【机器学习】线性回归原理推导与算法描述
该文已经收录到专题机器学习进阶之路当中,欢迎大家关注。1. 概念线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。2. 特点优点:结果具有很好的可解释性(w直观表达了各属性在预测中的重要性),计算熵不复杂。缺点:对非线性数据拟合不好适用数据类...
该文已经收录到专题机器学习进阶之路当中,欢迎大家关注。
1. 概念
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。
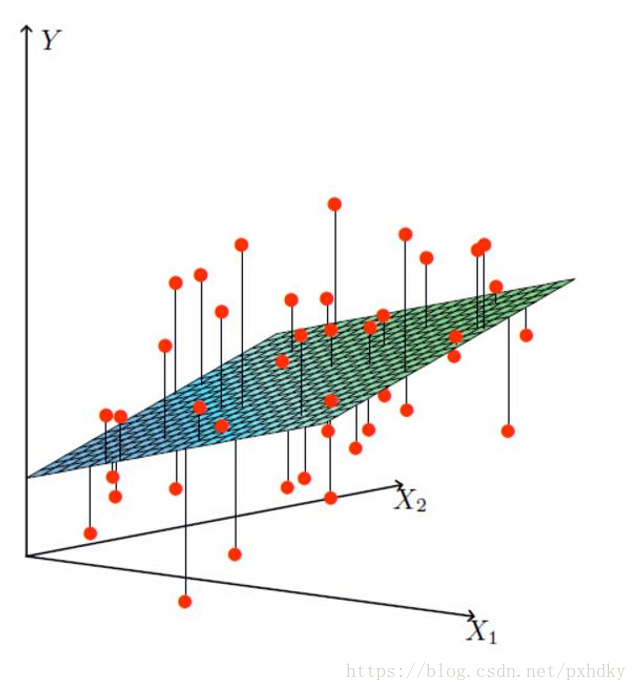
2. 特点
- 优点:结果具有很好的可解释性(w直观表达了各属性在预测中的重要性),计算熵不复杂。
- 缺点:对非线性数据拟合不好
- 适用数据类型:数值型和标称型数据
3. 原理与推导
1. 给定数据集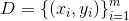
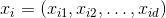
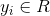
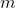
是属性维度。
线性回归试图学得:
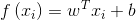
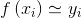
为便于讨论,使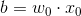
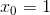
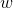
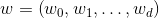
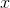
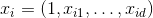
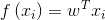
2. 预测值和真实值之间都肯定存在差异
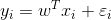
假设误差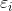
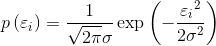
将(2)代入(3)中,得到在已知参数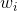
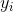
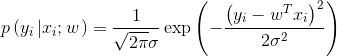
3. 将(4)连乘得到在已知参数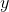
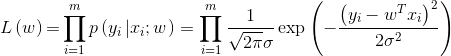
为什么要引入似然函数:为了根据样本估计参数值。
为什么要对似然函数进行log变换:由于乘法难解,通过对数可以将乘法转换为加法,简化计算。
对数似然函数:
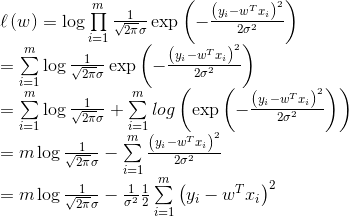
得到目标函数:
![J(w) = \frac{1}{2}\sum\limits_{i = 1}^m {{{\left( {{y_i} - {w^T}{x_i}} \right)}^2}} \\ = \frac { 1 } { 2 } \left\| \left[ \begin{array} { c } { y _ { 1 } - w ^ { T } x _ { 1 } } \\ { y _ { 2 } - w ^ { T } x _ { 2 } } \\ { \cdots } \\ { y _ { m } - w ^ { T } x _ { m } } \end{array} \right] \right\| ^ { 2 }= \frac { 1 } { 2 } \left\| \left[ \begin{array} { l } { y _ { 1 } } \\ { y _ { 2 } } \\ { \cdots } \\ { y _ { m } } \end{array} \right] - w ^ { T } \left[ \begin{array} { c } { x _ { 1 } } \\ { x _ { 2 } } \\ { \cdots } \\ { x _ { m } } \end{array} \right] \right\| ^ { 2 } \\ = \frac{1}{2}{\left\| {y - {w^T}X} \right\|^2} = \frac{1}{2}{\left( {y - {w^T}x} \right)^T}\left( {y - {w^T}x} \right)](https://img-blog.csdnimg.cn/20181222212812582)
为什么要让目标函数越小越好:似然函数表示样本成为真实的概率,似然函数越大越好,也就是目标函数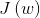
4. 目标函数是凸函数,只要找到一阶导数为0的位置,就找到了最优解。
因此求偏导:
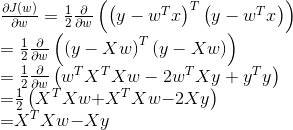
5. 令偏导等于0:
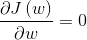
得到:
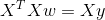
情况一: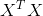
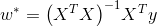
学得的线性回归模型为:
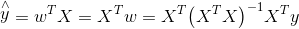
情况二: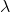
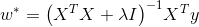
4. 算法描述
1. 从数据集D出发,构建输入矩阵X和输出向量y。
2. 计算伪逆(pseudo-inverse)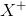
3. 返回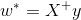
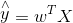
5. 广义线性回归
当
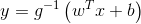
其中函数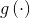
参考文献:
1. 《机器学习基石课程》lecture_9_Linear_Regression——林轩田
2. 《机器学习》第三章线性回归——周志华

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)