
linux下处理实时日志生成另一个实时日志
一.背景介绍1.知识点写这篇blog,主要有下面几个知识点想介绍:curl获取http相应内容;shell中执行php文件;php中执行shell命令(通过exec函数);php实现tail -f命令;包含空格的参数如何作为参数传递(用双引号括起来)。2.业务流程这篇blog的背景是读取"/data3/im-log/nginx.im.imp.current/
一.背景介绍
1.知识点
写这篇blog,主要有下面几个知识点想介绍:
curl获取http相应内容;
shell中执行php文件;
php中执行shell命令(通过exec函数);
php实现tail -f命令;
包含空格的参数如何作为参数传递(用双引号括起来)。
2.业务流程
这篇blog的背景是读取"/data3/im-log/nginx.im.imp.current/nginx.im.imp.current_current"这个实时日志,生成招聘会所需的实时日志。
业务流程如下:
(1)从http://bj.baidu.com/jobfairs/jobfairs_im_port.php?action=getIms获取企业和IM客户端id的关系。
响应的格式如下:
{"status":1,"ret":{"company_id":{“im_accout”:[im_id],"company_name":[]}}}
获取到的数据如下:
{"status":1,"ret":{"2028107":{"im_account":["31669394","50000098"],"name":["baidu"]},"2028098":{"im_account":["50029298","50000098","31669376","31669394","50006271"],"name":["sogou"]}},"msg":""}
这里碰到的第一个问题是我开发所在的环境和http://bj.baidu.com不在同一个网段内,该url服务所在的IP为10.3.255.201,此时我需要进行hosts映射,这样当我访问http://bj.baidu.com/jobfairs/jobfairs_im_port.php?action=getIms时,便相当于我在访问了http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms。
但是我们一定有一个疑问,为什么我们不直接使用http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms来进行访问,答案是我们需要通过url获取到用户的城市,即http://bj.baidu.com/jobfairs/jobfairs_im_port.php?action=getIms,这里面包含bj.baidu.com,包含用户的城市信息bj。
解决方法是通过curl对url和host进行映射:
curl -H "Host: bj.ganji.com" http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms
参考链接:http://blog.csdn.net/lianxiang_biancheng/article/details/7575370 中的curl命令的使用。
(2)其次,如果这条日志记录中fromUserId或者toUserId包含某个企业的IM客户端id,则说明这条消息属于这个企业;
(3)最后,生成所需格式的日志,日志的字段格式如下:
时间 企业Id 企业名称 企业IM的id 应聘者IM的id 谁发送的信息(0:企业,1:应聘者) 消息内容
二.采用了三种实现方式
1.第一种:shell读取每一行记录传递给php进行匹配并输出
(1)start.sh是启动文件,如下:#!/bin/sh
#执行前清除所有该进程
pids=`ps aux | grep jobfairs | grep -v "grep" | awk '{print $2}'`
if [ "$pids" != "" ];then
echo $pids
kill -9 $pids
fi
sh jobfairs.sh >> /home/baidu/log/jobfairs.log
(2)jobfairs.sh是获取http内容,读取实时日志并每2分钟重新请求的实现,如下:
#!/bin/sh
logfile="/data3/im-log/nginx.im.imp.current/nginx.im.imp.current_current"
hours=`date +%H`
start_time=`date +%s`
#17点后停止运行程序
while [ $hours -lt 17 ]
do
res=`curl -s -H "Host: bj.baidu.com" http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms`
#echo $res
len=${#res}
if [ $len = 0 ]; then
echo "Failed! Request error!"
exit
fi
status=`echo $res | sed -e 's/.*status"://' -e 's/,.*//'`
if [ $status != 1 ]; then
echo "Failed! Request stauts:"$status
exit
fi
ret=`echo $res | sed -e 's/.*ret"://' -e 's/,"msg.*//'`
#ret='{"2028097":{"im_account":["2875001357","197823104","3032631861","197305863"],"name":["8\u811a\u732b\u521b\u65b0\u79d1\u6280\u6709\u9650\u516c\u53f8\uff08\u4e60\u5927\u7237\u6dae\u8089\u5bf9\u976210000\u7c73\u7684\u79d1\u6280\u516c\u53f8\uff09"]},"2028098":{"im_account":["3658247660","192683241","197488883","108963206","197305001"],"name":["9\u811a\u732b\u521b\u65b0\u79d1\u6280\u6709\u9650\u516c\u53f8"]}}';
tail -f $logfile | grep sendMsgOk | grep "spamReasons=\[\]" | awk -F"\t" '{
printf("%s\t%s\t%s\t%s\n",$1,$3,$4,$11);
}' | while read line
do
/usr/local/webserver/php/bin/php jobfairs.php $ret "$line"
#120s后停止生成日志,重新执行http请求去获取公司相关信息
end_time=`date +%s`
if [ $(expr $end_time - $start_time) -ge 120 ]; then
#echo `date +%T`" "`date +%D`
#echo "120s is done!"
break
fi
done
start_time=`date +%s`
hours=`date +%H`
done
这里的场景是这样的:由于一行记录各个字段是以制表符分隔的,其中有一个字段msgContent是消息内容,而消息中经常包含空格,而php接受外来参数默认是以空格分隔的,这样如果将$line作为参数进行传递,就导致msgContent被分隔为了好几个字段。那我们如何解决这个问题呢,答案就是通过加双引号(即将$line变为"$line"),将一行记录作为一个整体字符串传入即可,然后php接收到这个字符串后,再通过explode("\t",$line)进行分隔出各个字段。如下所示:
/usr/local/webserver/php/bin/php jobfairs.php $ret "$line"
(3)jobfairs.php是对实时日志的每一行进行匹配并输出为IM的log格式:
<?php
$ret = $_SERVER["argv"][1];
$arr = json_decode($ret, true);//将json字符串解码成数组
foreach ($arr as $key => $value) {
$name = $value["name"][0];//企业名称
foreach ($value["im_account"] as $v) { //企业对应的叮咚id
$userId[$v] = $key;
$compName[$v] = $name;
//echo $key ."\t" . $v ."\t" . $name ."\n";
}
}
$line = $_SERVER["argv"][2];//获取日志的一条记录
$logArr = explode("\t", $line);
//echo $line . "\n";
//获取各个字段
$time = $logArr[0];
$fromUserId = $logArr[1];
$toUserId = $logArr[2];
$msgContent = $logArr[3];
$fuiArr = explode('=', $fromUserId);
$tuiArr = explode('=', $toUserId);
$fui = $fuiArr[1];
$tui = $tuiArr[1];
$output = $time . "\t";
if(isset($userId[$fui])) { //fromUserId是某个企业的叮咚id
//echo $line . "\n";
$output .= "companyId=$userId[$fui]\t";
$output .= "companyName=$compName[$fui]\t";
$output .= "companyDingdongId=$fui\t";
$output .= "personalDingdongId=$tui\t";
$output .= "whoSend=0\t";
$output .= $msgContent;
echo $output . "\n";
} else if(isset($userId[$tui])) { //toUserId是某个企业的叮咚id
//echo $line . "\n";
$output .= "companyId=$userId[$tui]\t";
$output .= "companyName=$compName[$tui]\t";
$output .= "companyDingdongId=$tui\t";
$output .= "personalDingdongId=$fui\t";
$output .= "whoSend=1\t";
$output .= $msgContent;
echo $output . "\n";
}
?>
2.第二种:php执行shell命令并将输出结果进行匹配
注:该方法不能生成实时日志,因为tail -f命令是实时获取更新命令,php无法获取其返回结果。所以该方法仅用于读取一段固定文本并进行处理。
这里通过exec执行tail -n1000这个shell命令,获取到最后1000行数据然后再进行处理。同时,这里还调用了php中curl模块获取http响应内容。该文件名为jobfairs2.php。
<?php
//error_reporting(E_ALL & ~E_NOTICE);
$host = array("Host: bj.baidu.com");
$data = 'user=xxx&qq=xxx&id=xxx&post=xxx';
$url = 'http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms';
$res = curl_post($host, $data, $url);
$arr = json_decode($res, true);
$status = $arr["status"];
if ($status != 1) {
echo "Request Failed!";
exit;
}
//获取返回的企业信息
$ret = $arr["ret"];
foreach ($ret as $key => $value) {
$name = $value["name"][0];
//将IM的Id和企业id进行hash映射
foreach ($value["im_account"] as $v) {
$userId[$v] = $key;
$compName[$v] = $name;
}
}
$logfile = "/data3/im-log/nginx.im.imp.current/nginx.im.imp.current_current";
//tail -n1000获取最后1000行记录,并保存到$log变量中
$shell = "tail -n 1000 $logfile | grep sendMsgOk | grep 'spamReasons=\[\]' | ";
$shell .= "awk -F'\t' '{print $1,$3,$4,$11;}'";
exec($shell, $log); //将执行的shell结果保存到数组中
//处理每一行记录
foreach ($log as $line) {
//通过正则表达式匹配出所需要的字段
$flag = preg_match("/([0-9]+:[0-9]+:[0-9]+).*fromUserId=([0-9]+).*toUserId=([0-9]+).*msgContent=(.*)/", $line, $matches);
if( $flag == 0 ){//匹配失败
continue;
}
//echo $line . "\n";
$time = $matches[1];
$fui = $matches[2];
$tui = $matches[3];
$msgContent = $matches[4];
//查看fromUserId和toUserId有没有对应的公司
$output = $time . "\t";
//通过hash判断IM的id是否属于某个企业
if(isset($userId[$fui])){
//echo $line . "\n";
$output .= "companyId=$userId[$fui]\t";
$output .= "companyName=$compName[$fui]\t";
$output .= "companyDingdongId=$fui\t";
$output .= "personalDingdongId=$tui\t";
$output .= "whoSend=0\t";
$output .= $msgContent;
echo $output . "\n";
}else if(isset($userId[$tui])){
//echo $line . "\n";
$output .= "companyId=$userId[$tui]\t";
$output .= "companyName=$compName[$tui]\t";
$output .= "companyDingdongId=$tui\t";
$output .= "personalDingdongId=$fui\t";
$output .= "whoSend=1\t";
$output .= $msgContent;
echo $output . "\n";
}
}
/*
* 提交请求
* @param $host array 需要配置的域名 array("Host: bj.ganji.com");
* @param $data string 需要提交的数据 'user=xxx&qq=xxx&id=xxx&post=xxx'....
* @param $url string 要提交的url 'http://192.168.1.12/xxx/xxx/api/';
*/
function curl_post($host,$data,$url){
$ch = curl_init();
$res= curl_setopt($ch, CURLOPT_URL,$url);
//var_dump($res);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt ($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch,CURLOPT_HTTPHEADER,$host);
$result = curl_exec($ch);
curl_close($ch);
if ($result == NULL) {
return 0;
}
return $result;
}
?>
3.第三种:php自己实现tail -f命令来实时读取日志文件
该文件名为jobfairs3.php。这里是php通过文件偏移量实现tail -f命令的效果。但是不适用于读取每次都动态指向不同文件。同时,这里还调用了php中curl模块获取http响应内容。
<?php
//error_reporting(E_ALL & ~E_NOTICE);
//php通过curl获取http相应的内容
$host = array("Host: bj.ganji.com");
$data = 'user=xxx&qq=xxx&id=xxx&post=xxx';
$url = 'http://10.3.255.201/jobfairs/jobfairs_im_port.php?action=getIms';
$res = curl_post($host, $data, $url);
//将json字符串解码成数组
$arr = json_decode($res, true);
$status = $arr["status"];
if ($status != 1) {
echo "Request Failed!";
exit;
}
//获取返回的企业信息
$ret = $arr["ret"];
foreach ($ret as $key => $value) {
$name = $value["name"][0];
//将IM的Id和企业id进行hash映射
foreach ($value["im_account"] as $v) {
$userId[$v] = $key;
$compName[$v] = $name;
}
}
$logfile = "/data3/im-log/nginx.im.imp.current/nginx.im.imp.current_current";
tail_f($logfile, $userId);
//通过php实现shell的tail -f命令
function tail_f($logfile, $userId) {
$size = filesize($logfile);
$ch = fopen($logfile, 'r');
$i = 0;
while (1) {
clearstatcache();
$tmp_size = filesize($logfile);
if (0 < ($len = $tmp_size - $size)) {
$i = 0;
fseek($ch, -($len -1), SEEK_END);
$content = fread($ch, $len);
$lineArr = explode("\n", $content);
foreach ($lineArr as $line) {
//echo $line . "\n";
if (preg_match("/sendMsgOk.*spamReasons=\[\]/", $line)) {
matchCompany($line, $userId);
}
}
} else {
$i++;
if ($i > 60) {
echo PHP_EOL . 'The file in 60s without change,So exit!';
break;
}
sleep(1);
continue;
}
$size = $tmp_size;
}
fclose($ch);
}
//对一行记录判断是否在企业信息中,如果在,则输出组合后的记录
function matchCompany($line, $userId) {
$flag = preg_match("/([0-9]+:[0-9]+:[0-9]+).*fromUserId=([0-9]+).*toUserId=([0-9]+).*msgContent=(.*)\tchannel=.*/", $line, $matches);
if( $flag == 0 ){
return;
}
//echo $matches[0] ."\t" .$matches[1] . "\t" . $matches[2] . "\t" . $matches[3] . "\t" . $matches[4] . "\n";
$time = $matches[1];
$fromUserId = $matches[2];
$toUserId = $matches[3];
$msgContent = $matches[4];
//查看fromUserId和toUserId有没有对应的公司
$output = $time . "\t";
//如果IM的id属于某个企业
if(isset($userId[$fromUserId])){
//echo $line . "\n";
$output .= "companyId=$userId[$fui]\t";
$output .= "companyName=$compName[$fui]\t";
$output .= "companyDingdongId=$fui\t";
$output .= "personalDingdongId=$tui\t";
$output .= "whoSend=0\t";
$output .= $msgContent;
echo $output . "\n";
}else if(isset($userId[$toUserId])){
//echo $line . "\n";
$output .= "companyId=$userId[$tui]\t";
$output .= "companyName=$compName[$tui]\t";
$output .= "companyDingdongId=$tui\t";
$output .= "personalDingdongId=$fui\t";
$output .= "whoSend=1\t";
$output .= $msgContent;
echo $output . "\n";
}
}
/*
* 提交请求
* @param $host array 需要配置的域名 array("Host: bj.ganji.com");
* @param $data string 需要提交的数据 'user=xxx&qq=xxx&id=xxx&post=xxx'....
* @param $url string 要提交的url 'http://192.168.1.12/xxx/xxx/api/';
*/
function curl_post($host,$data,$url){
$ch = curl_init();
$res= curl_setopt($ch, CURLOPT_URL,$url);
//var_dump($res);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt ($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch,CURLOPT_HTTPHEADER,$host);
$result = curl_exec($ch);
curl_close($ch);
if ($result == NULL) {
return 0;
}
return $result;
}
?>
三.总结
本文最终采取了第一种方式来实现,最后还需要将start.sh加入到crontab -e中,加入如下一条记录:
30 9 * * * cd /home/baidu/zhaolincheung/JobFairs; sh start.sh
第二种方式不适合这里的业务,因为需要实时读取日志,但是php的exec无法返回tail -f的读取结果。
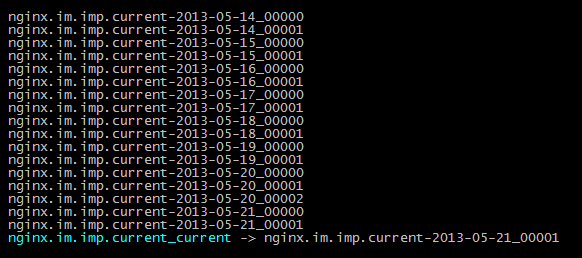
第三种方式也可以实现,仅适用读取一个固定的动态增长的日志文件。但是这里的日志文件nginx.im.imp.current_current是一个软连接,它会动态地指向不同的文件,如下图所示:
这样自己实现tail -f的话,由于文件会改变,导致文件的动态偏移量有可能是不同的文件的,导致读取的日志不对。所以这种方法也没有采用。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)