
Pytorch学习——线性回归模型
以下代码编写环境为:编译器PyCharm 2019.2 (Community Edition)pytorch版本为torch1.1.0torchvision0.3.0(可能今后大部分的环境都是这样)以下代码将展示如何构建一个简单的线性回归模型,从中可以看到一些惯用方法,参数的作用,以及编码习惯。第一步首先为了体现拟合效果,我们生成一些假的数据。x = Variable(...
·
以下代码编写环境为:
编译器PyCharm 2019.2 (Community Edition)
pytorch版本为torch 1.1.0
torchvision 0.3.0
(可能今后大部分的环境都是这样)
以下代码将展示如何构建一个简单的线性回归模型,从中可以看到一些惯用方法,参数的作用,以及编码习惯。
- 第一步 生成数据
首先为了体现拟合效果,我们生成一些假的数据。
x = Variable(torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1))
#torch.linspace返回一个1维张量,包含在区间start 和 end 上均匀间隔的steps个点。 输出1维张量的长度为steps。
#torch.unsqueeze增加维度
y = Variable(x * 2 + 0.2 + torch.rand(x.size()))
如果显示出来就是这样:y=2*x+0.2的散点图

- 第二步 构建模型
class LinearRegression(torch.nn.Module):#继承Module
def __init__(self):
super(LinearRegression, self).__init__()#继承父类构造函数
self.linear = torch.nn.Linear(1, 1)#线性输出
def forward(self, x):#前向传播
out = self.linear(x)
return out
第三步 训练模型
在训练之前有一些参数需要确定。
model = LinearRegression()#实例化对象
epoch_n = 1000#迭代次数
learning_rate = 1e-2#学习率
criterion = torch.nn.MSELoss()#损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)#优化函数
前三个没啥好说的。torch.nn.MSELoss()用于计算真实值与预测值之间的均方误差,公式表示为:
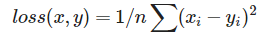
若给参数的size_average赋值为False,则结果不会除以n,即只有差的平方和。
**torch.optim.SGD()**为随机梯度下降。
以上两个参数可以自由选择,但不同的应用场景使用合适的函数的可以大大提高性能。
for epoch in range(epoch_n):
y_pred= model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()#清空上一步参数值
loss.backward()#反向传播
optimizer.step()#更新参数
if epoch % 5 == 0:
# plot and show learning process
matplotlib.pyplot.cla()
matplotlib.pyplot.scatter(x.data.numpy(), y.data.numpy())
matplotlib.pyplot.plot(x.data.numpy(), y_pred.data.numpy(), 'r-',lw=5)
matplotlib.pyplot.text(0.5, 0,'Loss=%.4f' % loss.data.item(), fontdict={'size': 20, 'color': 'red'})
matplotlib.pyplot.pause(0.1)

运行出来应该是动态的,只是我不会做gif
完整的代码如下:
import torch
import torch.nn
import numpy
import matplotlib.pyplot
from torch.autograd import Variable
x = Variable(torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1))
#torch.linspace返回一个1维张量,包含在区间start 和 end 上均匀间隔的steps个点。 输出1维张量的长度为steps。
#torch.unsqueeze增加维度
y = Variable(x * 2 + 0.2 + torch.rand(x.size()))
#matplotlib.pyplot.scatter(x.data.numpy(),y.data.numpy())
#matplotlib.pyplot.show()
class LinearRegression(torch.nn.Module):#继承Module
def __init__(self):
super(LinearRegression, self).__init__()#继承父类构造函数
self.linear = torch.nn.Linear(1, 1)#线性输出
def forward(self, x):#前向传播
out = self.linear(x)
return out
model = LinearRegression()#实例化对象
epoch_n = 1000#迭代次数
learning_rate = 1e-2#学习率
criterion = torch.nn.MSELoss()#损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)#优化函数
for epoch in range(epoch_n):
y_pred= model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()#清空上一步参数值
loss.backward()#反向传播
optimizer.step()#更新参数
if epoch % 5 == 0:
# plot and show learning process
matplotlib.pyplot.cla()
matplotlib.pyplot.scatter(x.data.numpy(), y.data.numpy())
matplotlib.pyplot.plot(x.data.numpy(), y_pred.data.numpy(), 'r-',lw=5)
matplotlib.pyplot.text(0.5, 0,'Loss=%.4f' % loss.data.item(), fontdict={'size': 20, 'color': 'red'})
matplotlib.pyplot.pause(0.1)
本文参考资料链接:pytorch中文网
大佬的博客
本人刚开始接触这个,如有错误请评论留言,或qq:1932859223

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)