Ombromanie:使用 Azure Speech 和 TensorFlow.js Handposes 创建手影故事
这篇文章是写给那些把手电筒偷偷带进卧室,在墙上投下可怕阴影的大兄弟,写给所有小孩子,或者内心还是孩子的大人,让他们享受如此美妙的娱乐。
你有没有试过在墙上投下手影?这是世界上最简单的事情,但要做好它需要练习和正确的设置。为了培养你的#cottagecore 审美,试着走进一个只有一根点燃的蜡烛的完全黑暗的房间,然后在素色的墙上投下手影。效果是惊人的戏剧性。多么有趣!
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--d06Uztbc--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/4vuuwdz6sgzlc6wbp59y.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--d06Uztbc--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/4vuuwdz6sgzlc6wbp59y.png)
哪怕是一盏茶灯也足以营造出绝佳的效果
在 2020 年和现在到 2021 年,许多人在环顾房屋时回归基本生活,重新打开阁楼和地下室尘土飞扬的角落,并回忆起他们曾经喜爱的简单手工艺品。造纸术,有人吗?您所需要的只是一些工具和撕碎的再生纸。压花?你所需要的只是报纸、一些厚重的书籍和耐心。还有手影?只是一根蜡烛。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--HOKt4XsS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/g9fc20uizkrr4fokskta.jpeg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HOKt4XsS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/g9fc20uizkrr4fokskta.jpeg)
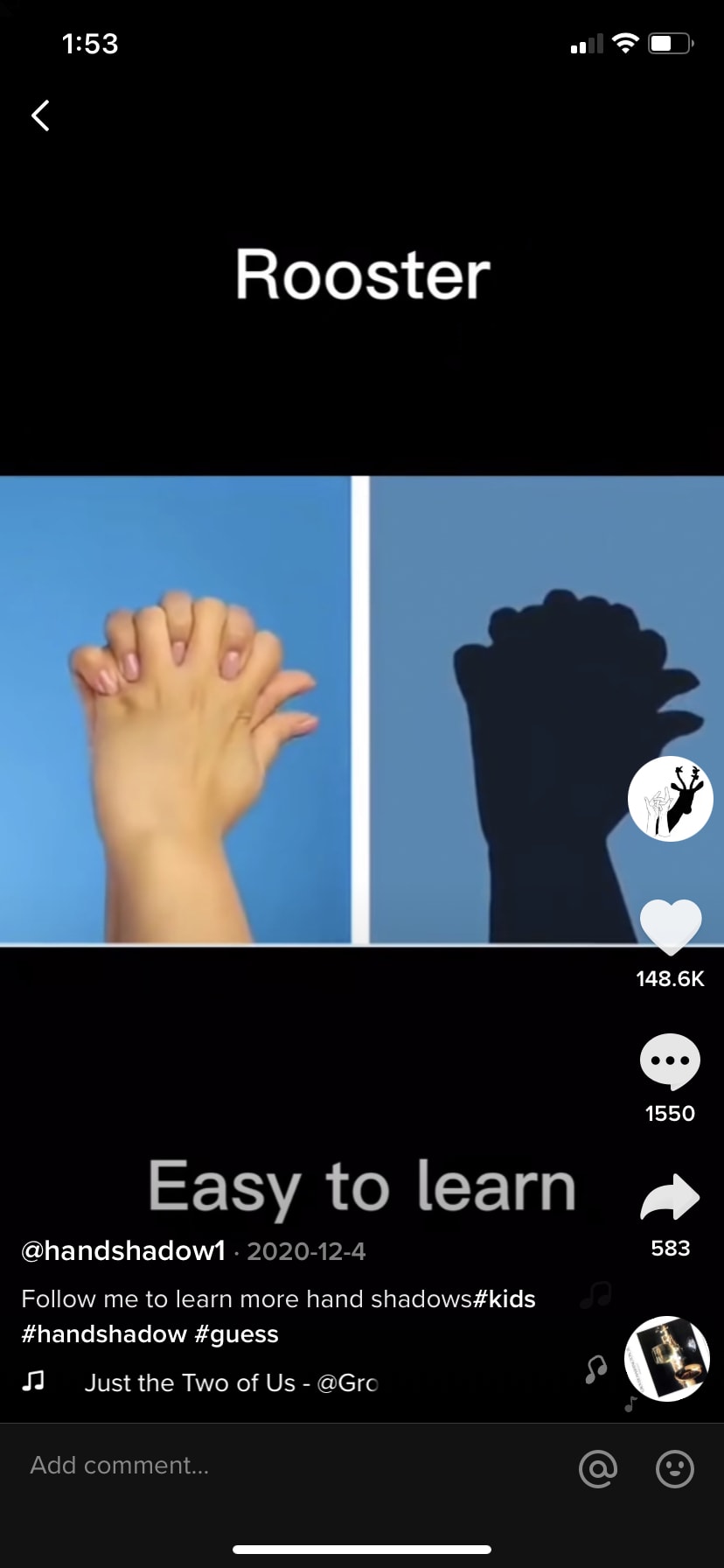
这位 TikTok 创作者的手影教程获得了数千次浏览
但是,当尝试在 Web 应用程序中捕捉 #cottagecore 氛围时,开发人员该怎么办?
高科技小屋
在探索手部阴影的艺术时,我想知道我最近为身体姿势所做的一些作品是否适用于手部姿势。如果您可以用手在网上讲述一个故事,并以某种方式保存该节目的视频及其背后的叙述,然后将其发送给某个特别的人,那会怎样?在封锁期间,还有什么比在朋友或亲戚之间分享影子故事更有趣的呢?
手影投射是一种可能起源于中国的民间艺术;如果你去有舞台表演的茶馆,你可能有幸看到这样的一场!
举手
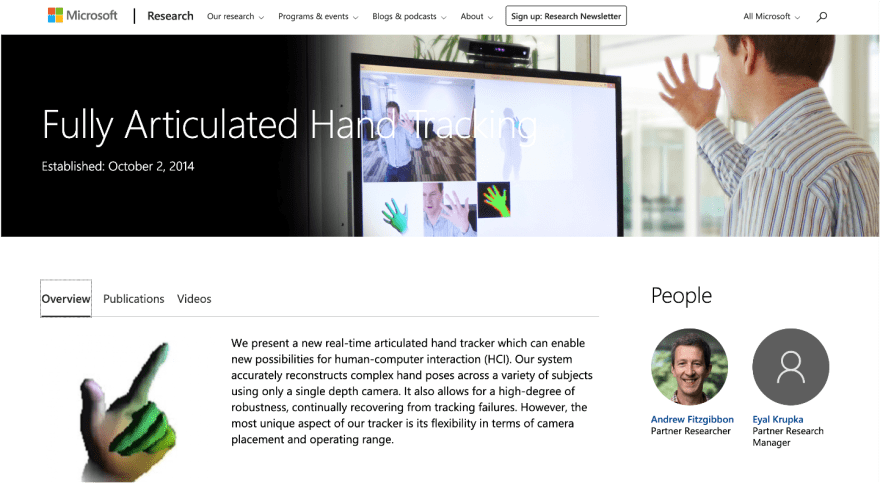
当您开始研究手部姿势时,令人惊讶的是,网络上有多少关于该主题的内容。至少自 2014 年以来,一直在研究、模拟和游戏领域创建完全铰接的手:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--HEbRgLdP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/xaajsrtmvm9m5f74ne8r.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HEbRgLdP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/xaajsrtmvm9m5f74ne8r.png)
MSR投掷手
GitHub 上已经有几十个手势库:
-
手头跟踪的整个 GitHub 主题
-
用于手部跟踪的“真棒”列表
-
挑战和黑客马拉松
在许多应用中,手部追踪是一项有用的活动:
• 游戏
• 模拟/培训
• “免提”用于通过移动身体与事物进行远程交互
• 辅助技术
• TikTok 效果🏆
• 有用的东西,例如Accordion Hands 应用程序
其中一个更有趣的新库handsfree.js提供了一系列出色的演示,旨在实现免提 Web 体验:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Mt-rcAD---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/l228n9e09eiu16g3csvp.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Mt-rcAD---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/l228n9e09eiu16g3csvp.gif)
Handsfree.js,一个很有前途的项目
事实证明,手是相当复杂的东西。它们每个包括 21 个关键点(对比 PoseNet 的 17 个整个身体的关键点)。事实证明,建立一个模型来支持对如此复杂的关键点分组进行推理具有挑战性。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--tc-kdfq8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/v8sl83we0tbpofbtdu5v.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--tc-kdfq8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/v8sl83we0tbpofbtdu5v.png)
将手势合并到应用程序中时,Web 开发人员可以使用两个主要库:TensorFlow.js 的手势和 MediaPipe。 HandsFree.js 使用这两种方法,只要它们公开 API。事实证明,TensorFlow.js 和 MediaPipe 的手势都不适合我们的项目。我们将不得不妥协。
-
TensorFlow.js 的手势允许访问每个手部关键点,并能够根据需要将手部绘制到画布上。但是,它目前仅支持单手姿势,这对于良好的手影表演来说并不是最佳选择。
-
MediaPipe 的手势模型(由 TensorFlow.js 使用)确实允许双手但其 API 不允许对关键点进行太多样式化,因此使用它绘制阴影并不明显。
另一个库fingerposes已针对手语上下文中的手指拼写进行了优化,值得一看。
由于使用 Canvas API 来绘制自定义阴影更为重要,因此我们不得不使用 TensorFlow.js,希望它能够很快支持多手或免提。
让我们开始构建这个应用程序。
脚手架静态 Web 应用程序
作为一名 Vue.js 开发人员,我总是使用 Vue CLI 来搭建一个使用vue create my-app的应用程序并创建一个标准应用程序。我设置了一个带有两条路线的基本应用程序:Home 和 Show。由于这将被部署为 Azure 静态 Web 应用程序,我遵循我的标准做法,将我的应用程序文件包含在一个名为app的文件夹中,并创建一个api文件夹以包含一个 Azure 函数来存储密钥(稍后会详细介绍)。
在我的 package.json 文件中,我导入了用于在此应用中使用 TensorFlow.js 和认知服务语音 SDK 的重要包。请注意,TensorFlow.js 已将其导入划分为单独的包:
"@tensorflow-models/handpose": "^0.0.6",
"@tensorflow/tfjs": "^2.7.0",
"@tensorflow/tfjs-backend-cpu": "^2.7.0",
"@tensorflow/tfjs-backend-webgl": "^2.7.0",
"@tensorflow/tfjs-converter": "^2.7.0",
"@tensorflow/tfjs-core": "^2.7.0",
...
"microsoft-cognitiveservices-speech-sdk": "^1.15.0",
进入全屏模式 退出全屏模式
设置视图
我们将 TensorFlow.js 检测到的手的图像绘制到画布上,叠加到由网络摄像头提供的视频上。此外,我们将手重新绘制到第二个画布(shadowCanvas),样式类似于阴影:
<div id="canvas-wrapper column is-half">
<canvas id="output" ref="output"></canvas>
<video
id="video"
ref="video"
playsinline
style="
-webkit-transform: scaleX(-1);
transform: scaleX(-1);
visibility: hidden;
width: auto;
height: auto;
position: absolute;
"
></video>
</div>
<div class="column is-half">
<canvas
class="has-background-black-bis"
id="shadowCanvas"
ref="shadowCanvas"
>
</canvas>
</div>
进入全屏模式 退出全屏模式
加载模型,开始关键帧输入
异步工作,加载 Handpose 模型。设置后端并加载模型后,通过网络摄像头加载视频,然后开始观看视频的关键帧以获取手部姿势。在这些步骤中,确保在模型加载失败或没有可用的网络摄像头时进行错误处理非常重要。
async mounted() {
await tf.setBackend(this.backend);
//async load model, then load video, then pass it to start landmarking
this.model = await handpose.load();
this.message = "Model is loaded! Now loading video";
let webcam;
try {
webcam = await this.loadVideo();
} catch (e) {
this.message = e.message;
throw e;
}
this.landmarksRealTime(webcam);
},
进入全屏模式 退出全屏模式
设置网络摄像头
仍在异步工作,设置相机以提供图像流
async setupCamera() {
if (!navigator.mediaDevices || !navigator.mediaDevices.getUserMedia) {
throw new Error(
"Browser API navigator.mediaDevices.getUserMedia not available"
);
}
this.video = this.$refs.video;
const stream = await navigator.mediaDevices.getUserMedia({
video: {
facingMode: "user",
width: VIDEO_WIDTH,
height: VIDEO_HEIGHT,
},
});
return new Promise((resolve) => {
this.video.srcObject = stream;
this.video.onloadedmetadata = () => {
resolve(this.video);
};
});
},
进入全屏模式 退出全屏模式
设计一只手来镜像网络摄像头
现在乐趣开始了,因为您可以创造性地在视频顶部画手。这个标记功能在每个关键帧上运行,观察要检测的手并在画布上绘制线条 - 视频顶部为红色,shadowCanvas 顶部为黑色。由于 shadowCanvas 背景是白色的,所以手也被绘制为白色,并且观察者只能看到偏移阴影,带有圆角的模糊黑色。效果比较诡异!
async landmarksRealTime(video) {
//start showing landmarks
this.videoWidth = video.videoWidth;
this.videoHeight = video.videoHeight;
//set up skeleton canvas
this.canvas = this.$refs.output;
...
//set up shadowCanvas
this.shadowCanvas = this.$refs.shadowCanvas;
...
this.ctx = this.canvas.getContext("2d");
this.sctx = this.shadowCanvas.getContext("2d");
...
//paint to main
this.ctx.clearRect(0, 0, this.videoWidth,
this.videoHeight);
this.ctx.strokeStyle = "red";
this.ctx.fillStyle = "red";
this.ctx.translate(this.shadowCanvas.width, 0);
this.ctx.scale(-1, 1);
//paint to shadow box
this.sctx.clearRect(0, 0, this.videoWidth, this.videoHeight);
this.sctx.shadowColor = "black";
this.sctx.shadowBlur = 20;
this.sctx.shadowOffsetX = 150;
this.sctx.shadowOffsetY = 150;
this.sctx.lineWidth = 20;
this.sctx.lineCap = "round";
this.sctx.fillStyle = "white";
this.sctx.strokeStyle = "white";
this.sctx.translate(this.shadowCanvas.width, 0);
this.sctx.scale(-1, 1);
//now you've set up the canvases, now you can frame its landmarks
this.frameLandmarks();
},
进入全屏模式 退出全屏模式
每帧,绘制关键点
随着关键帧的进展,模型会为每个手的元素预测新的关键点,并且两个画布都被清除并重新绘制。
const predictions = await this.model.estimateHands(this.video);
if (predictions.length > 0) {
const result = predictions[0].landmarks;
this.drawKeypoints(
this.ctx,
this.sctx,
result,
predictions[0].annotations
);
}
requestAnimationFrame(this.frameLandmarks);
进入全屏模式 退出全屏模式
画出栩栩如生的手
由于 TensorFlow.js 允许您直接访问手的关键点和手的坐标,因此您可以操纵它们来绘制更逼真的手。因此,我们可以将手掌重新绘制为多边形,而不是类似于花园耙子,其点在手腕处达到顶点。
重新识别手指和手掌:
fingerLookupIndices: {
thumb: [0, 1, 2, 3, 4],
indexFinger: [0, 5, 6, 7, 8],
middleFinger: [0, 9, 10, 11, 12],
ringFinger: [0, 13, 14, 15, 16],
pinky: [0, 17, 18, 19, 20],
},
palmLookupIndices: {
palm: [0, 1, 5, 9, 13, 17, 0, 1],
},
进入全屏模式 退出全屏模式
...并将它们绘制到屏幕上:
const fingers = Object.keys(this.fingerLookupIndices);
for (let i = 0; i < fingers.length; i++) {
const finger = fingers[i];
const points = this.fingerLookupIndices[finger].map(
(idx) => keypoints[idx]
);
this.drawPath(ctx, sctx, points, false);
}
const palmArea = Object.keys(this.palmLookupIndices);
for (let i = 0; i < palmArea.length; i++) {
const palm = palmArea[i];
const points = this.palmLookupIndices[palm].map(
(idx) => keypoints[idx]
);
this.drawPath(ctx, sctx, points, true);
}
进入全屏模式 退出全屏模式
加载模型和视频、跟踪关键帧以及在画布上绘制手和阴影后,我们可以实现语音转文本 SDK,以便您可以讲述和保存您的影子故事。
为此,请通过创建服务从 Azure 门户获取Speech Services的密钥:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--XEnt_4Zj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/j0h40v2q83g3trhfworg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--XEnt_4Zj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/j0h40v2q83g3trhfworg.png)
您可以通过导入 sdk 连接到此服务:
import * as sdk from "microsoft-cognitiveservices-speech-sdk";
...并在获得存储在/api文件夹中的 Azure 函数中的 API 密钥后开始音频转录。此函数获取存储在托管应用程序的 Azure 静态 Web 应用程序中的 Azure 门户中的密钥。
async startAudioTranscription() {
try {
//get the key
const response = await axios.get("/api/getKey");
this.subKey = response.data;
//sdk
let speechConfig = sdk.SpeechConfig.fromSubscription(
this.subKey,
"eastus"
);
let audioConfig = sdk.AudioConfig.fromDefaultMicrophoneInput();
this.recognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig);
this.recognizer.recognized = (s, e) => {
this.text = e.result.text;
this.story.push(this.text);
};
this.recognizer.startContinuousRecognitionAsync();
} catch (error) {
this.message = error;
}
},
进入全屏模式 退出全屏模式
在此函数中,SpeechRecognizer 以块的形式收集文本,它可以识别并组织成句子。该文本被打印到消息字符串中并显示在前端。
展示故事
在最后一部分中,投射到 shadowCanvas 上的输出被保存为流并使用 MediaRecorder API 记录:
const stream = this.shadowCanvas.captureStream(60); // 60 FPS recording
this.recorder = new MediaRecorder(stream, {
mimeType: "video/webm;codecs=vp9",
});
(this.recorder.ondataavailable = (e) => {
this.chunks.push(e.data);
}),
this.recorder.start(500);
进入全屏模式 退出全屏模式
...并在下面显示为带有新 div 中故事情节的视频:
const video = document.createElement("video");
const fullBlob = new Blob(this.chunks);
const downloadUrl = window.URL.createObjectURL(fullBlob);
video.src = downloadUrl;
document.getElementById("story").appendChild(video);
video.autoplay = true;
video.controls = true;
进入全屏模式 退出全屏模式
可以使用 Visual Studio Code](https://github.com/microsoft/vscode-azurestaticwebapps)的优秀[Azure 插件将此应用程序部署为 Azure 静态 Web 应用程序。一旦它上线,你就可以讲述持久的影子故事!
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--m7dwaqm3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/pkxdujhsgmpnyykj5500.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--m7dwaqm3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/pkxdujhsgmpnyykj5500.png)
在此处尝试 Ombromanie。代码库在此处可用
看看 Ombromanie 的实际应用:
了解有关 Azure 上 AI 的更多信息
Azure AI Essentials 视频,涵盖语音和语言
Azure 免费账户注册

Vue社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献21233条内容
已为社区贡献21233条内容

所有评论(0)