
ArrayList底层原理以及使用技巧
ArrayList简介ArrayList是我们在开发中非常常用的数据存储容器之一,其底层是数组实现的,我们可以在集合中存储任意类型的数据。ArrayList又是线程不安全的,这在接下来代码分析的过程中会有体现。ArrayList非常适合对元素进行查找,效率非常高。源码分析既然是分析源码,那我们先从构造函数开始。我们常用的构造函数有两个,分别是有参和无参的,如下图无参
ArrayList简介
ArrayList是我们在开发中非常常用的数据存储容器之一,其底层是数组实现的,我们可以在集合中存储任意类型的数据。ArrayList又是线程不安全的,这在接下来代码分析的过程中会有体现。ArrayList非常适合对元素进行查找,效率非常高。
源码分析
既然是分析源码,那我们先从构造函数开始。我们常用的构造函数有两个,分别是有参和无参的,如下图

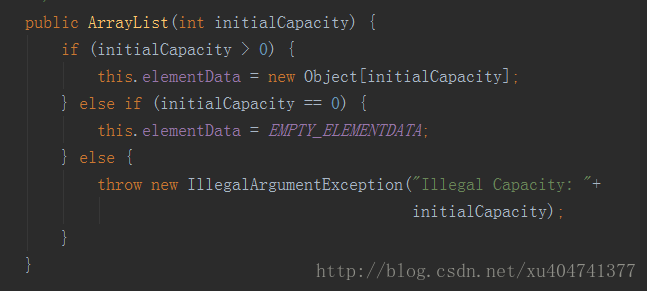
无参的构造函数十分简单,只有一行代码。elementData是一个Object型的数组,DEFAULTCAPACITY_MPTY_ELEMENTDATA是一个空的Object型数组。再来看看有参的,其实参数的含义就是这个集合的容量,代码很简单,一看就懂,如果指定了长度的话,会让元素容易elementData指向一个新的数组,长度为传入的值,而如果传入的值为0的话,则指向EMPTY_ELEMENTDATA。EMPTY_ELEMENTDATA与DEFAULTCAPACITY_MPTY_ELEMENTDATA一样,都是一个空的Object型的数组,那么区别在哪里呢?接下来就是重点。要知道,我们声明了一个集合,目的是向其中添加元素,而区别就在添加的过程中提现出来了,请看添加方法,如下图
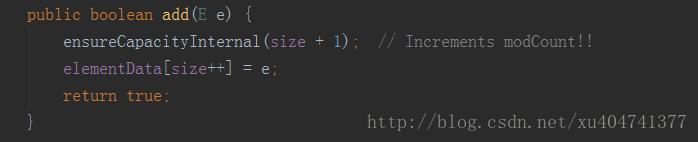
在添加元素之前,首先需要确保容量是否够用
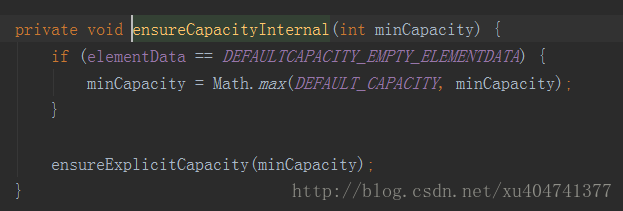
区别就在这里,如果我们一开始声明的是一个空参的构造函数,那么代码会走进第一个if语句,传入的minCapacity是1,那么最终计算得出minCapacity是等于DEFAULT_CAPACITY的,而DEFAULT_CAPACITY的值是10。也就是说,如果我们添加了一个默认的无参构造函数,在添加时,数组会将默认的数组长度变为10。说到这里,第一个使用技巧就出现了,如果我们很确定的知道我们要存储元素的数量,最好在声明集合的时候传入容量值。试想,如果我们只需要存储3个元素,而我们声明了一个空参的构造函数,那么集合的长度会是10,也就是说,数组有7个长度的空间被浪费了,这就是对内存的一种浪费。
接着往下走,之后会判断数组的容量是否够用,如果够用,那么不需要扩容,反之,则进行扩容,判断扩容代码没什么,很简单,但是扩容怎么办呢?数组一旦声明不是不能更改了吗?源码中是将数组进行copy,而copyOf的底层源码,是声明了一个新的数组,然后将原有的数组内容全复制进去,这样,就在不影响原有数据的基础上进行了数组扩容。说到这里,第一个使用技巧还是适用的。试想一下,我们需要保存1000个元素,而一开始默认长度是10,那么集合需要很多次扩容,每次扩容是上一次容量的1.5倍,每次扩容还要进行复制。如果不事先声明一个长度的话,使用效率会大大降低,即便是不知道具体数字,也可以指定一个大概的容量。
添加的方法说完了,接下来简单说一下删除方法,如下图
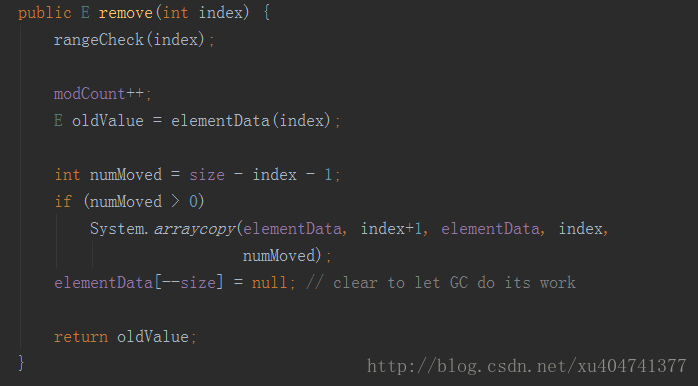
删除是每次进行数组复制,然后让旧的elementData置为null进行垃圾回收,代码很简单,一看就懂,但是我们可以从源码中去发现使用技巧。
查询的方法就更简单了,直接返回查询的对应数组中的值。
总结
1.在声明时尽量指定长度。
2.ArrayList底层是数组,数组是适合查询的,因为数组每个元素的内存空间是固定的,每次查询时,只需要去查询对应位置的内存空间,就可以很快找到相应的值。而数组不擅长的是添加和删除。试想,集合长度是100000,而我们在第2个位置添加了一个元素,导致的结果是从第3个开始后面每一个元素都要往后串一个元素内存空间那么大的位置。删除刚好相反,是向前串一个位置,这样的效率是很低的,元素越多,效率越低。而频繁的添加和删除,适用链表,LinkedList,可以参考我的另一篇博客http://blog.csdn.net/xu404741377/article/details/73526955

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)