机器学习:入门实例
随着科技的发展,机器学习越来越走进我们的日常生活中,在普通人眼里机器学习是一门重算法,数学公式复杂的高门槛职位,笔者也深入研究这块,接下来从一个学习小白的角度讲述一个完整的机器学习案例,方便很多像笔者这样在机器学习门外徘徊很久的爱好者能登堂入室,打开神秘的机器学习大门。一、概念机器学习:专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,以辅助人类决策。机器学习分类:监督学习...
·
随着科技的发展,机器学习越来越走进我们的日常生活中,在普通人眼里机器学习是一门重算法,数学公式复杂的高门槛职位,笔者也深入研究这块,接下来从一个学习小白的角度讲述一个完整的机器学习案例,方便很多像笔者这样在机器学习门外徘徊很久的爱好者能登堂入室,打开神秘的机器学习大门。
一、概念
- 机器学习:专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,以辅助人类决策。
- 机器学习分类:监督学习、非监督学习、半监督学习,他们的区别如下:监督学习就是按照你提供的输入输出关系找到里面的规律;非监督学习是给你一堆数据,你自己通过各种算法去找到规律;半监督学习正好处于两者之间;举个例子来说就是监督学习是按照老师教的去学习,非监督学习是自学,半监督学习是跟同学一块学习,里面的涵义读者朋友可以好好体会下。
二、实践
接下来我们将以一个监督学习的案例打开机器学习之旅。基本的业务是这样的:前提条件是体重是由性别和身高决定的,但具体的关系我们不是很清楚,这个时候我们通过一份既有的性别、身高和体重的关系表,根据这张关系表训练处一个模型,进而可以根据性别、身高来预测体重。
- 首先我们需要处理好数据,也就是我们需要训练的机器学习的每一列数据,避免出现异常、缺失值、数据的数量级弄错等情况。
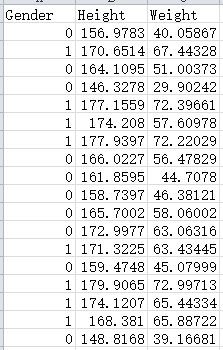
- 根据测试数据选择相应的训练模型,我们这里是通过机器学习中的线性回归作为我们的训练模型,这个过程最主要是选择训练模型,也就是算法,最终预测结果准不准确,主要还是看这个,当然因变量和自变量的选择也很关键,为什么只选择性别和身高呢,而不选择年龄,其实背后还是有很多前期的调研和逻辑论证的。

- 运用我们训练出来的模型预测数据。通过上面一步,我们基本上已经把模型训练出来,接下来是检验模型的时候,我们验证的方法很简单,就是通过模型预测的结果跟表中实际的值去比较。
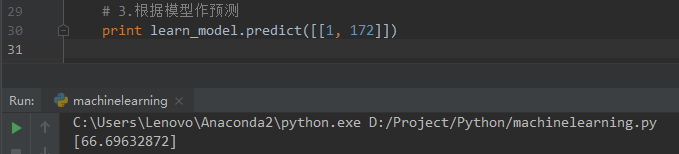
由于我们预测的是男性身高为172厘米的时候体重的范围,为了规避异常数据,我们从表格中取男性[171,173]之间的平均值,通过下面的数据基本上还是挺准确的,表格中数据如下:
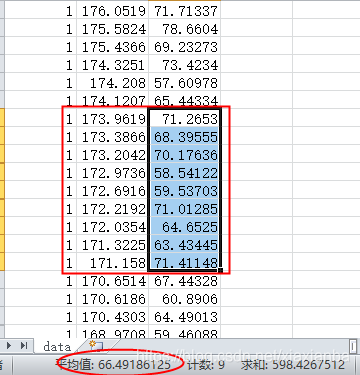
当然通过一次预测是说明不了什么问题的,读者朋友可以多试验几次,通过比较,我们大概知道我们模型预测的准确性如何。
以上项目的源代码和数据生成文件,可以查看文末参考文献github上项目源代码,欢迎读者朋友们互相交流学习。
参考文献
1.Github机器学习项目源代码
2.机器学习中三大学习类别

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)