机器学习笔记(4)——ID3决策树算法及其Python实现
决策树是一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。最经典的决策树算法有ID3、C4.5、CART,其中ID3算法是最早被提出的,它可以处理离散属性样本的分类,C4.5和CART算法则可以处理更加复杂的分类问题,本文重点介绍ID3算法。举个...
决策树是一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。
最经典的决策树算法有ID3、C4.5、CART,其中ID3算法是最早被提出的,它可以处理离散属性样本的分类,C4.5和CART算法则可以处理更加复杂的分类问题,本文重点介绍ID3算法。
举个例子:夏天买西瓜时,我一般先选瓜皮有光泽的(新鲜),再拍一拍选声音清脆的(成熟),这样挑出来的好瓜的可能就比较大了。那么我挑西瓜的决策树是这样的:
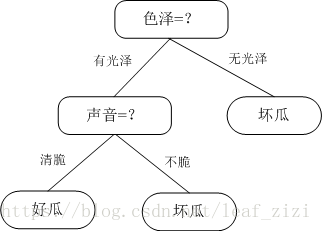
下面,我们就对以下表格中的西瓜样本构建决策树模型。

1. 利用信息增益选择最优划分属性
样本有多个属性,该先选哪个样本来划分数据集呢?原则是随着划分不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一分类,即“纯度”越来越高。先来学习一下“信息熵”和“信息增益”。
- 信息熵(information entropy)
样本集合D中第k类样本所占的比例(k=1,2,...,|Y|),|Y|为样本分类的个数,则D的信息熵为:
Ent(D)的值越小,则D的纯度越高。直观理解一下:假设样本集合有2个分类,每类样本的比例为1/2,Ent(D)=1;只有一个分类,Ent(D)= 0,显然后者比前者的纯度高。
在西瓜样本集中,共有17个样本,其中正样本8个,负样本9个,样本集的信息熵为:
- 信息增益(information gain)
使用属性a对样本集D进行划分所获得的“信息增益”的计算方法是,用样本集的总信息熵减去属性a的每个分支的信息熵与权重(该分支的样本数除以总样本数)的乘积,通常,信息增益越大,意味着用属性a进行划分所获得的“纯度提升”越大。因此,优先选择信息增益最大的属性来划分。设属性a有V个可能的取值,则属性a的信息增益为:
西瓜样本集中,以属性“色泽”为例,它有3个取值{青绿、乌黑、浅白},对应的子集(色泽=青绿)中有6个样本,其中正负样本各3个,
(色泽=乌黑)中有6个样本,正样本4个,负样本2个,
(色泽=浅白)中有5个样本,正样本1个,fuya负样本4个。
同理也可以计算出其他几个属性的信息增益,选择信息增益最大的属性作为根节点来进行划分,然后再对每个分支做进一步划分。创建一个trees.py文件,加入以下代码:
from math import log
# 计算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) # 样本数
labelCounts = {}
for featVec in dataSet: # 遍历每个样本
currentLabel = featVec[-1] # 当前样本的类别
if currentLabel not in labelCounts.keys(): # 生成类别字典
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts: # 计算信息熵
prob = float(labelCounts[key]) / numEntries
shannonEnt = shannonEnt - prob * log(prob, 2)
return shannonEnt
# 划分数据集,axis:按第几个属性划分,value:要返回的子集对应的属性值
def splitDataSet(dataSet, axis, value):
retDataSet = []
featVec = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 # 属性的个数
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures): # 对每个属性技术信息增益
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 该属性的取值集合
newEntropy = 0.0
for value in uniqueVals: # 对每一种取值计算信息增益
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain): # 选择信息增益最大的属性
bestInfoGain = infoGain
bestFeature = i
return bestFeature2. 递归构建决策树
通常一棵决策树包含一个根节点、若干个分支节点和若干个叶子节点,叶子节点对应决策结果(如好瓜或坏瓜),根节点和分支节点对应一个属性测试(如色泽=?),每个结点包含的样本集合根据属性测试的结果划分到子节点中。
在上一节中,我们对整个训练集选择的最优划分属性就是根节点,第一次划分后,数据被向下传递到树分支的下一个节点,再这个节点我们可以再次划分数据,构建决策树是一个递归的过程,而递归结束的条件是:所有属性都被遍历完,或者每个分支下的所有样本都属于同一类。
还有一种情况就是当划分到一个节点,该节点对应的属性取值都相同,而样本的类别却不同,这时就把当前节点标记为叶节点,并将其类别设为所含样本较多的类别。例如:当划分到某一分支时,节点中有3个样本,其最优划分属性为色泽,而色泽的取值只有一个“浅白”,3个样本中有2个好瓜,这时我们就把这个节点标记为叶节点“好瓜”。
在trees.py中添加以下代码:
import operator # 此行加在文件顶部
# 通过排序返回出现次数最多的类别
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 递归构建决策树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet] # 类别向量
if classList.count(classList[0]) == len(classList): # 如果只有一个类别,返回
return classList[0]
if len(dataSet[0]) == 1: # 如果所有特征都被遍历完了,返回出现次数最多的类别
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 最优划分属性的索引
bestFeatLabel = labels[bestFeat] # 最优划分属性的标签
myTree = {bestFeatLabel: {}}
del (labels[bestFeat]) # 已经选择的特征不再参与分类
featValues = [example[bestFeat] for example in dataSet]
uniqueValue = set(featValues) # 该属性所有可能取值,也就是节点的分支
for value in uniqueValue: # 对每个分支,递归构建树
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(
splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
下面使用西瓜样本集,测试一下算法,创建一个WaterMalonTree.py文件。因为生成的树是中文表示的,因此使用json.dumps()方法来打印结果。如果是不含中文,直接print即可。
# -*- coding: cp936 -*-
import trees
import json
fr = open(r'C:\Python27\py\DecisionTree\watermalon.txt')
listWm = [inst.strip().split('\t') for inst in fr.readlines()]
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
Trees = trees.createTree(listWm, labels)
print json.dumps(Trees, encoding="cp936", ensure_ascii=False)运行该文件,打印出西瓜的决策树,它是一个字典:
{"纹理": {"模糊": "否", "清晰": {"根蒂": {"稍蜷": {"色泽": {"乌黑": {"触感": {"软粘": "否", "硬滑": "是"}}, "青绿": "是"}}, "蜷缩": "是", "硬挺": "否"}}, "稍糊": {"触感": {"软粘": "是", "硬滑": "否"}}}}
3. 使用Matplotlib绘制决策树
字典形式的决策树仍然不易理解,下面我们利用Matplotlib库的annotate(注释)模块绘制决策树,就可以很直观的看出决策树的结构。annotate的详细说明:Matplotlib中的annotate(注解)的用法。
新建一个treeplotter.py文件,添加以下代码:
# -*- coding: cp936 -*-
import matplotlib.pyplot as plt
# 设置决策节点和叶节点的边框形状、边距和透明度,以及箭头的形状
decisionNode = dict(boxstyle="square,pad=0.5", fc="0.9")
leafNode = dict(boxstyle="round4, pad=0.5", fc="0.9")
arrow_args = dict(arrowstyle="<-", connectionstyle="arc3", shrinkA=0,
shrinkB=16)
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(unicode(nodeTxt, 'cp936'), xy=parentPt,
xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="top", ha="center", bbox=nodeType,
arrowprops=arrow_args)
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, unicode(txtString, 'cp936'))
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW,
plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff),
cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()在WaterMalonTree.py文件中添加一行代码绘制图形,图形虽然不太美观,但可以很直观的看出决策树的结构。
# -*- coding: cp936 -*-
import trees
import treePlotter
import json
fr = open(r'C:\Python27\py\DecisionTree\watermalon.txt')
listWm = [inst.strip().split('\t') for inst in fr.readlines()]
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
Trees = trees.createTree(listWm, labels)
print json.dumps(Trees, encoding="cp936", ensure_ascii=False)
treePlotter.createPlot(Trees)
4. 测试算法
构造完决策树,就可以用它对实际数据分类,分类时需要使用决策树和标签向量,比较测试数据在决策树上的值,递归执行下去直到jinr进入叶节点,也就得到了测试数据所属的类别。
# 测试算法
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0] # 根节点
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr) # 跟节点对应的属性
classLabel = None
for key in secondDict.keys(): # 对每个分支循环
if testVec[featIndex] == key: # 测试样本进入某个分支
if type(secondDict[key]).__name__ == 'dict': # 该分支不是叶子节点,递归
classLabel = classify(secondDict[key], featLabels, testVec)
else: # 如果是叶子, 返回结果
classLabel = secondDict[key]
return classLabel在WaterMalonTree.py文件中调用测试算法,最后运行文件,得到的测试结果是“否”,这是一个坏瓜。
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
testData = ['浅白', '蜷缩', '浊响', '稍糊', '凹陷', '硬滑']
testClass = trees.classify(Trees, labels, testData)
print json.dumps(testClass, encoding="cp936", ensure_ascii=False)5. 存储决策树
在处理大数据集时,构建决策树会耗费很多时间,而利用决策树对新数据分类的耗时是非常小的。因此,我们可以把构建好的决策树存起来,需要分类的时候再读取出来,就可以节省很多时间。
# 存储决策树
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
# 读取决策树, 文件不存在返回None
def grabTree(filename):
import pickle
if os.path.isfile(filename):
fr = open(filename)
return pickle.load(fr)
else:
return None>>> import WaterMalonTree
>>> import trees
>>> fileName = r'C:\Python27\py\DecisionTree\TreeFile.txt'
>>> trees.storeTree(WaterMalonTree.Trees, fileName)
>>> import json
>>> print json.dumps(readTrees, encoding="cp936", ensure_ascii=False)
{"纹理": {"清晰": {"根蒂": {"稍蜷": {"色泽": {"乌黑": {"触感": {"软粘": "否", "硬滑": "是"}}, "青绿": "是"}}, "蜷缩": "是", "硬挺": "否"}}, "模糊": "否", "稍糊": {"触感": {"软粘": "是", "硬滑": "否"}}}}
6. 总结
决策树作为经典分类算法,具有计算复杂度低、结果直观、分类效率高等优点。
ID3决策树利用信息增益来选择最优划分属性,它可以处理标称型数据,无法处理连续和缺失值。后续我们会持续学习C4.5算法,它可以处理连续值和缺失值,而且增加了剪枝过程来应对过拟合现象。
参考:
周志华《机器学习》
Peter Harrington 《机器学习实战》

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 79
79 1
1- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)