
精选机器学习开源项目Top10
作者 | Mybridge译者 | linstancy编辑 | Jane出品 | AI科技大本营【导读】过去一个月里,我们对近 250 个机器学习开源项目进行了排名,并挑选出热度前 10 的项目。这份清单的平均 github star 数量高达919,涵盖了包括 Auto Keras,Glow,Video to Video,机器翻译,舞蹈生成器,3D 足球视频,垃圾...

作者 | Mybridge
译者 | linstancy
编辑 | Jane
出品 | AI科技大本营
【导读】过去一个月里,我们对近 250 个机器学习开源项目进行了排名,并挑选出热度前 10 的项目。这份清单的平均 github star 数量高达919,涵盖了包括 Auto Keras,Glow,Video to Video,机器翻译,舞蹈生成器,3D 足球视频,垃圾邮件过滤,语音识别,图像生成,人脸处理等主题,希望你能从中找到一个你所感兴趣的项目深入探究。
▌1、Autokeras
AutoKeras是一款用于自动机器学习 (AutoML) 的开源软件库,由 Texas A&M大学的 DATA lab 和社区贡献者共同开发。AutoML 的最终目标是为那些仅具备有限数据科学或机器学习背景的领域专家提供易于访问、友好的深度学习工具。而 AutoKeras 则提供深度学习模型架构和超参数自动搜索等功能。
Github 链接:
https://github.com/jhfjhfj1/autokeras?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

▌2、Glow
Glow 是由 OpenAI 研发的一种使用 1×1 可逆卷积的生成对抗模型。它扩展了之前关于可逆生成对抗模型的工作,并进一步简化了体系结构。Glow 能够生成逼真的高分辨率图像,支持高效的采样过程,还能探索用于操纵数据属性的特征。这里提供项目主页和 github 链接,包括模型代码和在线可视化工具,帮助研究者探索并构建 Glow 模型。
项目主页:
https://blog.openai.com/glow/
Github 链接:
https://github.com/openai/glow?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

▌3、Vid2Vid
Vid2Vid 是由 NVIDIA 研发的一种新颖视频合成方法。基于生成对抗框架,通过精心设计的生成器和判别器网络结构,再加上一种时空对抗损失函数 (spatial-temporal adversarial objective),我们可以在多种输入格式上 (如分割掩码、草图和姿态) 实现高分辨率、逼真的、时序相关的视频效果。Vid2Vid 框架能够显著地提升视频合成的效果,还能用于未来的视频预测任务。
Github 链接:
https://github.com/NVIDIA/vid2vid?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
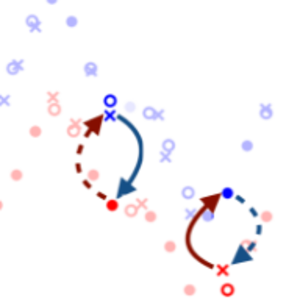
▌4、UnsupervisedMT
UnsupervisedMT 是由 Facebook Research 研发的一种无监督的神经机器翻译模型,它能够支持:
-
三种机器翻译架构,包括 seq2seq,biLSTM+attention 以及 Transformer 框架。
-
能够跨模型/语言共享任意数量的参数
-
去噪自动编码器训练
-
并行数据训练
-
反向并行数据训练
-
即时多线程地生成反向并行数据
Github 链接:
https://github.com/facebookresearch/UnsupervisedMT?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
▌5、DanceNet
DanceNet 是使用自编码器、LSTM 和混合密集网络结构设计的一种舞蹈生成器模型,它以舞蹈视频为训练数据,通过训练学习来生成新的舞蹈视频。
Github 链接:
https://github.com/jsn5/dancenet?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

▌6、Soccerontable
Soccerontable 是由华盛顿大学研发的一种能将单目的足球比赛视频进行3D 重建的系统,玩家和场地情景能够通过 AR/VR 设备交互式地呈现。这种系统通过对每名玩家深度图的估计,使用 CNN 来训练从足球视频游戏中所提取的玩家数据并进行 3D 重建过程。
项目主页:
http://grail.cs.washington.edu/projects/soccer/
Github 链接:
https://github.com/krematas/soccerontable?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

▌7、Artificial-Adversary
Artificial-adversary 是由 Airbnb 研发的一种能够生成对抗文本的项目。你可以使用这些方法生成文本样本,并在机器学习模型测试时模拟这些类型的攻击。它的主要原理是:以离线的方式将你的机器学习模型暴露在这些攻击之下,当在线训练模型过程中在此遇到这些类型的攻击时,模型能够更好地防御这些攻击。此外,与其他的对抗攻击项目不同的是,这种对抗攻击方法将模型视为黑盒子,且仅使用不依赖于模型自身知识的通用攻击方式。
Github 链接:
https://github.com/airbnb/artificial-adversary?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

▌8、Stt-benchmark
Stt-benchmark 是由 Picovoice 研发的一款语音到文本的转换框架基准。通过深度学习技术,改进先前语音-文本引擎的不足,并将这些优化迁移到低 CPU、低内存占用的物联网平台。此外,这项技术对基于云端的引擎更有利。
Github 链接:
https://github.com/Picovoice/stt-benchmark?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

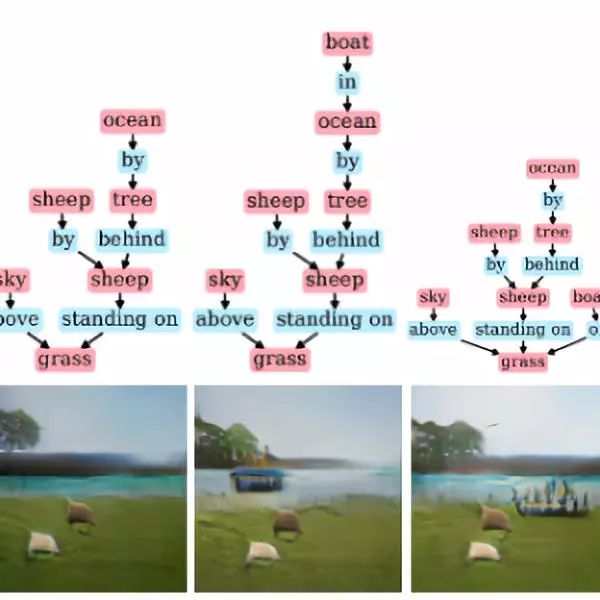
▌9、Sg2im
Sg2im 是 Google 团队研发的一种从场景图实现图像生成的图卷积神经网络框架。这是一种端到端的神经网络模型,以自然场景图为输入,沿着图卷积网络边缘传递信息以计算所有目标的嵌入对象并用于预测目标的边界框及分割掩码,最终组成以形成粗粒度的场景布局;通过级联的细化网络,以逐渐增大的空间尺度生成输出图像,并用一对判别器网络进行训练以确保输出图像的逼真性。
Github 链接:
https://github.com/google/sg2im?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
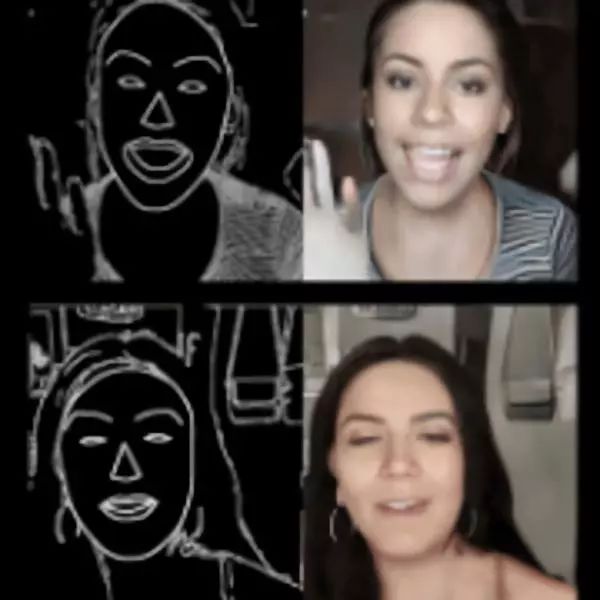
▌10、GANimation
GANimation 是一种基于动作单元 (Action Units,AU) 的新型条件 GAN 框架,用于在连续流形中根据面部动作来定义人脸表达。它能够控制每个 AU 的激活幅度,并允许自由组合。通过完全无监督的策略训练模型,只激活那些被 AU 注释过的图像,并通过注意力机制最终得到强鲁棒性的模型。
项目主页:
http://www.albertpumarola.com/research/GANimation/index.html
Github 链接:
https://github.com/albertpumarola/GANimation?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

原文链接:
https://medium.mybridge.co/machine-learning-open-source-of-the-month-v-aug-2018-ae85e7302ea5
--【完】--

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)