今天课间的时候偶然看到了一个面试题:单链表的逆置,看了题解感觉乖乖的,貌似和以前看的版本不搭,于是重新进行了一番探究
单链表的逆置分为两种方法:头插法和就地逆置法,这两种方法虽然都能够达到逆置的效果,但还是有着不小的差别
头插法

算法思路:依次取原链表中的每一个节点,将其作为第一个节点插入到新链表中,指针用来指向当前节点,p为空时结束。
核心代码
void reverse(node*head)
{
node*p;
p=head->next;
head->next=NULL;
while(p)
{
q=p;
p=p->next;
q->next=head->next;
head->next=q;
}
}
以上面图为例子,说白了就是不断的将1后面的节点插入到head后面,即为头插法
完整代码
typedef struct node
{
int data;
struct node*next;
}node;
node*creat()
{
node*head,*p,*q;
char ch;
head=(node*)malloc(sizeof(node));
q=head;
ch='*';
puts("单链表尾插法,?结束");
while(ch!='?')
{
int a;
scanf("%d",&a);
p=(node*)malloc(sizeof(node));
p->data=a;
q->next=p;
q=p;
ch=getchar();
}
q->next=NULL;
return(head);
}
void print(node*a)
{
puts("print ");
a=a->next;
while(a!=NULL)
{
printf("%d ",a->data);
a=a->next;
}
}
void reverse(node*head)
{
node*p,*q;
p=head->next;
head->next=NULL;
while(p)
{
q=p;
p=p->next;
q->next=head->next;
head->next=q;
}
}
main()
{
node*a;
a=creat();
print(a);
reverse(a);
puts("\nhaved reversed:");
print(a);
return 0;
}
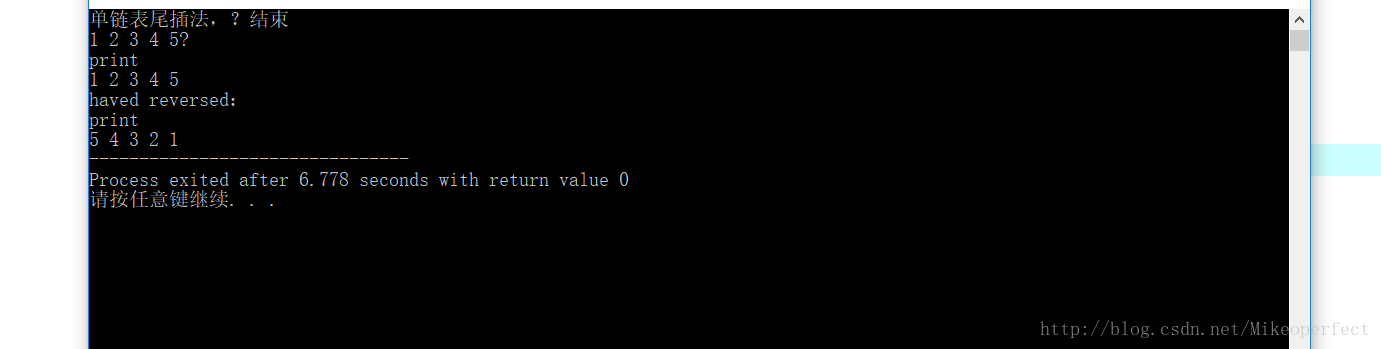
程序截图
就地逆置法
//单链表定义
typedef struct ListNode{
int m_nValue;
ListNode* pNext;
};
//单链表逆置实现
ListNode* ReverseList(ListNode* pHead)
{
if (pHead == NULL || pHead->pNext == NULL)
{
retrun pHead;
}
ListNode* pRev = NULL;
ListNode* pCur = pHead;
while(pCur != NULL)
{
ListNode* pTemp = pCur;
pCur = pCur->pNext;
pTemp->pNext = pRev;
pRev = pTemp;
}
return pRev;
}
下面我们来用图解的方法具体介绍整个代码的实现流程:
初始状态:
第一次循环:
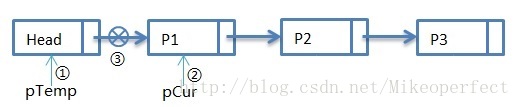
第一次循环过后,步骤①:pTemp指向Head,步骤②:pCur指向P1,步骤③:pTemp->pNext指向NULL。
此时得到的pRev为:
第二次循环:
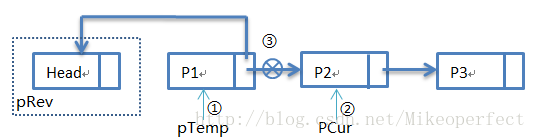
第二次循环过后,步骤①:pTemp指向P1,步骤②:pCur指向P2,步骤③:pTemp->pNext指向Head。
此时得到的pRev为:
第三次循环:
第三次循环过后:步骤①:pTemp指向P2,步骤②:pCur指向P3,步骤③:pTemp->pNext指向P1。
此时得到的pRev为:
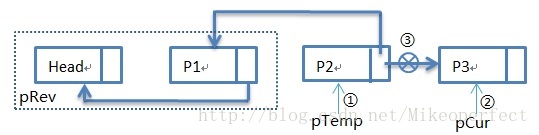
第四次循环:
第四次循环过后:步骤①:pTemp指向P3,步骤②:pCur指向NULL,步骤③:pTemp->pNext指向P2。
此时得到的pRev为:
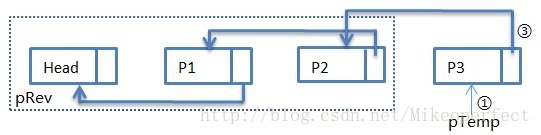
至此,单链表的逆置完成。
注就地逆置法转载出:灯火阑珊231
如果还没有看懂,可以去参考一下这个
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL)
return H;
node* p = H, *newH = NULL;
while (p != NULL)
{
node* tmp = p->next;
p->next = newH;
newH = p;
p = tmp;
}
return newH;
}
3、递归方式
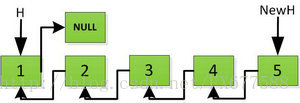
我们再来看看递归实现链表翻转的实现,前面非递归方式是从前面数1开始往后依次处理,而递归方式则恰恰相反,它先循环找到最后面指向的数5,然后从5开始处理依次翻转整个链表。
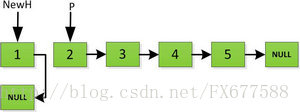
首先指针H迭代到底如下图所示,并且设置一个新的指针作为翻转后的链表的头。由于整个链表翻转之后的头就是最后一个数,所以整个过程NewH指针一直指向存放5的地址空间。
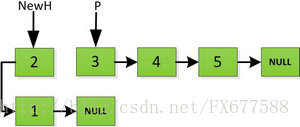
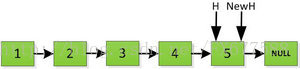 然后H指针逐层返回的时候依次做下图的处理,将H指向的地址赋值给H->next->next指针,并且一定要记得让H->next =NULL,也就是断开现在指针的链接,否则新的链表形成了环,下一层H->next->next赋值的时候会覆盖后续的值。
然后H指针逐层返回的时候依次做下图的处理,将H指向的地址赋值给H->next->next指针,并且一定要记得让H->next =NULL,也就是断开现在指针的链接,否则新的链表形成了环,下一层H->next->next赋值的时候会覆盖后续的值。
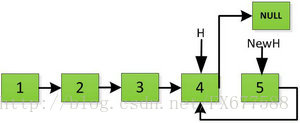 继续返回操作:
继续返回操作:
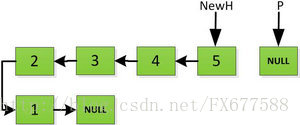
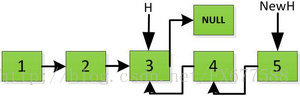 上图第一次如果没有将存放4空间的next指针赋值指向NULL,第二次H->next->next=H,就会将存放5的地址空间覆盖为3,这样链表一切都大乱了。接着逐层返回下去,直到对存放1的地址空间处理。
上图第一次如果没有将存放4空间的next指针赋值指向NULL,第二次H->next->next=H,就会将存放5的地址空间覆盖为3,这样链表一切都大乱了。接着逐层返回下去,直到对存放1的地址空间处理。
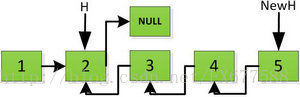 返回到头:
返回到头:
 4、迭代实现的程序
4、迭代实现的程序
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL)
return H;
node* newHead = In_reverseList(H->next);
H->next->next = H;
H->next = NULL;
return newHead;
}
5、整体实现的程序:
#include<iostream>
using namespace std;
struct node{
int val;
struct node* next;
node(int x) :val(x){}
};
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL)
return H;
node* p = H, *newH = NULL;
while (p != NULL)
{
node* tmp = p->next;
p->next = newH;
newH = p;
p = tmp;
}
return newH;
}
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL)
return H;
node* newHead = In_reverseList(H->next);
H->next->next = H;
H->next = NULL;
return newHead;
}
int main()
{
node* first = new node(1);
node* second = new node(2);
node* third = new node(3);
node* forth = new node(4);
node* fifth = new node(5);
first->next = second;
second->next = third;
third->next = forth;
forth->next = fifth;
fifth->next = NULL;
node* H1 = first;
H1 = reverseList(H1);
node* H2 = H1;
H2 = In_reverseList(H2);
return 0;
}
感谢原作者,转载请注明出处:
http://blog.csdn.net/FX677588/article/details/72357389
总结
头插法和就地逆置法是有区别的,其区别就在于逆置后的链表如果需要打印的话,那么头插法是从head开始的,而就地逆置则是从表尾开始的,从便捷性来说,头插法还是较之就地逆置法要好上那么一点点,当然因题而异了









 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)