【机器学习】评价指标PSI
话说这个我研一数据挖掘学过,但是现在一点点也不记得了
话说这个我研一数据挖掘学过,但是现在一点点也不记得了?通常用作模型效果监测
特征稳定性
所谓特征稳定性,就是关注该特征的取值随着时间的推移会不会发生大的波动。
对特征稳定性的关注,一定一定要在建模之前完成,从一开始就避免将那些本身不太稳定的特征选入模型。遗憾的是,很多做模型的同学并没有留意这一点,而是喜欢在特征ready后立刻开始建模,直到模型临近上线,才意识到应该去看看有没有不太稳定的特征,一旦发现有特征稳定性不满足要求,则需要对其进行剔除后重新建模,导致了不必要的重复性劳动。
通常采用PSI(PopulationStability Index,群体稳定性指数)指标评估特征稳定性。计算公式如下:

PSI是对两个日期的特征数据进行计算,可以任选其一作为base集,另一则是test集(也有其他叫法为expected集和actual集)。
下面介绍特征的PSI是如何计算出来的,有了这个,就可以读懂上面的公式了:
• 特征取值等频分段:对这个特征在base集的取值进行等频划分(通常等频分10份即可),用字母i表示第i个分段区间。

。。。。

在上面这个例子中,我对上百个特征计算PSI,流程如下:
• 取20171130分区的数据作为base集,对所有特征通过分箱组件进行特征值等频分段(上述步骤1),分箱之前进行随机采样的目的是减少数据量以加快分箱进程。
• 计算20171130分区与过往六个月分区的特征PSI,这就是PSI组件做的事情,也就是前文所述步骤2~4。
通过这个流程,轻松计算得到了上百个特征跨度1个月~跨度6个月的PSI。通常,如果一个特征跨度6个月的PSI取值小于0.1,那么这个特征被认为是稳定的(当然,也可以根据具体情况适当放宽0.1的标准)。
注意:并非所有PSI值很高的特征都不能用于建模,如果一个特征区分度很好但PSI值不满足预期(比如跨度6个月的PSI大于0.1),但同时,该特征的取值波动性从业务的角度可以解释得通,那么这样的特征用于建模也是可以的。
模型稳定性
相比特征稳定性,模型稳定性涉及的东西比较多,需要根据模型的具体应用方式选择性进行关注。通常,模型PSI是必须关注的一个指标。
- 模型PSI
有了前文对特征PSI的介绍,理解模型PSI就非常简单了。
二分类模型的输出一般都会有一个取值为0~1之间的概率值(记作:prediction_prob),模型PSI监控的就是这个值的稳定性。
将模型产出的prediction_prob理解为一个特征,就可以像计算特征PSI一样计算得到模型PSI了,不同的地方在于,特征PSI一般是对很多特征一起做计算(假如准备了200个特征进行建模,那就是对200个特征计算PSI),而模型PSI通常只是对prediction_prob这一个字段做计算。计算方式同前文所述完全一样,PAI组件的使用也没有任何不同,不再赘述。
- 模型稳定性的其他实践
2.1 消除波动性
对于二分类模型,在实际业务中通常会直接拿着prediction_prob去用。例如,对于某个风险识别场景,根据prediction_prob对用户进行准入或拦截(假如设定阈值为0.6,则prediction_prob小于0.6的用户被拦截,不小于0.6的用户被准入)。
但是会存在一些应用场景对稳定性要求更高。为了消除double型可能带来的波动性,可以将小数映射为整数再使用,我们将这个过程称为Rank。
具体要将0~1的小数值映射到1~10还是1~100亦或是1~1000的整数区间,完全取决于应用场景对这个数值的精细化程度。这样做映射以消除波动性是有道理的,它相当于把一定范围内的波动屏蔽了。例如,某信用风险模型在10月份对用户小C的打分为0.61,在11月份的打分为0.69(假如打分的差异仅仅因为该用户在双11期间疯狂买买买所致,而事实上短暂性的买买买并不应该对用户的信用风险评估造成影响),如果映射为1~10的整数区间后,连续两个月份的打分都是7([0.6, 0.69]整个区间均被映射为7),从而达到屏蔽波动性的目的。
将0~1小数映射到整数区间的做法非常简单:首先对原始小数列求分位数(如果要映射为1~10的得分区间就求十个分位点,如果要映射为1~100的得分区间就求一百个分位点),然后根据各分位点处的取值将原始值分为确定数量的区间(如果要映射为1~10的得分区间就是10个区间,如果要映射为1~100的得分区间就是100个区间),每个区间映射为一个整数值,映射完毕。
2.2 Rank迁移
当把prediction_prob Rank到整数区间后,就有必要对Rank后的结果实施必要的监控了。有两个事情值得去做,其一是对分位点进行按月迁移监控(看分位点有没有随着时间的推移产生波动),其二是对Rank后的整数进行月份间波动监控(看看每连续两个月之间,全量用户得分的波动性)。
计算上文所述指标的目的是为了实施每日监控,一旦出现不符合预期的情况就立刻通知到人。比如:每日定时执行SQL语句来实施监控分析,并将执行结果做成报表以方便查看,等等。
PSI定义
群体稳定性指标PSI(Population Stability Index)是衡量模型的预测值与实际值偏差大小的指标。
PSI = sum((实际占比-预期占比)* ln(实际占比/预期占比))
举例:
比如训练一个logistic回归模型,预测时候会有个概率输出p。
测试集上的输出设定为p1吧,将它从小到大排序后10等分,如0-0.1,0.1-0.2,......。
现在用这个模型去对新的样本进行预测,预测结果叫p2,按p1的区间也划分为10等分。
实际占比就是p2上在各区间的用户占比,预期占比就是p1上各区间的用户占比。
意义就是如果模型很稳定,那么p1和p2上各区间的用户应该是相近的,占比不会变动很大,也就是预测出来的概率不会差距很大。
一般认为PSI小于0.1时候模型稳定性很高,0.1-0.25一般,大于0.25模型稳定性差,建议重做。
PS:除了按概率值大小等距十等分外,还可以对概率排序后按数量十等分,两种方法计算得到的psi可能有所区别但数值相差不大。
PSI计算
PSI:检验变量的稳定性,当一个变量的psi值大于0.0001时,变量不稳定。一个变量,将它的取值按照分位数来分组一下,每一组中测试模型的客户数占比减去训练模型中的客户数占比再乘以这两者相除的对数,就是这一组的稳定性系数psi,然后变量的psi系数就是把这个变量的所有组的psi相加总起来。
计算某个变量的PSI,上面这段话中测试模型和训练模型替换成两个月份即可。
例如,下表是某个变量,以2018年10月为基准,每个月(以2018年9月为例)都和2018年10月去做一个下面表格的运算。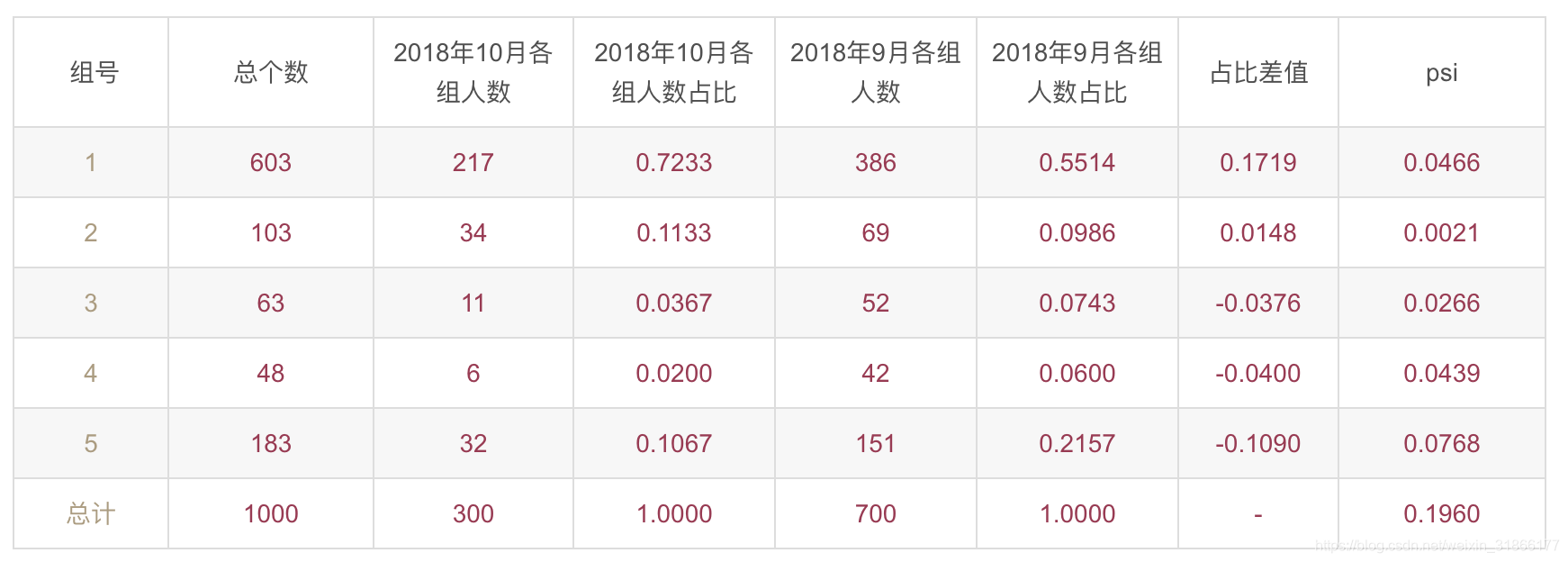
这个表的计算是错误的:
10月组号1的占比:217除以那一列的最后一个数300
日期新鲜的作为base,那么10月是base,使用test-base,也就是说9月的占比-10的占比。
第一个0.0466的计算方法:
= (0.7233-0.5514)*LN(0.7233/0.5514)
下面几个数值的计算方法是相同的,最后的0.1960是把上面的几个加起来。
可以把每个月份依次和2018年10月去对比求一个PSI值出来。
如果PSI值是0.1,只要有一个月对比得到的PSI值大于0.1,就要把这个变量踢掉。比如,从上表的结果来看,这个变量就应该被踢掉了。
PSI代码
def calculate_psi(expected, actual, buckets=10): # test, base
def psi(expected_array, actual_array, buckets):
def scale_range(input, min, max):
input += -(np.min(input))
input /= np.max(input) / (max - min)
input += min
return input
# 按照概率值分10段
breakpoints = np.arange(0, buckets + 1) / (buckets) * 100
breakpoints = scale_range(breakpoints, np.min(expected_array), np.max(expected_array))
expected_percents = np.histogram(expected_array, breakpoints)[0] / len(expected_array)
# print(expected_percents)
actual_percents = np.histogram(actual_array, breakpoints)[0] / len(actual_array)
def sub_psi(test, base): # test,base
if base == 0:
base = 0.0001
if test == 0:
test = 0.0001
value = (test - base) * np.log(test / base)
return(value)
psi_value = np.sum(sub_psi(expected_percents[i], actual_percents[i]) for i in range(0, len(expected_percents)))
return(psi_value)
if len(expected.shape) == 1:
psi_values = np.empty(len(expected.shape))
else:
psi_values = np.empty(expected.shape[0])
for i in range(0, len(psi_values)):
if len(psi_values) == 1:
psi_values = psi(expected, actual, buckets)
else:
psi_values[i] = psi(expected[:,i], actual[:,i], buckets)
return(psi_values)
四分位数
四分位数(Quartile)是统计学中分位数的一种,即把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。
1)第一四分位数(Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字;
2)第二四分位数(Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字;
3)第三四分位数(Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距。
参考:
https://blog.csdn.net/june1122/article/details/83278288
携程今天打电话让我去实习了!cv岗!!!当时面试的时候太傻了 说自己暑期才能来 所以通知下的这么晚 现在新的暑期实习都开始了!!!不好走了!!!leader说秋招会再联系我!!!他会再联系我吗????

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容








所有评论(0)