人工智能之机器学习
人工智能人工智能概述python与java人工智能分类人工智能的历史机器学习机器学习定义机器学习概念机器学习概念性含义人工智能概述人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它试图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反...
人工智能
人工智能
概述
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它试图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器。
python与java
- 利用python解析数据集速度、效率方面比较轻量级!
i.轻量级指的是部署到服务器里面,可以提高服务器访问并发!
ii.轻量级指的是业务与业务之间的逻辑性很强,兼容性很强、降低耦合度!
iii.轻量级指的是业务与数据之间的一种关系体现很轻,简单说:获取数据集的方式很快、多样化 - java语言也可以实现人工智能的操作数据但是不建议!—重量级
i.重量级的操作,不适合"数据集的"采集操
ii.重量级操作不适合数据集的清理操作
iii.重量级的业务与数据之间很难进行数据解析操作!
人工智能分类
- 弱人工智能Artificial Narrow Intelligence(ANI)
弱人工智能是擅长于单个方面的人工智能。 - 强人工智能Artificial General Intelligence(AGI)
人类级别的人工智能。强人工智能是指在各方面都能喝人类比肩的人工智能,人类能干的脑力活它都能干。 - 超人工智能Artificial Super Intelligence(ASI)
知名人工智能思想家Nick Bostrom把超级智能定义为”在几乎所有领域都比最聪明的人类大脑都聪明很多,包括科学创新、通识和社交技能“。
人工智能的历史

机器学习
机器学习定义
- Machine Learning(ML) is a scientific discipline that deals with the
construction and study of algorithms that can learn from data - 机器学习是一门从数据中研究算法的科学学科。
- 机器学习直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测

“数据”-----------到 --------“算法”
如何实现 “数据” 到 "算法"的过程?
数据采集(Python)—>数据分析(Python)—> 数据挖掘(hadoop)—> 模型建立(算法)—> 预测未来 (机器)
- 基本概念
输入: x ∈X(属性值)
输出: y ∈Y(目标值 )
获得一个目标函数(target function):f : X —> Y(理想的公式)
输入数据:D={(x1,y1),(x2,y2)·····(xn,yn)}(历史记录信息)==数据集!
最终具有最优性能的假设公式:g : X —> Y(学习得到的最终公式 )
机器学习概念
•美国卡内基梅隆大学(Carnegie Mellon University)机器学习研究领域的著名教授Tom Mitchell对机器学习的经典定义
- A program can be said to learn from experience E with respect to some class of tasks T and performance measure P , If its performance at tasks in T, as measured by P, improves with experience E
- 对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
- 其中重要的机器学习对象:
• 任务Task T,一个或多个、经验Experience E、度量性能Performance P
• 即:随着任务的不断执行,经验的累积会带来计算机性能的提升。

①算法(T):根据业务需要和数据特征选择的相关算法, 也就是一个数学公式
②模型(E):基于数据和算法构建出来的模型
③评估/测试( P):对模型进行评估的策略
机器学习概念性含义
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
-
训练数据
训练指的是一种学习行为 将学到的转化为:“经验”-----通过经验采集的数据才是训练数据!训练数据是存在很大的不合理性! 并不能满足机器的学习使用! -
数据集
数据集就是一种算法的实现!数据集不是训练数据,能满足机器的学习使用! -
x(i)
表示第i个样本的x向量 -
xi : x向量的第i维度的值
-
拟合
构建的算法符合给定数据的特征 -
鲁棒性
健壮性、稳健性、强健性,是系统的健壮性;当存在异常数据的时候,算法也会拟合数据 -
过拟合
算法太符合样本数据的特征,对于实际生产中的数据特征无法拟合 -
欠拟合
算法不太符合样本的数据特征
常见应用框架
- sciket-learn(Python)
http://scikit-learn.org/stable/
于Python语言开发的人工智能 ----大量使用 <效率最高的 > - Mahout(Hadoop生态圈基于MapReduce)
http://mahout.apache.org/
基于大数据hadoop的人工智能-----不建议 (大数据直接和AI结合)----成本太高!–国内:AI技术<科大讯飞> - Spark MLlib
http://spark.apache.org/
基于Spark MLlib 是处理数据解析 —数据集 --它处理数据集的速度高出hadoop的百倍
人工智能的应用场景
- 个性化推荐:个性化指的是根据各种因素来改变用户体验和呈现给用户内容,这些因素可能包含用户的行为数据和外部因素;推荐常指系统向用户呈现一个用户可能感兴趣的物品列表。
- 精准营销:从用户群众中找出特定的要求的营销对象。
- 客户细分:试图将用户群体分为不同的组,根据给定的用户特征进行客户分组。
- 预测建模及分析:根据已有的数据进行建模,并使用得到的模型预测未来
机器学习、数据分析、数据挖掘区别与联系
- 数据分析:数据分析是指用适当的统计分析方法对收集的大量数据进行分析并提取有用的信息,以及形成结论,从而对数据进行详细的研究和概括过程。在实际工作中,数据分析可帮助人们做出判断;数据分析一般而言可以分为统计分析、探索性数据分析和验证性数据分析三大类。
- 数据挖掘:一般指从大量的数据中通过算法搜索隐藏于其中的信息的过程。通常通过统计、检索、机器学习、模式匹配等诸多方法来实现这个过程。
- 机器学习:是数据分析和数据挖掘的一种比较常用、比较好的手段。
机器学习分类
有监督学习
定义
用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训练数据集中推断出模型的机器学习任务。
算法
- 判别式模型(Discriminative Model)
直接对条件概率p(y|x)进行建模,常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等; - 生成式模型(Generative Model)
对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等; - 区别:
①生成式模型更普适;判别式模型更直接,目标性更强
②生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的差异性,寻找的是分类面
③由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型
无监督学习
定义
与监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
算法
无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。
半监督学习
定义
考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习和无监督学习的结合。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
它的成立依赖于模型假设,主要分为三大类:平滑假设、聚类假设、流行假设;其中流行假设更具有普遍性。
算法
主要分为四大类:半监督分类、半监督回归、半监督聚类、半监督降维。
缺点
抗干扰能力弱,仅适合于实验室环境,其现实意义还没有体现出来;未来的发展主要是聚焦于新模型假设的产生。
机器学习算法TOP10
| 算法名称 | 算法描述 |
|---|---|
| C4.5 | 分类决策树算法,决策树的核心算法,ID3算法的改进算法。 |
| CART | 分类与回归树(Classification and Regression Trees) |
| kNN | K近邻 分类算法;如果一个样本在特征空间中的k个最相似的样本中大多数属于某一个类别,那么该样本也属于该类别 |
| NaiveBayes | 贝叶斯分类模型;该模型比较适合属性相关性比较小的时候,如果属性相关性比较大的时候,决策树模型比贝叶斯分类模型效果好(原因:贝叶斯模型假设属性之间是互不影响的) |
| SVM | 支持向量机,一种有监督学习的统计学习方法,广泛应用于统计分类和回归分析中。 |
| EM | 最大期望算法,常用于机器学习和计算机视觉中的数据集聚领域 |
| Apriori | 关联规则挖掘算法 |
| K-Means | 聚类算法,功能是将n个对象根据属性特征分为k个分割(k<n); 属于无监督学习 |
| PageRank | Google搜索重要算法之一 |
| AdaBoost | 迭代算法;利用多个分类器进行数据 |
机器学习、人工智能和深度学习的关系
- 深度学习是机器学习的子类;深度学习是基于传统的神经网络算法发展到’多隐层’的一种算法体现。
- 机器学习是人工智能的一个子类;
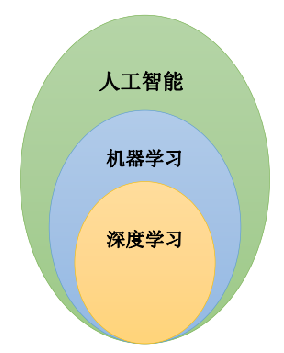
机器学习开发流程
- 数据收集
- 数据预处理(数据清洗和转换)
- 特征提取
- 模型构建
- 模型测试评估
- 投入使用(模型部署与整合)
- 迭代优化

数据收集
数据来源
- 用户访问行为数据-----页面数据
- 业务数据-----后台 Python 和 java
- 外部第三方数据-----接口数据
数据存储
- 需要存储的数据:原始数据、预处理后数据、模型结果
- 存储设施:mysql、HDFS、HBase、Solr、Elasticsearch、Kafka、Redis等
数据收集方式
- Flume & Kafka
机器学习可用公开数据集
在实际工作中,我们可以使用业务数据进行机器学习开发,但是在学习过程中,没有业务数据,此时可以使用公开的数据集进行开发,常用数据集如下:
① http://archive.ics.uci.edu/ml/datasets.html
② https://aws.amazon.com/cn/public-datasets/
③ https://www.kaggle.com/competitions
④ http://www.kdnuggets.com/datasets/index.html
⑤ http://www.sogou.com/labs/resource/list_pingce.php
⑥ https://tianchi.aliyun.com/datalab/index.htm
⑦ http://www.pkbigdata.com/common/cmptIndex.html
数据预处理
指的是将采集的 "数据集"通过 算法,变为满足无监督 、有监督、半监督的学习过程数据!
预处理的操作
- 数据过滤
- 处理数据缺失
- 处理可能的异常、错误或者异常值
- 合并多个数据源数据
- 数据汇总
对数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式,对许多模型类型来说,这种表示就是包含数值数据的向量或者矩阵
- 将类别数据编码成为对应的数值表示(一般使用1-of-k方法)-dumy
- 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)
- 处理图像或者音频数据(像素、声波、音频、振幅等<傅里叶变换>)
- 数值数据转换为类别数据以减少变量的值,比如年龄分段
- 对数值数据进行转换,比如对数转换
- 对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同
- 对现有变量进行组合或转换以生成新特征,比如平均数 (做虚拟变量)不断尝试
模型构建
- 对特定任务最优建模方法的选择或者对特定模型最佳参数的选择。
- 在训练数据集上运行模型(算法)并在测试数据集中测试效果,迭代进行数据模型的修改,这种方式被称为交叉验证(将数据分为训练集和测试集,使用训练集构建模型,并使用测试集评估模型提供修改建议)
- 模型的选择会尽可能多的选择算法进行执行,并比较执行结果
模型测试评估
模型的测试一般以以下几个方面来进行比较,分别是准确率/召回率/精准率/F值
①准确率(Accuracy)=提取出的正确样本数/总样本数
②召回率(Recall)=正确的正例样本数/样本中的正例样本数——覆盖率
③精准率(Precision)=正确的正例样本数/预测为正例的样本数
④F值=PrecisionRecall2 / (Precision+Recall) (即F值为正确率和召回率的调和平均值
附:

投入使用
- 当模型构建好后,将训练好的模型存储到数据库中,方便其它使用模型的应用加载(构建好的模型一般为一个矩阵)
- 模型需要周期性,比如:一个月、一周
模型的监控与反馈
- 当模型一旦投入到实际生产环境中,模型的效果监控是非常重要的,往往需要关注业务效果和用户体验,所以有时候会进行A/B测试
- 模型需要对用户的反馈进行响应操作,即进行模型修改,但是要注意异常反馈信息对模型的影响,故需要进行必要的数据预处理操作

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)