
torchtext读取文本数据集
Introduction
本文主要介绍如何使用Torchtext读取文本数据集。
Torchtext是非官方的、一种为pytorch提供文本数据处理能力的库, 类似于图像处理库Torchvision。
Install
下载地址:https://github.com/text
安装:pip install text-master.zip
测试安装是否成功: import torchtext
How To Use
概览
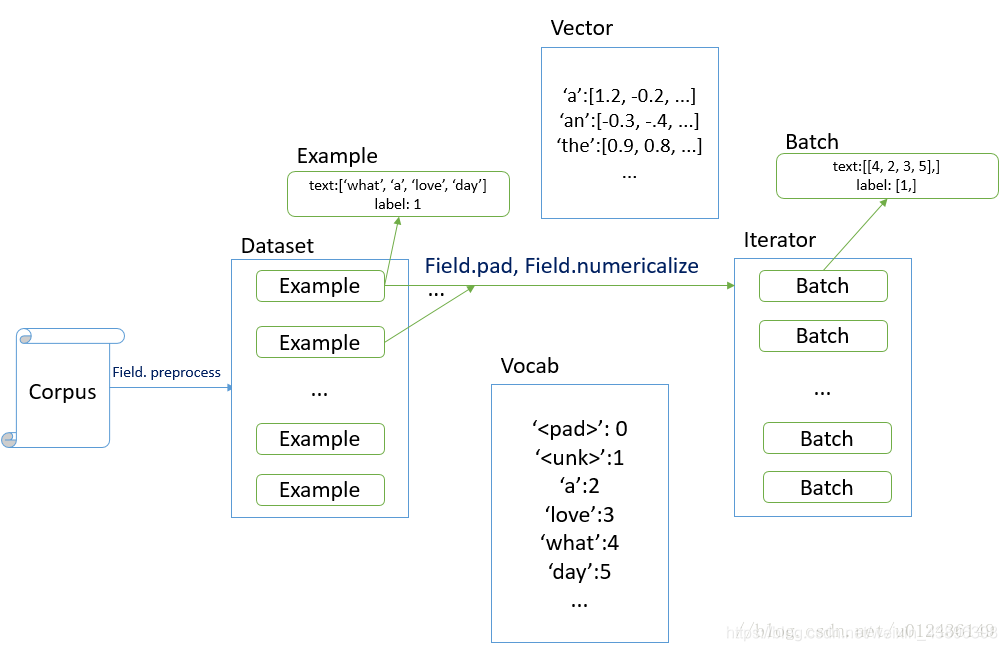
先上一张图。使用tortext的目的是将文本转换成Batch,方便后面训练模型时使用。过程如下:
- 使用Field对象进行文本预处理, 生成example
- 使用Dataset类生成数据集dataset
- 使用Iterator生成迭代器
从图中还可以看到,torchtext可以生成词典vocab和词向量embedding,但个人比较喜欢将这两步放在数据预处理和模型里面进行,所以这两个功能不在本文之列。
常用的类
from torchtext.data import Field, Example, TabularDataset
from torchtext.data import BucketIterator
Field:用来定义字段以及文本预处理方法
Example: 用来表示一个样本,通常为“数据+标签”
TabularDataset: 用来从文件中读取数据,生成Dataset, Dataset是Example实例的集合
BucketIterator:迭代器,用来生成batch, 类似的有Iterator,Buckeiterator的功能较强大点,支持排序,动态padding等
使用步骤
创建Field对象
def x_tokenize(x):
# 如果加载进来的是已经转成id的文本
# 此处必须将字符串转换成整型
# 否则必须将use_vocab设为True
return [int(c) for c in x.split()]
def y_tokenize(y):
return int(y)
TEXT = Field(sequential=True, tokenize=x_tokenize,
use_vocab=False, batch_first=True,
fix_length=self.fix_length,
eos_token=None, init_token=None,
include_lengths=True, pad_token=0)
LABEL = Field(sequential=False, tokenize=y_tokenize, use_vocab=False, batch_first=True)
参数说明
- sequential 类型boolean, 作用:是否为序列,一般文本都为True,标签为False
- tokenize 类型: function, 作用: 文本处理,默认为str.split(), 这里对x和y分别自定义了处理函数。
- use_vocab: 类型: boolean, 作用:是否建立词典
- batch_first:类型: boolean, 作用:为True则返回Batch维度为(batch_size, 文本长度), False 则相反
- fix_length:类型: int, 作用:固定文本的长度,长则截断,短则padding,可认为是静态padding;为None则按每个Batch内的最大长度进行动态padding。
- eos_token:类型:str, 作用: 句子结束字符
- init_token:类型:str, 作用: 句子开始字符
- include_lengths:类型: boolean, 作用:是否返回句子的原始长度,一般为True,方便RNN使用。
- pad_token:padding的字符,默认为”“, 这里因为原始数据已经转成了int类型,所以使用0。注意这里的pad_token要和你的词典vocab里的“”的Id保持一致,否则会影响后面词向量的读取。
读取文件生成数据集
fields = [
("label", LABEL), ("text", TEXT)]
train, valid = TabularDataset.splits(
path=config.ROOT_DIR,
train=self.train_path, validation=self.valid_path,
format='tsv',
skip_header=False,
fields=fields)
return train, valid
生成迭代器
train_iter, val_iter = BucketIterator.splits((train, valid),
batch_sizes=(self.batch_size, self.batch_size),
device = torch.device("cpu"),
sort_key=lambda x: len(x.text), # field sorted by len
sort_within_batch=True,
repeat=False)
这里要注意的是sort_with_batch要设置为True,并指定排序的key为文本长度,方便后面pytorch RNN进行pack和pad。
我们来看下train_iter和val_iter里放了什么东西。
bi = BatchIterator(config.TRAIN_FILE, config.VALID_FILE, batch_size=1, fix_length=None)
train, valid = bi.create_dataset()
train_iter, valid_iter = bi.get_iterator(train, valid)
batch = next(iter(train_iter))
print(train_iter)
print('batch:\n', batch)
print('batch_text:\n', batch.text)
print('batch_label:\n', batch.label)
结果为:
<torchtext.data.iterator.BucketIterator object at 0x7f04a9d845f8>
batch:
[torchtext.data.batch.Batch of size 1]
[.label]:[torch.LongTensor of size 1]
[.text]:('[torch.LongTensor of size 1x125]', '[torch.LongTensor of size 1]')
batch_text:
(tensor([[11149, 7772, 13752, 13743, 13773, 13793, 13791, 13591, 12478, 13759,
13783, 13492, 13793, 13745, 13754, 13612, 7452, 12185, 13789, 13784,
13765, 12451, 12112, 13620, 12240, 13073, 13790, 13738, 13637, 13759,
13776, 13793, 13739, 13783, 13787, 13793, 12702, 13790, 13698, 13774,
13792, 13768, 13715, 13641, 13761, 13713, 13682, 13712, 13786, 13749,
13097, 13734, 13702, 13735, 13257, 13642, 13700, 13793, 13684, 13755,
13488, 13789, 13750, 13484, 13494, 13793, 13624, 13670, 13786, 13655,
13768, 13687, 13774, 13792, 13791, 13591, 13546, 13777, 13658, 13740,
13577, 13790, 13684, 13755, 13793, 13572, 12891, 13793, 13368, 13713,
13682, 13712, 13786, 13786, 13642, 13700, 13793, 13429, 13520, 13613,
13792, 13368, 13790, 13750, 13699, 13764, 13590, 13675, 13742, 13691,
13688, 13742, 13782, 13538, 13742, 13783, 13787, 13774, 13645, 13742,
13791, 13740, 13744, 13750, 13792]]), tensor([125]))
batch_label:
tensor([11])
可以看到batch有两个属性,分别为label和text, text是一个元组,第一个元素为文本,第二个元素为文本原始长度(这里因为我们在定义TEXT时使用了include_lengths=True,否则这里只返回文本), label则是标签。
这里为了方便展示只使用了一个batch,返回的batch维度为(batch_size * length), 数据格式为LongTensor。如果想看动态padding的效果,可多取几个batch,会发现他们是按照长度进行排序,并且是以0进行padding的。
对Batch包装一下,方便调用
通过以上步骤,我们能够得到一个batch。但是很快就发现有个不太方便的地方。我们只能通过batch的属性,即自定义的字段名称,如text和label,来访问数据。这样的话在训练时我们只能这样操作:
for e in range(num_epoch):
for batch in train_iter:
inputs = batch.text[0]
label = batch.label
length = batch.text[1]
pass
万一这个字段改了,还要去改训练的代码,很麻烦,关键是显得很LOW,姿势不对。
怎么办呢?
我们对获得的iter进行包装一下,就可以避免这个问题了。
class BatchWrapper(object):
"""对batch做个包装,方便调用,可选择性使用"""
def __init__(self, dl, x_var, y_vars):
self.dl, self.x_var, self.y_vars = dl, x_var, y_vars
def __iter__(self):
for batch in self.dl:
x = getattr(batch, self.x_var)
if self.y_vars is not None:
temp = [getattr(batch, feat).unsqueeze(1) for feat in self.y_vars]
label = torch.cat(temp, dim=1).long()
else:
raise ValueError('BatchWrapper: invalid label')
text = x[0]
length = x[1]
yield (text, label, length)
def __len__(self):
return len(self.dl)
我们这样使用:
train_iter = BatchWrapper(train_iter, x_var=self.x_var, y_vars=self.y_vars)
val_iter = BatchWrapper(val_iter, x_var=self.x_var, y_vars=self.y_vars)
这样你就会发现batch不再有text和label属性了,而是一个三元组(text, label, length),调用时
就可以采用如下优雅一点的姿势:
for e in range(num_epoch):
for inputs, label, length in train_iter:
pass
完整代码
"""将id格式的输入转换成dataset,并做动态padding"""
import torch
from torchtext.data import Field, TabularDataset
from torchtext.data import BucketIterator
import config
def x_tokenize(x):
# 如果加载进来的是已经转成id的文本
# 此处必须将字符串转换成整型
return [int(c) for c in x.split()]
def y_tokenize(y):
return int(y)
class BatchIterator(object):
def __init__(self, train_path, valid_path,
batch_size, fix_length=None,
x_var="text", y_var=["label"],
format='tsv'):
self.train_path = train_path
self.valid_path = valid_path
self.batch_size = batch_size
self.fix_length = fix_length
self.format = format
self.x_var = x_var
self.y_vars = y_var
def create_dataset(self):
TEXT = Field(sequential=True, tokenize=x_tokenize,
use_vocab=False, batch_first=True,
fix_length=self.fix_length, # 如需静态padding,则设置fix_length, 但要注意要大于文本最大长度
eos_token=None, init_token=None,
include_lengths=True, pad_token=0)
LABEL = Field(sequential=False, tokenize=y_tokenize, use_vocab=False, batch_first=True)
fields = [
("label", LABEL), ("text", TEXT)]
train, valid = TabularDataset.splits(
path=config.ROOT_DIR,
train=self.train_path, validation=self.valid_path,
format='tsv',
skip_header=False,
fields=fields)
return train, valid
def get_iterator(self, train, valid):
train_iter, val_iter = BucketIterator.splits((train, valid),
batch_sizes=(self.batch_size, self.batch_size),
device = torch.device("cpu"),
sort_key=lambda x: len(x.text), # field sorted by len
sort_within_batch=True,
repeat=False)
train_iter = BatchWrapper(train_iter, x_var=self.x_var, y_vars=self.y_vars)
val_iter = BatchWrapper(val_iter, x_var=self.x_var, y_vars=self.y_vars)
### batch = iter(train_iter)
### batch: ((text, length), y)
return train_iter, val_iter
class BatchWrapper(object):
"""对batch做个包装,方便调用,可选择性使用"""
def __init__(self, dl, x_var, y_vars):
self.dl, self.x_var, self.y_vars = dl, x_var, y_vars
def __iter__(self):
for batch in self.dl:
x = getattr(batch, self.x_var)
if self.y_vars is not None:
temp = [getattr(batch, feat).unsqueeze(1) for feat in self.y_vars]
y = torch.cat(temp, dim=1).long()
else:
raise ValueError('BatchWrapper: invalid label')
text = x[0]
length = x[1]
yield (text, y, length)
def __len__(self):
return len(self.dl)
if __name__ == '__main__':
bi = BatchIterator(config.TRAIN_FILE, config.VALID_FILE, batch_size=1, fix_length=None)
train, valid = bi.create_dataset()
train_iter, valid_iter = bi.get_iterator(train, valid)
batch = next(iter(train_iter))
print(train_iter)
print('batch:\n', batch)
print('batch_text:\n', batch.text)
print('batch_label:\n', batch.label)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容









所有评论(0)