深度学习3:手动实现L2正则化(L2 Regularization)
在神经网络中,正则化的作用是防止过拟合,本文将结合一个实例来讲解神经网络中的L2正则化,并手动(不使用框架)实现出来。先来看代码运行结果:增加L2正则化之前增加L2正则化之后:L2正则化为:λ2 m ||W|| 2 \frac {\lambda}{2 \text{ }m}||W||^2, 其中λ \lambda是超参数, m是一个batch中数据个数, 除以2的原因是在求导的时候抵消掉
在神经网络中,正则化的作用是防止过拟合,本文将结合一个实例来讲解神经网络中的L2正则化,并手动(不使用框架)实现出来。
先来看代码运行结果:
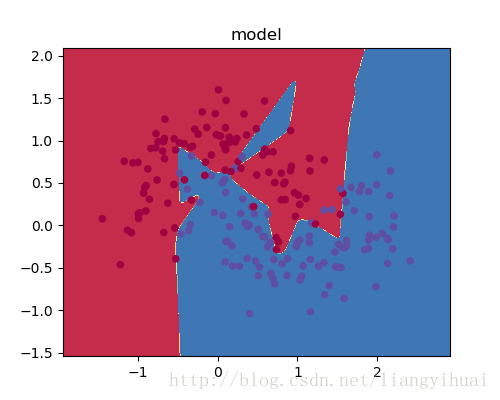
增加L2正则化之前
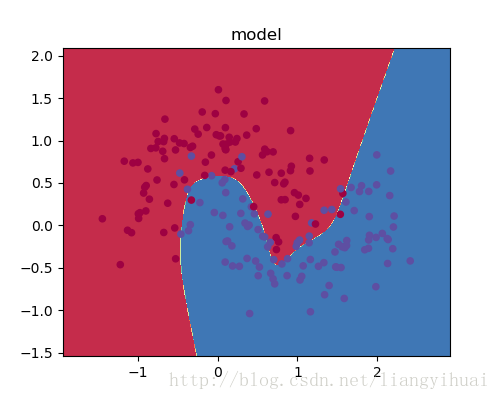
增加L2正则化之后:
L2正则化为: λ2 m ||W|| 2 , 其中 λ 是超参数, m是一个batch中数据个数, 除以2的原因是在求导的时候抵消掉。
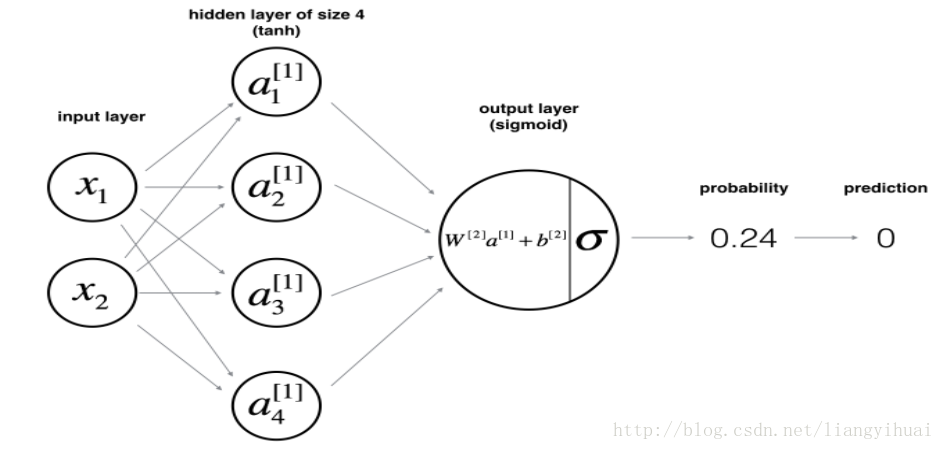
这个神经网络有两个输入节点和一个输出节点。该模型可以完成简单的二分类功能。其中,增加L2正则化之后,前向传播的公式不变,代价函数和backward propogation需要修改。
原本的cost函数由:
变成:
其中,
∑ k ∑ j W [l]2 k,j
表示第
l
层W参数的和,实际上
np.sum(np.square(Wl))对于backward propogation, 原本的公式为:

变为(其他的公式不变):
对应的,我们知道该网络模型的前向传播公式为:
现在就可以实现L2正则化了。因为L2正则化是在上面的模型上面增加进去了,所以,我们先来看一下在没有正则化的情况下如何实现上图所示的神经网络模型。
1. 生成模型训练数据:
def get_case_data(example_num = 200):
"""
获取点数据,需要进一步处理
:param example_num: 点的个数
:return:
"""
np.random.seed(6)
X, y = sklearn.datasets.make_moons(example_num, noise=0.30)
return X, y;- 代价函数
def cost_compute(A2, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters['W1']
W2 = parameters['W2'];
loss = Y * np.log(A2) + (1-Y)*np.log(1-A2+10**(-10))
cost1 = -np.sum(loss)/m
return cost1增加L2正则化之后变为:
def cost_compute(A2, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters['W1']
W2 = parameters['W2'];
loss = Y * np.log(A2) + (1-Y)*np.log(1-A2+10**(-10))
cost1 = -np.sum(loss)/m
l2_regularization_cost = lambd*(np.sum(np.square(W1)) + np.sum(np.square(W2)))/m/2
return cost1 + l2_regularization_cost3.
反向传播
def backward_propagate(X, Y, parameters, cache, lambd):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
A1 = cache['A1']
Z1 = cache['Z1']
A2 = cache['A2']
m = Y.shape[1]
dZ2 = A2 - Y
dW2 = np.dot(dZ2, A1.T)/m
db2 = np.sum(dZ2, axis=1, keepdims=True)/m
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1-np.power(A1, 2))
dW1 = np.dot(dZ1, X.T)/m
db1 = np.sum(dZ1, axis=1, keepdims=True)/m
W1 -= dW1
b1 -= db1
W2 -= dW2
b2 -= db2
return {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}增加正则化之后变为:
def backward_propagate(X, Y, parameters, cache, lambd):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
A1 = cache['A1']
Z1 = cache['Z1']
A2 = cache['A2']
m = Y.shape[1]
dZ2 = A2 - Y
dW2 = np.dot(dZ2, A1.T)/m + lambd / m * W2
db2 = np.sum(dZ2, axis=1, keepdims=True)/m
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1-np.power(A1, 2))
dW1 = np.dot(dZ1, X.T)/m + lambd / m * W1
db1 = np.sum(dZ1, axis=1, keepdims=True)/m
W1 -= dW1
b1 -= db1
W2 -= dW2
b2 -= db2
return {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}只需要改变dW2和dW1, 对cost表达式求偏导数之后,只有这两项的偏导数才有W2或者W1.
其他的地方跟没有增加L2正则化是一样的。下面是完整的代码:
完整的代码
# encoding=utf8
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib
learning_rate = 0.05
input_node_num = 2;
hidden_node_num = 8;
output_node_num = 1;
example_num = 200; # 输入数据点的个数
epoch_num = 30000; #迭代次数
# lambd = 0.001 # L2 正则化参数
lambd = 0.01 # L2 正则化参数
def get_case_data(example_num = 200):
"""
获取点数据,需要进一步处理
:param example_num: 点的个数
:return:
"""
np.random.seed(6)
X, y = sklearn.datasets.make_moons(example_num, noise=0.30)
return X, y;
def process_data(X, Y):
"""
处理原始数据集
:param X:
:param Y: label
:return:
"""
Y = np.reshape(Y, (1, -1))
return X.T, Y;
def random_mini_batches(X, Y, batch_size=32):
"""
:param X:
:param Y:
:param batch_size:
:return:
"""
m = Y.shape[1]
permutation = np.random.permutation(Y.shape[1])
X_shuffle = X[:, permutation]
Y_shuffle = Y[:, permutation]
mini_batches = []
batch_num = m//batch_size
for i in range(batch_num):
mini_batch_x = X_shuffle[:, i * batch_size: (i + 1) * batch_size]
mini_batch_y = Y_shuffle[:, i * batch_size: (i + 1) * batch_size]
mini_batch = (mini_batch_x, mini_batch_y)
mini_batches.append(mini_batch)
if batch_num * batch_size < m:
mini_batch_x = X_shuffle[:, batch_num * batch_size: m]
mini_batch_y = Y_shuffle[:, batch_num * batch_size: m]
mini_batch = [mini_batch_x, mini_batch_y]
mini_batches.append(mini_batch)
mini_batches = np.array(mini_batches)
return mini_batches
def initialize_parameters():
"""
初始化参数
:return:
"""
W1 = np.random.randn(hidden_node_num, input_node_num) * 0.01;
b1 = np.zeros((hidden_node_num, 1))
W2 = np.random.randn(output_node_num, hidden_node_num) * 0.01;
b2 = np.zeros((output_node_num, 1))
assert (W1.shape == (hidden_node_num, input_node_num))
assert (b1.shape == (hidden_node_num, 1))
assert (W2.shape == (output_node_num, hidden_node_num))
assert (b2.shape == (output_node_num, 1))
return {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
def sigmoid(x):
s = 1 / (1 + (np.exp(-x)))
return s;
def forward_propagate(X, parameters):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
z1 = np.dot(W1, X) + b1
a1 = np.tanh(z1)
z2 = np.dot(W2, a1) + b2
a2 = sigmoid(z2)
cache = {'A1':a1, 'Z1':z1, 'A2':a2, 'Z2':z2}
return cache
def cost_compute(A2, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters['W1']
W2 = parameters['W2'];
loss = Y * np.log(A2) + (1-Y)*np.log(1-A2+10**(-10))
cost1 = -np.sum(loss)/m
l2_regularization_cost = lambd*(np.sum(np.square(W1)) + np.sum(np.square(W2)))/m/2
return cost1 + l2_regularization_cost
def backward_propagate(X, Y, parameters, cache, lambd):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
A1 = cache['A1']
Z1 = cache['Z1']
A2 = cache['A2']
m = Y.shape[1]
dZ2 = A2 - Y
dW2 = np.dot(dZ2, A1.T)/m + lambd / m * W2
db2 = np.sum(dZ2, axis=1, keepdims=True)/m
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1-np.power(A1, 2))
dW1 = np.dot(dZ1, X.T)/m + lambd / m * W1
db1 = np.sum(dZ1, axis=1, keepdims=True)/m
W1 -= dW1
b1 -= db1
W2 -= dW2
b2 -= db2
return {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
def do_predict(X, parameters):
cache = forward_propagate(X, parameters)
return np.around(cache['A2'])
def build_model():
X_original, Y_original = get_case_data(example_num)
X, Y = process_data(X_original, Y_original)
assert (Y.shape == (1, example_num))
assert (X.shape == (2, example_num))
parameters = initialize_parameters()
for i in range(epoch_num):
mini_batches = random_mini_batches(X, Y)
for j in range(mini_batches.shape[0]):
x_mini_batch, y_mini_batch = mini_batches[j]
cache = forward_propagate(x_mini_batch, parameters=parameters)
A2 = cache['A2']
cost = cost_compute(A2, y_mini_batch, parameters, lambd)
parameters = backward_propagate(x_mini_batch, y_mini_batch, parameters, cache, lambd)
if i % 300 == 0:
print(cost)
def predict(X):
return do_predict(X.T, parameters)
matplotlib.rcParams['figure.figsize'] = (5.0, 4.0)
plot_decision_boundary(X_original, Y_original, lambda x: predict(x))
# plt.scatter(X_original[:, 0], X_original[:, 1], c=Y_original, s=20, cmap=plt.cm.Spectral)
plt.title("model")
plt.show()
def plot_decision_boundary(X, y, pred_func):
"""
可视化结果
:param X:
:param y:
:param pred_func: 模型的predict函数
"""
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])#
Z = np.reshape(Z, xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, cmap=plt.cm.Spectral)
build_model()总结:
L2正则化是常用的避免模型过拟合的方法。通过在代价函数中增加了 λ2 m ||W|| 2 ,所以,在反向传播求导的时候需要做适当的修改。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)