深度学习优化函数详解(2)-- SGD 随机梯度下降
深度学习优化函数详解系列目录深度学习优化函数详解(0)– 线性回归问题深度学习优化函数详解(1)– Gradient Descent 梯度下降法深度学习优化函数详解(2)– SGD 随机梯度下降深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降深度学习优化函数详解(4)– momentum 动量法深度学习优化函数详解(5)– Neste...
深度学习优化函数详解系列目录
本系列课程代码,欢迎star:
https://github.com/tsycnh/mlbasic
深度学习优化函数详解(0)-- 线性回归问题
深度学习优化函数详解(1)-- Gradient Descent 梯度下降法
深度学习优化函数详解(2)-- SGD 随机梯度下降
深度学习优化函数详解(3)-- mini-batch SGD 小批量随机梯度下降
深度学习优化函数详解(4)-- momentum 动量法
深度学习优化函数详解(5)-- Nesterov accelerated gradient (NAG)
深度学习优化函数详解(6)-- adagrad
本文延续该系列的上一篇 深度学习优化函数详解(1)-- Gradient Descent 梯度下降法
上文讲到的梯度下降法每进行一次 迭代 都需要将所有的样本进行计算,当样本量十分大的时候,会非常消耗计算资源,收敛速度会很慢。尤其如果像ImageNet那样规模的数据,几乎是不可能完成的。同时由于每次计算都考虑了所有的训练数据,也容易造成过拟合。在某种程度上考虑的太多也会丧失随机性 。于是有人提出,既然如此,那可不可以每一次迭代只计算一个样本的loss呢?然后再逐渐遍历所有的样本,完成一轮(epoch)的计算。答案是可以的,虽然每次依据单个样本会产生较大的波动,但是从整体上来看,最终还是可以成功收敛。由于计算量大大减少,计算速度也可以极大地提升。这种逐个样本进行loss计算进行迭代的方法,称之为 Stochasitc Gradient Descent 简称SGD。
注:目前人们提到的SGD一般指 mini-batch Gradient Descent,是经典SGD的一个升级。后面的文章会讲到。
公式推导
我们再来回顾一下参数更新公式。每一次迭代按照一定的学习率
α
\alpha
α 沿梯度的反方向更新参数,直至收敛
θ
t
+
1
=
θ
t
−
α
d
f
d
θ
\theta_{t+1}=\theta_{t}-\alpha\frac{df}{d\theta}
θt+1=θt−αdθdf
接下来我们回到房价预测问题上。线形模型:
y
p
,
i
=
a
x
i
+
b
y_{p,i}=ax_i+b
yp,i=axi+b
这是经典梯度下降方法求loss,每一个样本都要经过计算:
l
o
s
s
=
1
2
m
∑
i
=
1
m
(
y
p
,
i
−
y
i
)
2
{loss=\frac{1}{2m}\sum_{i=1}^m(y_{p,i}-y_i)^2 }
loss=2m1i=1∑m(yp,i−yi)2
这是SGD梯度下降方法:
l
o
s
s
=
1
2
(
y
p
,
i
−
y
i
)
2
{loss=\frac{1}{2}(y_{p,i}-y_i)^2 }
loss=21(yp,i−yi)2
要优化的参数有两个,分别是a和b,我们分别对他们求微分,也就是偏微分
∂
l
o
s
s
∂
a
=
(
a
x
i
+
b
−
y
i
)
x
i
\frac{\partial loss}{\partial a}=(ax_i+b-y_i)x_i
∂a∂loss=(axi+b−yi)xi
∂
l
o
s
s
∂
b
=
(
a
x
i
+
b
−
y
i
)
\frac{\partial loss}{\partial b}=(ax_i+b-y_i)
∂b∂loss=(axi+b−yi)
∂
l
o
s
s
∂
a
\frac{\partial loss}{\partial a}
∂a∂loss 记为
∇
a
\nabla a
∇a
∂
l
o
s
s
∂
b
\frac{\partial loss}{\partial b}
∂b∂loss 记为
∇
b
\nabla b
∇b ,分别表示loss在a、b方向的梯度, 更新参数的方法如下
a
n
e
w
=
a
−
α
∇
a
a_{new}=a-\alpha \nabla a
anew=a−α∇a
b
n
e
w
=
b
−
α
∇
b
b_{new}=b-\alpha \nabla b
bnew=b−α∇b
实验
直接看图
关于图中四个子图的意义,请参看 深度学习优化函数详解(1)-- Gradient Descent 梯度下降法
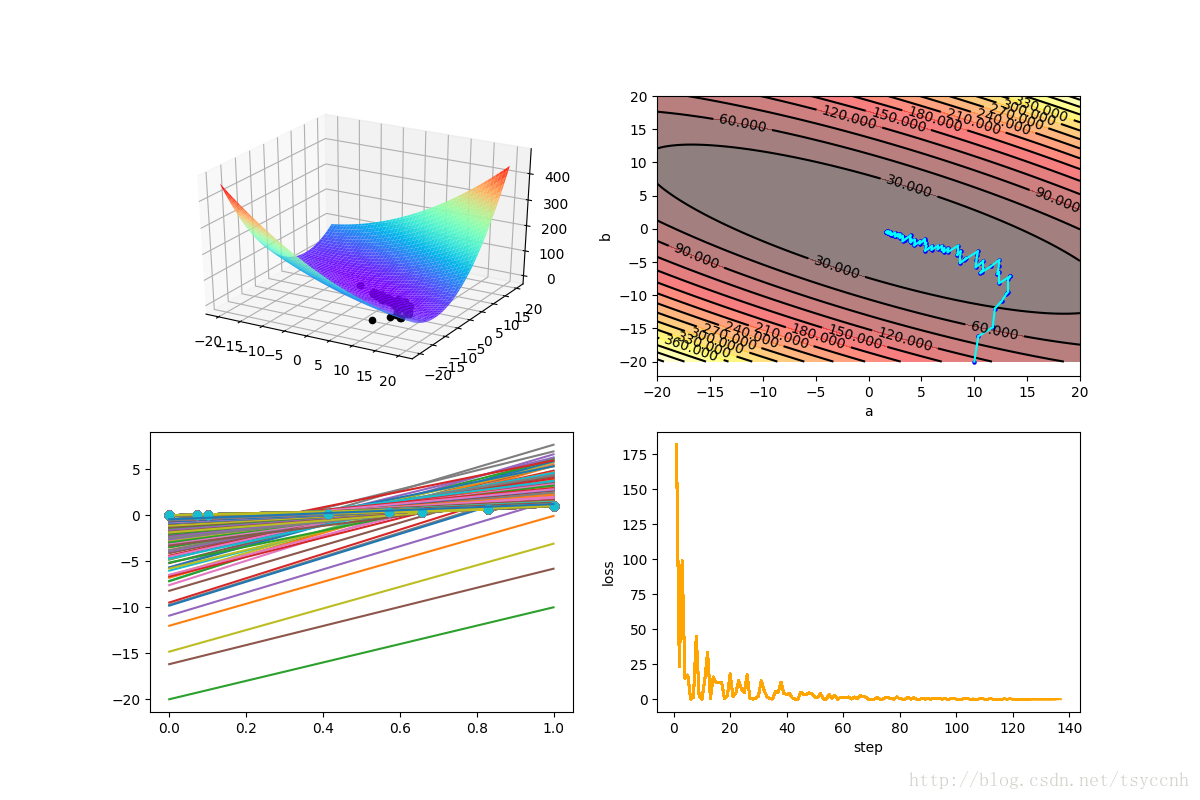
等高线图和loss图都很明显的表现了SGD的特点。总体上收敛,局部有一些震荡。
由于加入了随机的成分,有的时候可能算法有一点点走偏,但好处就是对于一些局部极小点可以从坑中跳出,奔向理想中的全局最优。
实验代码下载:https://github.com/tsycnh/mlbasic/blob/master/p2 origin SGD.py

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)