基于深度学习的目标检测算法及其在医学影像中的应用
(自己写的,需要转载请联系作者,或者标明出处呀,欢迎加微信交流:wx604954)摘要:目标检测是计算机视觉中一个重要问题,在行人跟踪、车牌识别、无人驾驶等领域都具有重要的研究价值。近年来,随着深度学习对图像分类准确度的大幅度提高,基于深度学习的目标检测算法逐渐成为主流。本文介绍了目前发展迅猛的深度学习方法在目标检测中的最新应用进展,然后介绍了基于深度学习的目标检测算法在医学图像领域的应...
(自己写的,需要转载请联系作者,或者标明出处呀,欢迎加微信交流:wx604954)
摘要:目标检测是计算机视觉中一个重要问题,在行人跟踪、车牌识别、无人驾驶等领域都具有重要的研究价值。近年来,随着深度学习对图像分类准确度的大幅度提高,基于深度学习的目标检测算法逐渐成为主流。本文介绍了目前发展迅猛的深度学习方法在目标检测中的最新应用进展,然后介绍了基于深度学习的目标检测算法在医学图像领域的应用,最后讨论了深度学习方法应用于目标视觉检测时存在的困难和挑战, 并对今后的发展趋势进行展望。
关键词:深度学习;卷积神经网络;目标检测;医学影像
1 引言
目标检测是计算机视觉领域中一个非常重要的研究问题。随着电子设备的应用在社会生产和人们生活中越来越普遍,数字图像已经成为不可缺少的信息媒介,每时每刻都在产生海量的图像数据。与此同时,对图像中的目标进行精确识别变得越来越重要[1]。我们不仅关注对图像的简单分类,而且希望能够准确获得图像中存在的感兴趣目标及其位置[2],并将这些信息应用到视频监控、自主驾驶等一系列现实任务中,因此目标检测技术受到了广泛关注。
目标检测具有巨大的实用价值和应用前景。应用领域包括智能视频监控、机器人导航、数码相机中自动定位和聚焦人脸的技术、飞机航拍或卫星图像中道路的检测、车载摄像机图像中的障碍物检测、医学影像在的病灶检测等[3]–[10]。同时,目标检测也是众多高层视觉处理和分析任务的重要前提,例如行为分析、事件检测、场景语义理解、病灶检测等都要求利用图像处理和模式识别技术,检测出图像中存在的目标,确定这些目标对象的语义类型,并且标出目标对象在图像中的具体区域[11]。
在自然环境条件下,目标检测经常遇到以下几个方面的挑战:
(1)类内和类间差异
对于很多物体,它们自身就存在很大的差异性,同类物体的不同实例在颜色、材料、形状等方面可能存在巨大的差异,很难训练一个能够包含所有类内变化的特征描述模型。另外,不同类型物体之间又可能具有很大的相似性,甚至非专业人员从外观上很难区分它们。类内差异可能很大,而类间差异可能很小,给目标检测提出了挑战。
(2)图像采集条件
在图像采集过程中,由于环境、光照、天气、拍摄视角和距离的不同、物体自身的非刚体形变以及可能被其他物体部分遮挡,导致物体在图像中的表观特征具有很大的多样性,对目标检测算法的鲁棒性提出了很高要求。
(3)语义理解的差异
对同一幅图像,不同的人可能会有不同的理解,这不仅与个人的观察视角和关注点有关,也与个人的性格、心理状态和知识背景等有关,这明显增加了从仿生或类脑角度来研究视觉算法的难度。
(4)计算复杂性和自适应性
目标检测的计算复杂性主要来自于待检测目标类型的数量、特征描述子的维度和大规模标记数据集的获取。由于在真实世界中存在大量的目标类型,每种类型都包含大量的图像,同时识别每种类型需要很多视觉特征,这导致高维空间稀疏的特征描述[4]。另外,目标模型经常从大规模标记数据集中学习得到,在许多情况下,数据采集和标注很困难,需要耗费大量的人力物力。这些情况导致目标检测的计算复杂性很高,需要设计高效的目标检测算法。同时,在动态变化的环境中,为了提高目标检测精度,还需要探索合适的机制来自动更新视觉模型,提高模型对复杂环境的自适应能力。
为了克服上述挑战,已经提出了许多目标检测算法,它们在目标区域建议、图像特征表示、候选区域分类等步骤采用了不同的处理策略。近年来,随着深度学习技术的发展,很多基于深度学习的目标检测方法陆续被提出,在精度上显著优于传统方法,成为最新的研究热点。
本文内容安排如下:第1节介绍目标检测的基本概念和面临的挑战;第2节介绍深度学习算法在目标检测中的最新进展;第3节介绍深度学习算法在医学图像检测领域的应用;第4节讨论深度学习算法应用于目标检测时存在的困难和挑战,并对今后的发展趋势进行展望;第5节对本文进行总结。
2 基于深度学习的目标检测算法
2.1 基于Region proposal的目标检测算法
卷积神经网络(CNN)是目标区域建议 (Region proposal)算法中的核心组成部分,卷积神经网络最早是由Yann LeCun教授提出来的[12],早期的卷积神经网络是用作分类器使用,主要用于图像的识别。然而卷积神经网络有3个结构上的特性:局部连接、权重共享以及空间或时间上的采样。这些特性使得卷积神经网络具有一定程度上的平移、缩放和扭曲不变性。在2006年Hinton提出利用深度神经网络从大量的数据中自动的学习高层特征。Region proposal在此基础之上解决了传统目标检测的两个主要问题。比较常用的Region proposal方法有Selective Search[13]和Edge Boxes[14]。此后,CNN网络迅速发展,微软最新的ResNet和谷歌的Inception V4[15], [16]模型的Top-5 error降到了4%以内,所以目标检测得到候选区域后使用CNN对其进行图像分类的准确率和检测速度上都有提高。
2.1.1 R-CNN算法
G
图1 R-CNN 的计算流程
R-CNN的基本流程如图1所示,首先对每一幅输入图像采用选择性搜索(Selective search)[13]来提取候选区域;然后用CNN网络从每个区域提取一个固定长度的特征向量,这里采用AlexNet[15]结构,图像经过5个卷积层和2个全连接层,得到一个4096维的特征向量; 接着把提取到的特征向量送入支持向量机进行分类。由于一些区域存在高度交叠,Girshick等采用非极大值抑制 (Non-maximum suppression)来舍弃那些与更高得分区域IoU (Intersection-over-Union) 过大的区域。为了得到更精确的结果,还采用了边框回归方法来进一步改善检测结果。在 R-CNN 模型的训练过程中,由于目标检测标注数据集的规模不够,Girshick等先将网络在大规模数据集ImageNet[19]上进行预训练,然后用 N+1类 (N个目标类和1个背景类) 的输出层来替换1000类的Softmax层,再针对目标检测任务,用PASCAL VOC 数据集进行微调。这种方法很好地解决了训练数据不足的问题,进一步提升了检测精度。得益于CNN的参数共享以及更低维度的特征,整个检测算法更加高效。
然而,R-CNN也存在一些不容忽视的问题:
(1)候选区域之间的交叠使得特征被重复提取,造成了严重的速度瓶颈, 降低了计算效率。
(2) 将候选区域直接缩放到固定大小,破坏了物体的长宽比,可能导致物体的局部细节损失。
(3) 使用边框回归有助于提高物体的定位精度,但是如果待检测物体存在遮挡,该方法将难以奏效。
2.1.2 SPP-Net
He等[20]针对R-CNN速度慢以及要求输入图像块尺寸固定的问题,提出空间金字塔池化(Spatial pyramid pooling,SPP)模型。在R-CNN中,要将提取到的目标候选区域变换到固定尺寸,再输入到卷积神经网络,He等加入了一个空间金字塔池化层来避免了这个限制。SPP-net网络不论输入图像的尺寸大小,都能产生固定长度的特征表示。SPP-net是对整幅图像提取特征,在最后一层卷积层得到特征图后,再针对每个候选区域在特征图上进行映射,由此得到候选区域的特征。因为候选区域的尺寸各不相同,导致它们映射所得到的特征图大小也不同,但CNN的全连接层需要固定维度的输入,因此引入了空间金字塔池化层来把特征转换到相同的维度。
空间金字塔池化的思想来源于空间金字塔模型(Spatial pyramid model,SPM)[21],它采用多个尺度的池化来替代原来单一的池化。SPP层用不同大小的池化窗口作用于卷积得到的特征图,池化窗口的大小和步长根据特征图的尺寸进行动态计算。SPP-net对于一幅图像的所有候选区域,只需要进行一次卷积过程,避免了重复计算,显著提高了计算效率,而且空间金字塔池化层使得检测网络可以处理任意尺寸的图像,因此可以采用多尺度图像来训练网络,从而使得网络对目标的尺度有很好的鲁棒性。该方法在速度上比R-CNN提高24-102倍,并且在PASCAL VOC 2007和Caltech 101数据集上取得了当时最好的成绩。
但是它存在以下缺点:
(1)SPP-net的检测过程是分阶段的,在提取特征后用SVM分类,然后还要进一步进行边框回归,这使得训练过程复杂化。
(2)CNN提取的特征存储需要的空间和时间开销大。
(3)在微调阶段,SPP-net只能更新空间金字塔池化层后的全连接层,而不能更新卷积层,这限制了检测性能的提升。
2.1.3 Fast-RCNN
Girshick等[22]对R-CNN和SPP-net进行了改进,提出能够实现特征提取、区域分类和边框回归的端到端联合训练的Fast-RCNN算法,计算流程如图2所示。
与R-CNN类似,FastR-CNN首先在图像中提取感兴趣区域(Regions of Interest,RoI);然后采用与SPP-net相似的处理方式,对每幅图像只进行一次卷积,在最后一个卷积层输出的特征图上对每个RoI进行映射,得到相应的RoI的特征图,并送入RoI池化层(相当于单层的SPP层,通过该层把各尺寸的特征图统一到相同的大小);最后经过全连接层得到两个输出向量,一个进行Softmax分类,另一个进行边框回归。在微调阶段,FastR-CNN采用一种新的层级采样方法,先采样图像,再从采样出的图像中对RoI进行采样,同一幅图像的RoI共享计算和内存,使得训练更加高效。FastR-CNN采用Softmax分类与边框回归一起进行训练,省去了特征存储,提高了空间和时间利用率,同时分类和回归任务也可以共享卷积特征,相互促进。与R-CNN相比,在训练VGG[23]网络时,FastR-CNN的训练阶段快9倍,测试阶段快213倍;与SPP-net相比,Fast R-CNN的训练阶段快3倍,测试阶段快10倍,并且检测精度有一定提高。然而,Fast R-CNN仍然存在速度上的瓶颈,区域建议步骤耗费了整个检测过程的大量时间。

图2 Fast R-CNN 的计算流程
2.1.4 Faster R-CNN
SPP-Net和Fast R-CNN从特征提取的角度,减少了工作量,但依然没有解决Selective Search选择候选区域速度慢的问题。Faster R-CNN [24]使用RPN网络(Region Proposal Networks)替代Selective Search算法,使目标识别实现真正端到端的计算。
如图3所示,RPN网络通过在特征图上做滑窗操作,使用预设尺度的锚点框映射到原图,得到候选区域。RPN网络输入的特征图和全连接层中的特征图共享计算。RPN的使用,使Faster R-CNN能够在一个网络框架之内完成候选区域、特征提取、分类、定位修正等操作。
R
PN使得Faster R-CNN在region proposal阶段只需10ms,检测速度达到5f/s(包括所有步骤),并且检测精度也得到提升,达到73.2%。但是,Faster R-CNN仍然使用ROI Pooling,导致之后的网络特征失去平移不变性,影响最终定位准确性;ROI Pooling后每个区域经过多个全连接层,存在较多重复计算;Faster R-CNN在特征图上使用滑动框对应原图,而滑动框经过多次下采样操作,对应原图一块较大的区域,导致Faster R-CNN检测小目标的效果并不是很好。
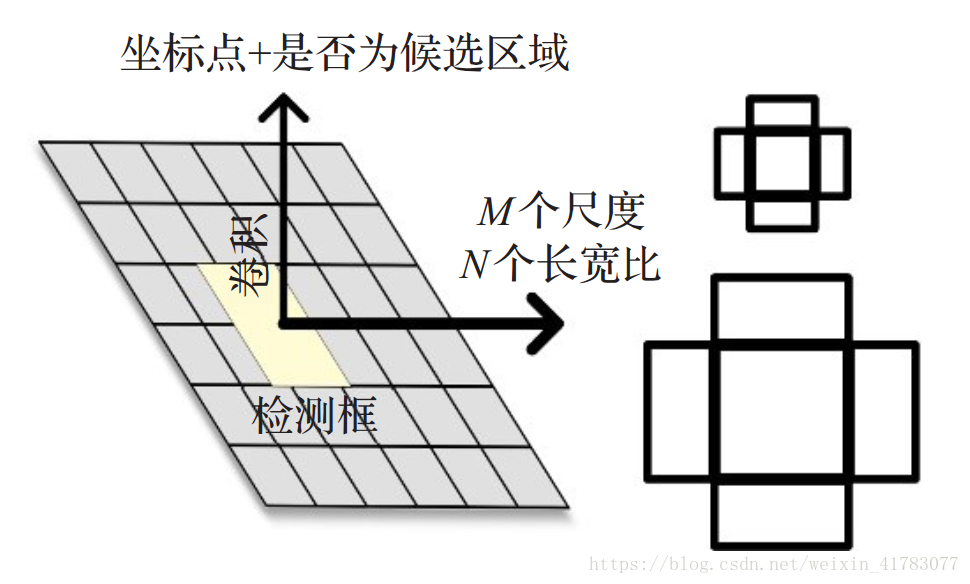
图3 RPN网络示意图
2.1.5 R-FCN
目标检测要包括两个问题:分类问题和检测定位问题。前者具有平移不变性,后者具有平移敏感性。
R-FCN[25]使用全卷积网络 ResNet[26]代替VGG,提升特征提取与分类的效果;针对全卷积网络不适应平移敏感性的缺陷,该算法使用特定的卷积层生成包含目标空
间位置信息的位置敏感分布图(Position Sensitive Score Map);ROI Pooling 层后不再连接全连接层,避免重复计算。
R-FCN的准确率达到83.6%,测试每张图片平均花费170ms,比Faster-RCNN快了2.5-20倍。但是R-FCN在得到Score map需要生成一个随类别数线性增长的channel数,这一过程虽然提升了目标检测精度,但减慢了检测速度,导致其难以满足实时性要求。
2.1.6 Mask R-CNN
M
图4 Mask R-CNN结构示意图
实例分割要求实例定位的精准度达到像素级,而Faster R-CNN因为ROI Pooling 层的等比例缩放过程中引入了误差,导致空间量化较为粗糙,无法准确定位。Mask R-CNN 提出双线性差值RoIAlign获得更准确的像素信息,使得掩码(mask)准确率提升10%到50%;Mask R-CNN 还使用ResNeXt[28]基础网络,在COCO数据集[29]上的检测速度为5f/s,检测准确性 FastR-CNN的19.7%提升至39.8%。
Mask R-CNN在检测精度、实例分割方面都达到目前最高的层次。其后一些算法在性能上有所提升,但基本维持在同一水平。但是该算法的检测速度依旧难以满足实时要求,并且实例分割目前也还面临着标注代价过于昂贵的问题。
2.2 基于回归的目标检测算法
基于回归的目标检测框架不需要产生候选窗口,直接将待检测的图像送入目标窗口,得到目标物体所在的位置。
2.2.1 YOLO
从R-CNN到Faster R-CNN,目标检测始终遵循“region proposal+分类”的思路,训练两个模型必然导致参数、训练量的增加,影响训练和检测的速度。由此,YOLO[30]提出了一种“single-stage”的思路。
如图5所示,YOLO将图片划分为S×S的网格(cell),各网格只负责检测中心落在该网格的目标,每个网格需要预测两个尺度的bounding box和类别信息,一次性预测所有区域所含目标的bounding box、目标置信度以及类别概率完成检测。

图5 YOLO网格划分示意
YOLO采用以cell为中心的多尺度区域取代region proposal,舍弃了一些精确度以换取检测速度的大幅提升,检测速度可以达到45f/s,足以满足实时要求;检测精度为63.4%,较Faster R-CNN的73.2%,差距较大。
YOLO在极大提高检测速度的情况下,也存在以下问题:
(1)因为每个网格值预测两个bounding box,且类别相同,因此对于中心同时落在一个网格总的物体以及小物体的检测效果差,多物体环境下漏检较多。
(2)由于YOLO关于定位框的确定略显粗糙,因此其目标位置定位准确度不如Fast-RCNN。
(3)对于外型非常规的物体检测效果不佳。
2.2.2 SSD
Faster R-CNN检测检测精度高但检测速度慢,YOLO检测精度不高但检测速度快,SSD[31]则结合两者的优点,在YOLO的基础上借鉴了RPN的思路,在保证高精度检测的同时,兼顾检测速度。
如图6所示,因为不同层的特征图具有对应大小的感受野,特定层的特征图只需要训练对应尺度的对象检测。因此,SSD结合高层和底层的特征图,使用多尺度区域特征进行回归。
SSD300的mAP能达到73.2%,基本与Faster R-CNN(VGG16)持平,而检测速度达到59f/s,比Faster R-CNN快6.6倍。
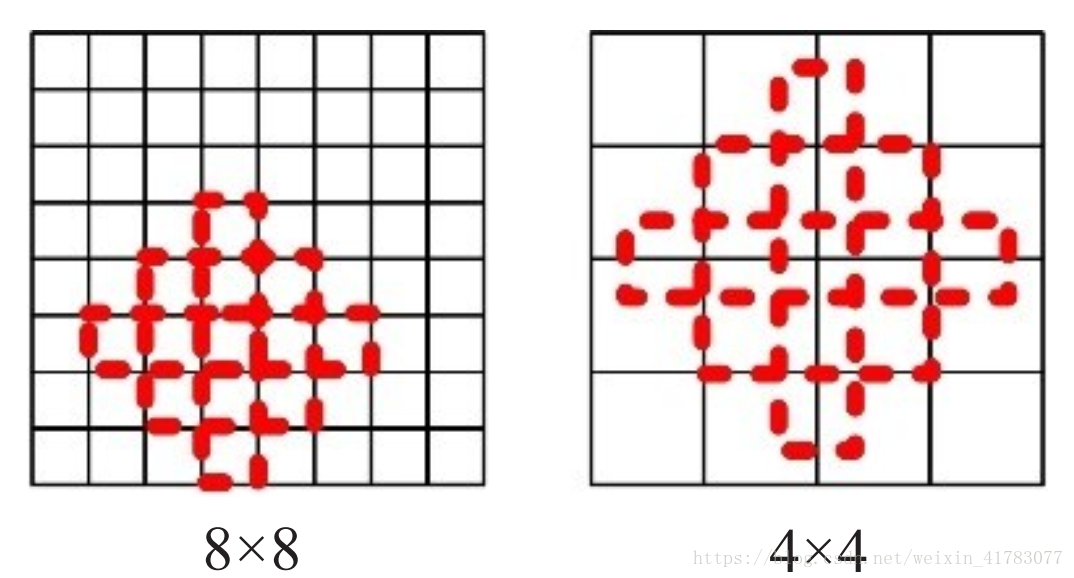
图 6 特征图感受野示意图
然而 SSD具有以下问题:
(1)小目标对应到特征图中很小的区域,无法得到充分训练,因此 SSD 对于小目标的检测效果依然不理想。
(2)无候选区域时,区域回归难度较大,容易出现难以收敛等问题。
(3)SSD不同层的特征图都作为分类网络的独立输入,导致同一个物体被不同大小的框同时检测,重复运算。
3 深度学习算法在医学影像领域的应用
(需要查看请联系博主)
4 思考与展望
基于深度学习的目标检测算法在检测精度以及检测速度上,较传统方法获得了极大的提高,但依然面临这一些问题:
(1)对于小数据量,目前的框架可能无法得到好的结果。目前的算法,大多使用了迁移学习,也就是先在现有的大数据集中进行训练,再将训练好的“半成品”做fine-tune操作。若目标数据不在ImageNet等数据集中,训练效果要视目标与大数据集相关程度而定。DSOD[47]算法虽然设计了一种从零开始训练的网络,也取得了不错的效果,但是其检测速度尚有待提升。
(2)深度学习算法的解释性差,特别是在更深的层次上,很多时候只能依靠测试和经验来猜测其有效或无效的原因,对于中间的过程缺少明确的解释,更像是一个黑盒。
(3)计算强度大。GPU的使用,提升了计算机的运算能力,但是很多操作依然过于庞大。如何简化、复用计算的同时,尽可能保证准确率,可能会是一个可以创新的点。
(4)对于场景信息、语义信息等图像中原有信息的利用不充分,造成一些有效信息的损失。
(5)无论是R-CNN系列还是SSD等算法,始终无法在小目标检测问题上获得令人满意的效果。就目前算法而言,为保证检测速度,通常减少特征金字塔的图像,以减少计算量,但这必然导致小目标在特征图上得不到充分训练;如R-SSD增加特征图数量,损失了检测速度。此问题与问题(3)有一定相通之处。
针对上述问题以及近几年研究趋势,本文对目标检测算法未来的发展方向做出讨论:
(1)更多更全面的数据集。目前有两种解决思路:一种是人工手动标注,对于小数据量而言,操作简单且能保证较高正确率,但对大数据量以及物体分割要求精准标注的数据时,力有不逮;另一种是使用平行视觉方法,旨在利用人工场景模拟实际场景,通过计算实验对模型进行设计和评估,平行执行在线优化视觉系统。平行视觉如果实现,那么将解决标注数据集不足的问题,促进目标检测发展。
(2)更多的计算共享。不论是R-CNN系列还是基于回归的检测算法,都是为了让不同的ROI之间的计算量得到更多的共享,以达到加快运算的目的。
(3)RNN思想的尝试。图像本身是包含上下文信息的,这是人类做出某些判断的依据。深度学习是一种类人的“学习”方式,结合深度学习中的循环神经网络思想是一种较可能实现的思路。另外,结合具体场景及语意信息,真正去“理解”场景也是一种思路。
(4)更具体的应用场景。Wang等人[48]提出一种利用卷积网络检测视频中显著目标的模型;Li等人[49]提出一种检测小型交通标志的网络;Dong[50]和Chen等人[51]探索如何将自然环境中的目标检测转换为3D;Dave等人[52]更关注对目标具体动作的识别。可以看出,目标检测,特别是基于深度学习的目标检测,正在向着更具体、更实际的场景发展。
(5)“新”神经网络的应用。从AlexNet到VGG再到ResNet和ResNext,基础网络的改进,也是目标检测效果不断提升原因之一。早在2011年,被誉为“神经网络之父”的Hinton就提出capsule[53]的概念。他在2017年的论文中提出了捕捉空间结构信息的capsule概念,用向量输出代替标量输出,改善CNN网络各特征之间联系缺失,需要大量数据集的问题。
5 总结
从最初的人为寻找特征到最近的基于深度学习的目标检测算法,可以看出对于目标检测的要求始终是快速、精准以及适用范围广。就目前来说,传统的目标检测方法仍在使用,且在一段时间内仍会有一定市场。传统的目标检测技术对数据量要求少,在针对数据来源不够丰富的项目时,可能会取得比深度学习更好的效果。但是将深度学习应用到目标检测中是可以预见的主流趋势。特别是随着硬件设备性能的提升,一定范围内的运算量处理将不会再成为实时检测的掣肘。
如何利用上下文关联信息、场景信息和语义信息,将会是接下来目标检测的一个重要研究方向。假使平行视觉的思路切实可行,那么数据集标注困难、数据量不足的问题,将获得较好的解决。另外,如何更好解决与训练集关联性不大的小数据集检测问题,也是一个比较重要的研究方向。Hinton的capsule能否获得比传统CNN更好的效果,也需要进行进一步的研究。
参考文献
[1] C. Szegedy, A. Toshev, and D. Erhan, “Deep Neural Networks for Object Detection,” Adv. Neural Inf. Process. Syst., 2013.
[2] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object Detection with Discriminative Trained Part Based Models,” IEEE Trans. Pattern Anal. Mach. Intell., 2010.
[3] P. Dollar, R. Appel, S. Belongie, and P. Perona, “Fast feature pyramids for object detection,” IEEE Trans. Pattern Anal. Mach. Intell., 2014.
[4] J. Gall and V. Lempitsky, “Class-specific hough forests for object detection,” in 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2009, 2009.
[5] A. Tigadi, R. Gujanatti, and A. Gonchi, “Advanced Driver Assistance Systems,” Int. J. Eng. Res. Gen. Sci., 2016.
[6] A. Jazayeri, H. Cai, J. Y. Zheng, and M. Tuceryan, “Vehicle Detection and Tracking in Car Video Based on Motion Model,” Intell. Transp. Syst. IEEE Trans., 2011.
[7] C. Caraffi, T. Vojir, J. Trefný, J. Šochman, and J. Matas, “A system for real-time detection and tracking of vehicles from a single car-mounted camera,” in IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, 2012.
[8] M. Wang, W. Daamen, S. P. Hoogendoorn, and B. Van Arem, “Driver assistance systems modeling by model predictive control,” IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, 2012.
[9] H. Cho, Y. W. Seo, B. V. K. V. Kumar, and R. R. Rajkumar, “A multi-sensor fusion system for moving object detection and tracking in urban driving environments,” in Proceedings - IEEE International Conference on Robotics and Automation, 2014.
[10] J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Z. Kolter, D. Langer, O. Pink, V. Pratt, M. Sokolsky, G. Stanek, D. Stavens, A. Teichman, M. Werling, and S. Thrun, “Towards fully autonomous driving: Systems and algorithms,” in IEEE Intelligent Vehicles Symposium, Proceedings, 2011.
[11] X. Zhang, Y.-H. Yang, Z. Han, H. Wang, and C. Gao, “Object Class Detection: A Survey,” ACM Comput. Surv., 2013.
[12] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. IEEE, 1998.
[13] J. R. R. Uijlings, K. E. A. Van De Sande, T. Gevers, and A. W. M. Smeulders, “Selective search for object recognition,” Int. J. Comput. Vis., 2013.
[14] C. L. Zitnick and P. Dollár, “Edge boxes: Locating object proposals from edges,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2014.
[15] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Adv. Neural Inf. Process. Syst., 2012.
[16] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, K. He, X. Zhang, S. Ren, J. Sun, A. Rajkomar, S. Lingam, A. G. Taylor, M. Blum, J. Mongan, Y. Gong, K. H. T. Leung, A. T. Toshev, S. Ioffe, Y. Jia, K. He, X. Zhang, S. Ren, J. Sun, Z. Z. Z. Wang, X. X. Wang, G. Wang, O. M. Parkhi, A. Vedaldi, A. Zisserman, others, O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, others, L. Wang, S. Guo, W. Huang, Y. Xiong, Y. Qiao, C. Szegedy, S. Ioffe, V. Vanhoucke, A. A. Alemi, K. He, X. Zhang, S. Ren, J. Sun, G. Böning, J. F. Kahn, D. Kaul, R. Rotzinger, P. Freyhardt, M. Pavel, F. Streitparth, K. Simonyan, A. Zisserman, L. C. Gansel, N. Bloecher, O. Floerl, J. Guenther, K. Kang, H. H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Z. Z. Wang, R. Wang, X. X. Wang, others, X. He, L. Liao, H. Zhang, L. Nie, X. Hu, T.-S. Chua, W. Liu, Z. Z. Z. Wang, X. Liu, N. Zeng, Y. Y. Liu, F. E. Alsaadi, H. H. Li, L. Zhang, X. Zhou, B. Huang, A. G. Trofimov, B. M. Velichkovskiy, S. L. Shishkin, S. Wu, S. Zhong, Y. Y. Liu, X. He, L. Liao, H. Zhang, L. Nie, X. Hu, T.-S. Chua, R. Ramachandra, S. Y. McGrew, J. C. Baxter, J. R. Howard, K. S. Elmslie, N. Vervliet, O. Debals, L. Sorber, and L. De Lathauwer, “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.,” Proc. IEEE Int. Conf. Comput. Vis., 2017.
[17] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2014.
[18] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (VOC) challenge,” Int. J. Comput. Vis., 2010.
[19] Jia Deng, Wei Dong, R. Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009.
[20] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,” IEEE Trans. Pattern Anal. Mach. Intell., 2015.
[21] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2006.
[22] R. Girshick, “Fast R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision, 2015.
[23] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” Int. Conf. Learn. Represent., 2015.
[24] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” IEEE Trans. Pattern Anal. Mach. Intell., 2017.
[25] L. Gi. Roberts, “Machine perception of three-dimensional solids,” 1965.
[26] J. Canny, “A Computational Approach to Edge Detection,” IEEE Trans. Pattern Anal. Mach. Intell., 1986.
[27] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision, 2017.
[28] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, 2017.
[29] T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2014.
[30] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “(2016 YOLO)You Only Look Once: Unified, Real-Time Object Detection,” Cvpr 2016, 2016.
[31] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2016.
[32] Y. Al-Kofahi, W. Lassoued, W. Lee, and B. Roysam, “Improved automatic detection and segmentation of cell nuclei in histopathology images,” IEEE Trans. Biomed. Eng., 2010.
[33] A. Oliver, J. Freixenet, J. Martí, E. Pérez, J. Pont, E. R. E. Denton, and R. Zwiggelaar, “A review of automatic mass detection and segmentation in mammographic images,” Med. Image Anal., 2010.
[34] D. Rey, G. Subsol, H. Delingette, and N. Ayache, “Automatic detection and segmentation of evolving processes in 3D medical images: Application to multiple sclerosis,” Med. Image Anal., 2002.
[35] H. C. Shin, H. R. Roth, M. Gao, L. Lu, Z. Xu, I. Nogues, J. Yao, D. Mollura, and R. M. Summers, “Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning,” IEEE Trans. Med. Imaging, 2016.
[36] R. K. Samala, H.-P. Chan, L. Hadjiiski, M. A. Helvie, J. Wei, and K. Cha, “Mass detection in digital breast tomosynthesis: Deep convolutional neural network with transfer learning from mammography,” Med. Phys., 2016.
[37] N. Tajbakhsh, J. Y. Shin, S. R. Gurudu, R. T. Hurst, C. B. Kendall, M. B. Gotway, and J. Liang, “Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning?,” IEEE Trans. Med. Imaging, 2016.
[38] R. Sa, W. Owens, R. Wiegand, M. Studin, D. Capoferri, K. Barooha, A. Greaux, R. Rattray, A. Hutton, J. Cintineo, and V. Chaudhary, “INTERVERTEBRAL DISC DETECTION IN X-RAY IMAGES USING FASTER R-CNN State University of New York ( SUNY ) at Buffalo Spine Metrics , Inc . University of Bridgeport College of Chiropractic Academy of Chiropractic,” pp. 564–567, 2017.
[39] J. Liu, D. Wang, L. Lu, Z. Wei, L. Kim, E. B. Turkbey, B. Sahiner, N. A. Petrick, and R. M. Summers, “Detection and diagnosis of colitis on computed tomography using deep convolutional neural networks,” Med. Phys., 2017.
[40] R. Ben-Ari, A. Akselrod-Ballin, L. Karlinsky, and S. Hashoul, “Domain specific convolutional neural nets for detection of architectural distortion in mammograms,” in Proceedings - International Symposium on Biomedical Imaging, 2017.
[41] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal Loss for Dense Object Detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2017.
[42] R. Platania, J. Zhang, S. Shams, K. Lee, S. Yang, and S. J. Park, “Automated breast cancer diagnosis using deep learning and region of interest detection (BC-DROID),” in ACM-BCB 2017 - Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, 2017.
[43] Z. Cao, L. Duan, G. Yang, T. Yue, Q. Chen, H. Fu, and Y. Xu, Breast Tumor Detection in Ultrasound Images Using Deep Learning. 2017.
[44] N. Li, H. Liu, B. Qiu, W. Guo, S. Zhao, K. Li, and J. He, “Detection and Attention: Diagnosing Pulmonary Lung Cancer from CT by Imitating Physicians,” 2017.
[45] B. D. De Vos, J. M. Wolterink, P. A. De Jong, M. A. Viergever, and I. B. T.-M. I. 2016: I. P. Išgum, “2D image classification for 3D anatomy localization: employing deep convolutional neural networks,” 2016, p. 97841Y.
[46] H. R. Roth, L. Lu, A. Seff, K. M. Cherry, J. Hoffman, S. Wang, J. Liu, E. Turkbey, and R. M. Summers, “A New 2.5D Representation for Lymph Node Detection Using Random Sets of Deep Convolutional Neural Network Observations,” in Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2014: 17th International Conference, Boston, MA, USA, September 14-18, 2014, Proceedings, Part I, 2014.
[47] Z. Shen, Z. Liu, J. Li, Y. G. Jiang, Y. Chen, and X. Xue, “DSOD: Learning Deeply Supervised Object Detectors from Scratch,” in Proceedings of the IEEE International Conference on Computer Vision, 2017.
[48] W. Wang, J. Shen, and L. Shao, “Video Salient Object Detection via Fully Convolutional Networks,” IEEE Trans. Image Process., 2018.
[49] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, “Perceptual Generative Adversarial Networks for Small Object Detection,” Cvpr, 2017.
[50] J. Dong, X. Fei, and S. Soatto, “Visual-Inertial-Semantic Scene Representation for 3D Object Detection,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[51] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3D Object Detection Network for Autonomous Driving,” in CVPR, 2017.
[52] A. Dave, O. Russakovsky, and D. Ramanan, “Predictive-corrective networks for action detection,” in Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, 2017.
[53] S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic Routing Between Capsules,” no. Nips, 2017.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)