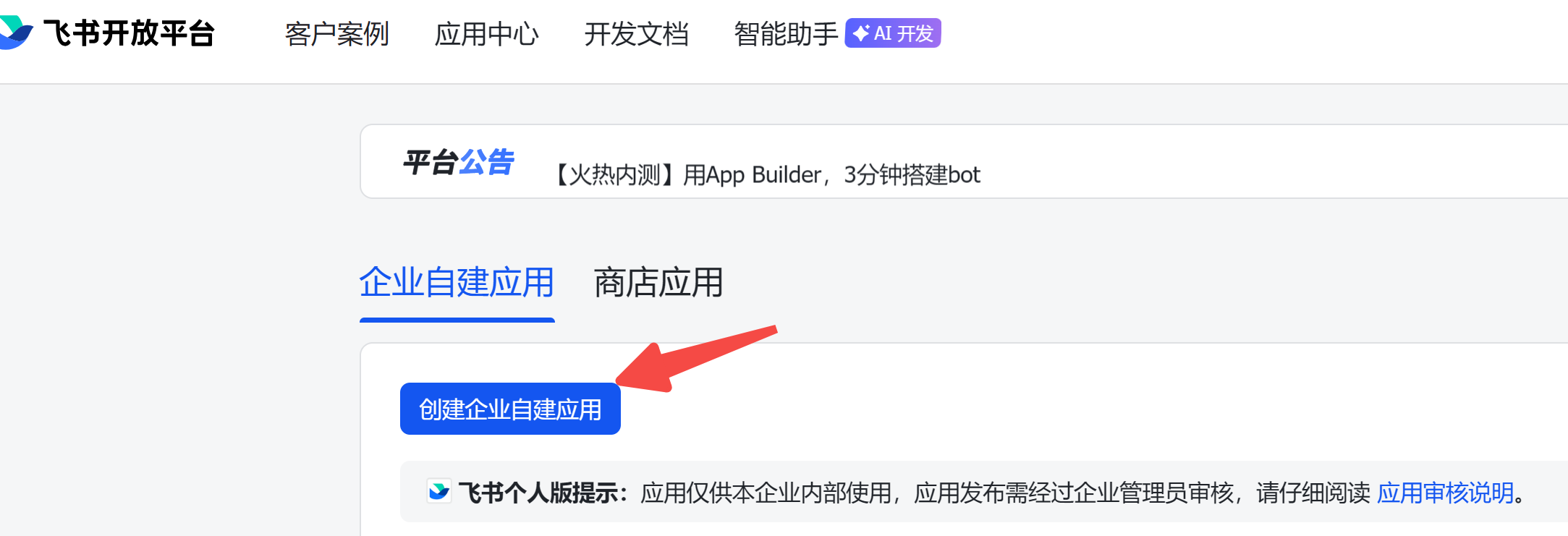
拿到 AppID 和 AppSecret,对应刚才配置文件中的环境变量。
然后,在事件与回调中,采用长连接订阅事件: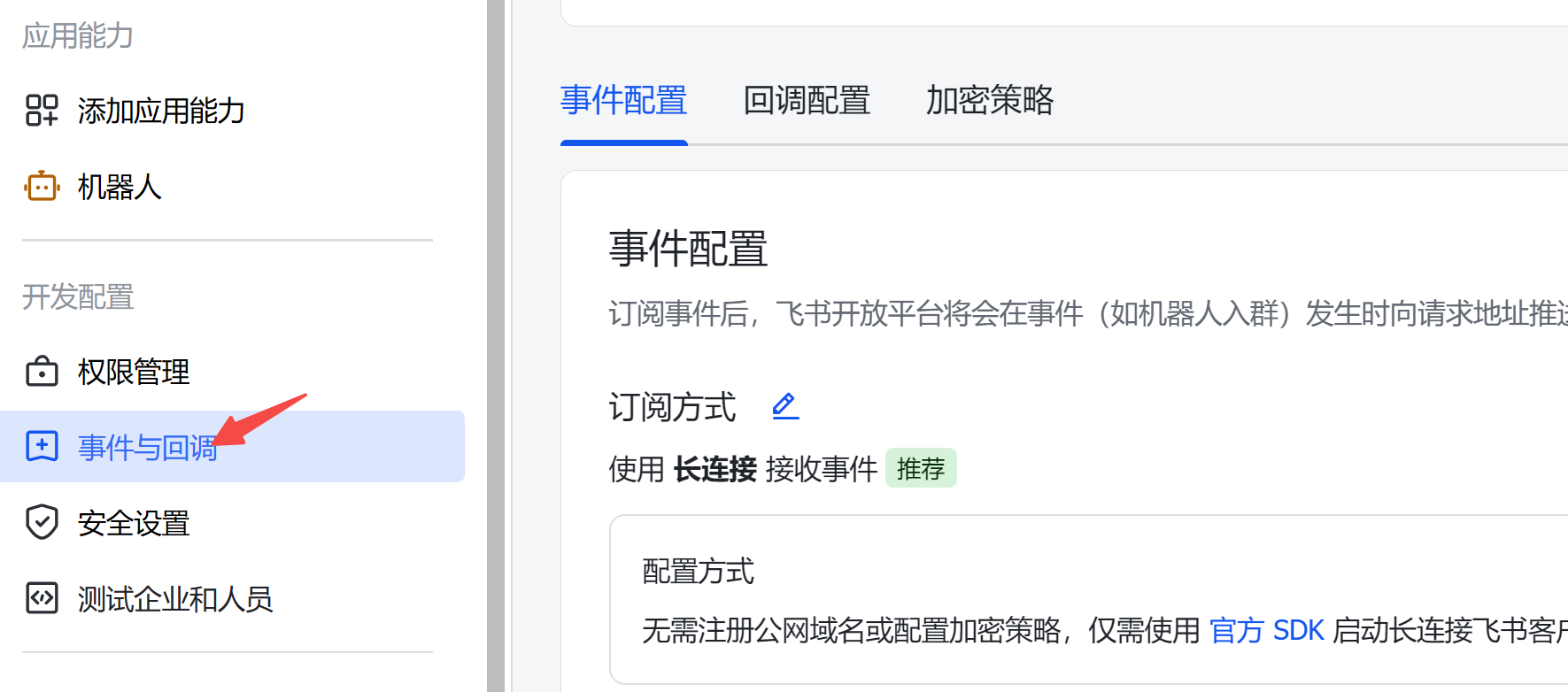
给应用开通权限,也可以导入其它应用配置好的权限(文末自取):
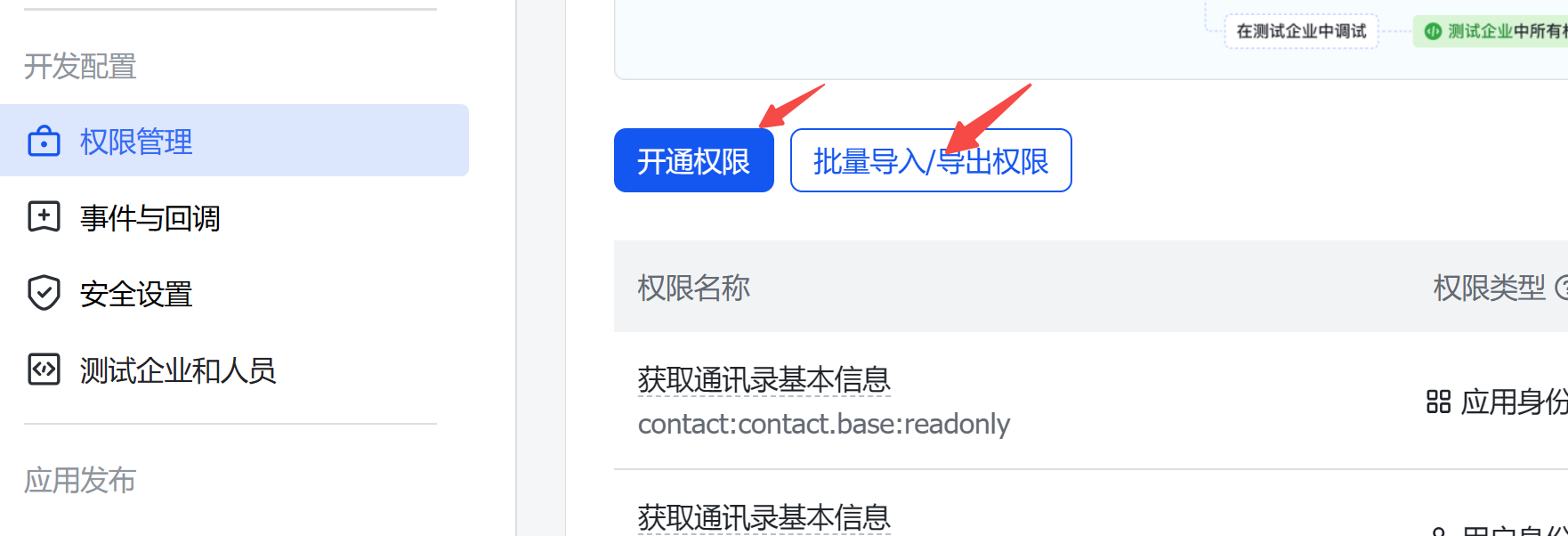
配置成功后,在飞书中给机器人发消息试试~
如果没收到回复,前往控制台,让openclaw帮你看看哪里出了问题。
踩坑记录:如果飞书无法接收图片,大概率是缺少下面这个权限:
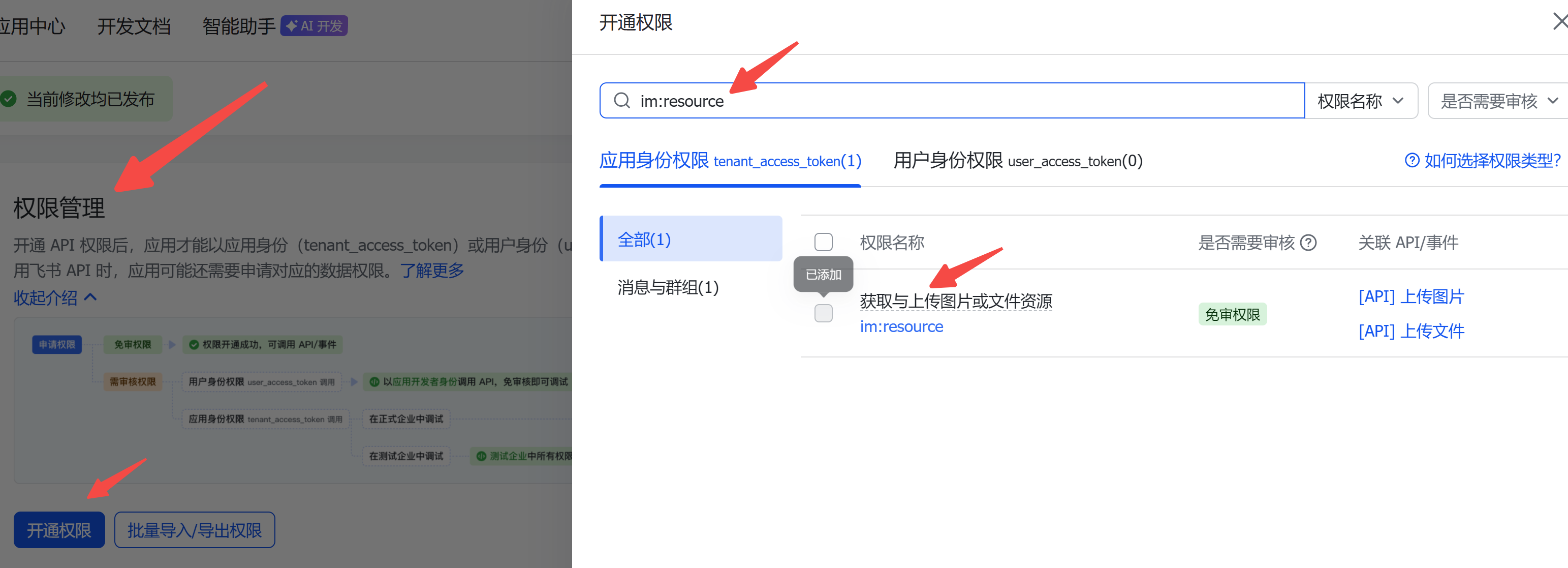
openclaw给飞书发送图片需要两步:
- 上传图片到飞书服务器,获取 image_key
- 用 image_key 发送图片
即便是图片url,也需要先下载到内存,再上传到飞书服务器。
3.2 接入企业微信
企业微信官方,已支持通过企业微信机器人接入openclaw。
参考文档:https://open.work.weixin.qq.com/help2/pc/cat?doc_id=21657
两条命令搞定:
# 安装插件
openclaw plugins install @wecom/wecom-openclaw-plugin
# 不需要重启OpenClaw
# 添加渠道-选择企业微信
openclaw channels add
OpenClaw 的插件系统支持从 npm 仓库安装包。
当你执行 openclaw plugins install xx 时:
- OpenClaw 从 npm 仓库下载这个包
- 安装到 ~/.openclaw/plugins/
- 自动加载插件,注册企业微信通道
注:企业微信机器人支持群聊,但只能在企业内部群中使用,不可拉到外部群。
也即:个人微信无法和企业微信机器人聊天。
3.3 接入个人微信
个人微信,需要通过企业自建应用接入openclaw。
参考文档:https://github.com/BytePioneer-AI/openclaw-china/blob/main/doc/guides/wecom-app/configuration.md
然后,通过微信插件的形式接入个人微信:
同样,两条命令搞定:
# 安装插件
openclaw plugins install @openclaw-china/wecom-app
# 不需要重启OpenClaw
# 配置
openclaw china setup
4. 技能系统接入指南
Skill 本质上是将最佳实践代码化和文件化。
最早由 claude 提出:

4.1 openclaw的技能系统
openclaw的强大,很大程度上也得益于 skill。
在openclaw中,skill存在于3个位置:
- 内置skills:
/usr/local/lib/node_modules/openclaw/skills
# 对应windows下的目录:
C:\Users\admin\AppData\Roaming\npm\node_modules\openclaw\skills
- 全局skills:
~/.openclaw/skills - Agent专属skills:
~/.openclaw/workspace/skills
OpenClaw 启动时会从三个地方加载 skill:
workspace/skills (最高优先级)
↓
~/.openclaw/skills (共享 skills)
↓
node_modules/openclaw/skills (内置,最低优先级)
4.2 Skill安装方式
方式1:复制粘贴(最简单)
对于简单的skill,把skill包放到.openclaw/skills/文件夹下即可。
方式2:从技能市场安装
在openclaw中,clawhub默认已安装。
在市场中找到需要的skill,直接命令行安装:
clawdhub install self-improving-agent
方式3:Skills CLI安装
Vercel 出品的命令行工具,一行命令安装任意开源skills:
# 格式
npx skills add vercel-labs/skills@find-skills -g
# 默认会装到 ~/.agents/skills/find-skills
# Skills CLI 自动检测 OpenClaw 存在,创建 symlink 到 ~/.openclaw/skills/
# 如果访问github失败,也可下载到本地后安装
npx skills add ./xx --skill find-skills
4.3 Skill推荐
结合笔者的使用频率,给大家推荐几个值得安装的skill:
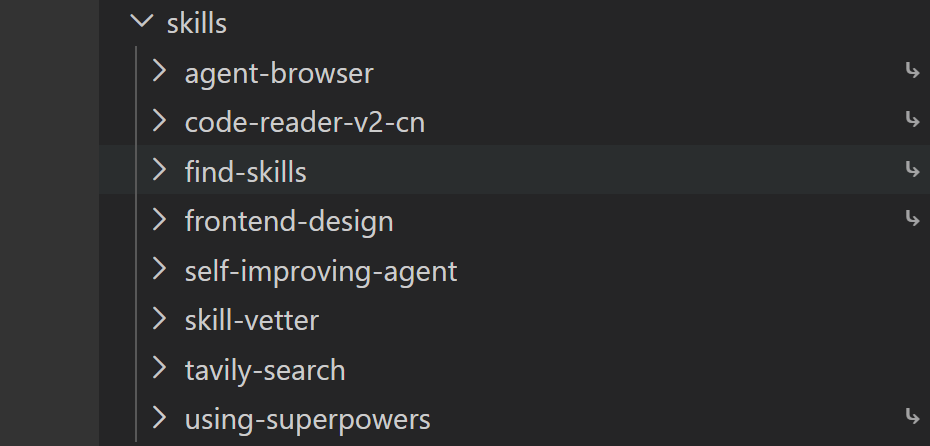
其中,超链接都是采用Skills CLI安装的。
1. find-skills
技能发现 - 帮你找有没有现成的 skill
搜索技能:npx skills find <关键词>
安装技能:npx skills add <包名>
浏览地址:https://skills.sh/
2. self-improving-agent
自我改进 - 记录经验教训,持续优化。重要 learnings 可以升级到 SOUL.md、AGENTS.md、TOOLS.md
触发场景:
3. skill-vetter
安全审查 - 安装第三方 skill 前先检查
检查内容:
权限 scope 是否过大
是否有可疑模式(窃密、高风险操作)
来源是否可靠
4. using-superpowers
技能使用规则 - 如何正确调用技能的核心指南
核心原则:即使 1% 的可能性,也要调用 Skill 工具检查
简单说:别偷懒,觉得可能有用就读一下技能,都没用再开干。
5. agent-browser
浏览器自动化 - 基于rust实现的无头浏览器。
打开网页、填表、点击按钮、截图、提取数据
支持表单提交、登录认证、文件下载
可模拟不同设备和视口
指令:agent-browser open <url> → snapshot -i → click @e1 → ...
6. frontend-design
前端界面设计 - 生产级 UI 开发
创建独特、有设计感的界面(避免 AI 的"垃圾审美")
支持 HTML/CSS/JS、React、Vue 等
强调:字体选择、色彩搭配、动效、空间构图
必须选择一个明确的风格方向并执行到位
7. code-reader-v2-cn
源代码深度理解 - 基于认知科学的代码分析
三种模式:
Quick (5-10分钟) - 快速概览
Standard (15-20分钟) - 标准理解
Deep (30分钟+) - 深度掌握
特点:强制"为什么"思考、自我解释测试、检索练习,避免"假懂"
8. tavily-search
Tavily 搜索 - AI 优化的网络搜索
比普通搜索更适合 AI 处理
返回简洁、相关的结果
支持地区和语言过滤
5. 两层记忆机制剖析
openclaw 是如何记住你的?
答:Markdown (文件) + sqlite(向量索引)
优势:透明可控 + 智能检索
5.1 文件记忆
~/.openclaw/agents/main
└── sessions/
└── *.jsonl # 会话记忆(自动记录)
~/.openclaw/workspace/
├── MEMORY.md # 长期记忆(精华浓缩版,存决策、偏好、经验教训)
└── memory/
└── YYYY-MM-DD.md # 每日笔记(默认加载今天 + 昨天的日志)
5.2 向量记忆
向量保存和检索流程:
Markdown 文件 → 分块(~400 token,80 token 重叠)
↓
生成嵌入向量(OpenAI/Gemini/本地模型)
↓
存入 SQLite(chunks 表 + chunks_fts 全文索引)
↓
查询时:混合搜索(向量相似度 + BM25 关键词)
数据库位置:~/.openclaw/memory/main.sqlite
注:
SQLite只是索引层,不是记忆本身。真正的记忆是 Markdown 文件。
默认配置是 FTS-only,没有向量嵌入。
要启用向量搜索,需要在 openclaw.json 配置 memorySearch.provider:
- openai
- local
- …
配置后,支持语义搜索、混合搜索
- 混合搜索:向量语义匹配 + BM25 关键词匹配。
记忆调用有两种方式:
memory_search 语义搜索,返回片段+路径+行号
memory_get 按路径读取特定记忆文件
6. 定时任务机制剖析
openclaw的 Cron 是 Gateway 内置的任务调度器。
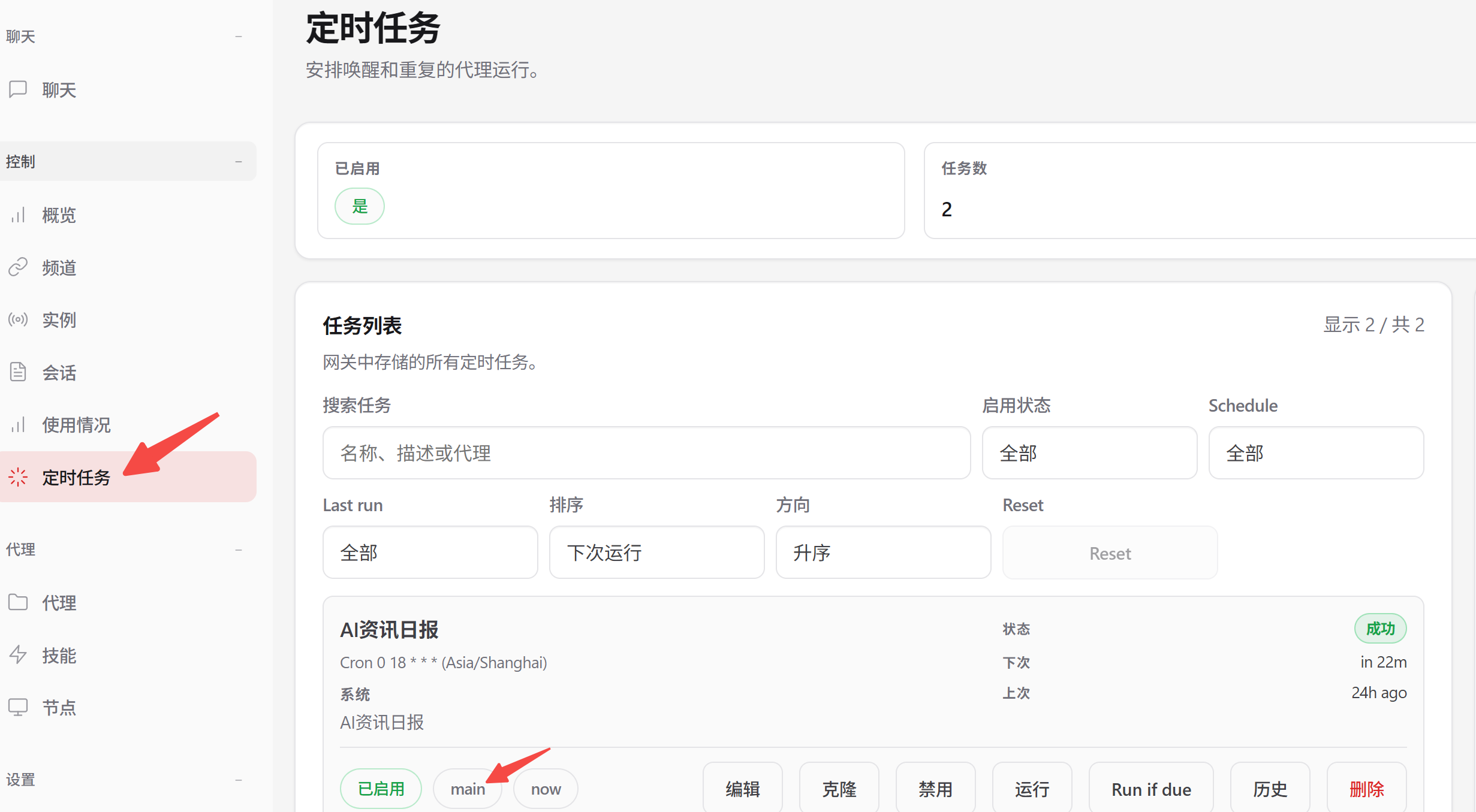
它有两种执行模式:
主会话模式 main:在主会话中跑
- 适合:需要主会话上下文的简单提醒。
# 例如
openclaw cron add --name "任务名" --cron "0 8 * * *" --session main --system-event "触发时要做的事" --tz "Asia/Shanghai"
隔离模式 isolated:在独立会话中运行(会自动在session列表中创建会话),可以配置自动发送结果到指定通道。
- 适合:后台任务、定期报告、不想污染主会话的事务。
文件位置:
任务定义: ~/.openclaw/cron/jobs.json
执行历史: ~/.openclaw/cron/runs/xx.jsonl
常用命令:
# 查看任务列表
openclaw cron list
# 修改任务
openclaw cron edit <任务ID> --system-event "新消息"
# 手动测试
openclaw cron run <任务ID>
7. 智能体和会话机制
7.1 Agent(智能体)
Agent 是 OpenClaw 的核心概念——一个完整的大脑,包含:
| 组件 | 说明 |
|---|---|
| Workspace | 工作目录,存放 AGENTS.md、SOUL.md、USER.md 等配置文件 |
| Agent 状态 | ~/.openclaw/agents/agentId/agent/ |
| 会话汇总 | ~/.openclaw/agents/agentId/sessions/sessions.json |
| 会话记录 | ~/.openclaw/agents/agentId/sessions/sessionId.jsonl |
Agent 的特性:
- 技能独立:通过各自的 skills/ 文件夹加载技能,也可共享全局技能
- 会话隔离:不同 Agent 的会话互不影响
默认只有一个 main Agent。
如何创建更多 Agent?
命令行创建:
# 假设要创建一个名为 nanny 的 Agent
openclaw agents add nanny --workspace C:\Users\admin\.openclaw\workspace-nanny
创建成功后,如何和 Agent 进行对话:
# 如果还没有会话,会自动创建一个 main session
openclaw agent --to nanny --message "hi"
# 给指定 Agent + 指定会话发消息
openclaw agent --to nanny --session-id test --message "hi"
7.2 多 Agent 路由
多 Agent 场景下,可以通过 bindings 将不同通道的消息路由到对应的 Agent:
# 查看所有 bindings
openclaw agents list --bindings
具体配置,可以在openclaw.json中添加路由映射:
"bindings": [
{
"agentId": "main",
"match": {
"channel": "feishu",
"accountId": "main"
}
}
],
7.3 Session(会话)
Session 是 Agent 与用户之间的对话上下文。
不同会话,以会话键(Session Key)区分,映射规则如下:
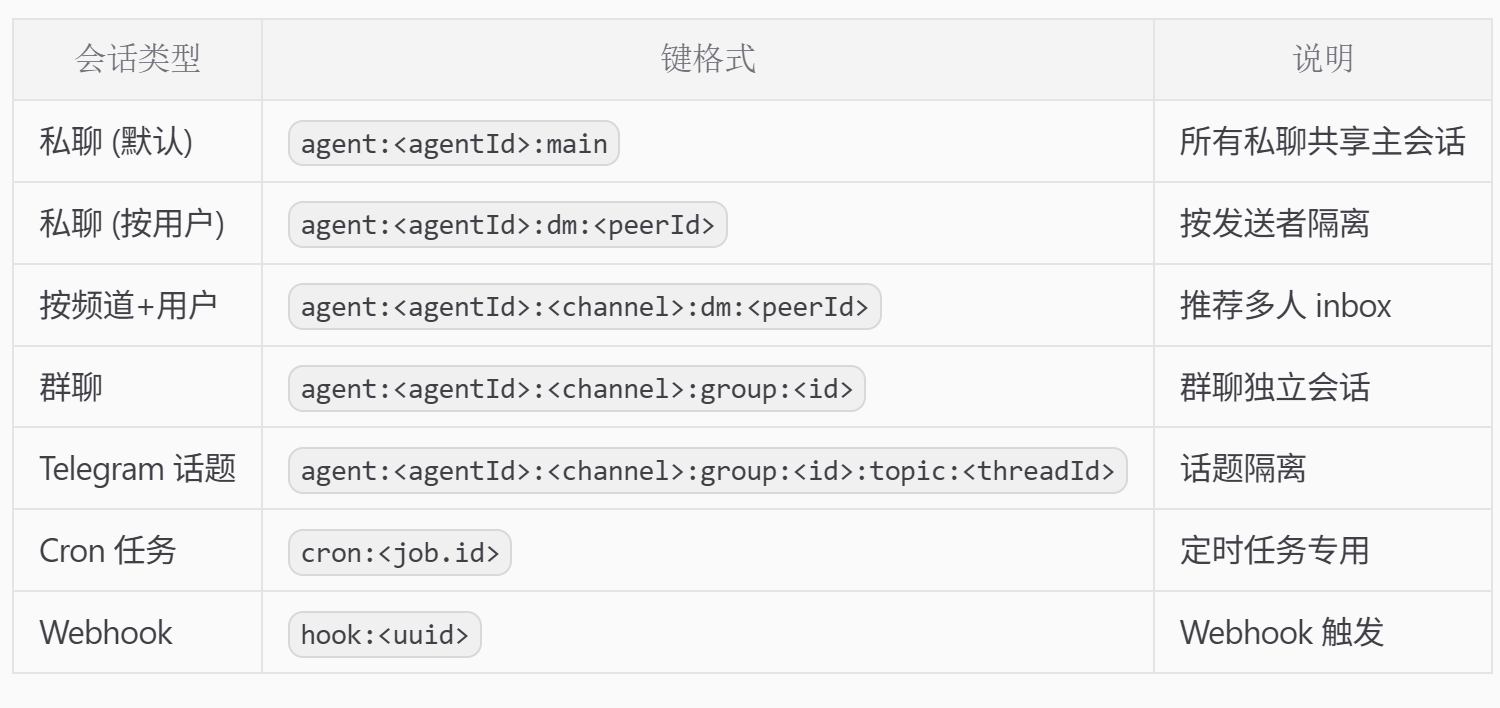
如果需要每个通道的会话隔离,需要在openclaw.json中启用 DM 模式:
"session": {
"dmScope": "per-channel-peer"
},
这样,每个通道连接成功,都会自动新建一个 session,比如我这里:
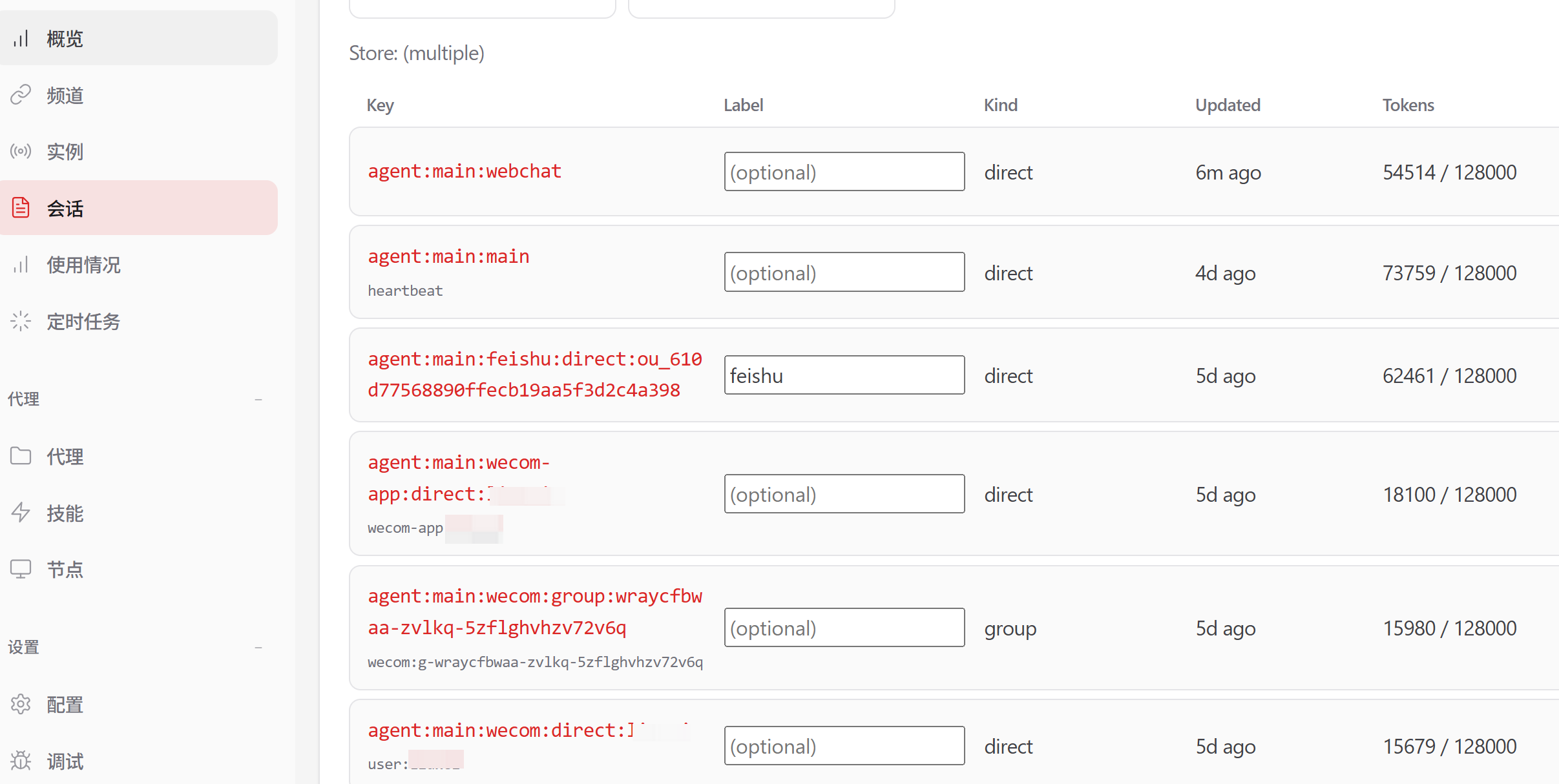
此外,我们还需要定期清理会话文件:
"session": {
"maintenance": {
"mode": "enforce", // 自动清理
pruneAfter: "30d", // 30天不活跃的会清理
"resetArchiveRetention": "1d" // 1天前的重置会话会清理
}
},
当然,也可以手动管理会话:
# 查看会话列表
openclaw sessions list
# 查看特定 Agent 的会话
openclaw sessions --agent nanny
# 清理会话(预览)
openclaw sessions cleanup --dry-run
# 强制清理
openclaw sessions cleanup --enforc
7.4 新建 Session
OpenClaw命令行不支持新建会话。
必须新建一个通道,指定sessionKey,才能新建会话。
目前,小智Pro也是通过这种方式和OpenClaw建立通信,详情可参考:
小智Pro:让小智控制 OpenClaw,一个MCP连接海量Skills
首先,前往小智Pro控制台:https://mkwyqeoebedx.sealosbja.site
指定sessionKey:
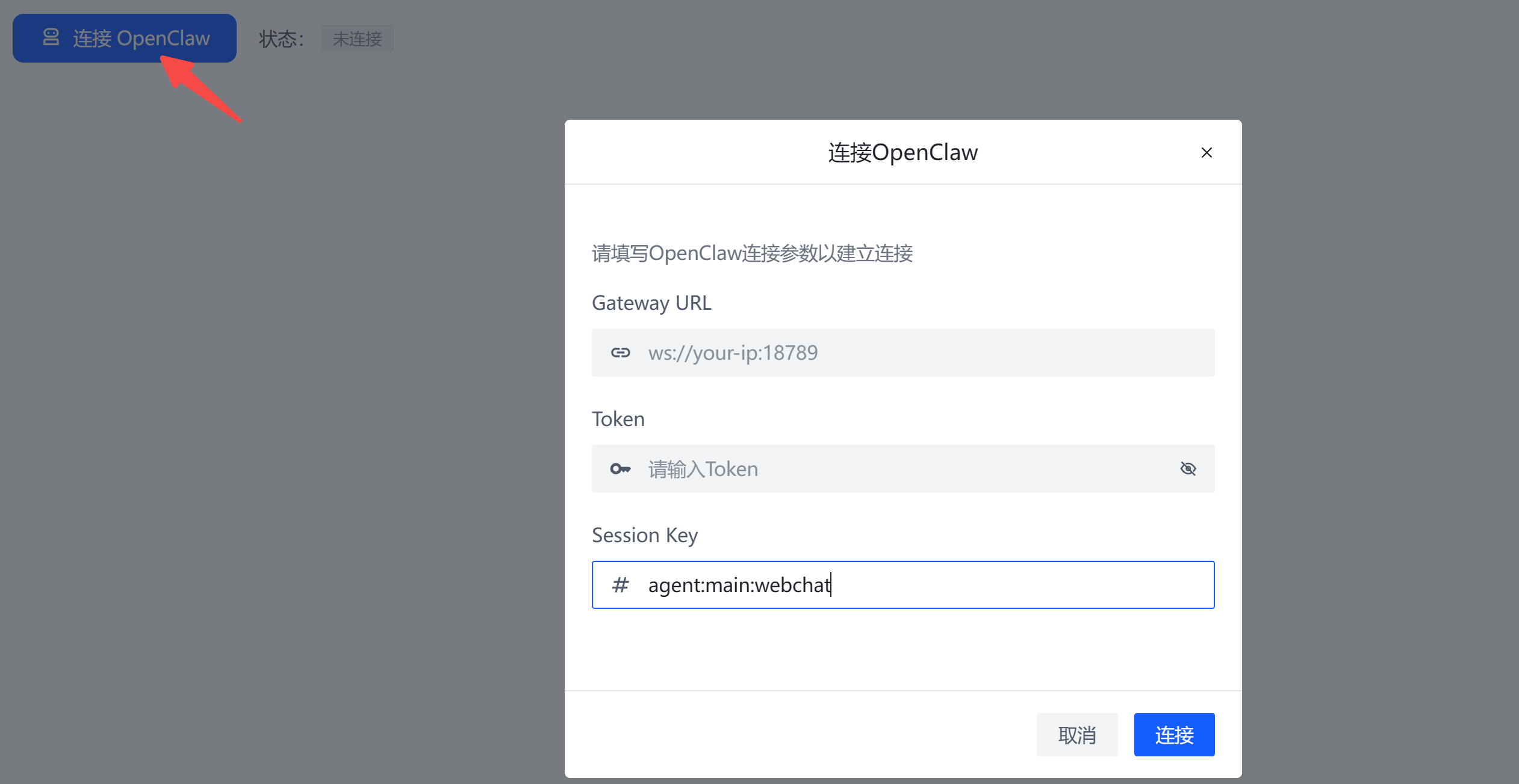
连接成功后,发送一条消息:
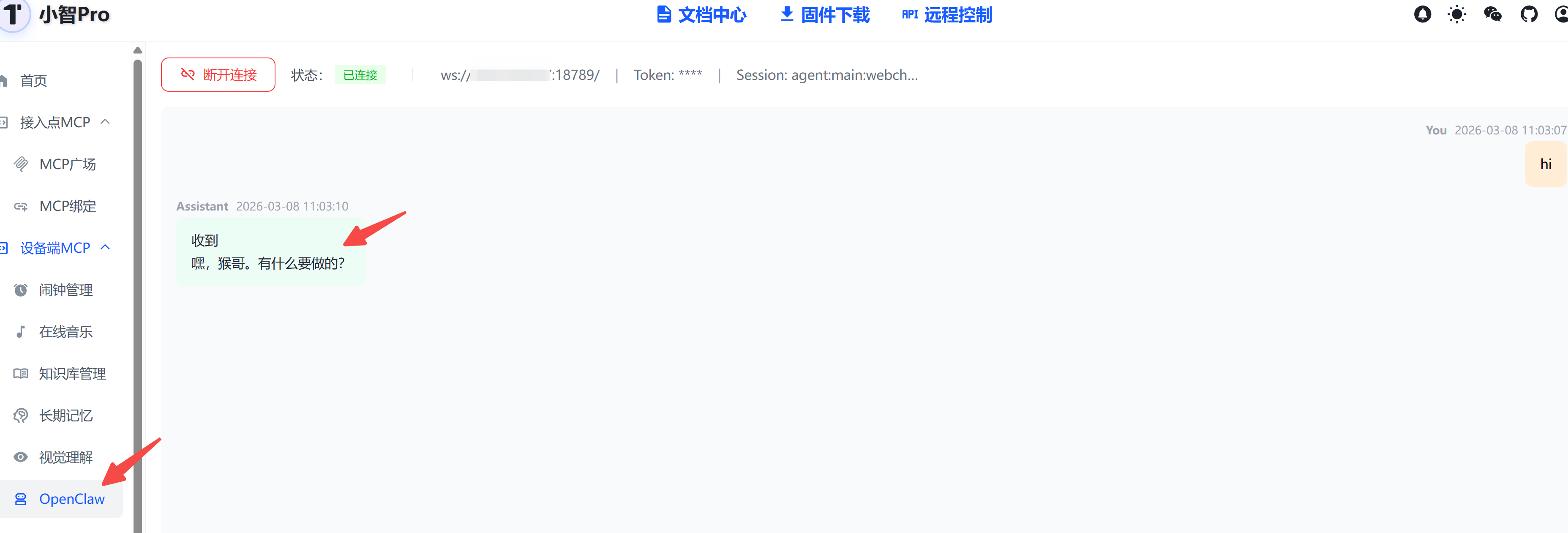
回到 OpenClaw 控制台,查看会话:
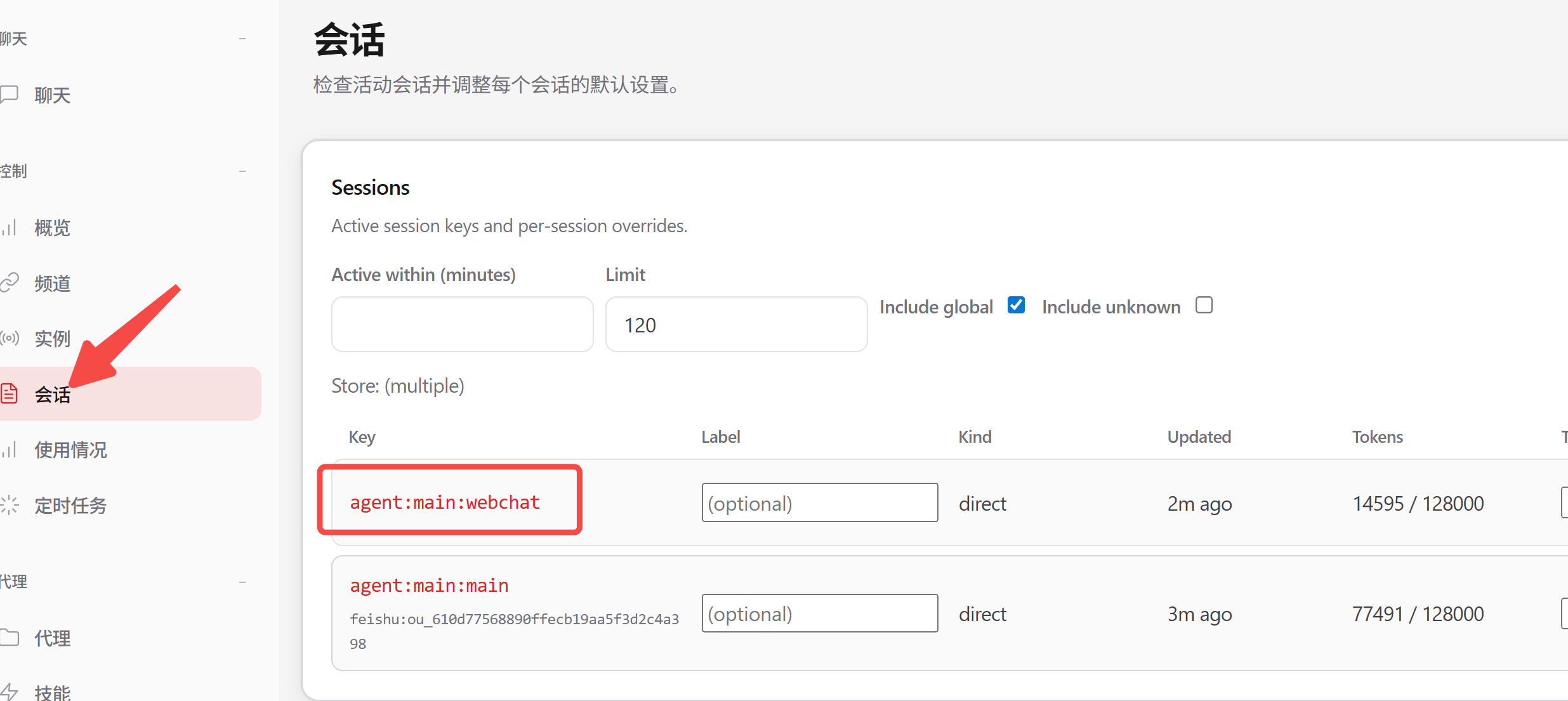
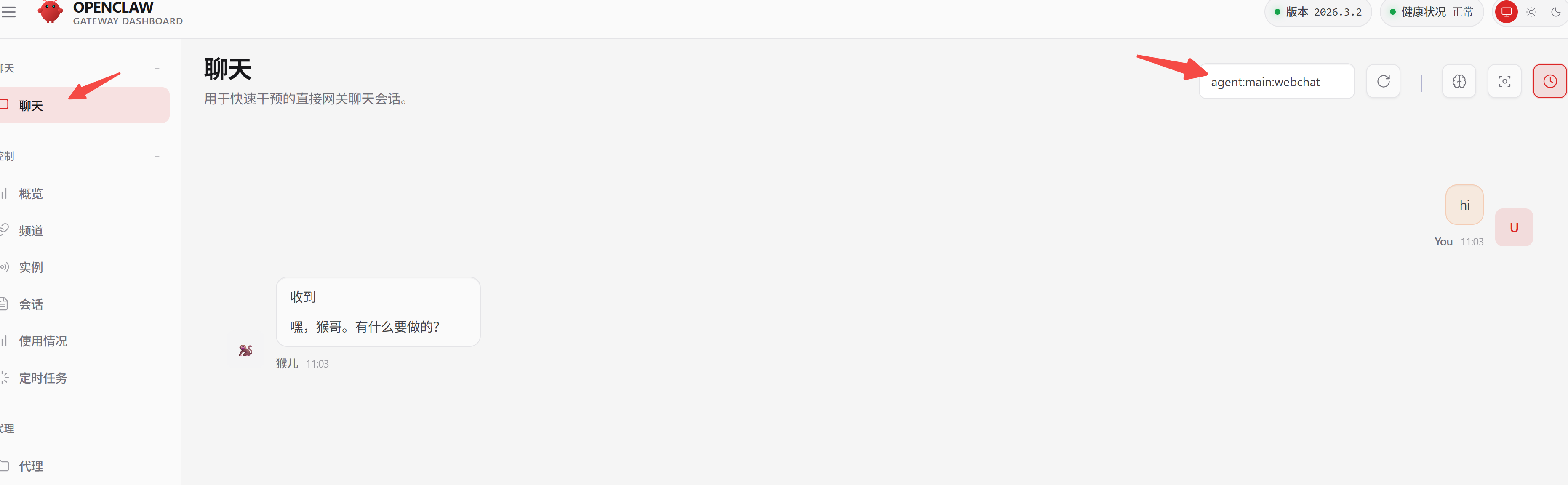
点击会话标题,进入聊天页面,即可看到新会话的记录:
8. 浏览器自动化指南
openclaw 拥有联网能力,本质上有以下 3 种工具:
web_search:调用 brave 等web_fetch:当你给它具体url,发送http请求htmlbrowser:交互式操作浏览器
3 种工具的适用场景如下:
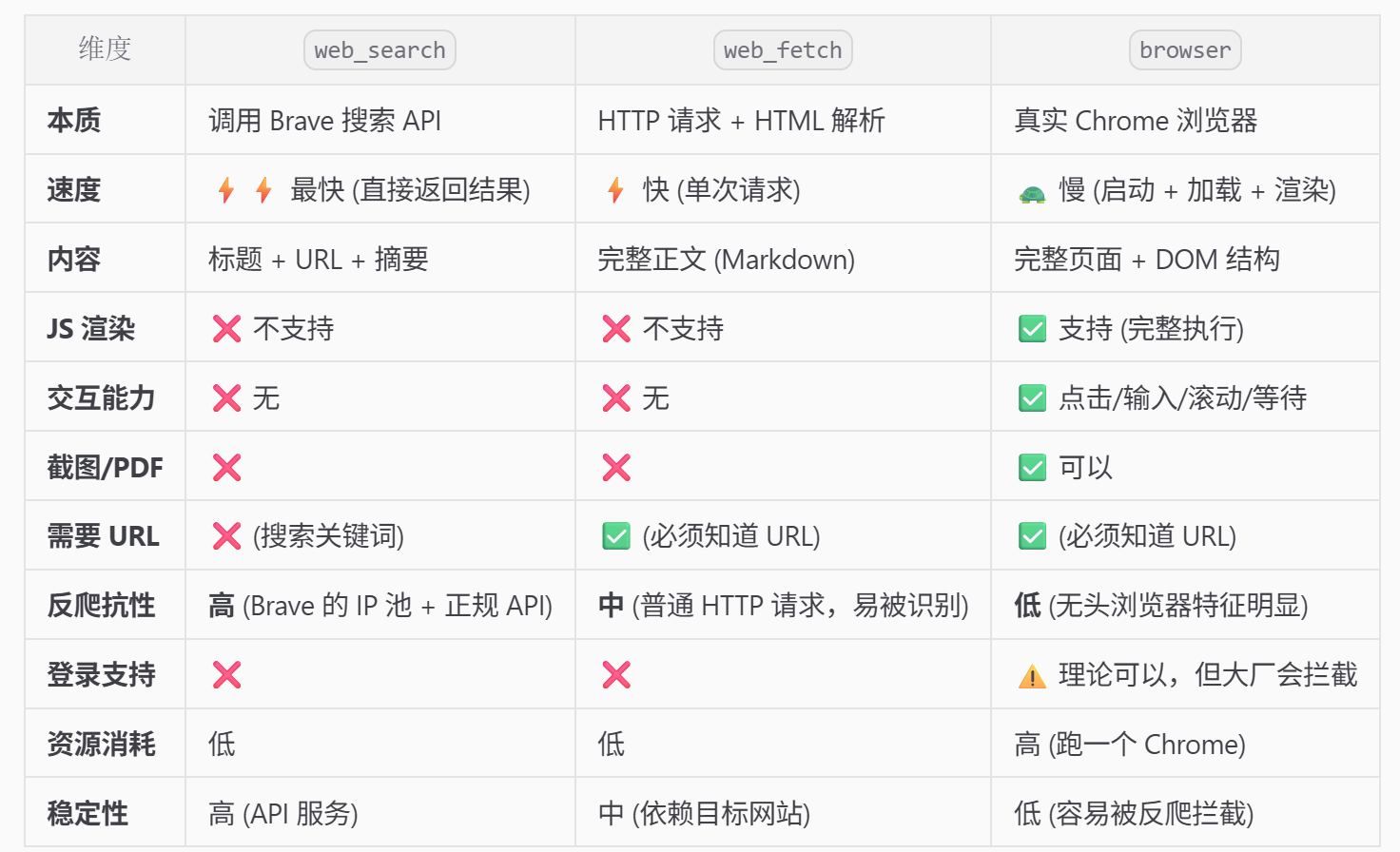
下面重点介绍下 browser 的两种模式。
8.1 browser 简介
browser 有两种模式:
- 有头模式 (chrome):必须有桌面环境(Windows/macOS/Linux 桌面版)
- 无头模式 (后台):无需桌面环境

browser的指令举例:
# 以用户openclaw登录
browser open --profile openclaw --url https://github.com/trending
# 获取页面文本 + 元素结构,非截图
browser snapshot --refs aria
8.2 有头浏览器
有头浏览器的工作原理:
┌─────────────────────────────────────┐
│ Chrome (桌面浏览器) │
│ ┌─────────────────────────────┐ │
│ │ OpenClaw Browser Relay 扩展 │ │
│ └─────────────────────────────┘ │
│ ↓ (通过 chrome.debugger) │
│ Local Relay Server (端口 18792) │
└─────────────────────────────────────┘
↓ (WebSocket 通过 Gateway)
OpenClaw:
┌─────────────────────────────────────┐
│ browser 工具 (profile="chrome") │
│ → 发送命令到你的 Relay │
│ → Relay 控制你的 Chrome 标签页 │
└─────────────────────────────────────┘
怎么搞?
首先前往chrome应用商店,安装OpenClaw Browser Relay:
输入 token 并保存:
新开一个标签页,点击确保这里的状态 ON 即可:
8.3 无头浏览器
无头浏览器适合VPS、容器等无桌面环境的工作场景。
无头浏览器的原理:
┌─────────────────────────────────────┐
│ OpenClaw Gateway │
│ ┌─────────────────────────────────┐ │
│ │ browser 工具 │ │
│ │ → 启动本地 Chrome 进程 │ │
│ │ → 通过 CDP 协议通信 │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────┘
↓ CDP
┌─────────────────────────────────────┐
│ Chrome (无头模式) │
│ --headless --no-sandbox │
└─────────────────────────────────────┘
首先,安装依赖:
# 安装Playwright和Chromium
npx playwright install chromium --with-deps
然后,配置无头模式:
# 在` openclaw.json` 中添加
"browser": {
"enabled": true,
"executablePath": "/root/.cache/ms-playwright/chromium-1208/chrome-linux64/chrome",
"headless": true,
"noSandbox": true,
"defaultProfile": "openclaw"
},
踩坑提醒:
一旦容器重启,如果 Chrome 的锁文件(SingletonLock, SingletonSocket)没清理,会导致新进程无法启动。
解决方案:
# 启动前删除锁文件
rm -rf ~/.openclaw/browser/openclaw/user-data/Singleton*
9. 节点接入指南
OpenClaw 的节点(Nodes)是为了"远程控制终端"。
我们可以通过 OpenClaw 远程控制手机、电脑等终端,比如拍照、截屏、获取位置、发送通知、执行命令等。
9.1 设备和节点的区别
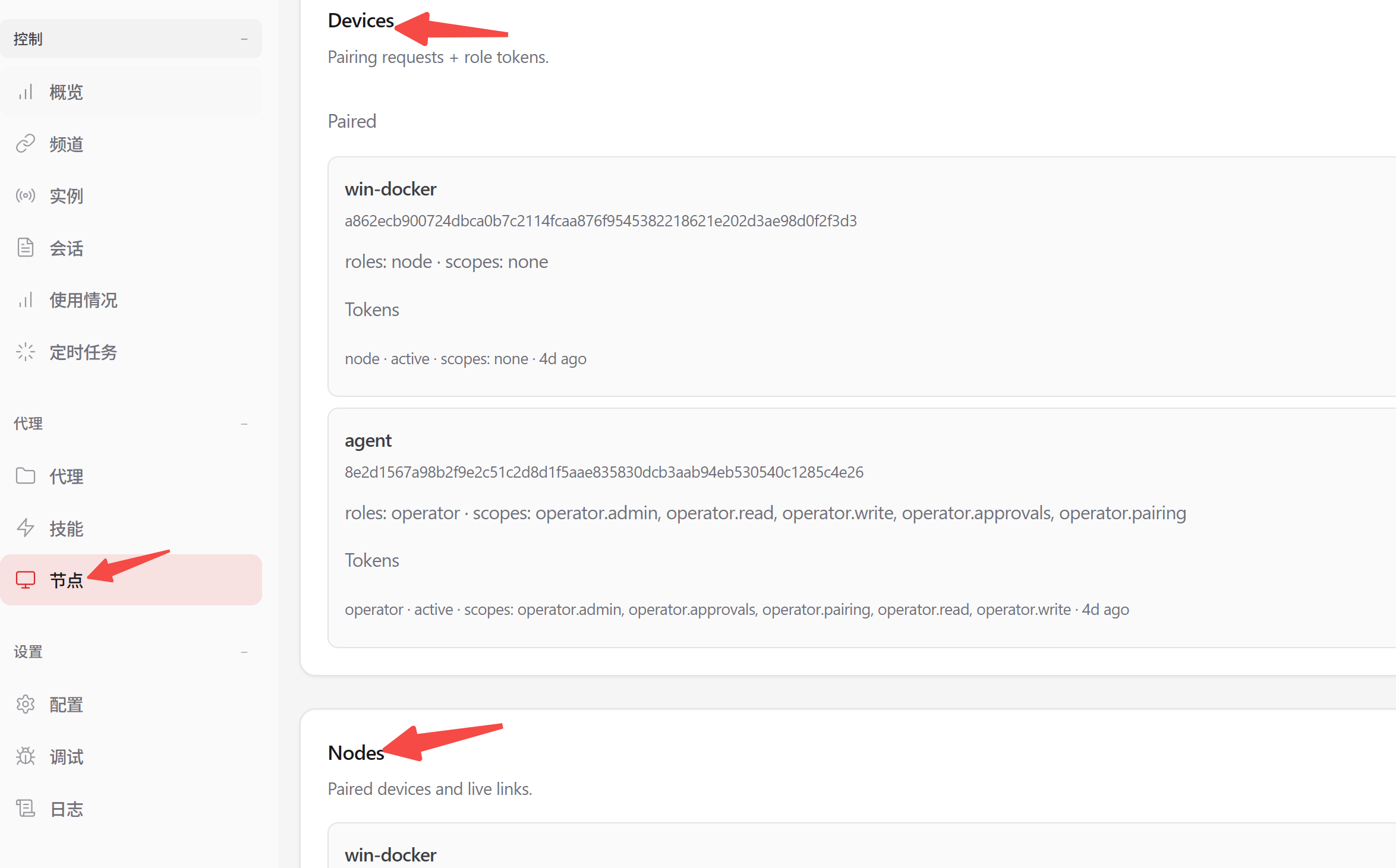
Device(设备)= 配对身份层
- 解决"谁可以连接"的问题
- 两种角色:
- operator(操作员,管理 Gateway)
- node(节点,提供能力)
Node(节点) = 能力层
- 解决"连接后能干什么"的问题
- 节点是配套设备(iOS/Android/macOS/无头主机)
- 暴露具体能力:摄像头、屏幕录制、位置、系统命令等
Device(设备)
├── role: operator → 操作员,管理 Gateway
└── role: node → 节点,暴露能力(camera/screen/canvas...)
9.2 节点接入
假设我要在远程Linux主机上调用windows主机上的浏览器。
如何把windows主机以 node 形式连接到远程Linux主机上的gateway?
实测发现,最好通过 ssh 通道进行转发:
# 把 Windows 的 18790 通过 SSH 隧道转发到远程 62.234.xx.xx 的 18789
ssh -N -L 18790:127.0.0.1:18789 root@62.234.xx.xx
# 执行node连接
$env:OPENCLAW_GATEWAY_TOKEN="xxx"; openclaw node run --host 127.0.0.1 --port 18790 --display-name "win-docker"
第一次连接过去会报错,因为还没配对:
node host gateway connect failed: pairing required
这时,在远程Linux主机的 device/pending.json 中会看到配对信息,批准后会移到 paird.json。
# 再次运行
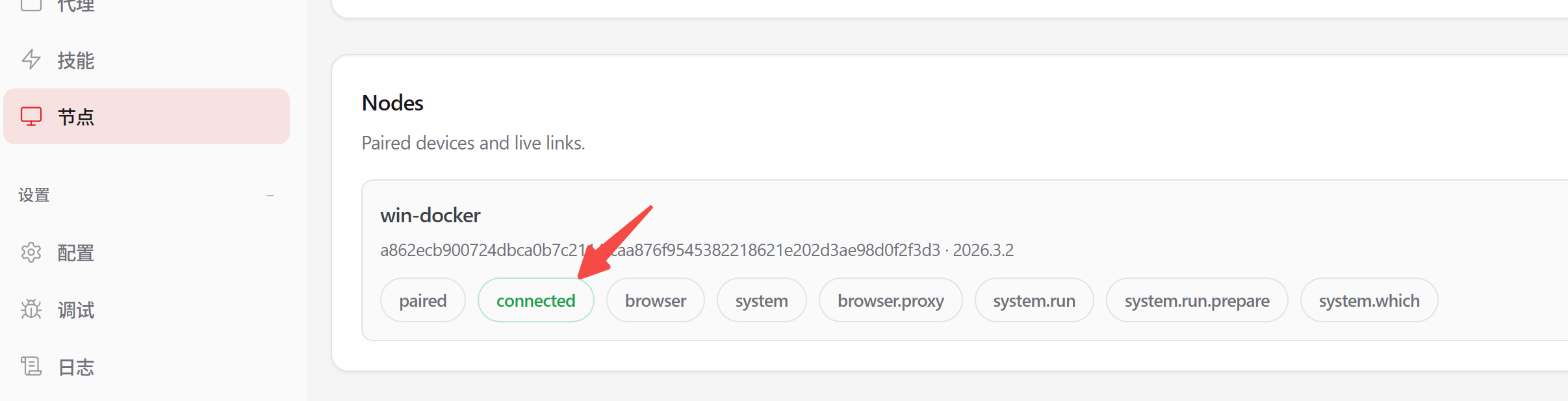
$env:OPENCLAW_GATEWAY_TOKEN="xxx"; openclaw node run --host 127.0.0.1 --port 18790 --display-name "win-docker"
控制台能看到连接成功信息:
最后,在 windows主机的~/.openclaw/exec-approvals.json中修改如下:
{
"version": 1,
"socket": {
"path": "C:\\Users\\admin\\.openclaw\\exec-approvals.sock",
"token": "xx"
},
"defaults": {
"security": "full",
"ask": "off",
"askFallback": "allow"
}
}
这样,远程Linux主机就可以执行任何操作,不需要手动允许了。
现在,让它访问 windows 的浏览器,测试一下能否访问gemini?
搞定:
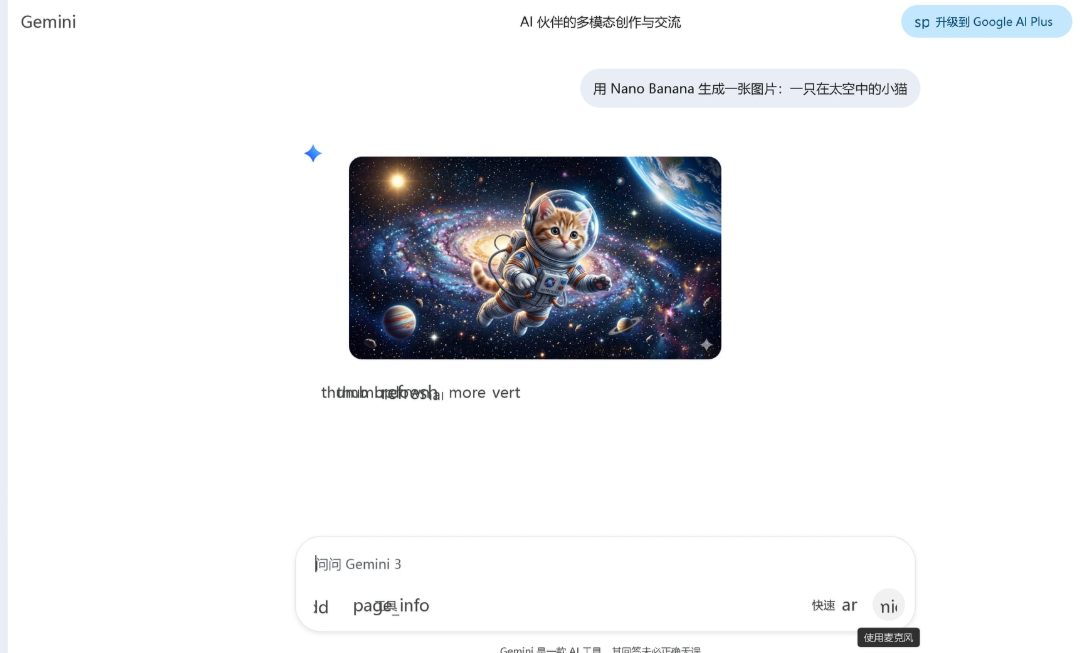
原理:
Linux主机通过browser工具和windows主机通信,底层做了这些事:
OpenClaw发指令给windows节点:
openclaw nodes invoke --node win-docker --command browser.proxy
- 节点收到指令后启动 Chrome:
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=18800 --user-data-dir="C:\Users\admin\.openclaw\browser\openclaw\user-data"
-
OpenClaw通过 Chrome DevTools Protocol (CDP) 远程控制浏览器 -
以
profile=openclaw访问gemini
只要我登录账号,数据就会持久化在:
~/.openclaw/browser/openclaw/user-data
写在最后
本文分享了永久免费 OpenClaw 部署的续集:踩坑记录和实战指南。
希望本文,能帮你建立对OpenClaw的全面认识。
动起来,开始和OpenClaw的第一次对话,和先进生产力工具,更近一步。
另:文中提到的所有脚本已打包,供需要的朋友参考,公众号后台回复
openclaw自取,免费。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)