
数据库系统——关系型数据在磁盘上的存储布局
关系型数据在磁盘上的存储布局1.基于page的heap fileHeap file是保存page数据的一种数据结构。从功能上来说,Heap file类似于内存数据结构中的链表。它可以作为通用数据项的一种无序容器。Heap file和链表结构类似的地方:--高效的增加(append)功能--支持大规模顺序扫描--不支持随机访问下面是Heap file自有的一些特性:-
关系型数据在磁盘上的存储布局
1.基于page的heap file
Heap file是保存page数据的一种数据结构。从功能上来说,Heap file类似于内存数据结构中的链表。它可以作为通用数据项的一种无序容器。
Heap file和链表结构类似的地方:
--高效的增加(append)功能
--支持大规模顺序扫描
--不支持随机访问
下面是Heap file自有的一些特性:
--数据保存在二级存储体(disk)中:Heapfile主要被设计用来高效存储大数据量,数据量的大小只受存储体容量限制;
--Heapfile可以跨越多个磁盘空间或机器:heapfile可以用大地址结构去标识多个磁盘,甚至于多个网络;
--数据被组织成页;
--页可以部分为空(并不要求每个page必须装满);
页面可以被分割在某个存储体的不同的物理区域,也可以分布在不同的存储体上,甚至是不同的网络节点中。我们可以简单假设每一个page都有一个唯一的地址标识符PageAddress,并且操作系统可以根据PageAddress为我们定位该Page。
下面是heap file的一些主要的接口:
class HeapFile
{
PageIterator scan();
PageAddress allocate();
void deallocate(PageAddress);
Page read(PageAddress);
void write(PageAddress, Page);
PageAddress find_free(int minsize);
};
class PageIterator
{
Page first();
boolean hasNext();
Page next();
};
1.1 基于链表的heap file实现
一种简单的基于链表的heap file实现方案的磁盘结构布局:
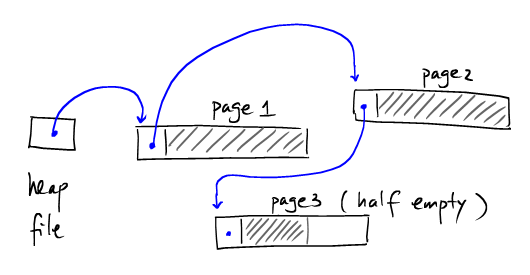
但是这种方案存在这样的问题:HeapFile::find_free(int minsize)的开销比较大。如上图,我们要定位存在剩余空间的page(page3),那么我们必须从开始遍历很多page(page1和page2)。我们发现,这时的遍历I/O开销是这个数据存储区,显然这样I/O开销就太高。
1.2 基于索引的heap file实现
一个简单的,但是比较高效的heap file的实现是:用少量的block去存放所有page的地址索引和它们剩余的空间大小。
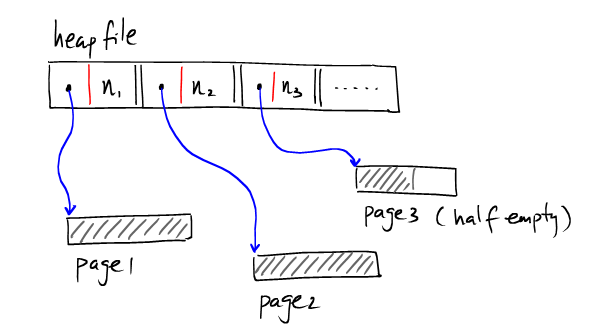
从page1到page2都是满的,它们的剩余空间大小n1和n2都为零。我们寻找一个存在剩余空间的page仍然需要遍历索引,但是这时我们的开销仅仅是一个磁盘的I/O。
如果索引page是多个的话,那么我们可以采用链表的形式存储page索引,如下图所示
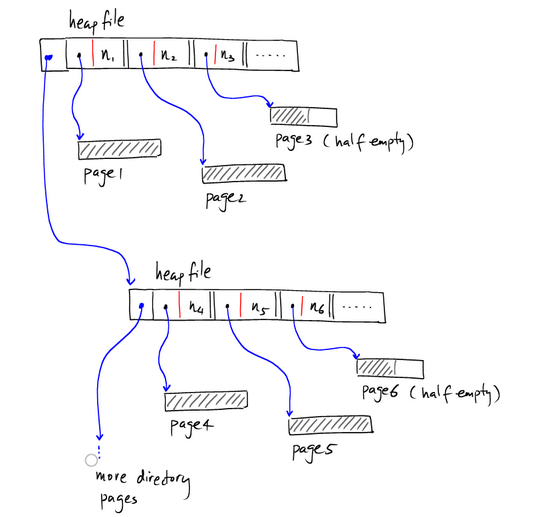
我们假设有如下参数:
Page size:16K
Page address size:32bits
那么,每个索引项(即是索引Page的记录项)的大小:
Bits for free space+Bits for page addresslog2(16 KB)+32=17+32 bits=49 bits
则,每个索引page能索引的数据大小为:
16 KB/49 bits=2674 pages=42 MB
2.数据的序列化
我们稍稍从磁盘整体布局离题讨论一下如何从tuple record转化成字节数组。
2.1定长record的序列化
对于一些关系型数据,所有的record必须具有相同的长度。例如,思考一下用下面的SQL定义的关系型schema:
CREATE TABLE Person1 (
name CHAR(100) NOT NULL,
age INTEGER NOT NULL,
birthdate DATETIME NOT NULL
)
所有的记录都具有一样的字节数:
100 * sizeof(CHAR) + sizeof(INTEGER) + sizeof(DATETIME)
那么定长record可以采用如下的序列化方式:
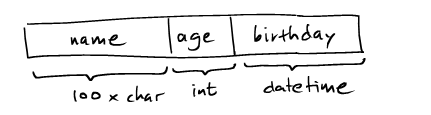
从schema上来说,我们可以检查每个字段的大小,从而将字节数组解码成不同的字段。
2.2变长record的序列化
假设我们改变上面Person1表的schema定义,使name可以是不超过1024个字符。Schema如下:
CREATE TABLE Person2 (
name VARCHAR(1024) NOT NULL,
age INTEGER NOT NULL,
birthdate DATETIME
)
上面table的record是边长的是由于:
--name字段是一个变长的字符串;
--birthdate可以为NULL;
变长record的序列化的关键是字段边界的界定。一种比较流行的方法是在record的首部保存字段边界的offset。
Person2的record的编排方式如下:
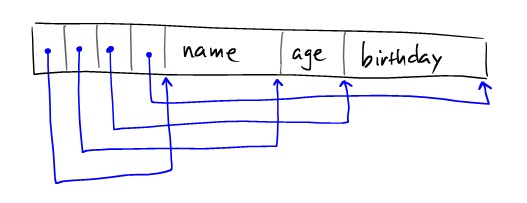
Note:我们在首部设置4个整型去存储三个字段的四个边界offset。
上面的编排方式很自然的提供一种NULL字段的编排方式--可以标识该字段的值为NULL,如下图:
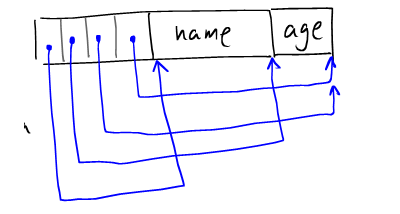
第三个offset和第四个offset指向同一个位置,那么就表明第三个字段的大小是零,即是一个NULL值。
3 Page Format
现在我们要具体的描述一下数据在page中是如何编排的。
我们做一个简单化的设想:每个page中的tuple record具有相同的schema。
这种简单化的设想有两个重要的结果:
1. 每个关系表至少占用一个page;
2. 每个page中保存的要么是定长的数据,要么是变长数据;
在Page编排格式中有两个变量:一个是为了定长数据,一个是为了变长数据。对于DMS(Database Management System)来说,Page Format必须具有如下的特性:
1.高效利用磁盘空间;
2.支持scan、insert、delete和modify record的功能,并且要求高效和尽量少的I/O;
3.有一个高效的为每一个record分配唯一ID的方式。并且某个record的ID不会由于数据库的modify、insert、delete而改变;
4.每个record的大小不能超过一个Page的有效存储大小,这个特性在以后的章节将会被放宽。
3.1基于定长record的page format
在Page中组织编排定长record相对来说是比较容易的。常用的方法是将一个Page的初始数据段分割成大小相等的M个slot,每个slot装载一个record。Page的最后一段存储着一个整数M和标识对应的slot是否为空的M bit。
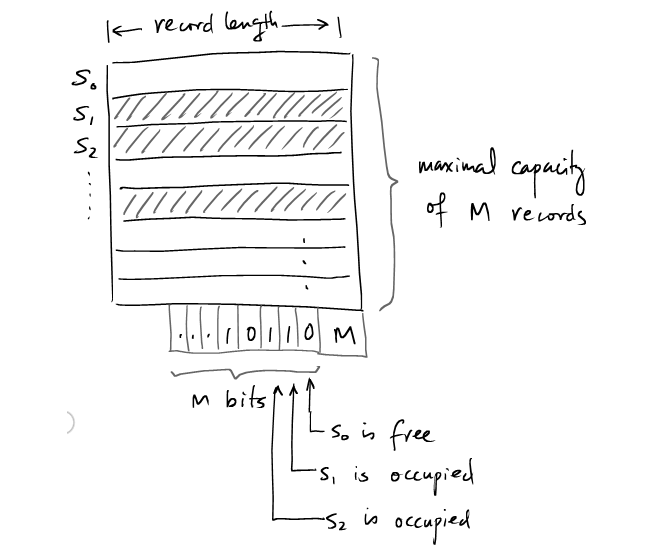
定长record的Page的维护也非常简单。
Record ID
record r的Record ID可以是这种结构<pid(P), offset(r)>。
Record ID的一个重要的特性是它的分配是持久的——它不因数据库的改变而受到影响。甚至,Record ID作为数据库定位该record在物理磁盘上位置的依据,是完全能胜任的。
创建一个新的Record
将record r插入到page P中,
1.将page P中的最后sizeof(int)个字节读出来作为M,
2.然后在倒着遍历M bits,
3.如果所有M bit都是1,那就表明page P没有多余的空间存储record r,
4.如果K-th bit是0(当然这个K是离结尾最近的那个为0的),那么,record r可以存储在P[nk:n(k+1)]的位置,其中n=sizeof(r),最后将K-th bit置为1.
修改record
修改一个record,我们可以很简单的用该record的新值去覆盖旧的值。这是由于都是定长数据,它的边界不会因为record的值而受到影响。
删除record
删除一个record,就将对应的那个bit从1改变成0即可。
3.2.变长record的Page Format
在一个Page中保存变长数据以及对该数据的维护相对来说都是比较困难的,因为:
1.record的边界以及字段的边界都依赖于数据内容(即是record的值);
2.Record被修改时,record的大小可能会改变,这就造成物理上对该record的重新定位。这就需要一个非常高效的在一个Page内的或是多个Page的record迁移方法;
3.如果Record ID需要持久,那么尽管该record已经被迁移,那么该record被分配到的Record ID也不能改变。
一个有效的设计方法是维护一个Page首部去跟踪free空间和record的索引。
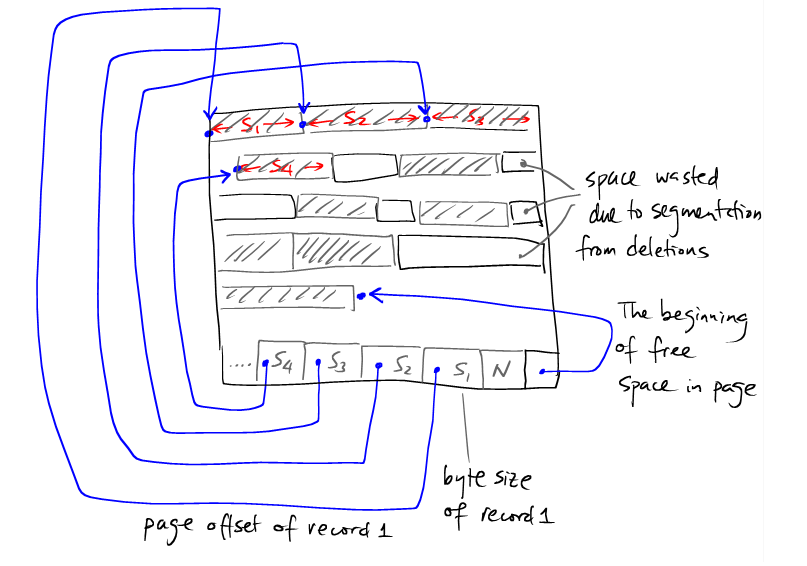
Record ID的分配
Record ID是由page ID和目录索引组成的。
创建一个新的record
将record r插入到page P中,
1.确保page P中的剩余空间能存放sizeof(r)的数据和(sizeof(offset)+sizeof(int))的目录索引;
2.将r从剩余空间的开始写入;
3.修改目录索引信息:offset和record size;
4.修改空余空间指针的指向。
删除record
将record i从page P中删除:
1.如果i是最后一个record,我们只需将最后一个目录索引删除,在修改空余空间的指向即可;
2.如果i不是最后一个,我们只需将该record对应的目录索引的offset设置为-1即可。
修改record
假设r是一个旧的值,r’是一个新的值。i是r的索引。
如果|r’|<=|r|,那么就将新的值写的offset(i),修改对应的目录索引的size:sizeof(r’)。
如果|r|<=|r’|:
--如果该record所在的page P还有空余的空间能够存放r’,那么
1.将r’写入page P;
2.修改offset(i),更新到r’存储的位置;
3.更新空余空间的指针。
--如果剩余空间不足以存放r’,那么我们就尝试压缩page P(由于删除操作使得page中有很多空洞,所以可以压缩)。压缩后,如果存在足够的空间存放r’,那么就按上面的顺序增加r’;如果还是没有足够的空间存放r’,那么:
1.申请一个新page,将r’写入到新page中。由于r’在不同的page中,所以它有一个不同的Record ID;
2.将r’的Record ID写入到r中去。
4.处理比较大的record
在这个部分,我们专注讨论一下一个record保存在多个page中的方法。
4.1.record跨page保存的动因
一个明显的动因是当一个record的大小超出了page size。record域被设计用来承载一个大的对象,比如:文件,多媒体数据等等。几乎可以肯定的是,BLOB记录必须跨越多个page。
另一个动因是避免空间的浪费。思考一下,在上面介绍的定长record的存储中,如果record的大小略大于1/2page size,那么我们的一个page只能存放一个record,我们浪费几乎浪费了一半的存储空间。在这种情况下,我们采用record跨page存储将获益匪浅。
4.2.Spanned records(跨page的record)
--如果一个record存储在多个page中,那么我们就说它spanned。否则,unspanned。
--Spanned record分别保存在不同的record fragment中。每个片段在一个page中。
--每个record必须用1 bit去标识该record是否spanned。
--每一个record fragment都需要保存下一个record fragment的地址,使得众多的record fragment能够串联起来。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)