RAG拓展、变体、增强版(二)
Infinite Retrieval、IterDRAG、KG-RAG、LightRAG:架构、部署;MiniRAG、PIKE-RAG、RAG-Anything、Speculative RAG。
接上篇RAG拓展、变体、增强版(一)。
注:本文整理自ChatGPT和网络资料。
txtai
官网,开源(GitHub,11.6K Star,739 Fork),一个多功能的AI数据平台,超越传统的RAG框架。为构建语义搜索、语言模型工作流和文档处理管道提供一套全面的工具:
- 嵌入式数据库,用于高效的相似性搜索
- 用于集成语言模型和其他人工智能服务的 API
- 用于自定义工作流的可扩展架构
- 支持多种语言和数据类型
Infinite Retrieval
北师大论文,提出Infinite Retrieval,无需额外训练,即可赋能现有模型理论上就可以处理无限长度的文本。
InfiniRetri的核心在于一个关键发现:LLMs在执行推理任务时展现出的注意力分配模式,与信息检索的过程存在内在的一致性,因此也叫注意力即检索。就像人类在阅读长篇书籍时,大脑会对关键信息给予更高的关注。在LLMs的深层网络中,注意力机制能够更精准地聚焦于与当前任务相关的上下文片段。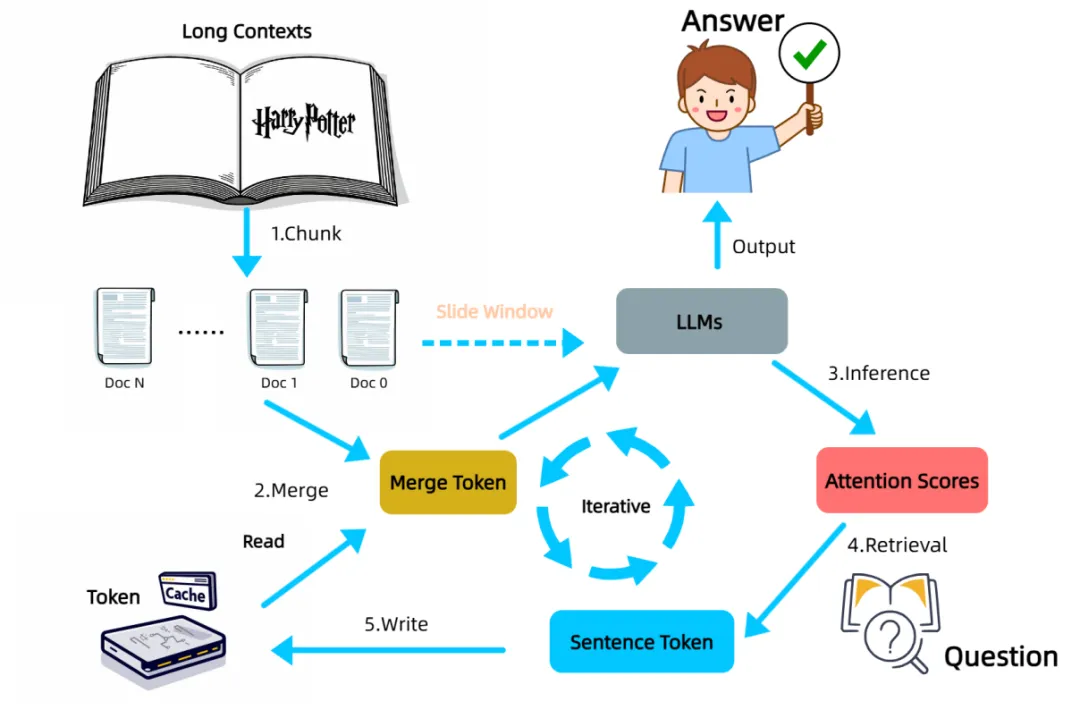
基于这一洞察,采用一种无需额外训练的迭代式处理流程。面对超长文本,它将其划分为若干连续的片段,并逐一输入LLM进行处理。关键的创新在于,InfiniRetri在处理每个文本片段后,会利用LLM最后一层的注意力分布信息,识别并保留那些被模型认为最相关的句子。这些被“重点关注”的句子被存储在一个外部缓存中,如同大脑在阅读过程中记住的关键情节。
在处理后续的文本片段时,InfiniRetri会将缓存中保留的相关句子与当前片段进行合并,共同作为LLM的输入。使得LLM在处理局部文本时,能够“回忆”起先前被认为重要的上下文信息,从而在整体上理解和处理更长的文本。与直接缓存模型内部状态不同,InfiniRetri仅缓存关键的句子文本,这更类似于人类记忆语义信息而非底层的神经元激活。
在模拟大海捞针式信息检索的NIH任务中,该方法使一个轻量级的模型(Qwen2.5-0.5B)在100万tokens的超长文本中实现100%的检索准确率,显著超越了现有技术。在更贴近实际应用的LongBench基准测试中,InfiniRetri同样在多个主流LLMs上取得了显著的性能提升,尤其在多文档问答等需要整合多来源信息的任务中表现突出,Qwen2-7B-Instruct在HotpotQA上的提升高达288%。通过选择性地缓存和处理关键信息,有效降低推理延迟和计算资源消耗。
IterDRAG
论文,
推理缩放策略
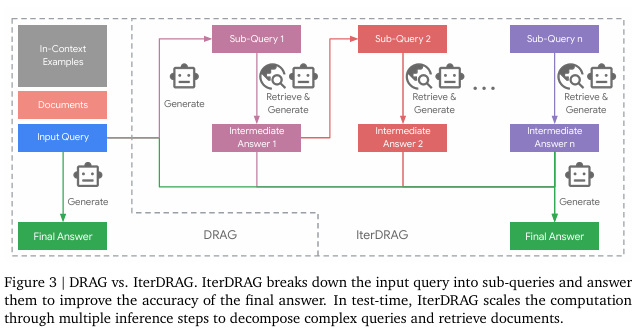
- 基于演示的RAG(DRAG):利用上下文学习,将大量文档和上下文示例集成到输入提示中,使模型能在单次推理请求内生成答案。从大型语料库(如Wikipedia)检索文档构建丰富输入上下文,让模型学会提取信息和回答问题,突破传统RAG局限。
- 迭代式基于演示的RAG(IterDRAG):针对复杂多跳查询,将其分解为简单子查询,通过迭代检索和生成中间答案,最后合成最终答案。利用受限解码生成包含子查询和中间答案的上下文示例,在推理过程中不断扩展计算,有效缩小组合性差距,提升知识提取和整体RAG性能。
RAG性能与推理计算规模关系
- 固定预算下最优性能:给定推理计算预算(最大有效上下文长度
L_max),通过调整DRAG中的检索文档数、上下文示例数和IterDRAG中的迭代次数等参数,寻找最优性能配置。在多跳知识问答数据集上实验,采样不同预算,对比零样本QA、多样本QA、传统RAG等基线方法,评估精确匹配(EM)、F1分数和准确率等指标,发现DRAG和IterDRAG性能随预算增加而提升,且在不同长度下各有优势。 - 总体性能趋势:DRAG和IterDRAG性能增长优于基线方法,RAG在128k后性能停滞,DRAG可达1M tokens,IterDRAG在5M tokens预算下表现更优,表明增加有效上下文长度对RAG有益,二者在不同规模下发挥关键作用。
- 推理缩放定律:绘制性能与有效上下文长度关系图,发现最优性能与推理计算量级呈近线性增长,定义为RAG的推理缩放定律。但在1M tokens后性能增益逐渐减小,可能受长上下文建模限制,总体在合理范围内线性提升。
- 参数特定缩放分析:网格搜索参数组合发现,增加检索文档和演示通常提升性能,但二者贡献不同。如固定配置下增加文档收益更大,而增加示例对IterDRAG更有帮助;不同方法参数饱和点不同,且最优参数受方法、指标和数据集影响,确定超参数组合仍具挑战。
长上下文RAG的推理计算分配模型
- 模型构建与估计:将平均性能指标 P 定义为参数 θ(文档数 k k k、演示数 m m m、最大迭代次数 n n n)的函数,引入 i i i衡量文档和示例信息量,构建计算分配模型。通过特定任务性能差异计算 i i i,对模型参数 a , b , c a,b,c a,b,c进行估计,实验表明该模型能反映LLM性能变化,且一次估计可应用于不同任务。
- 模型验证与分析:对比预测指标和实际值验证模型,DRAG在不同数据集上预测与实际趋势高度一致,Bamboogle一致性最高。消融研究表明纳入 b b b和 i i i可增强相关性和降低误差,逆 s i g m o i d sigmoid sigmoid缩放 P P P显著提升估计效果;在域泛化和长度外推实验中,模型表现出色,在1M tokens以下目标长度外推准确有效,为长上下文RAG计算分配提供有力指导。
讨论与分析
- 检索质量影响:检索文档质量对RAG性能关键,增加文档可提高召回率,但NDCG等指标显示相关性和排名质量未必提升,甚至引入噪声。IterDRAG的迭代检索通过分解查询提高召回和排名性能,凸显动态调整检索方法减少无关内容的重要性。
- 错误原因剖析:对错误分析发现主要有检索不准确或过时、推理错误或缺失、幻觉或不可靠推理、评估问题或拒绝回答四类。IterDRAG可改善前两类问题,表明检索与迭代生成结合对多跳查询重要,同时需增强模型可靠性和改进评估方法。
- 长上下文建模局限:检索更多文档虽有益,但简单延长上下文长度未必提升结果。DRAG和IterDRAG分别在特定长度达到最优,表明模型识别长上下文相关信息能力和上下文学习能力有待提高,需优化长上下文建模。
KG-RAG
论文首次提出基于知识图谱(KG)的RAG,后来出现好多篇此类主题的论文。提出背景:
- 传统RAG挑战:传统RAG在将多样化信息相互关联方面存在局限;
- KG作用:KG通过仅表示实体和关系,提供数据如何关联的洞察;
- 增强的连通性:结合KG有助于RAG系统更有逻辑地连接信息片段,提高输出一致性;
- 更深的语义理解:利用KG的关系结构,RAG能够更好地理解数据中的上下文和表达;
- 性能提升:RAG与KG结合增强系统处理复杂查询的能力,提供更准确和有深度的响应。
优势:
- 增强的连通性:KG在不同信息片段之间建立联系,提供更有意义和逻辑的答案,使模型能够发现可能被忽略的关系;
- 改进的语义理解:结构化的数据表示提供了对整体的理解,使模型能够全面理解数据集中的高阶关系;
- 提高准确性:通过从更广泛的上下文中获取信息,LLM能够生成更准确、更符合上下文的结果,提供更符合用户意图的响应;
- 可扩展性:通过添加新数据,KG可扩展、持续增强RAG的能力,以应对不同领域的新挑战。
将KG整合到RAG中涉及以下关键步骤:
- 索引:将用户提供的文档分割成易于分析的独立文本单元(TextUnits);
- 图谱提取:从这些文本单元中生成实体、关系和断言,以建立基本的图结构;
- 图谱增强:向图中添加更多信息,丰富数据表示,包括社区检测的应用;
- 摘要:为每个社区提供特定的摘要报告,包含相关发现;
- 网络可视化:展示关系和实体,使其更易于解读。
论文架构图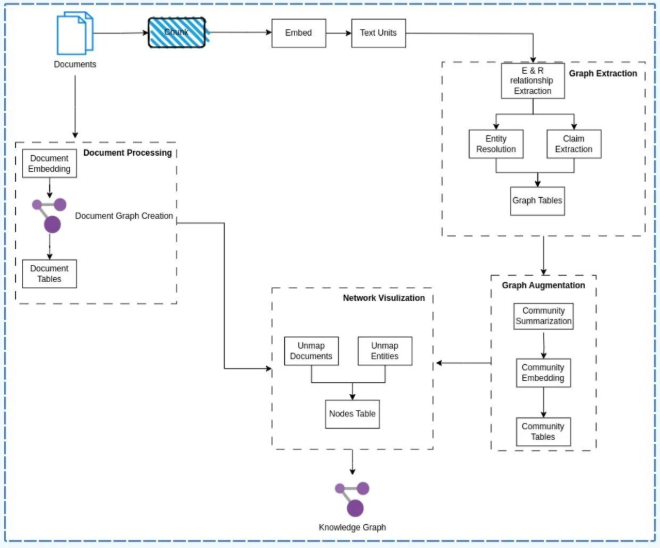
阶段1:构建文本单元
- 目标:将输入文档拆分为较小的文本单元,便于后续的图谱提取。
- 过程:将文档分割成通常包含300个标记的文本单元,但可根据需要配置至1200个标记以实现最佳效果。
- 配置:用户可设置这些片段的大小以及文本单元的分割方式。
阶段2:图谱提取
- 目标:分析文本单元,提取基本的图结构,包括实体、关系和断言。
- 过程:联合检测实体和关系,然后一次性提取断言。最终,数据生成的子图根据特征的一致性进行合并,以减少重复性。
阶段3:图谱增强
- 目标:通过添加信息,揭示社区结构,增强整体理解。
- 技术:采用分层Leiden算法进行社区检测,并使用Node2Vec进行图嵌入,生成综合的图表。
阶段4:社区摘要
- 目标:为图中发现的每个社区撰写摘要,以提供不同抽象层次的见解。
- 过程:利用嵌入扩展从关键数据中得出的摘要,创建数据集中社区的报告。
阶段5:文档处理
- 目标:在知识模型框架内建议和改进详细信息表。
- 过程:将文档连接到文本单元,并实例化关系和相关性,为后续阶段提供网络组织的对数线性方法。
阶段6:网络可视化
- 目标:采用高维向量空间的实体-关系和文档图框架生成网络表示。
- 技术:应用UMAP降维,将图转换为二维,以直观地表示图并理解对象之间的关系。
LightRAG
港大实验室开源,参考HKUDS介绍。
MiniRAG
同样也是港大实验室开源,参考HKUDS介绍。
PIKE-RAG
微软亚洲研究院论文,开源,sPecalized KnowledgE and Rationale Augmented Generation,专注于提取、理解和应用领域特定知识,同时构建连贯的推理逻辑,以逐步引导LLM获得准确响应。主打在复杂企业场景中私域知识提取、推理和应用能力,已在工业制造、采矿、制药等领域进行测试,显著提升问答准确率。
基本模块:文档解析、知识抽取、知识存储、知识检索、知识组织、以知识为中心的推理以及任务分解与协调。通过调整主模块内的子模块,可以实现侧重不同能力的RAG系统,以满足现实场景的多样化需求。
例如,在患者历史病历搜索中,侧重于事实信息检索能力;主要挑战在于:
- 知识的理解和提取常常受到不恰当的知识切分的阻碍,破坏语义连贯性,导致检索过程复杂而低效;
- 常用的基于嵌入的知识检索受到嵌入模型对齐专业术语和别名的能力的限制,降低了系统准确率。
利用PIKE-RAG,可以在知识提取过程中使用上下文感知切分技术、自动术语标签对齐技术和多粒度知识提取方法来提高知识提取和检索的准确率,从而增强事实信息检索能力,流程:
对于像为患者制定合理的治疗方案和应对措施建议这样的复杂任务,需要更高级的能力:
- 需要强大的领域特定知识才能准确理解任务并有时合理地分解任务;
- 还需要高级数据检索、处理和组织技术来预测潜在趋势;
而多智能体规划也将有助于兼顾创造力和可靠性。在这种情况下,可以初始化下面更丰富的管道来实现这一点。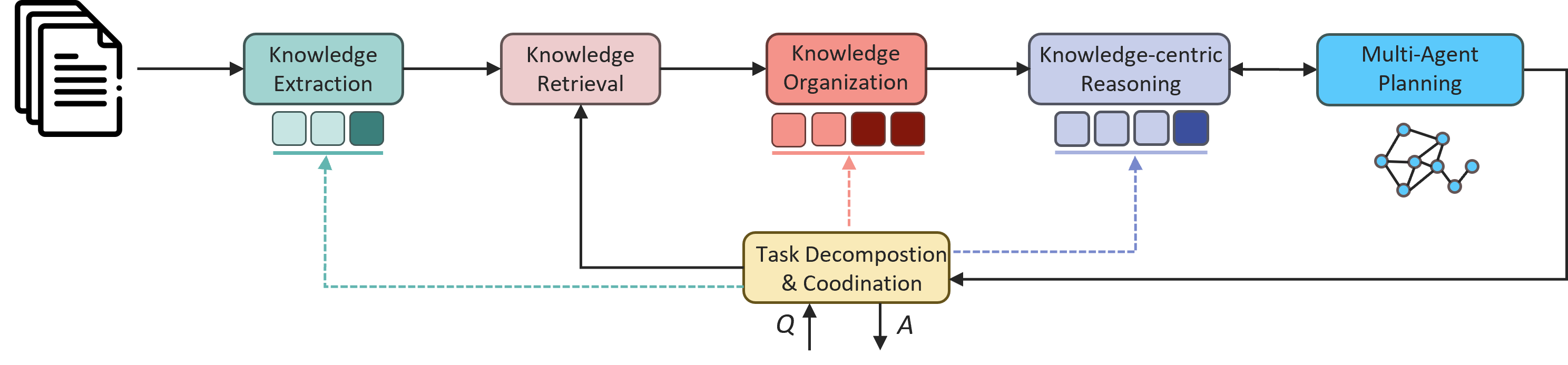
与Zero-Shot CoT、Naive RAG、Self-Ask、GraphRAG Local、GraphRAG Global相比,PIKE-RAG在准确率、F1分数等指标上均表现出色,PIKE-RAG在处理复杂推理任务方面具有显著优势,特别是在需要整合多源信息、进行多步骤推理的场景中。
首次提出5级RAG系统能力与挑战,针对不同系统层级的技术挑战,PIKE-RAG框架都有针对性策略。
其中:PA代表文件解析,KE代表知识抽取,RT代表知识检索,KO代表知识组织,KR代表以知识为中心的推理。
RAG-Anything
香港大学数据智能实验室开源,通过多模态KG+混合检索机制,实现从文档摄取到智能查询的端到端解决方案。相比传统RAG仅支持文本的局限,可同时解析文本、表格、图表、公式,复杂文档处理效率提升高达300%!
核心目标是解决传统RAG在复杂文档处理中的三大瓶颈:
- 单一模态限制:传统RAG仅支持文本;
- 上下文感知不足:检索结果与用户查询的关联性弱,答案精度低;
- 检索机制僵化:依赖单一检索策略(如关键词匹配),难以适应多样化的查询需求。
三大创新技术:
- 多模态KG:将文档中的文本、表格、图表等元素转化为关联KG,构建全局语义网络;
- 灵活的解析架构:支持多种格式,自动识别并提取结构化与非结构化数据;
- 混合检索机制:结合稀疏检索(关键词)、稠密检索(向量相似度)和多模态检索(视觉+文本),动态适配查询类型。
核心优势:
- 多模态解析能力:从读文字到懂图表
- 支持文本、表格、公式、流程图的联合解析,例如从财报中同时提取关键数据和图表趋势;
- 对比传统RAG工具(如ChatPDF),可处理更复杂的文档类型(如学术论文中的实验图表)。
- 上下文感知的高精度检索
- 通过多模态KG构建文档全局语义网络,检索时不仅匹配关键词,还能理解查询意图;
- 例如,用户提问“图中所示的算法在表格第3行的数据表现如何?”,系统可关联图表与表格数据生成答案。
- 混合检索机制:动态适配查询需求
- 稀疏检索:适用于关键词明确的查询;
- 稠密检索:适用于语义模糊的查询;
- 多模态检索:适用于图文混合查询。
- 开源免费与易部署
- 完全开源,支持Docker一键部署,兼容主流云服务器和本地环境;
- 提供详细的API文档和示例代码,开发者可快速集成到现有系统中。
主流RAG平台对比
| 平台/工具 | 核心能力 | 模态支持 | 检索机制 | 复杂文档处理 | 开源/闭源 |
|---|---|---|---|---|---|
| RAG-Anything | 多模态KG+混合检索 | 文本/表格/图表 | 稀疏+稠密+多模态 | ★★★★ | 开源 |
| ChatPDF | 文本解析与问答 | 仅文本 | 关键词匹配 | ★★☆ | 闭源 |
| LLM Chain | 多文档摘要与推理 | 文本为主 | 稠密检索 | ★★★☆ | 开源 |
| Open-RAG | 动态检索增强 | 文本 | 稀疏+稠密检索 | ★★★☆ | 开源 |
| Mistral RAG | 长文本理解与生成 | 文本 | 向量相似度检索 | ★★★☆ | 闭源 |
关键结论:
- 对比ChatPDF:ChatPDF仅支持文本解析,而RAG-Anything可处理多模态文档,复杂查询精度提升显著;
- 对比LLMChain:LLMChain依赖单一稠密检索,RAG-Anything的混合检索机制适配更多场景;
- 对比OpenRAG:OpenRAG缺乏多模态支持,而RAG-Anything通过KG实现全局语义关联。
技术选型建议:何时选择RAG-Anything?
- 需要处理多模态文档:如财报、学术论文、技术手册中的图表与文本联合分析;
- 追求高精度检索:传统RAG无法满足复杂查询需求(如图文交叉问答);
- 开源可控性优先:避免闭源工具的数据隐私风险,需自主部署和定制化开发;
- 长尾查询场景:混合检索机制可适应关键词、语义模糊、多模态混合等多种查询类型。
Speculative RAG
论文利用一个更大的通用LM来高效验证由一个小型精炼的专业型LM并行生成的多个RAG草稿。每个草稿基于检索文档的不同子集生成,既能在证据层面提供多样化视角,又能减少单份草稿的输入token量。增强对每个子集的理解能力,并缓解长上下文场景下的潜在位置偏差。通过将草稿生成任务委托给小型专业LM,并由大型通用LM对草稿执行单次验证,显著加速RAG流程。在TriviaQA、MuSiQue、PopQA、PubHealth和ARC-Challenge等基准测试,在降低延迟的同时达到SOTA;尤其在PubHealth数据集上,实现高达12.97%的准确率提升,并将延迟降低50.83%。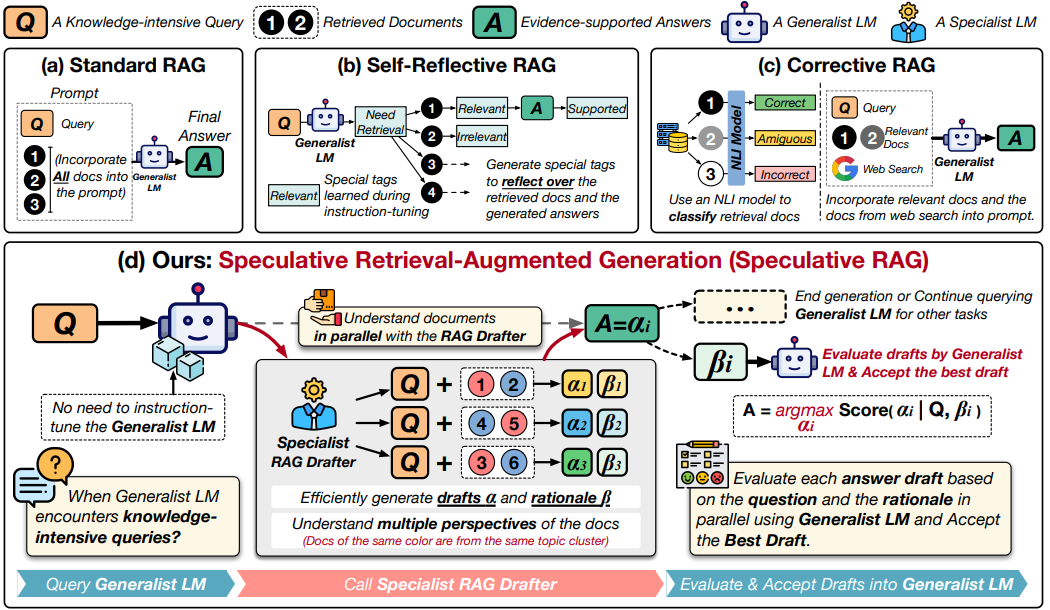
NodeRAG
架构
异构图结构:数据组织的革新
传统的检索系统通常将信息视为独立的文本块,而 NodeRAG 则引入了一种全新的数据组织方式 - 异构图结构(HeteroGraph)。这就像是一张智能的知识网络,其中不同类型的节点代表不同类型的信息单元:
- 语义单元节点(Semantic Unit):表示文本中的核心语义片段
- 实体节点(Entity):代表文本中的关键实体或概念
- 关系节点(Relationship):描述实体之间的关联和交互
- 属性节点(Attribute):存储实体的特征和属性
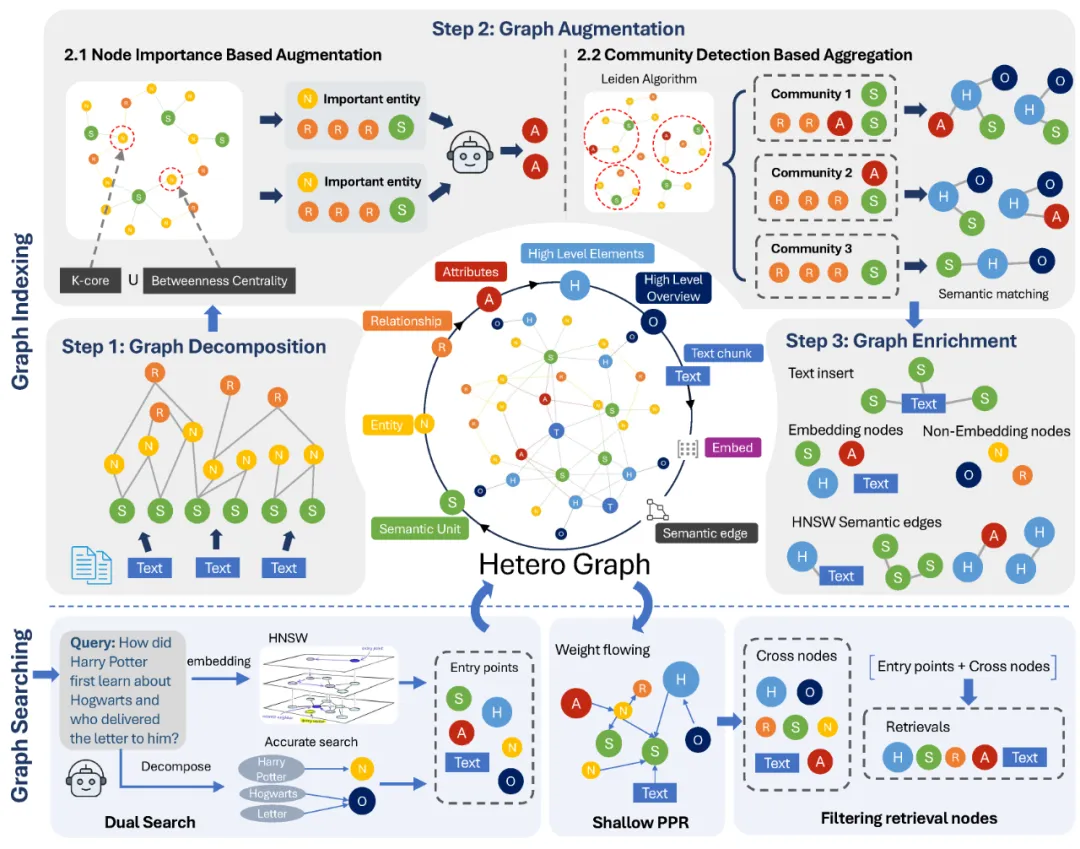
这些不同类型的节点通过边(Edge)相互连接,形成一个复杂而丰富的知识图谱。这种结构不仅仅存储了原始信息,更捕捉信息之间的内在联系,为后续的智能检索奠定基础。
NodeRAG使用NetworkX库构建图结构
def add_semantic_unit(self, semantic_unit:Dict, text_hash_id:str):
semantic_unit = Semantic_unit(semantic_unit, text_hash_id)
if self.G.has_node(semantic_unit.hash_id):
self.G.nodes[semantic_unit.hash_id]['weight'] += 1
else:
self.G.add_node(semantic_unit.hash_id, type='semantic_unit', weight=1)
self.semantic_units.append(semantic_unit)
return semantic_unit.hash_id
流水线处理:从原始文本到结构化知识
采用精心设计的流水线架构,将原始文本转化为结构化的知识图谱。整个流水线包含多个关键阶段:
- 文档处理(Document Pipeline):解析和预处理原始文档
- 文本分解(Text Pipeline):将文本分解为有意义的语义单元
- 图构建(Graph Pipeline):从语义单元中提取实体和关系,构建基础图结构
- 属性生成(Attribute Pipeline):为实体生成丰富的属性信息
- 嵌入计算(Embedding Pipeline):计算节点的向量表示
- 摘要生成(Summary Pipeline):为复杂节点生成概括性摘要
- HNSW 索引(HNSW Pipeline):构建高效的近似最近邻搜索索引
这种流水线设计实现从非结构化文本到高度结构化知识图谱的转换,每个阶段都专注于特定的数据处理任务。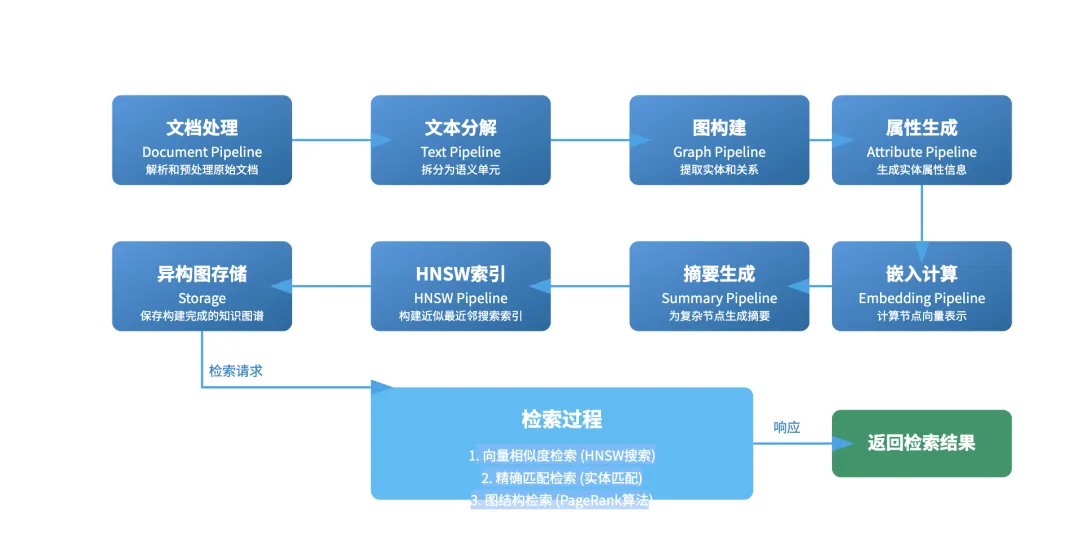
检索算法:融合语义与结构的智能搜索
检索系统融合多种先进技术,实现精准而全面的信息检索:
- 向量相似度检索:利用 HNSW(Hierarchical Navigable Small World)算法实现高效的语义相似度搜索
# HNSW search for enter points by cosine similarity
query_embedding = np.array(self.config.embedding_client.request(query), dtype=np.float32)
HNSW_results = self.hnsw.search(query_embedding, HNSW_results=self.config.HNSW_results)
- 精确匹配检索:针对查询中的关键实体进行精确匹配
# Decompose query into entities and accurate search for short words level items
decomposed_entities = self.decompose_query(query)
accurate_results = self.accurate_search(decomposed_entities)
- 图结构检索:利用个性化PageRank算法在异构图上进行检索
# Personalization for graph search
personalization = {ids:self.config.similarity_weight for ids in retrieval.HNSW_results}
personalization.update({id:self.config.accuracy_weight for id in retrieval.accurate_results})
weighted_nodes = self.graph_search(personalization)
这种多策略融合的检索方法,既考虑文本语义相似性,又利用图结构中的关系信息,实现更加精准和全面的信息检索。
技术创新
稀疏个性化 PageRank(Sparse PPR)
NodeRAG实现一种优化的稀疏个性化PageRank算法,利用SciPy的稀疏矩阵计算能力,高效处理大规模图结构:
def PPR(self, personalization:dict[str,float], alpha:float=0.85, max_iter:int=100, epsilons:float=1e-5):
probs = np.zeros(len(self.nodes))
for node,prob in personalization.items():
probs[self.nodes.index(node)] = prob
probs = probs/np.sum(probs)
for i in range(max_iter):
probs_old = probs.copy()
probs = alpha*self.trans_matrix.dot(probs) + (1-alpha)*probs
if np.linalg.norm(probs-probs_old)<epsilons:
break
return sorted(zip(self.nodes,probs), key=itemgetter(1), reverse=True)
使得NodeRAG能够在复杂的异构图上高效地进行节点重要性计算,为精准检索提供支持。
增量式图更新
NodeRAG支持增量式的图更新,这意味着当有新的文档加入时,系统不需要重建整个知识图谱,而是能够智能地将新信息整合到现有结构中:
async def state_transition(self):
# ...
if self.Current_state == State.FINISHED:
if self.Is_incremental:
if self.web_ui:
self.console.print("[bold green]Detected incremental file, Continue building.[/bold green]")
self.Current_state = State.DOCUMENT_PIPELINE
self.Is_incremental = False
大大提高系统在实际应用中的灵活性和效率。
后处理优化
NodeRAG实现一套智能的后处理机制,根据节点类型和重要性进行筛选和组合,确保检索结果的多样性和全面性:
def post_process_top_k(self, weighted_nodes:List[str], retrieval:Retrieval)->Retrieval:
entity_list = []
high_level_element_title_list = []
relationship_list = []
# 根据节点类型进行筛选和限制
# 关联属性节点
for entity in entity_list:
attributes = self.G.nodes[entity].get('attributes')
if attributes:
for attribute in attributes:
if attribute not in retrieval.unique_search_list:
retrieval.search_list.append(attribute)
retrieval.unique_search_list.add(attribute)
技术挑战
- 大规模图计算效率:随着知识库规模增长,图结构的计算复杂度也会增加。尽管 NodeRAG 实现了稀疏矩阵优化,但在极大规模数据集上的计算效率仍是一个挑战。未来可能需要引入图分区、并行计算等技术进一步提升性能。
- 知识图谱的质量控制:自动构建的知识图谱可能包含错误或不一致的信息。如何有效评估和提升知识图谱的质量,是NodeRAG类系统面临的重要问题。
- 多模态信息整合:实际应用中往往涉及图像、视频等多模态数据。如何将这些不同模态的信息有机整合到异构图结构中。
HiRAG
论文,开源(GitHub,402 Star,48 Fork),Hierarchical RAG,分层RAG,专门用于处理复杂知识图中的多层次推理问题。在处理大规模科学文献(如天体物理学或广义相对论相关论文)时,传统的平面知识图往往难以建立远距离概念间的有效连接,例如将星系形成理论与大爆炸膨胀期的基本粒子物理学关联起来。
基于GraphRAG,通过引入层次化架构来处理不同抽象层次的知识复杂度。
聚类技术采用高斯混合模型等算法将语义相似的实体分组,形成主题化的概念集合。摘要生成环节利用LLM为实体聚类创建更高层次的抽象表示。社区检测算法(如Louvain方法)用于识别跨层的相关实体组合。嵌入技术通过Sentence-BERT等模型将文本转换为数值向量,支持高效的相似度计算。
构建多层次的知识图谱结构,底层包含详细的具体实体,高层则包含抽象的概念摘要,形成从具体到抽象的知识层次体系。
架构
由两个核心模块组成:分层索引构建和分层检索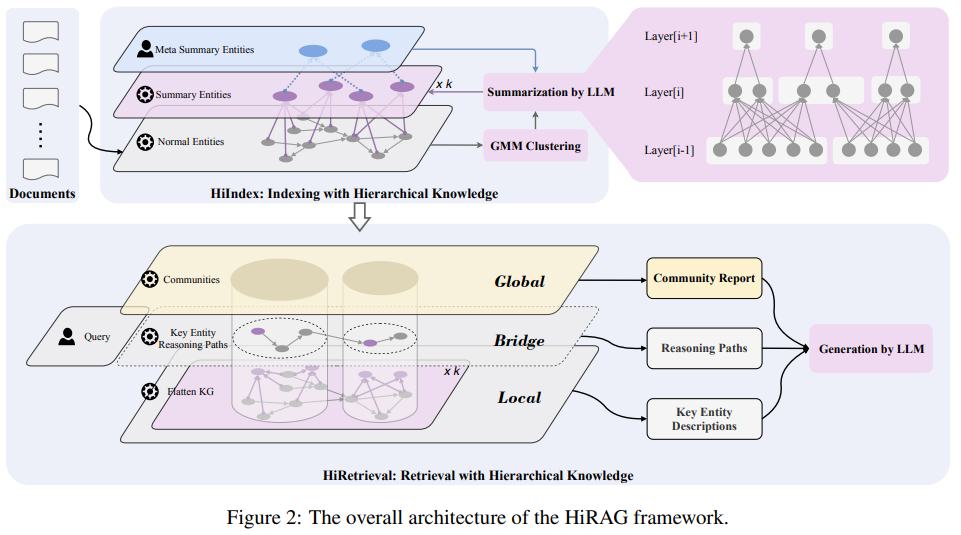
分层索引构建是将原始文档转换为结构化分层知识图的关键过程。该流程首先对输入文档进行预处理,将大型文档(如广义相对论相关的PDF文件)分割为适当大小的文本片段。以10篇论文为例,系统可以生成约300个文本块。
实体和关系提取阶段使用大型语言模型识别文档中的关键实体和它们之间的语义关系。例如系统可以从文档中提取出520个独特实体,如"史瓦西度量"或"爱因斯坦场方程",这些实体及其关系构成了基础层(Layer 0)的知识图G0。
嵌入计算过程使用Sentence-BERT等预训练模型为所有节点和边生成高维向量表示,为后续的相似度计算和聚类分析提供数学基础。
聚类和摘要循环是该系统的核心创新。系统首先使用高斯混合模型等聚类算法将Layer 0中的实体分组为主题相关的集合,例如将520个实体分为40个聚类。然后大型语言模型为每个聚类生成摘要,形成Layer 1的新摘要节点。系统对这些新节点进行嵌入计算,然后重复聚类过程,将Layer 1的摘要进一步聚类(例如形成6个聚类)并生成Layer 2的元摘要节点。当聚类分布的变化小于预设阈值(通常为5%)时,迭代过程结束。
社区检测阶段在所有层次上运行Louvain算法,识别出跨层的实体社区结构。假设系统可能识别出8个社区,如"紧凑恒星对象和引力波特征"等。系统随后使用大型语言模型为每个社区生成详细的描述报告。
这个过程最终创建了一个多层次的知识图谱,其中不同层次代表不同的抽象程度:Layer 0包含详细的具体实体,Layer 1包含主题摘要,Layer 2包含更高层次的元摘要。
当分层索引构建完成后,系统通过多层视图处理用户查询。查询嵌入过程首先将用户查询转换为向量表示,以支持与知识图中节点的相似度匹配。
本地实体检索从顶层开始检索与查询最相似的节点,这些节点包含了来自下层的聚合知识。这种设计有效结合了细粒度的具体信息和高层次的抽象信息。
社区选择机制基于查询相似度选择相关的实体社区,每个社区都提供全局上下文报告,为答案生成提供宏观背景。
全局桥接三元组生成是HiRAG的另一个重要创新。系统首先识别每个相关社区中的关键实体,然后计算它们之间的最短路径,形成"桥接三元组"(主语-关系-宾语结构,如"Kerr度量确定准正常模式")。这些三元组构建了基于事实的推理路径,确保答案的逻辑连贯性。
最终的答案生成阶段将本地片段、社区报告和桥接三元组整合为结构化的提示,输入给大型语言模型生成最终答案。这种设计确保推理轨迹来源于知识图结构,而不仅仅依赖于语言模型的内部参数知识。
工作流程
图
示例
import numpy as np
from sklearn.mixture import GaussianMixture
from sklearn.metrics.pairwise import cosine_similarity
# Sample entities and embeddings (in real case, use Sentence-BERT)
entities = ["Kerr metric", "Quasi-normal modes", "Black hole spin", "Einstein field equations", "Gravitational waves"]
embeddings = np.random.rand(5, 10) # Fake 10-dim embeddings
# Clustering with Gaussian Mixture
gm = GaussianMixture(n_components=2, random_state=0)
gm.fit(embeddings)
clusters = gm.predict(embeddings)
# Group entities by cluster
cluster_groups = {}
for i, cluster in enumerate(clusters):
if cluster not in cluster_groups:
cluster_groups[cluster] = []
cluster_groups[cluster].append(entities[i])
# Placeholder LLM summarization
def llm_summarize(group):
return f"Summary of {', '.join(group)}: Exact solutions in general relativity."
# Create summary nodes for next layer
summary_nodes = []
for cluster, group in cluster_groups.items():
summary = llm_summarize(group)
summary_nodes.append(summary)
print("Clusters:", cluster_groups)
print("Summary Nodes:", summary_nodes)
测评
HiRAG通过桥接机制实现的多尺度推理在减少答案矛盾方面表现突出,这主要归功于其基于结构化知识图的事实验证机制。
对比
LeanRAG
LeanRAG作为一个更加复杂的系统架构,强调基于代码设计的知识图构建方法。该系统通常采用程序化图构造策略,其中代码脚本或算法根据数据中的规则或模式动态构建和优化图结构。LeanRAG可能使用自定义代码来实现实体提取、关系定义和任务特定的图优化,这使得系统具有高度的可定制性,但同时也增加了实现的复杂度和开发成本。
相比之下,HiRAG采用了更加简化但技术上相关的设计方案。该系统优先考虑分层架构而非平面或代码密集型设计,利用强大的大型语言模型(如GPT-4)进行迭代摘要构建,减少了对大量编程工作的依赖。HiRAG的实现流程相对直观:文档分块、实体提取、聚类分析(使用高斯混合模型等),并利用语言模型为更高层次创建摘要节点,直到达到收敛条件(如聚类分布变化小于5%)。
在复杂性管理方面,LeanRAG的代码中心方法允许精细的控制调节,例如在代码中集成特定领域的专业规则,但这可能导致更长的开发周期和潜在的系统错误。HiRAG的语言模型驱动摘要方法减少了这种开销,依赖模型的推理能力进行知识抽象。在性能表现上,HiRAG在需要多层次推理的科学领域表现优异,能够在天体物理学等领域中有效连接基本粒子理论与宇宙膨胀现象,而无需LeanRAG的过度工程化设计。HiRAG的主要优势包括更简单的部署流程,以及通过从分层结构派生的基于事实的推理路径更有效地减少幻觉现象。
以量子物理学如何影响星系形成的查询为例,LeanRAG可能需要编写自定义提取器来处理量子实体并手动建立链接关系。而HiRAG会自动将低级实体(如"夸克")聚类为中级摘要(如"基本粒子")和高级摘要(如"大爆炸膨胀"),通过检索桥接路径来生成连贯的答案。两个系统的工作流程差异明显:LeanRAG采用代码实体提取、程序化图构建和查询检索的流程;而HiRAG采用语言模型实体提取、分层聚类摘要和多层检索的流程。
HyperGraphRAG
HyperGraphRAG在2025年发表的arXiv论文(2503.21322)中被首次介绍,该系统采用超图结构替代传统的标准图。在超图架构中,超边可以同时连接两个以上的实体,能够捕获n元关系(即涉及三个或更多实体的复杂关系,如"黑洞合并产生LIGO检测到的引力波")。这种设计对于处理复杂的多维知识特别有效,能够克服传统二元关系(标准图边)的局限性。
HiRAG坚持使用传统图结构,但通过添加分层架构来实现知识抽象。系统从基础实体构建多层次结构直至元摘要级别,并使用跨层社区检测算法(如Louvain算法)形成知识的横向切片。HyperGraphRAG专注于在相对平坦的结构中实现更丰富的关系表示,而HiRAG则强调垂直深度的知识层次。
在关系处理能力方面,HyperGraphRAG的超边能够建模复杂的多实体连接,例如医学领域的n元事实:“药物A与蛋白质B和基因C相互作用”。HiRAG使用标准的三元组结构(主语-关系-宾语),但通过分层桥接来建立推理路径。在效率表现上,HyperGraphRAG在具有复杂交织数据的领域表现出色,如农业领域中"作物产量取决于土壤、天气和害虫"等多因素关系,在准确性和检索速度方面优于传统GraphRAG。HiRAG更适合抽象推理任务,通过多尺度视图减少大规模查询中的噪声干扰。HiRAG的优势包括与现有图工具的更好集成性,以及通过分层结构减少大规模查询中的信息噪声。HyperGraphRAG可能需要更多的计算资源来构建和维护超边结构。
以"引力透镜对恒星观测的影响"查询为例,HyperGraphRAG可能使用单个超边同时链接"时空曲率"、"光路径"和"观察者位置"等多个概念。HiRAG则会采用分层处理:基础层(曲率实体)、中间层(爱因斯坦方程摘要)、高层(宇宙学解),然后通过桥接这些层次来生成答案。根据HyperGraphRAG论文的测试结果,该系统在法律领域查询中达到了更高的准确率(85% vs. GraphRAG的78%),而HiRAG在多跳问答基准测试中显示出88%的准确率。
MAIN-RAG
MAIN-RAG(arXiv 2501.00332),采用多个LLM智能体协作的方式来完成检索、过滤和生成等复杂任务。在MAIN-RAG架构中,不同智能体独立对文档进行评分,使用自适应阈值过滤噪声信息,并通过共识机制实现稳健的文档选择。其他变体,如Anthropic的多智能体研究成果或LlamaIndex的实现方案,采用角色分配策略来处理复杂的问题求解任务。
HiRAG采用更偏向单流的设计模式,但仍然具备智能体特性,因为其大型语言模型在摘要生成和路径构建中发挥智能体的作用。该系统不采用多智能体协作模式,而是依赖分层检索机制来提升效率。
在协作能力方面,多智能体系统能够处理动态任务(例如一个智能体负责查询优化,另一个负责事实验证),特别适合长上下文问答场景。HiRAG的工作流程更加简化:离线构建分层结构,在线通过桥接机制执行检索。在稳健性表现上,MAIN-RAG通过智能体共识机制将不相关文档的比例降低2-11%,从而提高答案准确性。HiRAG通过预定义的推理路径减少幻觉现象,但可能缺乏多智能体系统的动态适应能力。HiRAG的优势包括单查询处理的更高速度,以及无需智能体协调的更低系统开销。多智能体系统在企业级应用中表现优秀,特别是在医疗保健等领域,能够协作检索患者数据、医学文献和临床指南。
以商业报告生成为例,多智能体系统可能让Agent1负责检索销售数据,Agent2负责趋势过滤,Agent3负责洞察生成。HiRAG则会将数据进行分层处理(基础层:原始数据;高层:市场摘要),然后通过桥接机制生成直接答案。
Tiny-RAG
更智能的检索策略:
- 混合检索 (Hybrid Search):它将传统关键词检索(类似BM25)的精准匹配能力和向量检索的语义理解能力结合起来,你可以通过一个权重参数动态调节两者的贡献。这意味着,无论你的问题是偏向语义理解还是关键词匹配,系统都能找到最相关的结果。
- 集成检索 (Ensemble Retrieval):可定义多个检索器,系统会将它们的结果加权融合,取长补短,最大化召回的准确性和多样性。
每一个由LLM生成的答案,都会附带详细的引用来源:
- 答案依据哪些原文片段
- 每个片段与问题的相关度分数
- 由哪种检索策略(向量/混合)找到的
参考

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)