
大模型智能体实战指南
可以分为短期记忆与长期记忆,同时Agentic RAG也可以认为是记忆模块的一种,claude的skills,Manus的文件也都是为了增强智能体的记忆能力。然后我们的agent会负责执行这个工具,并把工具结果作为context继续输入给大模型,如果需要多次调用工具则进行反复调用,最终大模型输出正式的结论。最近流行的大模型智能体,以大模型为大脑,通过调用工具来完成复杂的任务。强化学习中的智能体 通
·
> https://github.com/hongyingyue/LLM-agent-tutorials
强化学习中的智能体 通过与环境交互,学习新的策略从而获得奖励。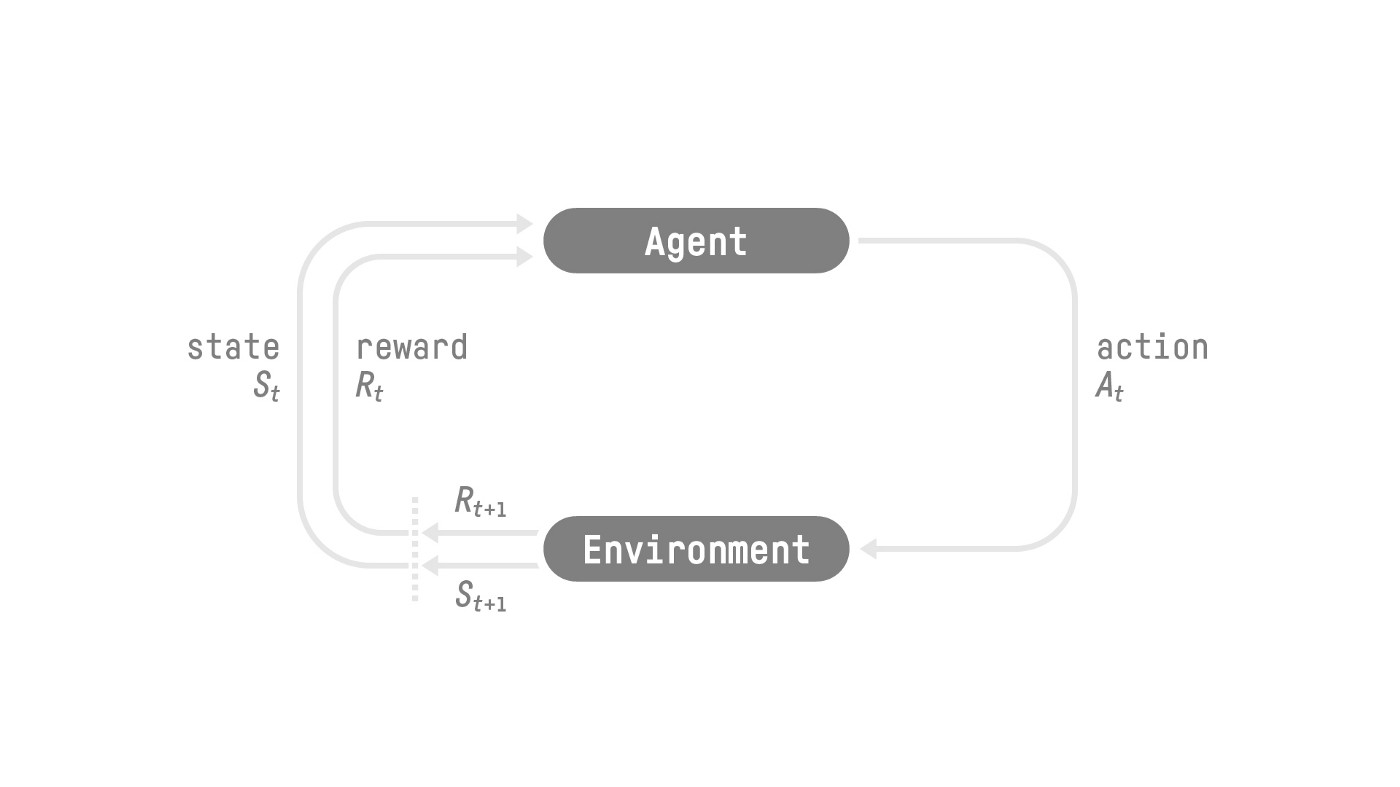
最近流行的大模型智能体,以大模型为大脑,通过调用工具来完成复杂的任务。
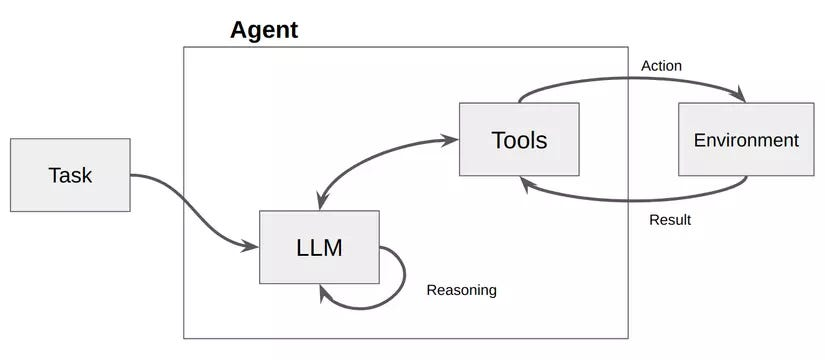
大模型工具调用
- https://github.com/hongyingyue/LLM-agent-tutorials/blob/main/1_llm_tool_call.ipynb
最简单的调用工具的例子
# Tool 1: DuckDuckGo Search
def duckduckgo_search(query, max_results=5):
results = []
with DDGS() as ddgs:
for r in ddgs.text(query, max_results=max_results):
results.append(f"{r['title']}: {r['href']}")
return "\n".join(results)
工具注册给大模型后,根据任务,大模型会返回的是工具调用
🔧 Tool requested: duckduckgo_search({'query': 'Beijing weather forecast tomorrow'})
然后我们的agent会负责执行这个工具,并把工具结果作为context继续输入给大模型,如果需要多次调用工具则进行反复调用,最终大模型输出正式的结论。
ReACT
- https://github.com/hongyingyue/LLM-agent-tutorials/blob/main/6_react.ipynb
观察 - 思考 - 行动的范式
行动后的结果进一步加入到context从而继续观察。在prompt中,要求大模型按照特定格式进行回应:
REACT_PROMPT = """
You are a smart physics assistant.
To solve a question, you must iterate through these steps:
1. Question: The input question you must answer
2. Thought: Comment on what you want to do next
3. Action: The function to call. Available tools: [get_planet_mass, calculate_gravity]
4. Action Input: The exact arguments to the function
5. Observation: The output of the tool (I will provide this)
... (Repeat steps 2-5 as needed) ...
6. Final Answer: The answer to the original question.
Rules:
- You MUST output 'Thought:', 'Action:', and 'Action Input:' in that order.
- Stop generating after 'Action Input'. I will give you the 'Observation'.
- When you have the answer, output 'Final Answer:'.
Current conversation:
{history}
"""
记忆
- https://github.com/hongyingyue/LLM-agent-tutorials/blob/main/7_memory.ipynb
- https://github.com/mem0ai/mem0
可以分为短期记忆与长期记忆,同时Agentic RAG也可以认为是记忆模块的一种,claude的skills,Manus的文件也都是为了增强智能体的记忆能力。
上下文工程
从 Prompt Engineering 到 Context Engineering,更有针对性的管理上下文,例如retreval的内容。
# 1. 动态组装上下文
context = ContextEngine()
context.add_system_instructions(project_patterns)
context.add_retrieved_docs(relevant_components)
context.add_conversation_history(recent_messages, max_tokens=4000)
context.add_user_profile(user_preferences)
context.add_available_tools(filtered_tools)
MCP协议
- https://github.com/hongyingyue/LLM-agent-tutorials/blob/main/8_mcp_agent.ipynb
Agentic-RL
- https://github.com/hongyingyue/LLM-agent-tutorials/blob/main/11_rl_finetune.ipynb
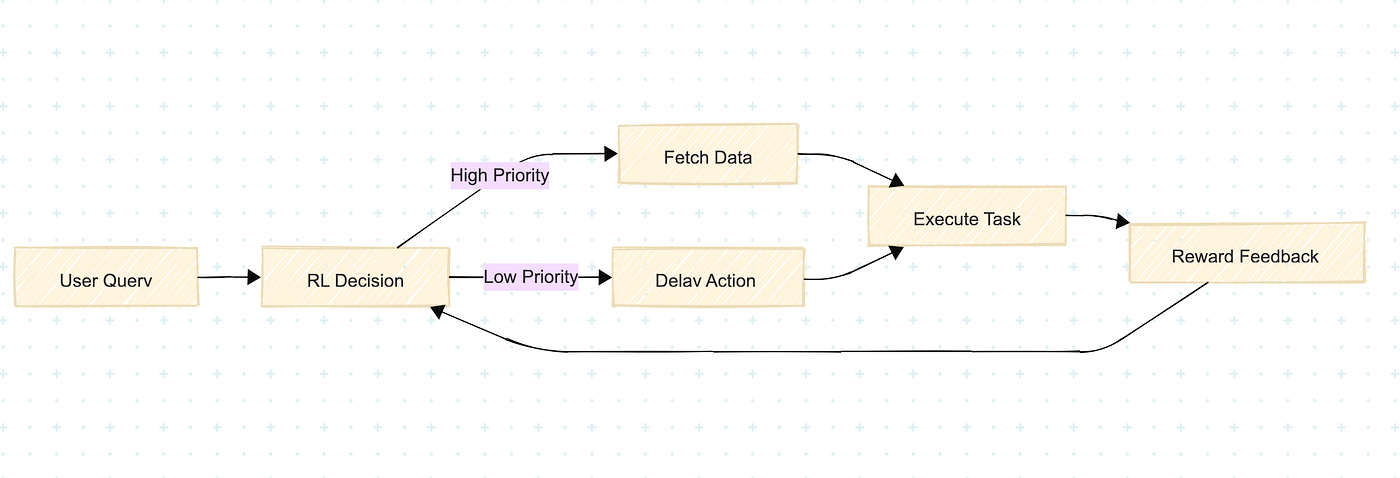
相比RLHF, Agentic RL关注的是多轮任务决策
评估

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)