【Deep Learning】基于 Keras 的猫狗分类识别
基于 Keras 的猫狗分类识别 本篇主要实现利用 Keras 来实现 Kaggle 的经典比赛 ——猫狗识别,目的是熟悉 Keras 的基本用法与使用环境,为后期利用 Keras 和 TensorFlow 实现更多的深度学习网络打下基础。 本篇的主要参考来自DeepLearn ,并在这个实现基础上,增加了一些实现,如 Tensorboard 可视化训练过程,使用 matplotlib ..
基于 Keras 的猫狗分类识别
更新:
本文代码github连接:https://github.com/Sdamu/Keras_pratice
本篇主要实现利用 Keras 来实现 Kaggle 的经典比赛 ——猫狗识别,目的是熟悉 Keras 的基本用法与使用环境,为后期利用 Keras 和 TensorFlow 实现更多的深度学习网络打下基础。
本篇的主要参考来自DeepLearn ,并在这个实现基础上,增加了一些实现,如 Tensorboard 可视化训练过程,使用 matplotlib 可视化训练过程,保存加载模型,使用全部的训练集等操作,后期我会同步到我的 github 上。
1. 使用自己搭建的 CNN 实现猫狗分类
1.1 数据集
可以直接从 这里 进行下载数据,下载好后放在工程文件夹下,针对训练数据和测试数据,分别命名为 train 和 test 文件夹,用来存储训练数据和测试数据。
可以看到,训练数据有 25000 张图片,其中猫狗图片各占二分之一,测试数据有 12500 张。
1.2 图片读入
对于原博客 DeepLearn 直接利用 opencv 进行读取,然后存放在内存中,这是一种直接将所有图片读到内存中的方法,但是当文件数量很大的时候,就会发现内存会发生溢出的现象,因此当文件数量很大的时候个人并不推荐这种方法,而是使用 keras 中的函数进行读取。下面首先给出将所有图片读入到内存中的代码:
resize = 224
def load_data():
imgs = os.listdir("./train/")
train_data = np.empty((5000, resize, resize, 3), dtype="int32")
train_label = np.empty((5000, ), dtype="int32")
test_data = np.empty((5000, resize, resize, 3), dtype="int32")
test_label = np.empty((5000, ), dtype="int32")
print("load training data")
for i in trange(5000):
if i % 2:
train_data[i] = cv2.resize(cv2.imread('./train/' + 'dog.' + str(i) + '.jpg'), (resize, resize))
train_label[i] = 1
else:
train_data[i] = cv2.resize(cv2.imread('./train/' + 'cat.' + str(i) + '.jpg'), (resize, resize))
train_label[i] = 0
print("\nload testing data")
for i in trange(5000, 10000):
if i % 2:
test_data[i-5000] = cv2.resize(cv2.imread('./train/' + 'dog.' + str(i) + '.jpg'), (resize, resize))
test_label[i-5000] = 1
else:
test_data[i-5000] = cv2.resize(cv2.imread('./train/' + 'cat.' + str(i) + '.jpg'), (resize, resize))
test_label[i-5000] = 0
return train_data, train_label, test_data, test_label
train_data, train_label, test_data, test_label = load_data()
train_data, test_data = train_data.astype('float32'), test_data.astype('float32')
train_data,test_data = train_data/255.0, test_data/255.0
# 变为 one-hot 向量
train_label = keras.utils.to_categorical(train_label,2)
test_label = keras.utils.to_categorical(test_label,2)
从上面的代码种可以看出,因为需要将所有图片都读入到内存中,因此并未使用所有的图片进行训练,而仅仅使用了一小部分图片。
当我们想利用全部图片进行训练时,会发现这种方法并不能满足我们的要求,因此考虑使用 keras 中的内置函数 .flow_from_directory 详见 keras,但是在使用这种方法前,我们需要重新整理一下我们数据集的文件夹结构,具体如下所示:
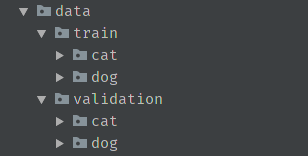
在整理好数据集后,我们利用 keras 中的 ImageDataGenerator 类的相关操作进行数据的整理和生成,这部分代码如下所示:
from keras.preprocessing.image import ImageDataGenerator
# 训练样本目录和测试样本目录
train_dir = './data/train/'
test_dir = './data/validation/'
# 对训练图像进行数据增强
train_pic_gen = ImageDataGenerator(rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.5,
horizontal_flip=True,
fill_mode='nearest')
# 对测试图像进行数据增强
test_pic_gen = ImageDataGenerator(rescale=1./255)
# 利用 .flow_from_directory 函数生成训练数据
train_flow = train_pic_gen.flow_from_directory(train_dir,
target_size=(224,224),
batch_size=64,
class_mode='categorical')
# 利用 .flow_from_directory 函数生成测试数据
test_flow = test_pic_gen.flow_from_directory(test_dir,
target_size=(224,224),
batch_size=64,
class_mode='categorical')
print(train_flow.class_indices)
利用最后的输出我们可以看到程序根据我们的目录已经自动将训练文件分为了两个类别,即 cat :0 和 dog:1 ,具体输出如下所示:
Using TensorFlow backend.
Found 22500 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
{'cat': 0, 'dog': 1}
1.3 搭建网络
在完成了数据的读取任务后,需要进行的是搭建网络,这里只搭建一个简单的 CNN 就结构,因此使用 Keras 中的 Sequential 即可完成任务。具体代码如下所示:
model = Sequential()
# level1
model.add(Conv2D(filters=96,kernel_size=(11,11),
strides=(4,4),padding='valid',
input_shape=(resize,resize,3),
activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2),
padding='valid'))
# level_2
model.add(Conv2D(filters=256,kernel_size=(5,5),
strides=(1,1),padding='same',
activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2),
padding='valid'))
# layer_3
model.add(Conv2D(filters=384,kernel_size=(3,3),
strides=(1,1),padding='same',
activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(filters=384,kernel_size=(3,3),
strides=(1,1),padding='same',
activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(filters=356,kernel_size=(3,3),
activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2),padding='valid'))
# layer_4
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='relu'))
model.add(Dropout(0.5))
# output layer
model.add(Dense(2))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
1.4 训练数据
在网络搭建完成后,需要将数据喂给网络进行训练,这里直接使用 keras 中的 fit_generator 即可完成相关工作,具体代码如下所示:
his = model.fit_generator(data_move.train_flow,
steps_per_epoch=100,
epochs=50,
verbose=1,
validation_data=data_move.test_flow,
validation_steps=500,
callbacks=[tbCallBack])
这里简单介绍一下这个函数,即 fit_generator, 这部分内容参考博客 fit_generator(). 函数定义如下所示:
fit_generator(self, generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)这个函数的作用是:通过Python generator产生一批批的数据用于训练模型。generator可以和模型并行运行,例如,可以使用CPU生成批数据同时在GPU上训练模型。
参数:
- generator:一个generator或Sequence实例,为了避免在使用multiprocessing时直接复制数据。
- steps_per_epoch:从generator产生的步骤的总数(样本批次总数)。通常情况下,应该等于数据集的样本数量除以批量的大小。
- epochs:整数,在数据集上迭代的总数。
- works:在使用基于进程的线程时,最多需要启动的进程数量。
- use_multiprocessing:布尔值。当为True时,使用基于基于过程的线程。
为了可以更加形象的可视化我们的训练过程,因此引入 keras 中的 history 参数,利用这个参数结合 matplotlib 可以很方便的画出 loss 和 accuracy 的迭代曲线,只需要添加很少的代码即可完成这部分工作:
plt.plot(his.history['acc'])
plt.plot(his.history['val_acc'])
plt.title('model_accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.plot(his.history['loss'])
plt.plot(his.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
除了利用 matplotlib 进行可视化外,因为我按装的 Keras 是基于 Tensorflow 的,因此还可以调用 TensorBoard 进行做图,具体来说,只需要在 fit_generator 参数种令 callbacks 参数指向 Tensorboard 即可。
2. 利用训练好的模型进行迁移学习
除了利用我们自己搭建的网络进行训练学习外,我们还可以使用 keras 中已经训练好的权重进行迁移学习,这里以 VGG16 为例,数据的读取方法和上面介绍的大致相同,因此不再进行赘述,这里直接给出相关的代码:
import keras
import matplotlib.pyplot as plt
from keras.layers import Dense,Dropout
from keras.layers import GlobalAveragePooling2D
from keras.applications.vgg16 import VGG16
from keras.models import Model
import data_move
resize = 224
tbCallBack = keras.callbacks.TensorBoard(log_dir='./logs/1',
histogram_freq= 0,
write_graph=True,
write_images=True)
base_model = VGG16(weights='imagenet', include_top=False, pooling=None,
input_shape=(resize, resize, 3), classes = 2)
for layer in base_model.layers:
layer.trainable = False
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(2, activation='sigmoid')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'],)
his = model.fit_generator(data_move.train_flow,
steps_per_epoch=100,
epochs=50,
verbose=1,
validation_data=data_move.test_flow,
validation_steps=500,
callbacks=[tbCallBack])
plt.plot(his.history['acc'])
plt.plot(his.history['val_acc'])
plt.title('model_accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.plot(his.history['loss'])
plt.plot(his.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
model.save('./weights/catdogs_model.h5')
其中,data_move.py 也就是上面提到的读入数据的部分,下面给出完整代码:
from keras.preprocessing.image import ImageDataGenerator
train_dir = './data/train/'
test_dir = './data/validation/'
train_pic_gen = ImageDataGenerator(rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.5,
horizontal_flip=True,
fill_mode='nearest')
test_pic_gen = ImageDataGenerator(rescale=1./255)
train_flow = train_pic_gen.flow_from_directory(train_dir,
target_size=(224,224),
batch_size=64,
class_mode='categorical')
test_flow = test_pic_gen.flow_from_directory(test_dir,
target_size=(224,224),
batch_size=64,
class_mode='categorical')
print(train_flow.class_indices)
3. 测试
在训练完成后,我们可以利用 keras 的 predict 函数,给出一张图片,我们对其进行相应处理后,直接利用 predict进行预测。具体代码如下所示:
model.load_weights('./weights/catdogs_model.h5')
test_image = cv2.resize(cv2.imread('./43.jpg'),(224,224))
test_image = np.asarray(test_image.astype("float32"))
test_image = test_image/255.
test_image = test_image.reshape((1,224,224,3))
preds = model.predict(test_image)
if preds.argmax() == 0:
print("cat")
else:
print("dog")
通过上面的简单程序,就可以很方便的识别出我们提供的图片属于猫或狗。
4.代码
全部代码将会上传到我的 github,后期会进行更新。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)