微服务的重试和幂等
系统架构优化-重试和幂等摘要重试常见的重试场景幂等页面 和API 幂等实现定时任务幂等mq的幂等消费微服务框架遗留问题摘要重试是一种保障业务运行的容错机制,比如页面查询、数据导出等业务场景,如果某个微服务出现异常,可以将请求动态路由到其他的服务。但是对于写的业务场景,就会导致很多问题,比如重复订购,重复生成记录,甚至重复扣费。本文重点讨论如果避免写的重试重试常见的重试场景(1)页面操作...
1、摘要
重试是一种保障业务运行的容错机制,比如页面查询、数据导出等业务场景,如果某个微服务出现异常,可以将请求动态路由到其他的服务。但是对于写的业务场景,就会导致很多问题,比如重复订购,重复生成记录,甚至重复扣费。本文重点讨论如果避免写的重试
2、重试
2.1、常见的重试场景
(1)页面操作
重复点击添加或者修改按钮
重复导入同一批数据,如Excel
页面刷新导致重复提交
(2)定时任务
定时任务Cron表达式设置有问题,导致短时间内重复处理同一批数据。
定时任务中某个分片失败了,重复执行。
(3)开放API
http超时重发
异常重发
黑客等恶意重复发送同一消息
(4)消息队列
业务异常导致重复发送同一条到同一个队列。
消息处理失败后放到Retry队列,然后重复消费。
死信队列里面的消息重复消费。
(5)微服务框架
容错机制选用不当 比如upate 和 insert 接口选用 faileover,导致超时重发多次请求。
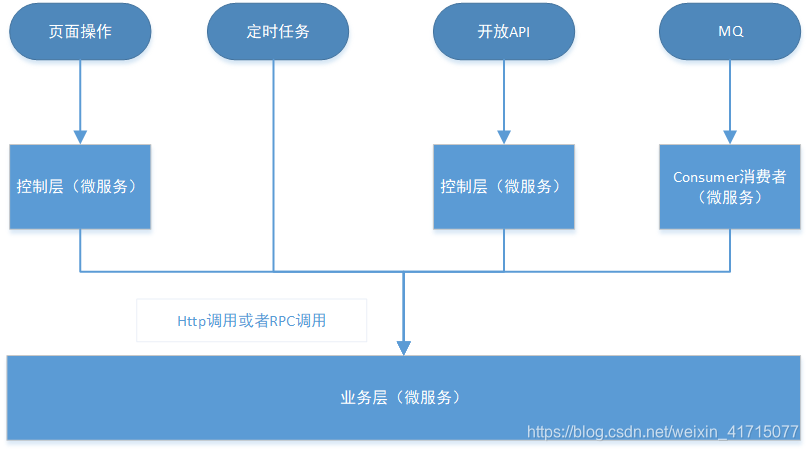
上面的场景有可能组合到一起出现,如下图:

系统如果不对重试做控制,在极端情况下,会导致系统并发量瞬间暴增,出现大量脏数据甚至系统瘫痪。
3、幂等
幂等设计是解决写重试问题重要手段。下面针对各种场景以及我们系统现实情况,分析如何实现幂等
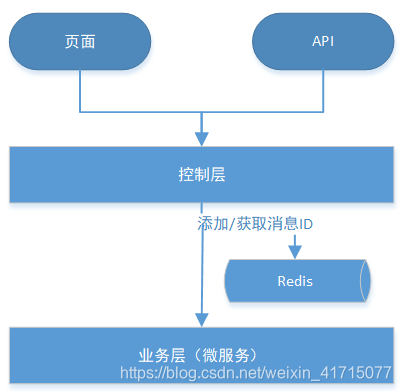
3.1、页面 和API 幂等实现
首先应该遵循restfull 接口设计规范,‘写’请求,最好是对单一资源的操作,如果是批量操作,必须有批次号,以及详细的操作记录。请求消息体中携带消息ID,(消息的完整性和安全性可以通过hash算法保证,不在本次讨论范围内)。在控制层,针对消息ID做重复校验,这样可以做到技术上的幂等。
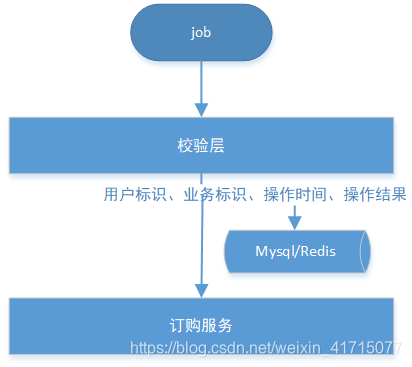
3.2、定时任务幂等
很多时候会设置一个唯一任务ID,业务层对任务ID做唯一性校验,但这可能起不了太大作用,因为job 是重复执行的,每次都会生成新的任务ID。这时只能根据业务特点,针对特定的业务类型,添加业务操作日志。比如定时为某些用户下发订单的场景,可以将用户订购信息添加到单独日志表中或者redis中,且这些日志信息应该是跟业务无关的,只用来做防止重复订购的校验,使用完后可以定时清理掉,或者自动失效,避免堆积太多的垃圾数据。消息的结构可以包括:用户标识、业务标识、操作时间、操作结果,其中业务类型就表示这是定制化的重复校验,用来保证业务上的幂等。
3.3、mq的幂等消费
防止消息重复消费的设计方式跟定时任务幂等的设计方式一样,只能根据特定的业务类型,做到业务逻辑上的幂等设计。
3.4、微服务架构
要谨慎的选择重试策略和集群方式。
对于系统间调用链比较短的场景,可以取消重试,然后整个数据流向设计成快速失败的(failefast), 比如我们的系统,目前最长的业务流程也就是调用5个功能模块(微服务)。
但是必须有其他的容错机制,这里容错机制不仅仅是微服务架构上的容错,也是业务流程整体设计上的容错,例如:每个请求都带有请求日志,记录请求状态和时间。对于异常的请求,可以手动重试,也可以自动重试,或者将整个过程回滚,这就是业务流程设计上的容错。微服务架构容错机制则是重试并添加熔断器,重试可以用前提是所有接口都是幂等的,但是熔断器也是个鸡肋,很难自动控制,若果熔断策略选用不当还会起反作用,甚至不如APM监控+分布式配置功能开关组合策略。所以对于完整性要求比较的高的业务场景,可以取消重试,去掉熔断器,但是要在业务流程的入口处加上限流机制,防止过载。
我们目前的措施是在入口处做限流。因为我们的系统主要还是给公司内部的运营人员用的,运营会有很多批量操作,这些操作都是短时间大批量数据的处理,在不影响系统正常运作的前提下,我们直接在功能入口处做限流,限制操作频次,限制数据量。
还有一种情况是定时任务处理大批量的数据,对这种场景我们并没有做限流,否则会影响处理效率。但是所有的接口都设计成幂等的。
4、遗留问题
请求日志主要做幂等校验的,应该和业务数据隔离开来,目前系统还是放在一起的。

开源、云原生的融合云平台
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)