
机器学习(python)-Fashion Mnist分类模型构建
三种机器学习方法和使用CNN训练FashionMNIST的性能比较,三种机器学习方法分别为:随机森林、KNN、朴素贝叶斯。完整实验代码可在https://github.com/Ryanlzz/fashion-mnist-train查看一、数据准备1.数据来源根据Fashion Mnist论文给出的网址下载数据集:https://github.com/zalandoresearc...
三种机器学习方法和使用CNN训练FashionMNIST的性能比较,三种机器学习方法分别为:随机森林、KNN、朴素贝叶斯。
完整实验代码可在https://github.com/Ryanlzz/fashion-mnist-train查看
一、数据准备
1.数据来源
根据Fashion Mnist论文给出的网址下载数据集:
https://github.com/zalandoresearch/fashion-mnist
2.数据背景
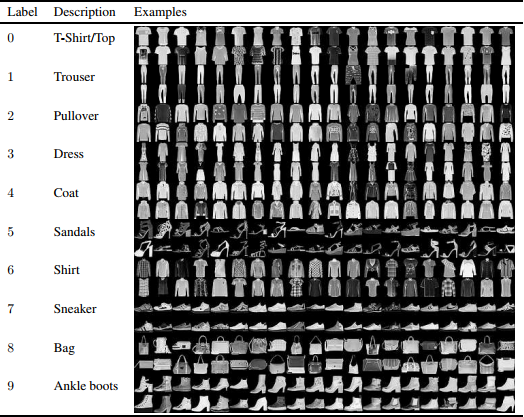
FashionMNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。FashionMNIST 的大小、格式和训练集 / 测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。
经典的MNIST数据集包含了大量的手写数字。十几年来,来自机器学习、机器视觉、人工智能、深度学习领域的研究员们把这个数据集作为衡量算法的基准之一。我们会在很多的会议,期刊的论文中发现这个数据集的身影。实际上,MNIST数据集已经成为算法作者的必测的数据集之一。有人曾调侃道:“如果一个算法在MNIST不work, 那么它就根本没法用;而如果它在MNIST上work, 它在其他数据上也可能不work!”
制作这个数据集的目的就是取代MNIST,作为机器学习算法良好的“检测器”,用以评估各种机器学习算法。为什么不用MNIST了呢? 因为MNIST就现在的机器学习算法来说,是比较好分的,很多机器学习算法轻轻松松可以达到99%,因此无法区分出各类机器学习算法的优劣。
为了和MNIST兼容,Fashion-MNIST 与MNIST的格式,类别,数据量,train和test的划分,完全一致。
3.数据的样本和特征
其中训练集包含60000个样例,测试集包含10000个样例,分为10类,其中的样本都来自日常穿着的衣裤鞋包,每个都是28×28的灰度图像,其中总共有10类标签,每张图像都有各自的标签。
二、被测试的机器方法介绍
1.随机森林
1)基本原理
随机森林就是用随机的方式建立一个森林,在森林里有很多决策树组成,并且每一棵决策树之间是没有关联的。当有一个新样本的时候,我们让森林的每一棵决策树分别进行判断,看看这个样本属于哪一类,然后用投票的方式,哪一类被选择的多,作为最终的分类结果。在回归问题中,随机森林输出所有决策树输出的平均值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YZiW9O7b-1607663807871)(https://s3.ax1x.com/2020/12/11/rkTQuF.png)]
2)主要参数设置及其意义
n_estimators:森林(决策)树的数目。n_estimators太小,容易过拟合,n_estimators太大,又容易欠拟合,一般选择一个适中的数值。(默认值为10)。
max_depth:树的最大深度。数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。 (默认值 None)
min_samples_split:分割内部节点所需的最少样本数量。值越大,决策树越简单,越不容易过拟合。(默认值 2)
min_samples_leaf:叶子节点上包含的样本最小值。值越大,叶子节点越容易被被剪枝,决策树越简单,越不容易过拟合。(默认值 1)
max_features:寻求最佳分割时的考虑的特征数量,即特征数达到多大时进行分割。值越大,模型学习能学习到的信息越多,越容易过拟合。(默认值 auto)
2.KNN
1)基本原理
KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
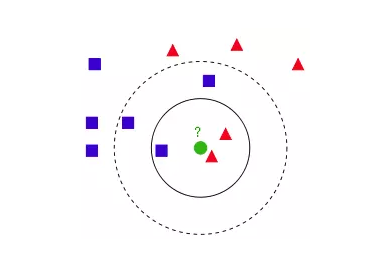
2)算法描述
1 计算测试数据与各个训练数据之间的距离;
2 按照距离的递增关系进行排序;
3 选取距离最小的K个点;
4 确定前K个点所在类别的出现频率;
5 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
3)距离计算:欧氏距离
对于距离的度量,有很多的距离度量方式,但是最常用的是欧式距离,即对于两个n维向量x和y,两者的欧式距离定义为
d ( p , q ) = d ( q , p ) = ( q 1 − p 1 ) 2 + ( q 2 − p 2 ) 2 + ⋯ + ( q n − p n ) 2 = ∑ i = 1 n ( q i − p i ) 2 \begin{aligned} \mathrm{d}(\mathbf{p}, \mathbf{q})=\mathrm{d}(\mathbf{q}, \mathbf{p}) &=\sqrt{\left(q_{1}-p_{1}\right)^{2}+\left(q_{2}-p_{2}\right)^{2}+\cdots+\left(q_{n}-p_{n}\right)^{2}} \\ &=\sqrt{\sum_{i=1}^{n}\left(q_{i}-p_{i}\right)^{2}} \end{aligned} d(p,q)=d(q,p)=(q1−p1)2+(q2−p2)2+⋯+(qn−pn)2=i=1∑n(qi−pi)2
4)主要参数设置及其意义
n_neighbors:k-NN的k值,选取最近的k个点。(默认为5)
weights:参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。(默认为uniform)
algorithm:快速k近邻搜索算法,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。(默认为auto)
leaf_size:构造kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。(默认是30)
metric:用于距离度量,也就是p=2的欧氏距离(欧几里德度量)。(默认度量是minkowski)
3.朴素贝叶斯
1)基本原理
朴素贝叶斯分类是一种十分简单的分类算法:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A | B)=\frac{P(B | A) P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)
P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
2)主要参数设置及其意义
alpha:浮点型可选参数,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑。(默认为1.0)
fit_prior:布尔型可选参数。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。(默认为True)
class_prior:可选参数。(默认为None)
4.卷积神经网络
1)基本原理
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。

卷积层,用来学习输入数据的特征表征。卷积层由很多的卷积核(convolutional kernel)组成,卷积核用来计算不同的feature map;
激励函数(activation function)给CNN卷积神经网络引入了非线性,常用的有sigmoid 、tanh、 ReLU函数;
池化层降低卷积层输出的特征向量,同时改善结果(使结构不容易出现过拟合),典型应用有average pooling 和 max pooling;
全连接层将卷积层和Pooling 层堆叠起来以后,就能够形成一层或多层全连接层,这样就能够实现高阶的推理能力
2)主要参数设置及其意义
Epoch(迭代数): 1个epoch等于使用训练集中的全部样本训练一次
lr(learnling rate):控制梯度下降的步长(默认 0.001)
batchsize:每批数据量的大小。也就是一次(1 个iteration)一起训练batchsize个样本,计算它们的平均损失函数值,来更新参数。
iteration:1个iteration即迭代一次,也就是用batchsize个样本训练一次。
in_channels:输入维度(一般图片为1或3代表灰度图和RGB图)
out_channels:输出维度(卷集核的个数)
kernel_size:卷集核的大小 ,要求为整数或者列表等
strides:步长(卷集核滑动的大小,默认为1)
padding:填充(如果滤波器窗口不够滑,默认为0)
三、性能评价
1.随机森林
1)性能度量方法
精确率Precision 正确率Accuracy F1(Precision、Recall)
2)测试集与训练集划分
训练集包含60000个样例,测试集包含10000个样例,分为10类。
3)在不同参数下所取得的性能指标
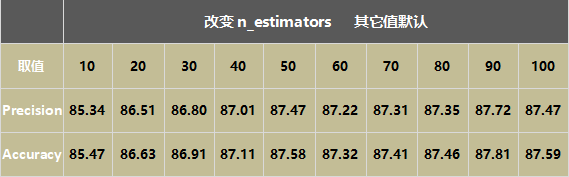
调节参数n_estimators,即树的数目,其它值默认,随着树的增加,正确率随之提升,在参数为60之后正确率不再显著变化。
调节参数max_depth,树的深度,n_estimators=50,其它值默认,随着树的深度增加,正确率随之提升,在参数为25之后正确率不再显著变化。

max_depth=50,n_estimators=100,其它值默认,训练10次,对训练10次后的数据取平均值,Precision取平均:87.58,Accuracy取平均:87.68。

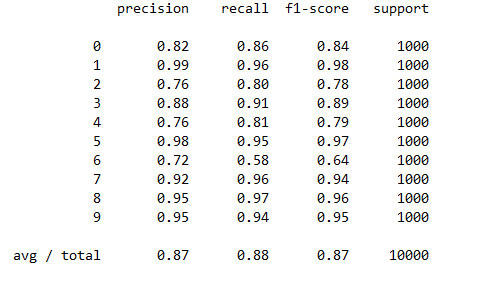
每个类的精确度,召回率,F1值等信息
每一类的ROC曲线

2.KNN
1)性能度量方法
精确率Precision 正确率Accuracy F1(Precision、Recall)
2)测试集与训练集划分
训练集包含60000个样例,测试集包含10000个样例,分为10类。
3)在不同参数下所取得的性能指标
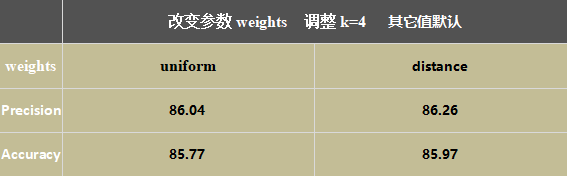
调节参数k,其它值默认,观察正确率的变化。共训练10次,k值从1到10,绘制k值关于正确率的曲线,观察到k=4时正确率最高。

k = 4,调整参数weights,设置参数为distance,正确率略微提升
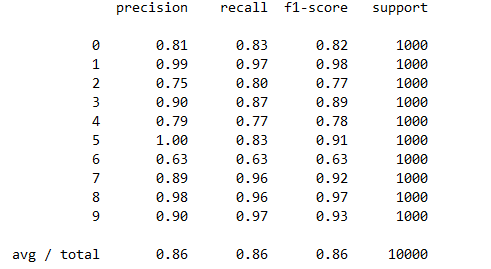
每一类的精确度,召回率,F1值等信息
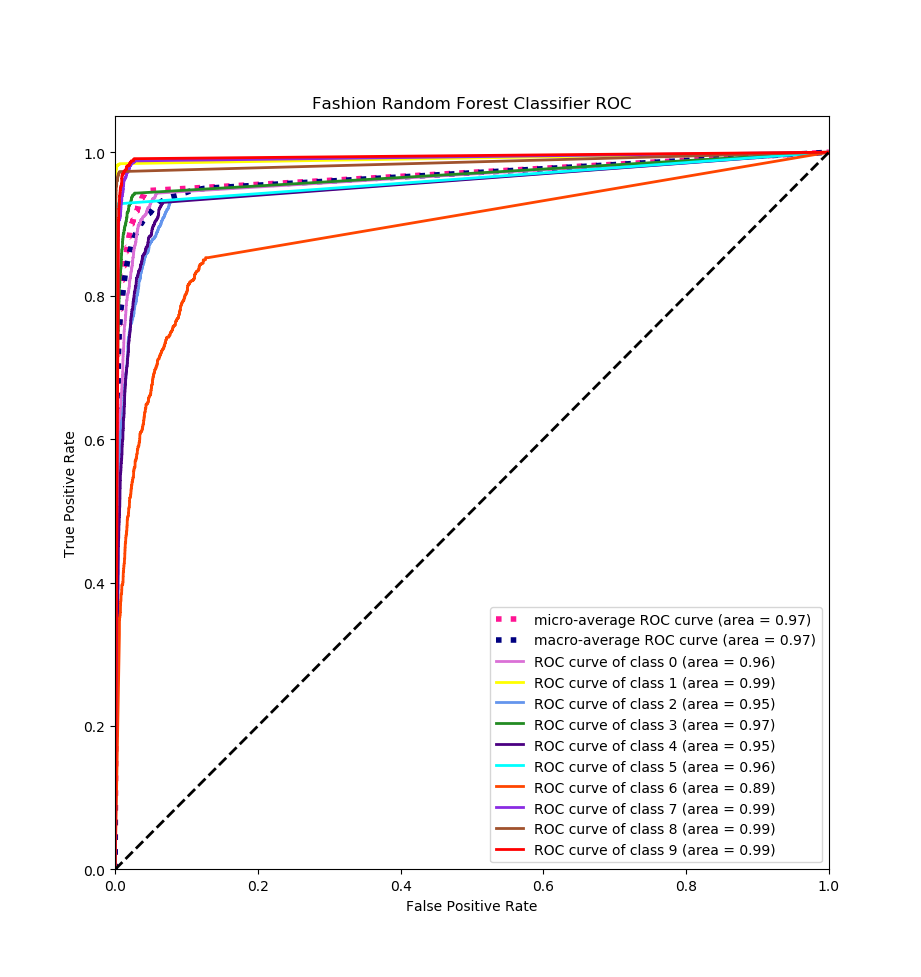
每一类的ROC曲线
3.朴素贝叶斯
1)性能度量方法
精确率Precision 正确率Accuracy F1(Precision、Recall)
2)测试集与训练集划分
训练集包含60000个样例,测试集包含10000个样例,分为10类。
3)在不同参数下所取得的性能指标
参数:alpha=1,fit_prior=True 改变参数正确率不变
precision: 65.41%
accuracy: 65.54%
每一类的精确度,召回率,F1值等信息
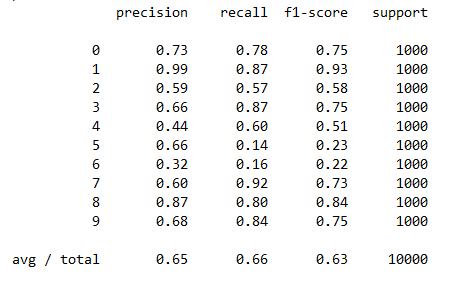
每一类的ROC曲线
4.卷积神经网络
1)性能度量方法
Loss(损失) Accuracy(正确率)
2)测试集与训练集划分
训练集包含60000个样例,测试集包含10000个样例,分为10类。
3)网络结构及优化器的选择
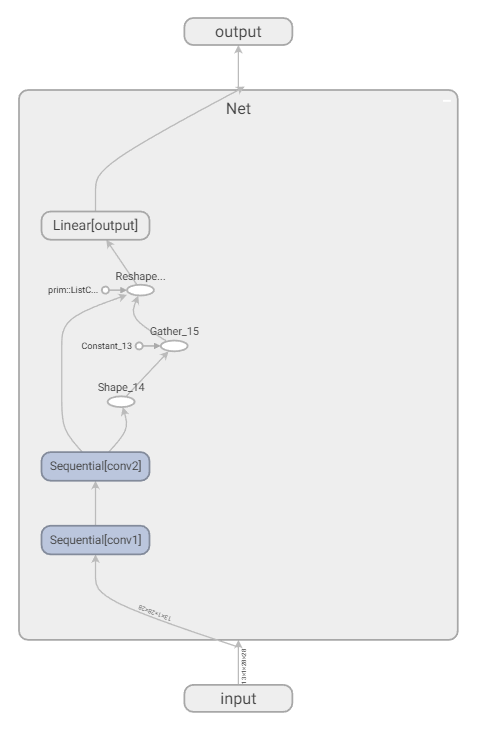
1 网络结构
包括输入层,两个卷积层,全连接层和输出层,下面是详细信息
Net(
(conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(output): Linear(in_features=1568, out_features=10, bias=True)
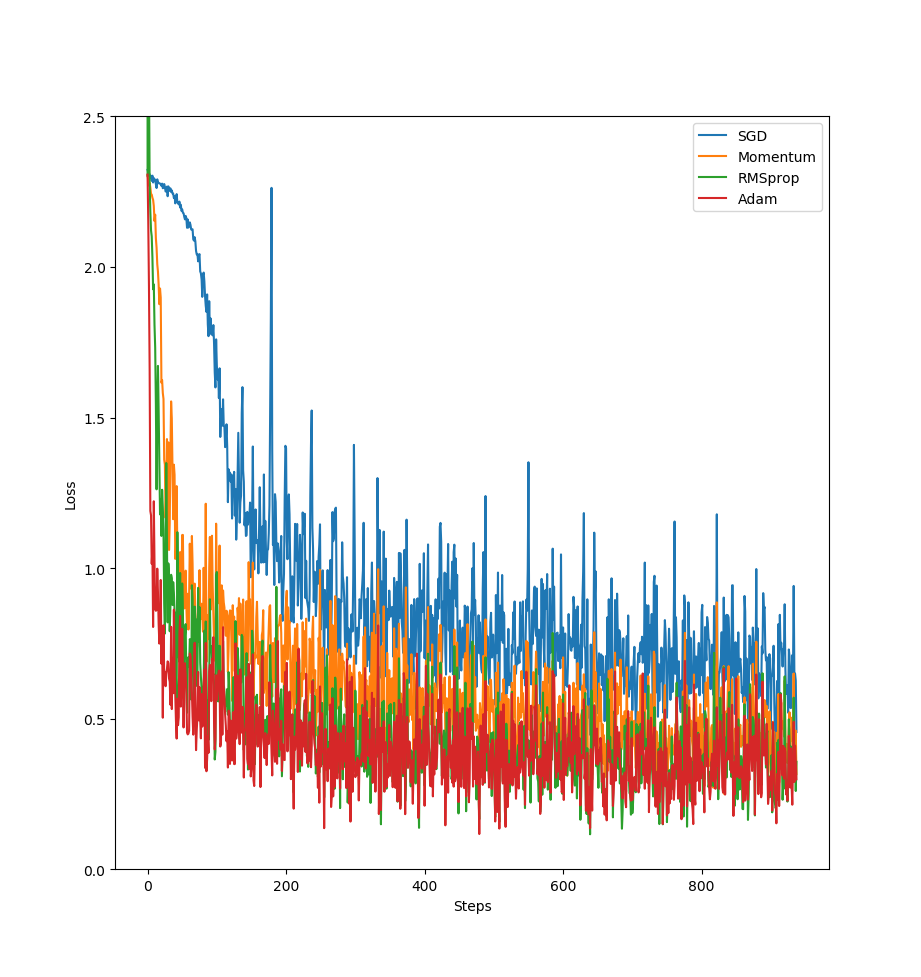
2 优化器的选择
测试四种优化器,如下图所示,epoch一次的结果,Adam效果最好。
4)在不同参数下所取得的性能指标
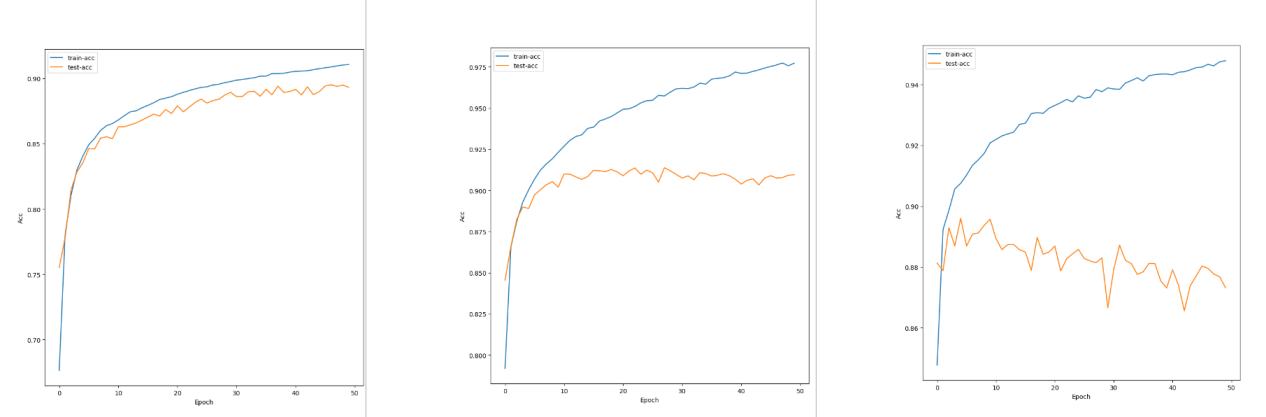
1 调节Lr,根据数据可以看出,学习率太小,epoch需要相应增大,而学习率太大就会导致test loss不下降,学习效果很差或是过拟合,学习率的选择可以预先设置一个小的值,根据loss的下降效果来慢慢增大学习率。
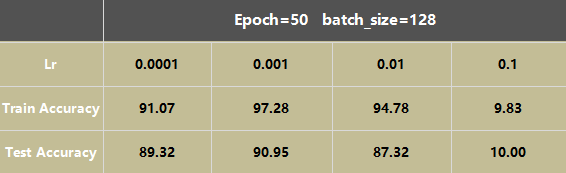
从左到右为0.0001,0.001,0.01的accuracy-epoch曲线图,从曲线可以看出,后两个过拟合了,因为epoch太大,可以提前结束训练。
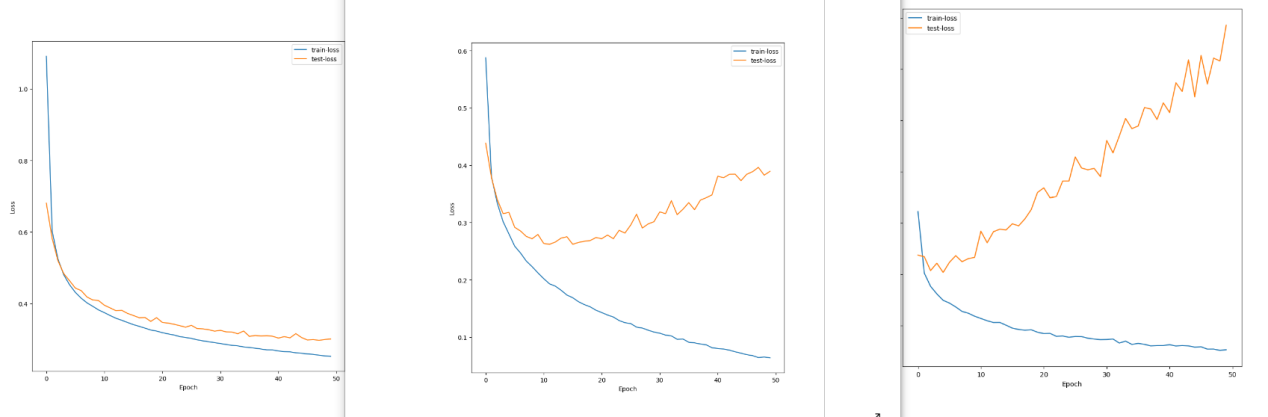
从左到右为0.0001,0.001,0.01的loss-epoch曲线图

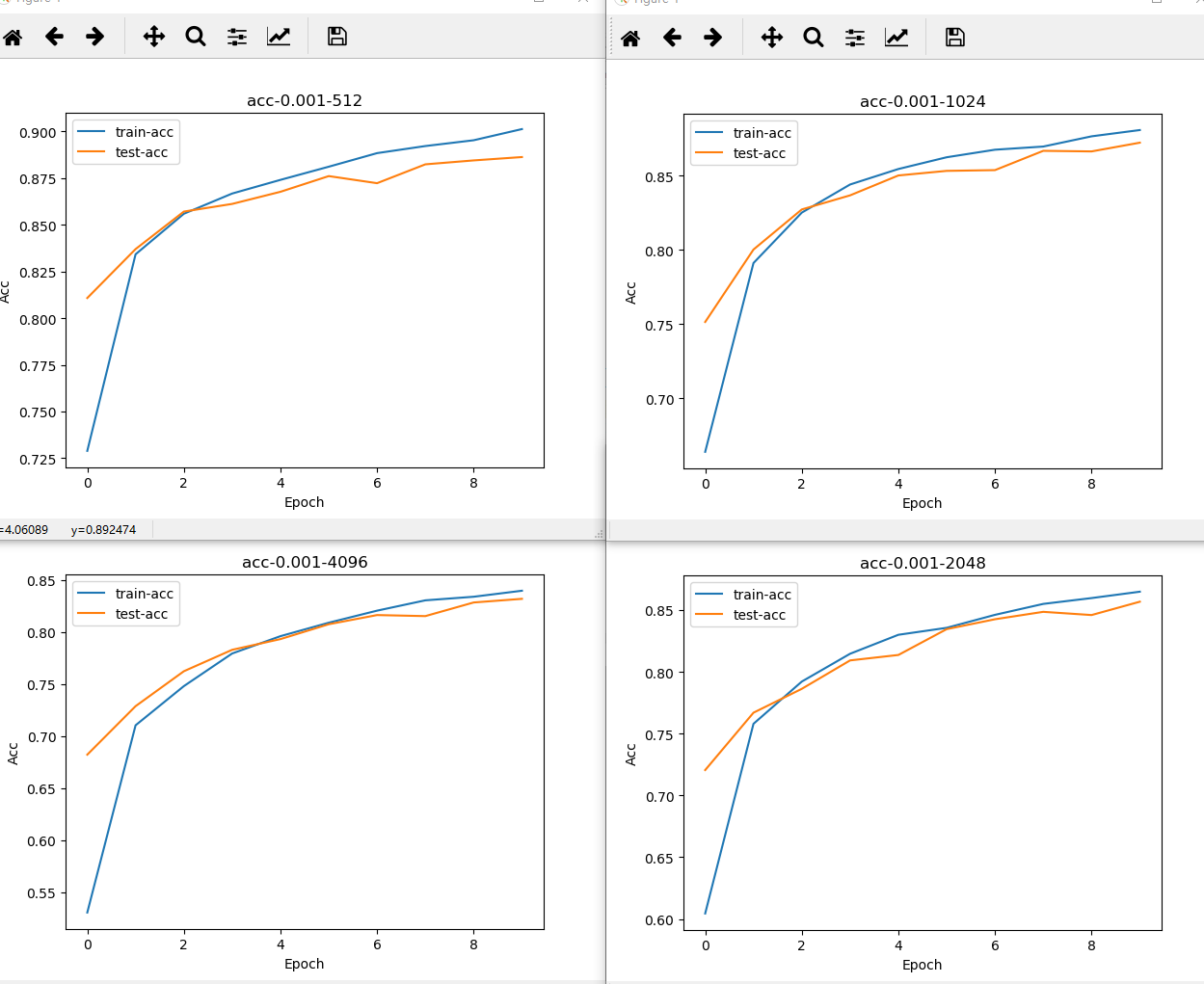
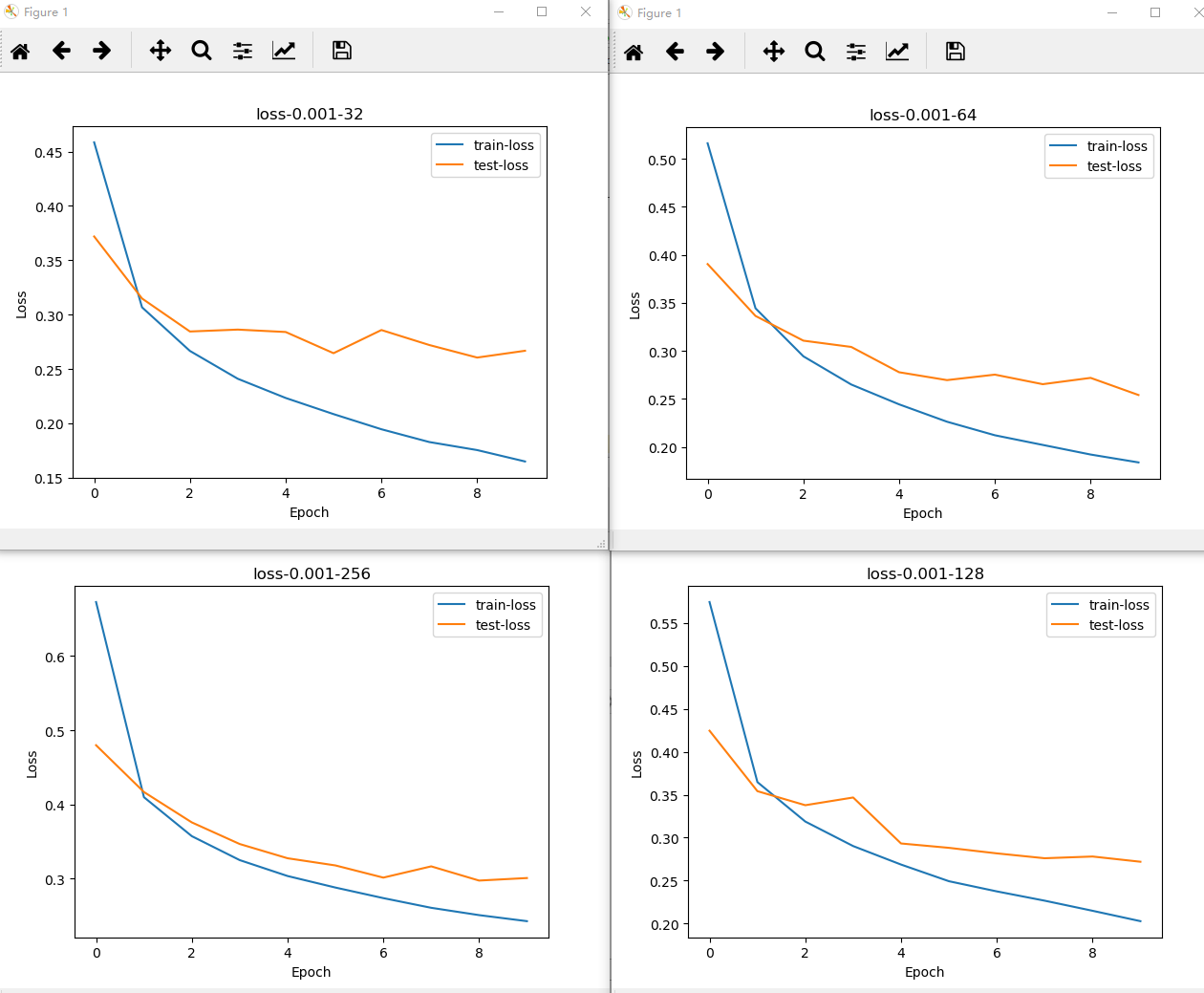
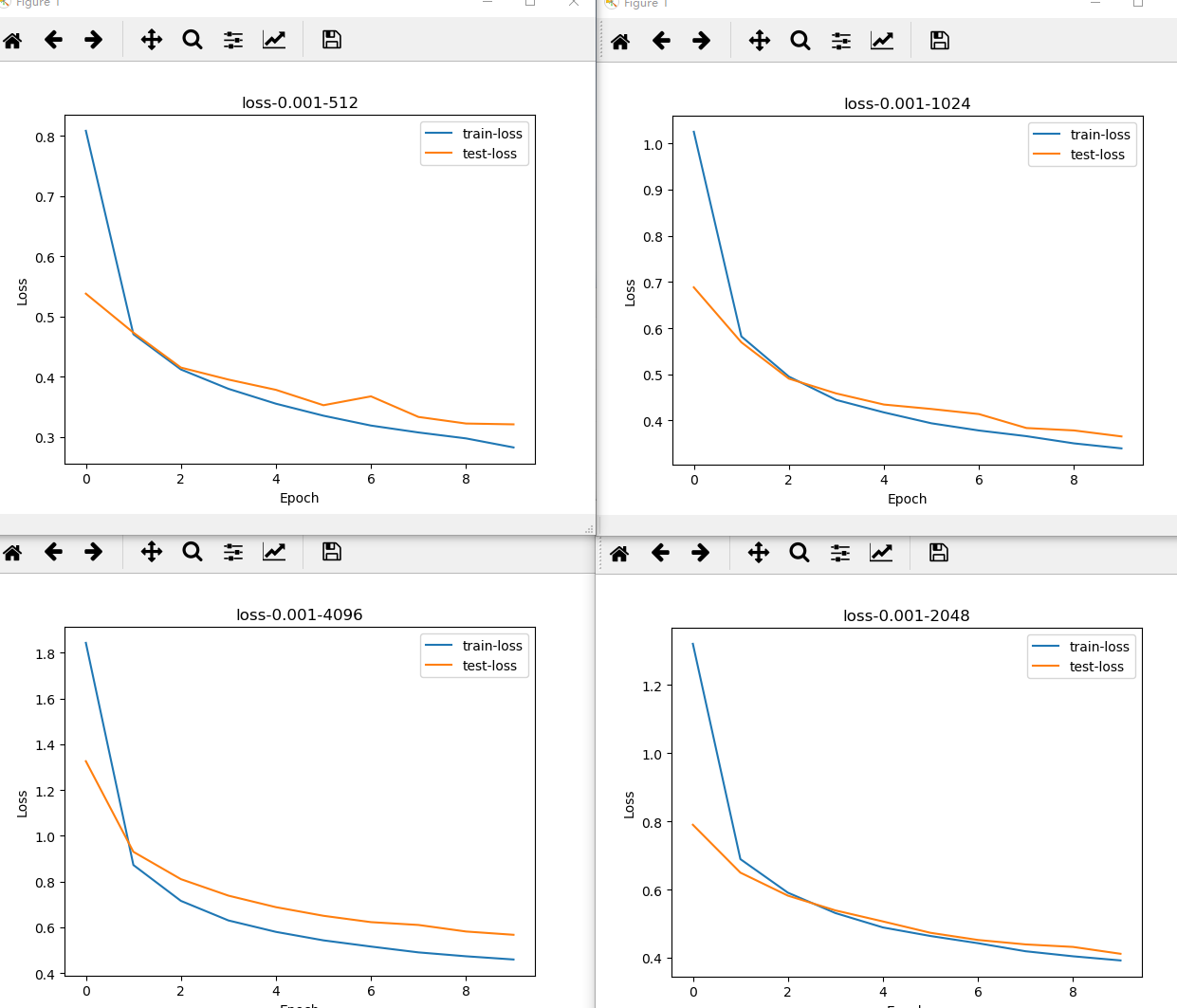
2 调节batch_size,以2的指数倍增加,观察正确率和loss的化。可以看出,随着batch_size的增加,正确率开始减小,但是更不容易过拟合,也可以从曲线图看出明显的变化。
batch_size从32以2的指数形式增加的accuracy-epocp和loss-epoch图

四、总结
1)本次实验总共测试了4种分类器,分别是随机森林、KNN、朴素贝叶斯和卷积神经网络。前三种方法主要采用精确率(precision)和正确率(accuracy)的性能评价方法,卷积神经网络采用正确率(accuracy)和损失(loss)来评价性能的好坏。
2)通过上述实验总结了每个分类器对于该数据集分类的性能,总结如下
训练集60000,测试集10000,共10类,下面是每种分类器的正确率
随机森林:87.68% (训练十次平均值)
KNN:85.97%
朴素贝叶斯:65.54%
卷积神经网络:91.32%

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)