【大模型】向量检索已过时?RAG技术正在发生哪些颠覆性创新?解读GraphRAG、Agentic RAG等前沿思路如何突破性能天花板
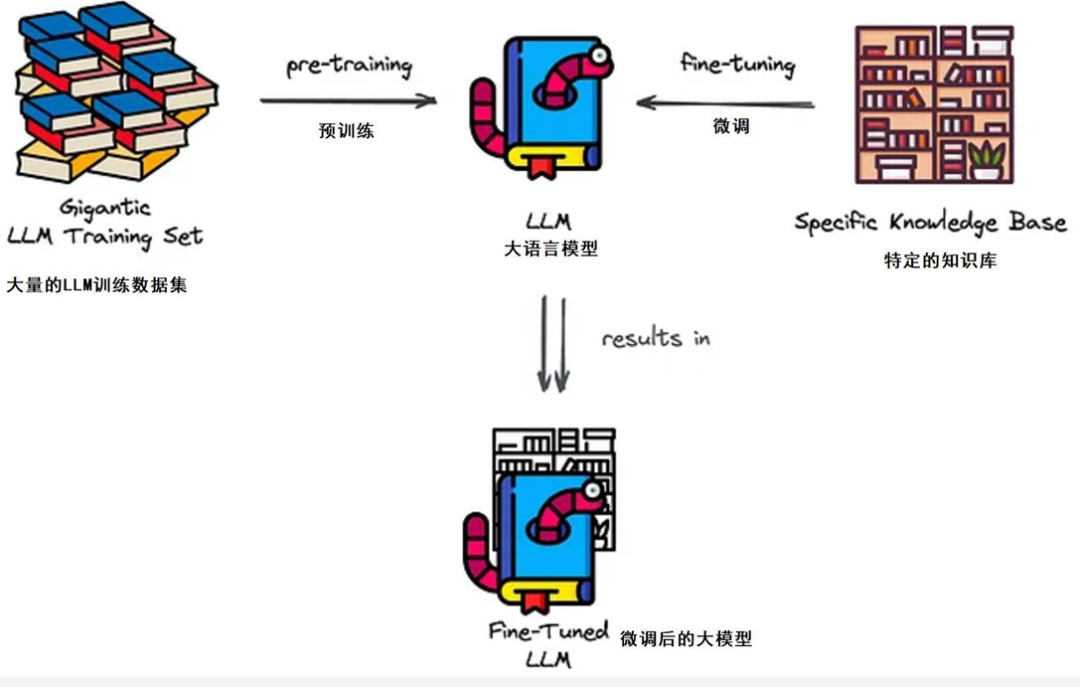
本文系统介绍了RAG(检索增强生成)技术及其应用。RAG通过结合外部知识检索和大语言模型生成,解决了传统LLM在知识更新、专业性和溯源能力上的不足。文章详细解析了RAG的三大组成(检索器、语言模型、知识库),对比了BM25和DPR等主流检索器类型,并提出了数据源优化、查询优化等检索优化策略。同时阐述了语义索引构建流程和多轮问答系统的工程实现,包括LangChain框架的应用、文档切分策略和向量数据
你的AI还在胡说八道?快上RAG救命车!从原理到实战,彻底解决大模型知识断层问题,企业级落地指南来了!
Part 1
引言:为什么需要RAG?
RAG(Retrieval-Augmented Generation)是当前大语言模型的重要增强方案,它在LLM基础上加入“外部知识检索”机制,从而提升生成结果的准确性与溯源能力。
微传统LLM的局限性
-
依赖微调,成本高;
-
对专有知识掌握差;
-
难以支持数据动态更新;
-
无法溯源回答来源。
知识的两种形式
-
参数化知识(Parametric Memory):存储在模型权重中,依赖训练;

-
非参数化知识(Non-parametric Memory):依赖外部检索,如知识库、文档数据库。


因此,结合检索能力的大模型,是实现高精度、低成本、强溯源智能系统的关键。
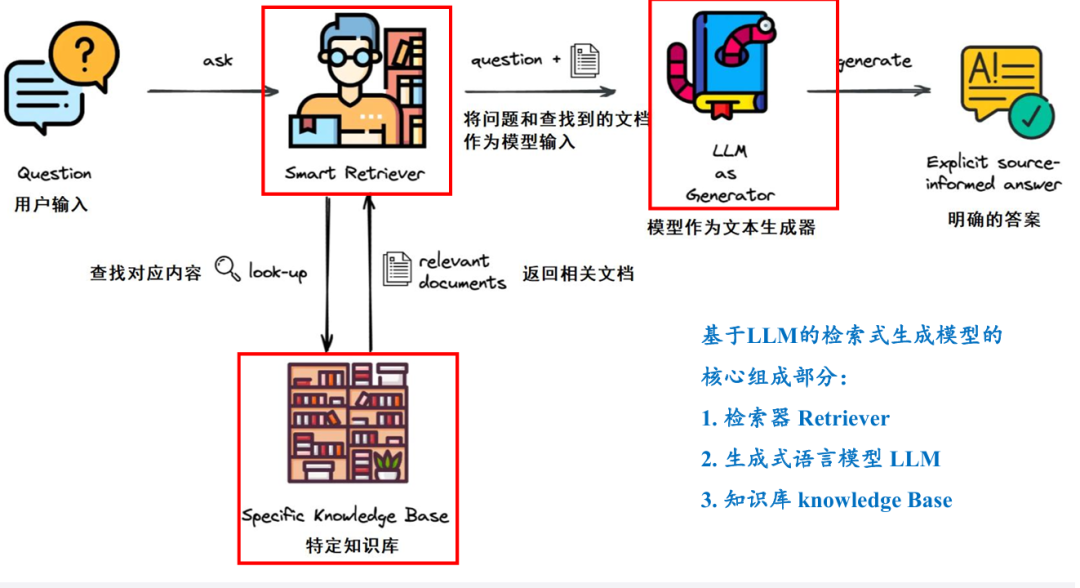
RAG模型的三大组成
-
Retriever(检索器)
-
LLM(语言模型)
-
Knowledge Base(知识库)
Part 2
检索构建与优化
Retriever的作用是从知识库中快速找到与问题最相关的信息,是RAG系统的基石。
检索增强生成(RAG)机制简介
-
将检索结果嵌入到大模型的输入提示中,引导其生成更精准的答案;
-
弥补LLM在知识覆盖、时效性和专业性上的缺陷。
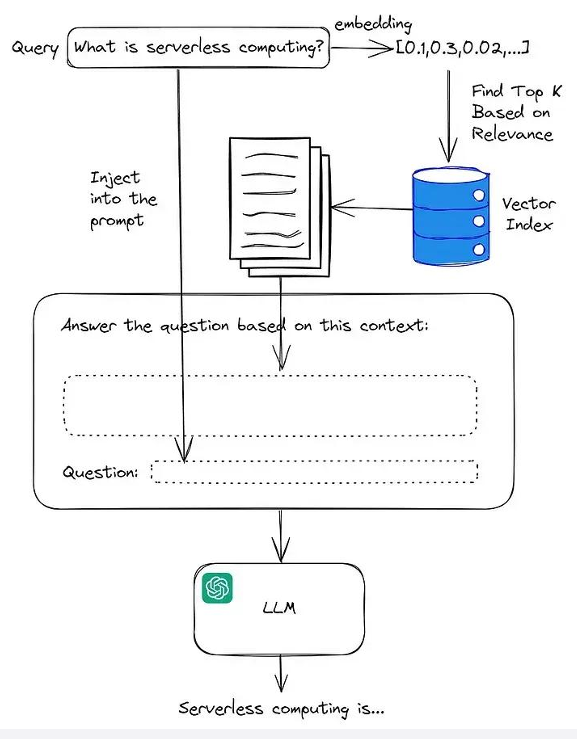
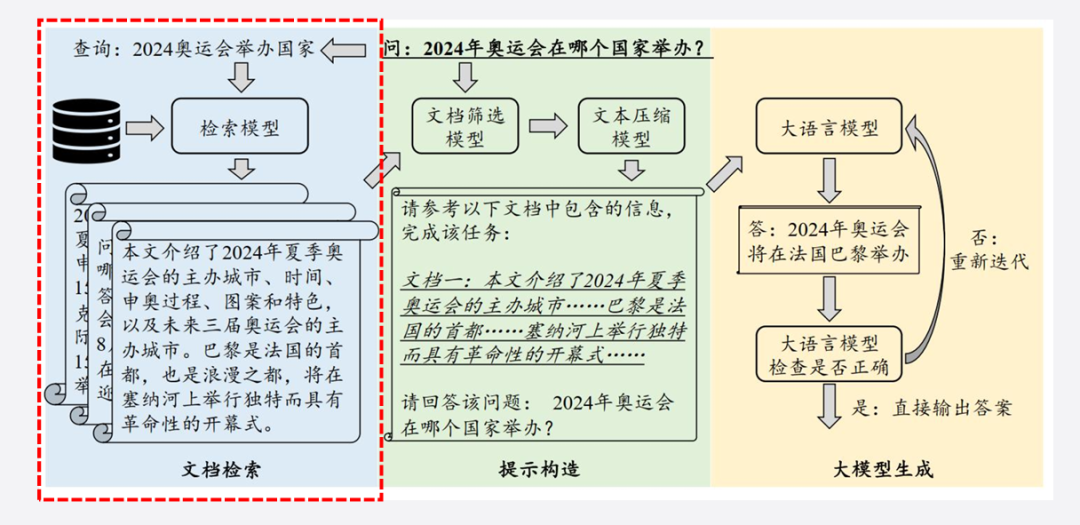
RAG三阶段流程
-
文档检索:根据用户问题查询知识库;
-
提示构造:将检索结果融入提示词;
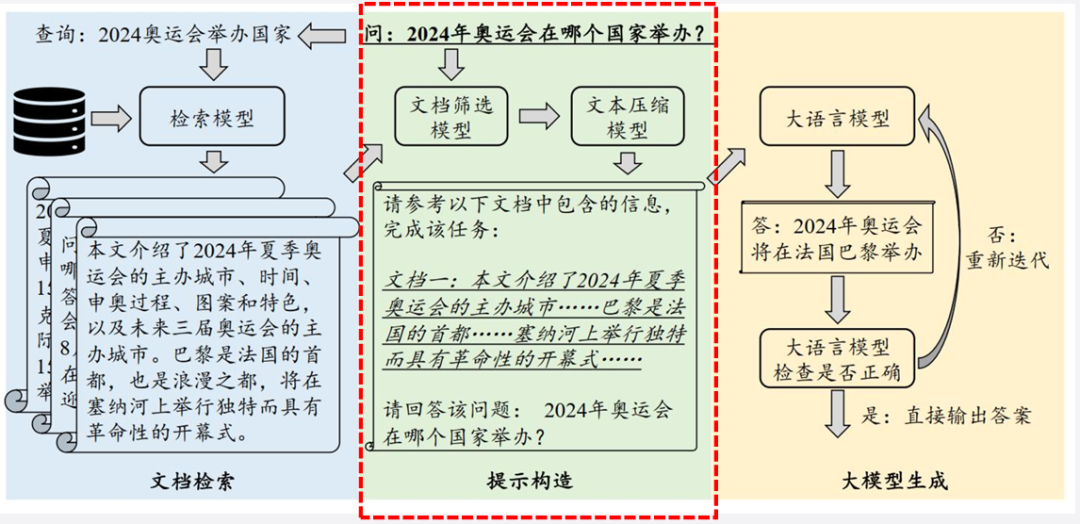
-
大模型生成:生成更贴合需求的答案。
主流检索器类型对比
(1)基于统计的BM25
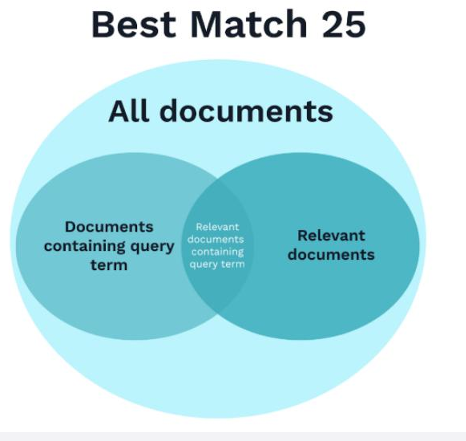
-
原理:基于词频和逆文档频率;
-
优点:无需训练,部署简单;
-
局限:不具备语义理解能力,对无关键词匹配的问题表现差。
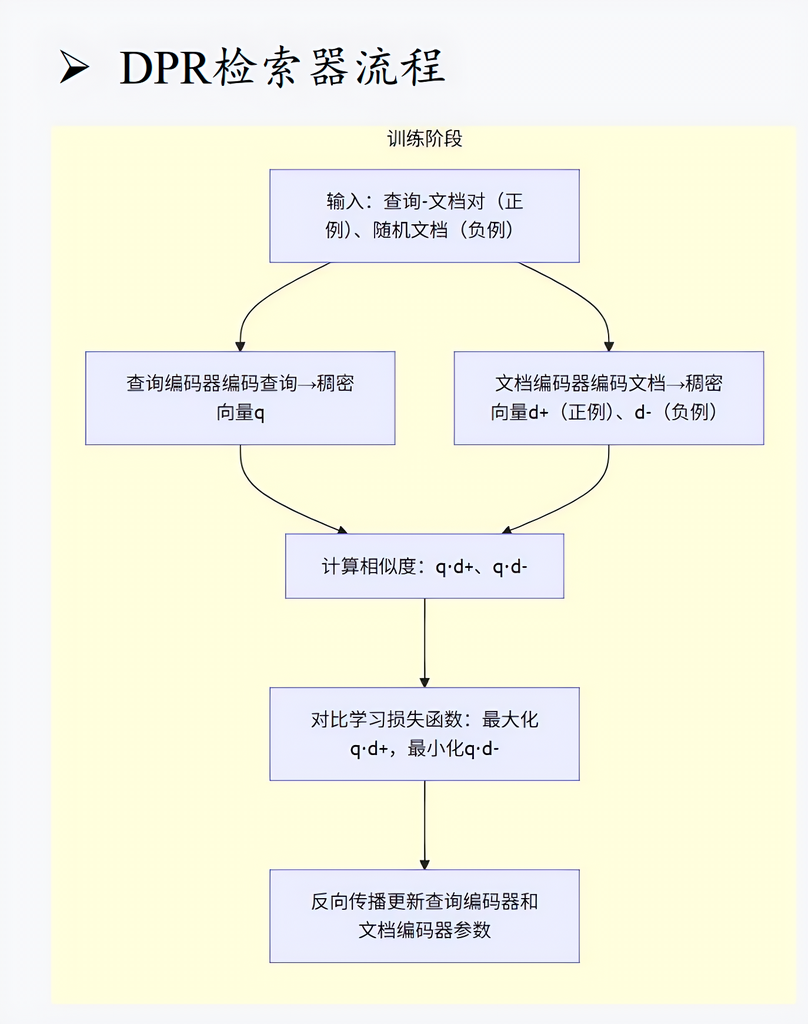
(2)基于深度学习的DPR
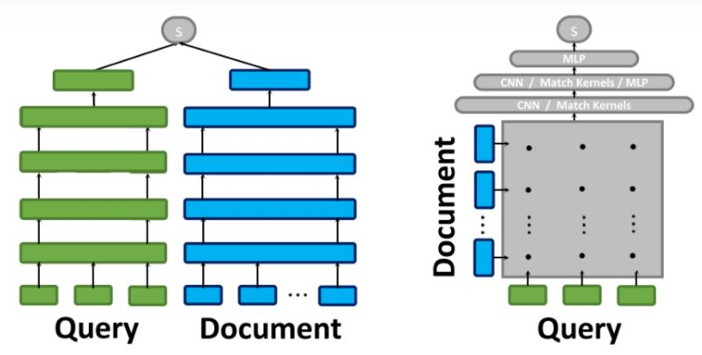
-
原理:将问题与文档分别编码为向量,进行语义匹配;
-
优点:支持语义搜索,可找出无关键词但语义相关的内容;
-
局限:需训练,资源开销大,对底层模型依赖较强。
BM25 适合结构清晰、关键词突出的数据场景;而 DPR 更适合开放领域问答等需要理解上下文的复杂任务。
检索优化策略
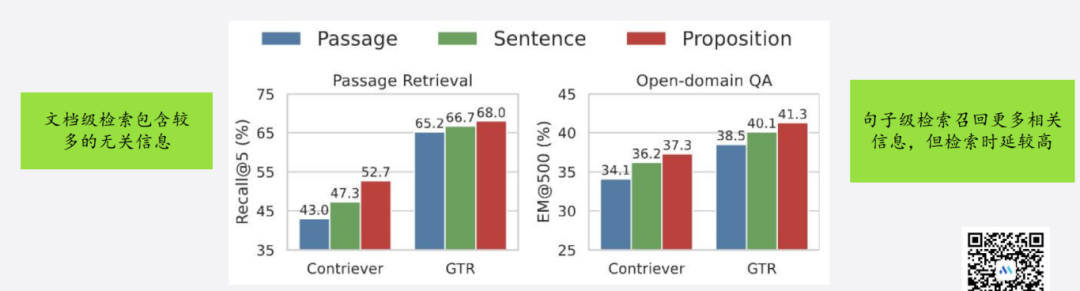
(1)数据源优化
-
优化粒度(文档级、段落级、句子级);
-
保留关键信息,去除无关内容。
(2)查询优化
-
查询扩展:补充关键词或将复杂问题拆解为子查询;
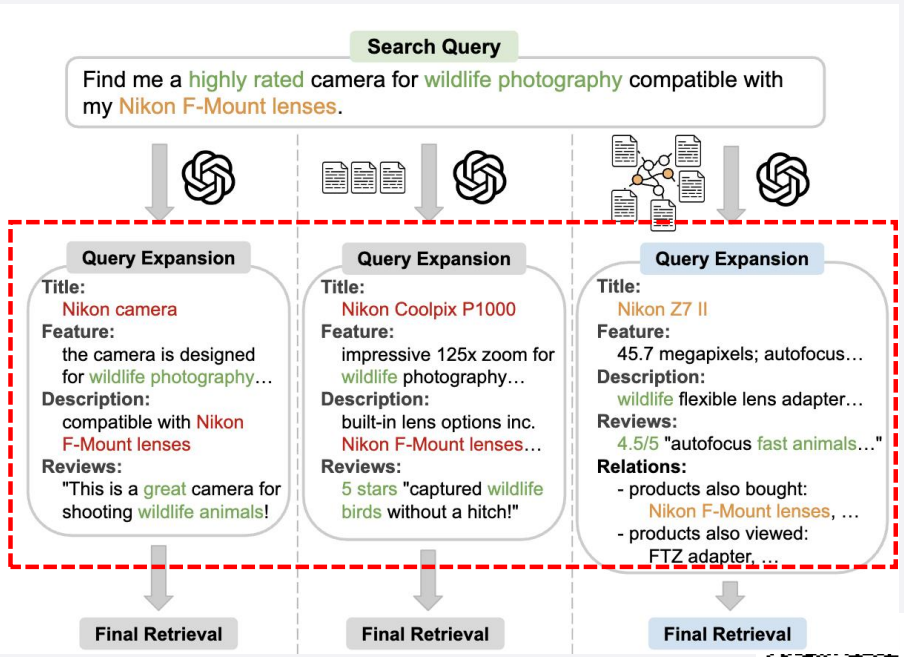
-
查询重写:优化原始查询语义,提升相关性;
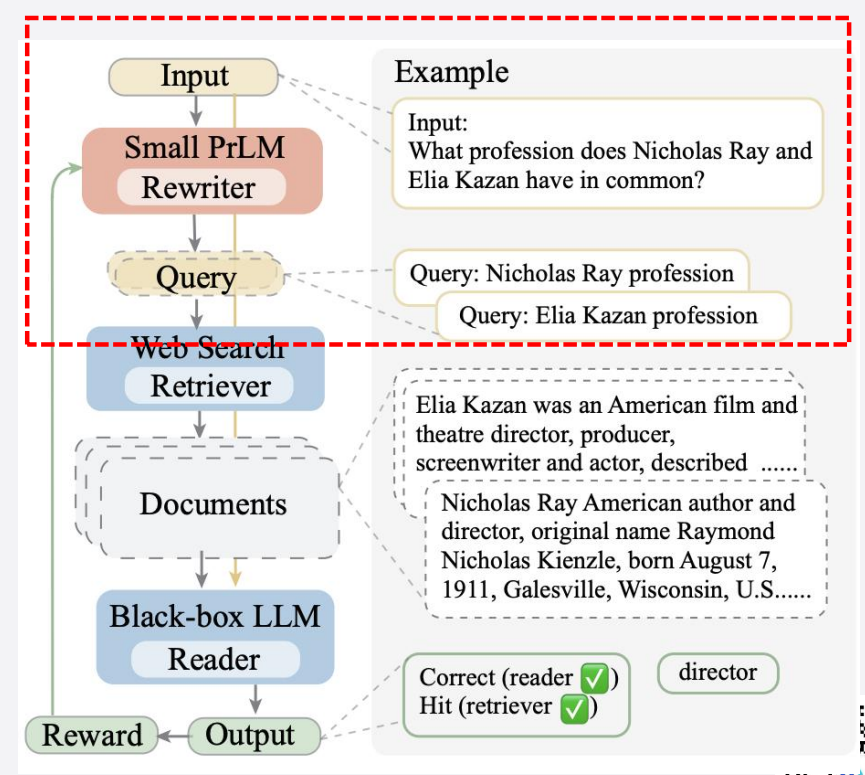
-
伪查询生成:以初步回答为伪查询迭代优化检索。
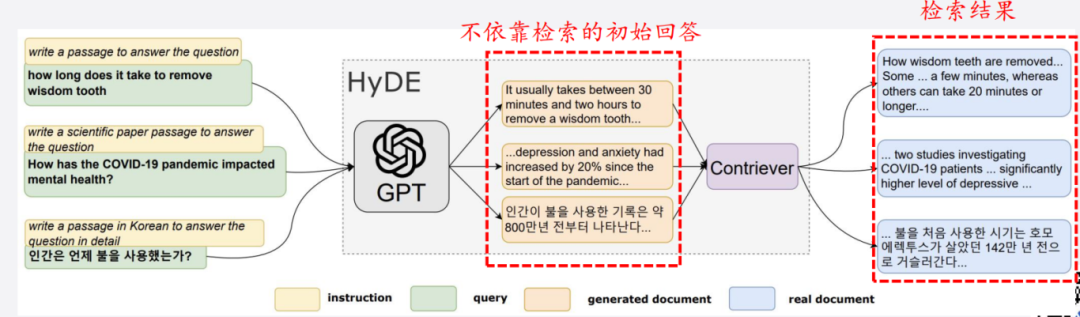
提示优化
-
文档重排序:提升高质量文档曝光;
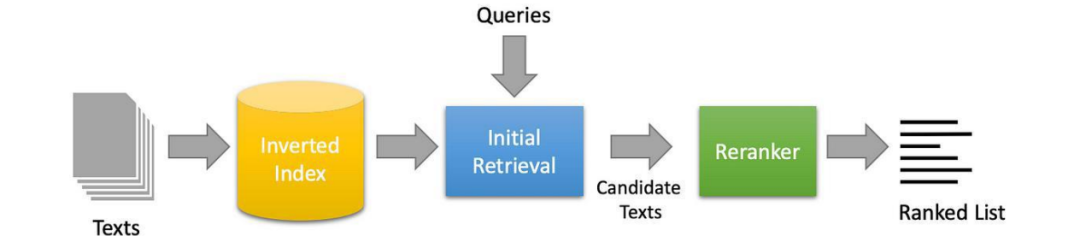
-
上下文压缩:控制Token数量,聚焦关键信息。
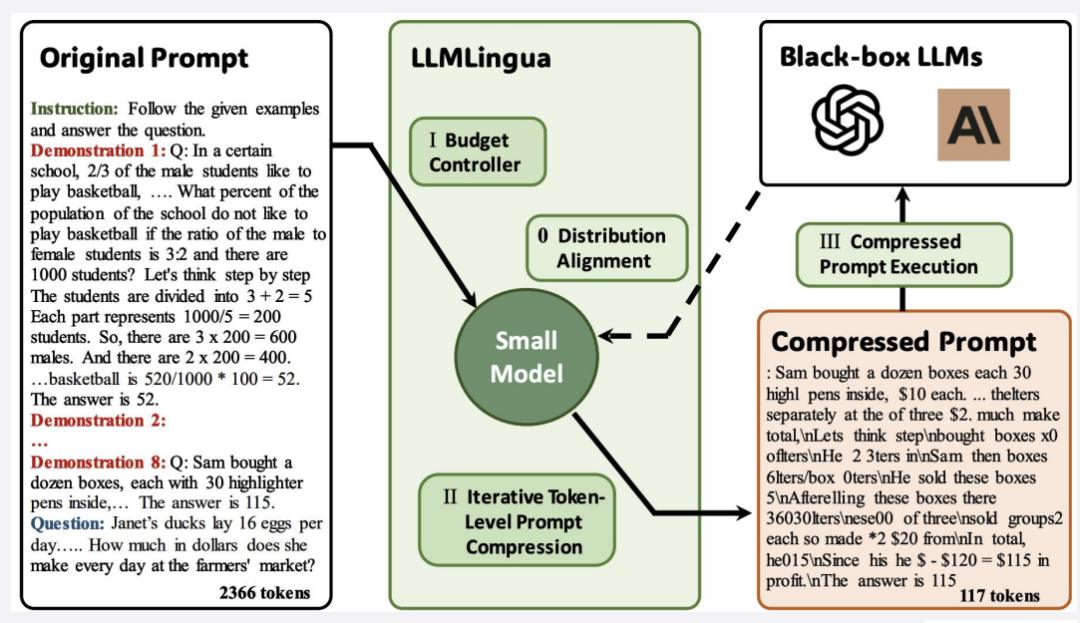
(4)流程优化
-
迭代检索:多轮合并优化检索结果;
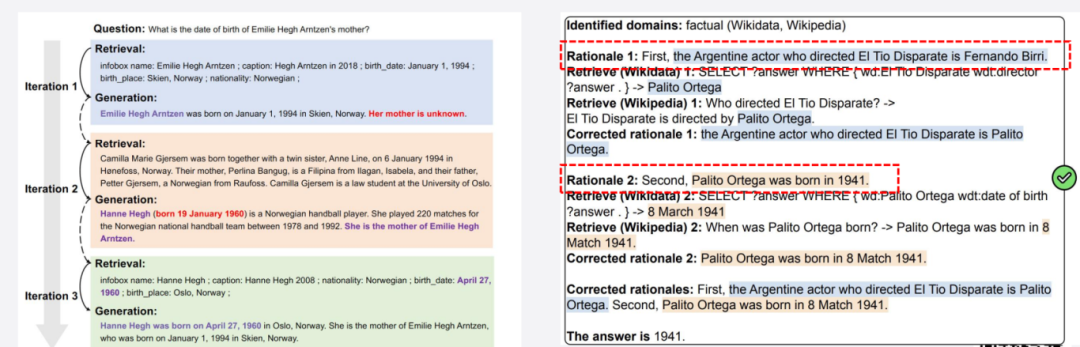
-
自适应检索:让大模型自动决定是否检索、检索什么。
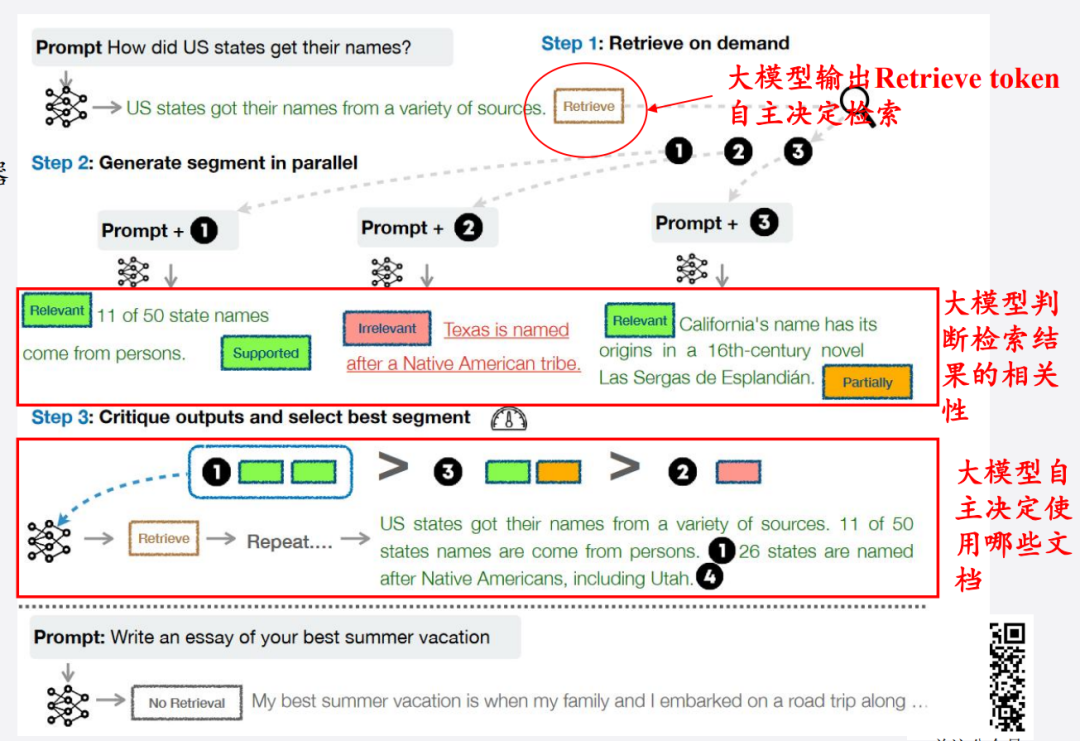
(5)模型优化
-
通过微调、指令训练等方式,让模型学会如何更好地使用检索结果生成回答。
Part 3
语义索引构建与召回机制
索引构建流程
(1)数据预处理
-
清洗、分词、去噪、去停用词;
-
将长文拆分为更小的片段,便于检索。
(2)向量化方法对比
-
TF-IDF:速度快,但语义弱;
-
Word2Vec:能学语义,但不适合整段文本;
-
BERT:支持上下文建模,语义强但计算成本高。
(3)索引结构选择
-
倒排索引:关键词搜索快;
-
向量量化:节省存储空间,牺牲一定精度;
-
ANN(如 FAISS、HNSW):平衡速度和准确率的主流方案。
(4)索引优化
-
参数调优(如索引树深度);
-
支持增量更新;
-
实验评估检索准确性、响应时间等指标。
检索召回流程
-
用户输入处理(标准化 + 向量化);
-
使用索引进行精确或近似相似度匹配;
-
对候选文档排序、筛选;
-
提取与问题相关的上下文,作为生成输入。
Part 4
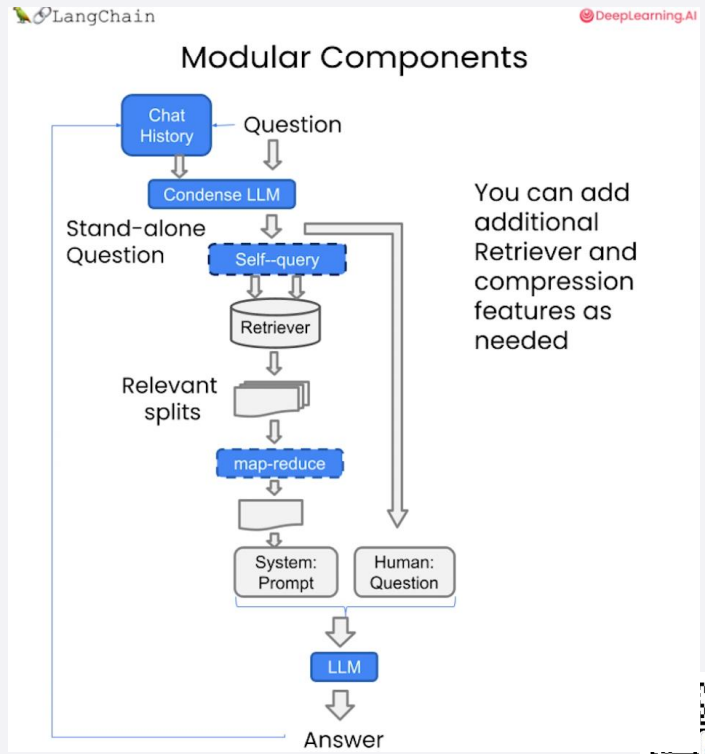
多轮RAG问答系统工程化搭建
以 LangChain 框架为例,介绍如何将 RAG 系统落地为一个可运行的多轮问答产品。
Langchain框架简介
包含以下模块:
-
Prompts:提示词构建;
-
Models:语言模型;
-
Indexes:向量索引管理;
-
Chains:链式任务逻辑;
-
Agents:智能决策引擎。
数据接入方式
-
PDF 文档:用 pypdf 加载;
-
网页/Notion:使用对应 Loader;
-
YouTube 音频:结合 yt_dlp 与 pydub 提取文本。

文档切分策略
为了控制Token数量并保留上下文信息,采用如下分割方法:
-
基于字符(按字符长度、标点分割);
短句分割
#导入文本分割器from langchain.text_splitter importRecursiveCharacterTextSplitter, CharacterTextSplitter
chunk_size=20#设置块大小
chunk overlap=10#设置块重叠大小
#初始化递归字符文本分割器
r_splitter= RecursiveCharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlap)
#初始化字符文本分割器
c_splitter = CharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlapseparator=.'')
text="在AI的研究中,由于大模型规模非常大,模型参数很多,在大模型上跑完来验证参数好不好训练时间成本很高,所以一般会在小模型上做消融实验来验证哪些改进是有效的再去大模型上做实验。"#测试文本
r_splitter.split_text(text)
长文本分割
# 中文版
some_text="""在编写文档时,作者将使用文档结构对内容进行分组。\
这可以向读者传达哪些想法是相关的。例如,密切相关的想法\
段落构成是在句子中。类似的想法在段落中。文档。 \n\n
段落通常用一个或两个回车符分隔。回车符是您在该字符串中看到的嵌入的“反斜杠
句子末尾有一个句号,但也有一个空格。\并且单词之间用空格分隔"""
c_splitter=CharacterTextSplitter(chunk_size=80,chunk overlap=0,separator='')
"对于递归字符分割器,依次传入分隔符列表,分别是双换行符、单换行符、空格、空字符,因此在分割文本时,首先会采用双分换行符进行分割,同时依次使用其他分隔符进行分割"
r_splitter = RecursiveCharacterTextSplitter(chunk_size-80,chunk_overlap-0,separators=["\n\n", "\n"," ",""])
c_splitter.split_text(some_text)
```
-
基于Token(对齐LLM上下文窗口);
# 使用token分割器进行分割,
#将块大小设为1,块重叠大小设为0,相当于将任意字符串分割成了单个Token组成的列
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1,chunk_overlap=0)
text = "foo bar bazzyfoo"text_splitter.split_text(text)# 注:目前 LangChain 基于 Token 的分割器还不支持中文
-
基于结构(如Markdown标题)进行语义切块。
#定义一个Markdown文档
from langchain.document_loaders importNotionDirectoryLoader#Notion加载器
from langchain.text_splitter importMarkdownHeaderTextSplitter#markdown分割器
markdown_document=""# Titlelnin \## 第一章\n\n \
李白乘舟将欲行\n\n 忽然岸上踏歌声\n\n \
#### Section \n\n
桃花潭水深千尺 \n\n
##第二章\n\n \
不及汪伦送我情"""
# 定义想要分割的标题列表和名称
headers_to_split_on =[("#","Header 1"),("##","Header 2")("###","Header 3”)]
markdown_splitter =MarkdownHeaderTextSplitter(
headers_to_split on=headers_to_split_on)#message typemessage type
md_header_splits =markdown_splitter.split_text(markdown_document)
print("第一个块")print(md header splits[0])print("第二个块")
print(md header splits[1])
构建向量数据库
-
推荐使用轻量级Chroma;
-
将分块内容转为向量存入向量库;
-
可直接调用 .similarity_search() 完成高效召回。
检索式问答构建
提供不同构建方式:
-
普通QA链;
-
模板提示QA链;
-
MapReduce链(分批并行生成);
-
Refine链(迭代优化生成结果)。
多轮对话支持
-
使用 Memory 模块记录对话历史;
-
构建 ConversationalRetrievalChain 进行多轮问答。
结语:RAG的未来与应用前景
RAG已成为大模型落地过程中不可或缺的一环。它不仅弥补了大模型在知识更新、可靠性、成本上的不足,更能通过工程化手段快速部署于多种应用场景,包括智能问答、智能客服、金融分析、医疗辅助等。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)