2、知识图谱基础知识
等。知识图谱与自然语言处理关系密切,主要为两点:1、知识获取的一个重要途径是从自由文本中抽取,而文本信息抽取是自然语言处理的核心问题之一。2、知识图谱构建好后通常可以用作支撑自然语言理解的背景知识。除此之外,知识图谱还与语言学以及认知科学等学科关系密切。
概述
知识图谱涉及的相关计算机子学科有:知识表示,数据库,机器学习,自然语言处理等。
知识图谱与自然语言处理关系密切,主要为两点:
1、知识获取的一个重要途径是从自由文本中抽取,而文本信息抽取是自然语言处理的核心问题之一。
2、知识图谱构建好后通常可以用作支撑自然语言理解的背景知识。
除此之外,知识图谱还与语言学以及认知科学等学科关系密切。
知识表示
知识表示是对现实世界的一种抽象表述。评价标准主要有两点:表达能力(Expressive)计算效率(Efficiency)。知识的表示方式主要分为符号表示和数值表示。
基于不同学科发展出不同的知识表示
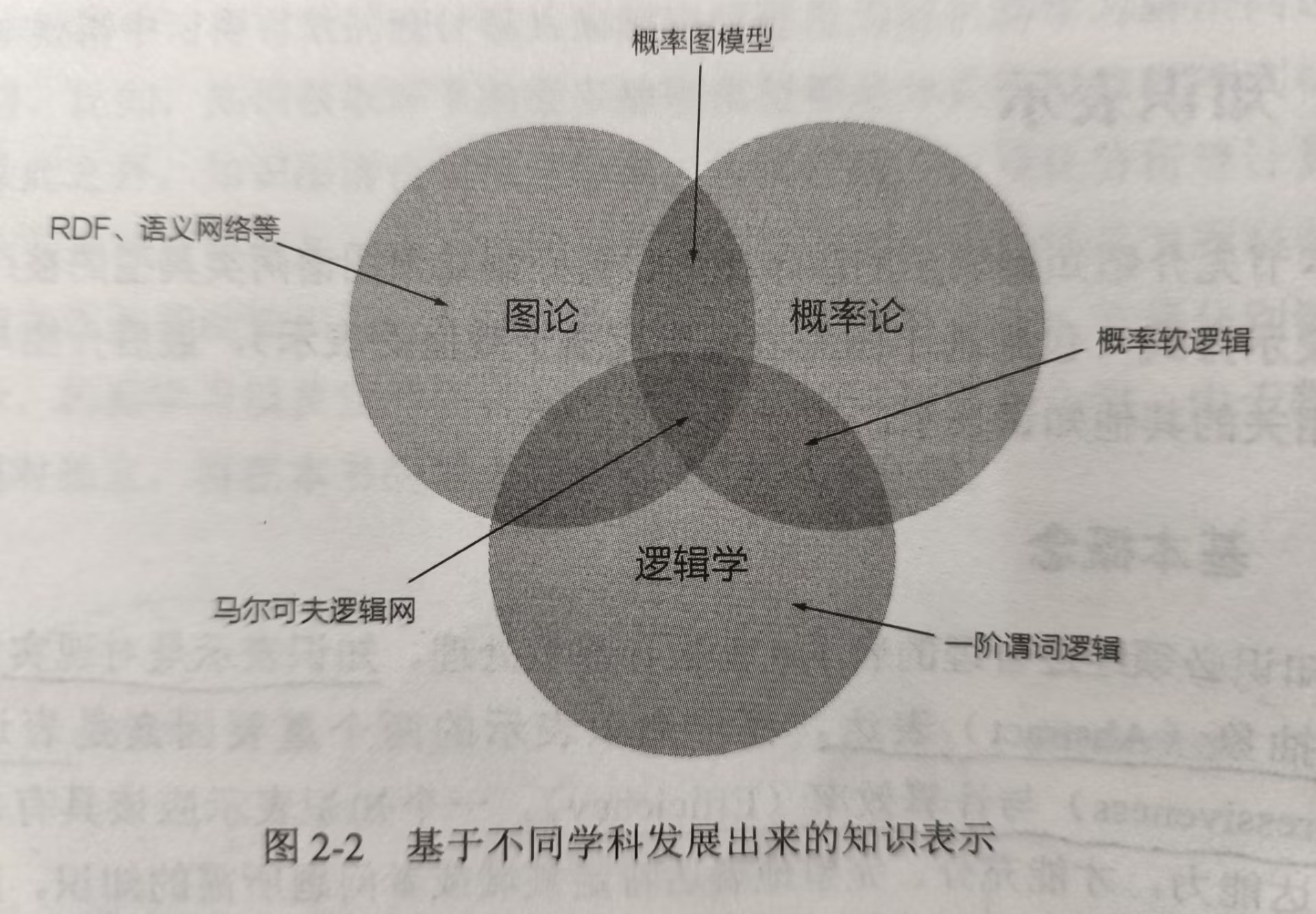
对知识图谱而言,较为常见的表示是基于图的表示方式。图模型是知识图谱的逻辑表达形式,是热门最容易理解的一种表示。为了方便知识图谱数据的管理和共享,语义网络领域制定了相应的规范与标注,按照RDF进行表示。同时,为了让计算机有效的处理和利用知识图谱,还需要有知识图谱的数值化表示。
知识图谱的图表示
二元组
涉及图表示的一些概念,详见图论。
包括:二元组,有向图,无向图,边,弧,度数,入度,出度,邻接矩阵,路径,路径长度,简单路径,环,可达等基本图论概念。
三元组
RDF是用于描述现实中资源的W3C标准,它是描述信息的一种通用方式,使信息可以被计算机应用程序读取并理解。
一个三元组包含三个元素:主体(Subject)谓词(Predicate)客体(Object)
如果三元组描述了某个资源的属性,那么三个元素也可以称为:主体,属性(Property)属性值(Property Value)
由此,一个知识图谱可以视作三元组的集合。
知识图谱的数值表示
背景:如何将知识图谱作为背景知识融合进深度学习模型成为一个关键技术问题
目前基本思路为:将知识图谱中的点与边表示成数值化的向量,不同向量表示在实际应用中有不同的效果。
引申:如何为知识图谱中的实体与关系求得最优的向量化表示,是当前知识图谱表示的核心问题。知识图谱的表示学习旨在将知识图谱中的元素表示为低维稠密实值向量。
向量化表示表示是面向机器处理的,而符号化表示是面向人的理解的。相对于向量化表示,符号化表示易于理解,可以实现符号推理。
学习向量化表示的关键:合理定义关于事实(三元组<h,r,t>)的损失函数fr(h,t),其中h和t是三元组的两个实体h和t的向量化表示。在通常情况下,当事实<h,r,t>成立时,我们期望fr(h,t)最小。考虑整个图谱的事实,则最小化来进行学习,其中O表示知识图谱中所有事实的集合。
常用的模型有:基于距离的模型SE,基于翻译的模型TransE,TransH,TransR,等。
其他相关知识表示
如:谓词逻辑,产生式规则,框架,树形知识表示,概率图模型,马尔科夫链,马尔科夫逻辑网。
机器学习
相关的基本概念:机器学习,样本,特征,模型,训练集,测试集,损失函数,监督学习/无监督学习,半监督学习,深度学习,CNN,RNN,注意力机制等。这部分建议单独学习相关的内容,跑点代码手动调一下。
自然语言处理
自然语言处理(Natural Language Processing,NLP),涉及语言学、计算机科学等多门知识学科,是实现自然人机交互的重要学科。NLP的主要使命是自然语言的理解与生成。
相关基本概念:
字符,单词(Token),句子,段落,篇章。这些与常识相同。NLP可以在词汇、句子、段落和篇章级别展开处理。
常见任务
对文本,NLP可以在词法分析、语法分析、语义分析、语用分析等层面展开。常见任务有:断句,分词,词性标注,词性还原,识别停用词,依存句法分析,命名实体识别,共指消解,语义角色标注等。
文本向量化表示
文本的向量化表示是指将文本表示成计算机能够进行运算的数值向量形式。传统的词向量表示是以独热(One-Hot)和词袋为代表的离散表示,近年来主流的词向量表示形式是以分布式表示为代表的连续表示。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)