Java容器学习笔记(一) 容器中基本概念及Collection接口相关知识
本篇文章主要是总结了java容器中的相关知识点,包括容器层次结构、类图结构,Collection接口的详细信息,以及Collection的一个重要子接口List接口的相关知识点总结。其中涉及到一些类如ArrayList、LinkedList、Vector、Stack、CopyOnWriteArrayList等的底层数据结构、实现机制及用法等的学习总结。 一.基本概念Java容器类库的用
本篇文章主要是总结了java容器中的相关知识点,包括容器层次结构、类图结构,Collection接口的详细信息,以及Collection的一个重要子接口List接口的相关知识点总结。其中涉及到一些类如ArrayList、LinkedList、Vector、Stack、CopyOnWriteArrayList等的底层数据结构、实现机制及用法等的学习总结。
Java容器类库的用途是保存对象,根据数据结构不同将其划分为两个不同的概念
(1) Collection,一个独立元素的序列,其中List按照元素的插入顺序保存元素,而set不能有重复元素,Queue按照先进先出(FIFO)的方式来管理数据,Stack按照后进先出(LIFO)的顺序管理数据。
(2) Map,一组键值对(key-value)对象的序列,可以使用key来查找value,其中key是不可以重复的,value可以重复。我们可以称其为字典或者关联数组。其中HashMap是无序的,TreeMap是有序的,WeakHashMap是弱类型的,Hashtable是线程安全的。
下面这张图来自于Thinking in Java Fourth Edition第十七章:
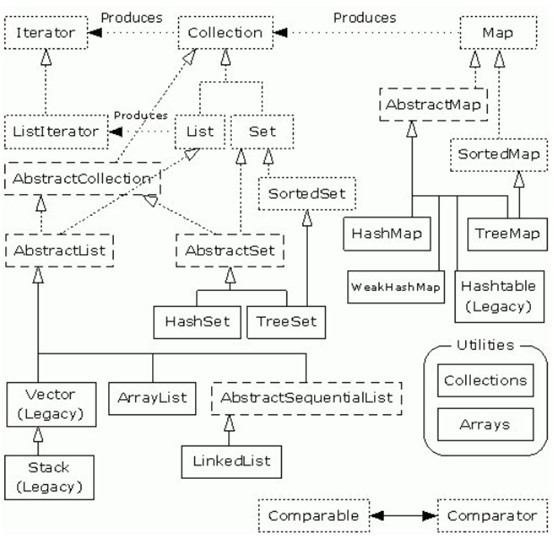
除上面图中画到的内容外在java.util.concurrent包中也实现了大量的线程安全的集合类,可以很方便的使用。如ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet等。
二.Collection接口
Ø 由集合类图结构可以得知Collection接口是Java语言中最基本的集合接口,在JDK中没有直接提供Collection接口的具体实现类,Collection的功能实现类主要是对它的两个更具体的子接口List和Set的具体实现类。但是在Collection接口中定义了一套通用操作的实现方法和命名规则。
Ø 在JDK帮助文档中可以看到Collection接口以及各个子接口、各种形式实现类的说明。
Ø 对Collection接口的实现类构造方法一般至少有下面两种:一个是void(无参数)构造方法,用于创建空的Collection对象实例;另一个是带有一个Collection类型参数的构造方法,用于创建一个具有与其参数相同元素的Collection对象实例。例如HashSet类的构造方法有下面四种:
a) HashSet():构造一个初始容量为16、加载因子为0.75的HashSet类的实例对象;
b) HashSet(Collection<? extends E> c):构造一个包含指定集合对象的HashSet类的对象实例。
c) HashSet(int initialCapacity):构造一个指定初始容量的HashSet类的实例对象。
d) HashSet(int initialCapacity, float loadFactor):构造一个指定初始容量以及指定加载因子的HashSet类的实例对象。
Ø Collection接口中共定义了15个通用的方法:
a) Collection接口方法清单
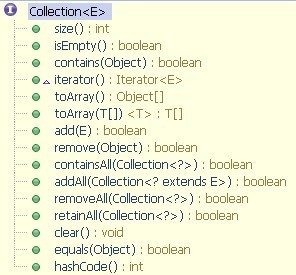
a) 添加和删除集合中的某个元素
• boolean add(E o) : 将指定的元素追加到集合当中
• boolean remove(Object o) : 将指定的元素从集合中删除
b) 查询与集合有关的数据
• int size() : 返回此集合中元素的个数
• boolean isEmpty() : 测试此集合是否为空
• boolean contains(Object element) : 测试此集合中是否有该元素
• Iterator<E> iterator() : 返回此集合中的各个元素进行迭代的迭代器
c) 对若干个元素以组为单位进行操作
• boolean containsAll(Collection<?> c) : 判断此集合是否包含给定的一组元素,包含返回true,否则false
• boolean addAll(Collection<? extends E> c) : 将指定集合中的所有元素都添加到当前集合中
• void clear() : 移除此集合中的所有元素
• boolean removeAll(Collection<?> c) : 移除此集合中那些也包含在指定集合中的元素(求集合的差集)
• boolean retainAll(Collection<?> c) : 仅保留此集合中那些也包含在指定集合中的元素(求集合的交集)
d) 将集合转换成Object类型的对象数组
• Object[] toArray() : 返回包含此集合中所有元素的数组
• <T> T[] toArray(T[] a) : 返回包含此集合中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同
1. List接口及其实现类
List接口中方法清单

List可以将元素维护在特定的序列中,并且允许一个相同元素在集合中多次出现。List接口在Collection接口的基础上增加了大量的方法,使得可以在List中间插入和移除元素。除了Abstract类之外,在学习中比较常用的类有ArrayList(基于数组实现),LinkedList(基于循环链表实现),Vector(基于数组实现,线程安全),Stack(是Vector的子类,基于数组实现),CopyOnWriteArrayList(基于数组实现,线程安全)
List接口中提供的面向位置操作的各种方法:(集合中已有的方法略去)
• void add(int index, E element) : 在列表的指定位置插入指定元素。
• boolean addAll(int index, Collection<? extends E> c) : 将指定集合中的所有元素插入到集合中的指定位置。
• E get(int index) : 返回集合中指定位置的元素。
• int indexOf(Object o) : 返回指定对象在集合中第一次出现的索引,从0位置开始,返回-1为不存在该元素。
• int lastIndexOf(Object O) : 返回指定对象在集合中最后一次出现的索引位置,返回-1为不存在。
• ListIterator<E> listIterator() : 以正确的顺序返回集合中元素的列表迭代器。
• ListIterator<E> listIterator(int index) : 以正确的顺序返回集合中元素的列表迭代器,从集合中指定的位置开始。
• E remove(int index) : 移除集合中指定位置的元素。
• E set(int index, E element) : 用指定元素替换集合中指定位置的元素。
• List<E> subList(int fromIndex, int toIndex) : 返回集合中指定的fromIndex(包括)和toIndex(不包括)之间的部分视图。
List接口提供了名称为ListIterator的特殊迭代器。
List在数据结构中分别表现为数组、向量、链表、堆栈、队列等形式。
Ø ArrayList的特点、实现机制及使用方法
a) ArrayList特点:
ArrayList顾名思义,它是用数组实现的一种线性表。常规数组不具备自动递增的功能,但是ArrayList在使用时我们不必考虑这个问题。可以直接按位置进行索引,查找和修改速度较快,缺点是插入或者删除速度较慢。在执行插入删除时调用的是System.arraycopy方法,是一个native方法。
b) ArrayList的实现机制:
在JDK源码中可以看到ArrayList总共只有两个属性,一个是Object数组类型的elementData,一个是int型的size。
在构造方法中也可以看到,无参构造方法调用的是this(10),调用的带一个参数的构造方法,默认无参构造方法分配一个size为10的数组。按照Collection接口中定义的构造方法,它必须有一个通过其它集合对象构造自身对象的方法。这是一个相对比较简单的线性表。并且JDK中提供了大量的比较好用的方法可以使用。该动态数组在存储空间不足时按照下面方法重新分配空间:
newCapacity = (oldCapacity*3)/2 + 1;
if(newCapacity < minCapacity) newCapacity = minCapacity;
c) 使用方法(ArrayList的使用方法其实是比较简单,但是也是比较常用和好用的,个人感觉)
下面例子为了尽可能多的用到ArrayList的方法,可能看起来没有多大意义
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ExampleForArrayList {
public static void main(String[] args) {
String[] str = new String[]{"My", "name", "is", "Wang", "Yan", "tao"};
List<String> ls1 = new ArrayList<String>(10);
//把数组中的数据添加到ls1中
for(int i=0; i<str.length; i++) {
ls1.add(str[i]);
}
//使用ls1来构造ls2
List<String> ls2 = new ArrayList<String>(ls1);
System.out.println("ls2中元素的个数:" + ls2.size());
System.out.println("is在ls2中的位置:" + ls2.indexOf("is"));
System.out.println("Wang在ls2中最后一次出现的位置:" + ls2.lastIndexOf("Wang"));
System.out.println("ls2中的所有元素:");
//这里使用iterator遍历
Iterator<String> it = ls2.listIterator();
while(it.hasNext()) {
System.out.println(it.next());
}
//我一般使用下面方法遍历,或者基本的for循环遍历
for(String tmp : ls2) {
System.out.println(tmp);
}
}
}Ø LinkedList的特点、实现机制及使用方法
a) LinkedList的特点:
现在发现java中类的命名真是太好了,比如这个吧,一看就知道它使用链表实现的。链表操作的优点就是插入删除比较快,但是不能按索引直接存取,所以执行更新操作比较快,执行查询操作比较慢。它的整体特性由于ArrayList。
b) LinkedList实现机制:
查看jdk源码可以得知每个元素在LinkedList中都是一个LinkedList.Entry的实例对象。该类定义如下:
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}在构造方法中这样的定义:
header.next = header.previous = header;
也就是说LinkedList底层使用一个循环双向链表实现的。
LinkedList实现了许多对first和last元素进行操作的方法,比如set、get、remove等。
虽然LinkedList获取指定位置的元素时较ArrayList按索引获取较慢,但是JDK中对get方法做了优化:
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}虽然还是顺序挨个查找,但是已经做了优化。size>>1 == size/2,移位运算要比除法运算效率高的多。
c) LinkedList和ArrayList的使用方法类似,只是看自己的需要进行选择了。除此之外LinkedList还实现了栈操作的所有方法。
Ø Vector的特点、实现机制及使用方法
a) Vector的特点:
ArrayList实现的是一种动态数组,LinkedList是一种双向循环链表,Vector并未在前两者的基础上做实现,而是直接实现了List接口。Vector中的所有方法前面都有一个synchronized关键字做修饰。Vector是有序可重复的。
b) Vector的实现机制:
我暂时还不理解为什么要实现Vector这个类,和ArrayList基本是一样的,不一样的是Vector是线程安全的,但是Collections里面提供了将非线程安全的集合转换成线程安全的集合的方法。
c) Vector的使用方法(与ArrayList使用方法类似)
Ø Stack的特点、实现机制及使用方法
a) Stack的特点:
Stack(栈)是一种后进先出的序列,主要操作有判空、压栈、退栈、取栈顶元素等。
b) Stack的实现机制:
Stack继承自Vector,同样使用数组保存数据,根据该数据结构的特点进行了限制性操作。JDK中共提供了6个方法用于实现特定要求的操作:
• Stack() : 构造一个空的栈
• empty() : 判断栈是否为空
• peek() : 查看栈顶元素并返回栈顶对象
• pop() : 删除栈顶元素并返回栈顶对象
• push(E element) : 将一个元素压入当前栈中
• search(Object o) : 查看指定对象是否在当前栈中
c) Stack的使用方法
import java.util.Stack;
public class ExampleForStack {
/*
* 这是一个非常简单的例子
* 用于展现栈的这种后进先出的特性
* 逆序打印一个字符串
*/
public static void main(String[] args) {
String str = "abcdefghijklmnopqrstuvwxyz";
Stack<Character> stack = new Stack<Character>();
for(char ch : str.toCharArray()) {
stack.push(ch);
}
while(!stack.empty()) {
System.out.print(stack.pop());
}
}
}Ø CopyOnWriteArrayList的特点、实现机制及使用方法
a) CopyOnWriteArrayList的特点:
CopyOnWriteArrayList是java.util.concurrent包中的一个类,此类是一个线程安全类。由于用到了ReentrantLock(重入锁)同步,所以在修改效率上较ArrayList差。
b) CopyOnWriteArrayList的实现机制:
刚开始觉得这个名字好长,并且感觉奇怪,为什么要这样命名?首先这是一个为了实现并发同步而设计的类,那么在所有与修改方法相关的地方均会使用lock来保证同步。Copy-on-write的英文释义是“写时拷贝、写时复制”,现在看来觉得这个名字就更容易理解了,那么这个类到底是怎么实现的呢?面试官说:“踏踏实实看源码”。-_-|||
首先说一下写方法:
• public E set(int index, E element) : 将指定位置的元素使用element替换掉。JDK中的源码如下:
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
Object oldValue = elements[index];
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
setArray(elements);
}
return (E)oldValue;
} finally {
lock.unlock();
}
}在源码中可以看出,首先执行写入(包括set,add,remove等)操作时,首先得到一把当前对象的重入锁,其次获得当前对象元素的一个拷贝(写时拷贝),再次用修改后的元素替换掉原来的元素,最终释放锁。
这里引用两个常识:
1、JAVA中“=”操作只是将引用和某个对象关联,假如同时有一个线程将引用指向另外一个对象,一个线程获取这个引用指向的对象,那么他们之间不会发生ConcurrentModificationException,他们是在虚拟机层面阻塞的,而且速度非常快,几乎不需要CPU时间。
2、JAVA中两个不同的引用指向同一个对象,当第一个引用指向另外一个对象时,第二个引用还将保持原来的对象。
• public void add(E e) : 向当前对象中加入指定元素。实现方式与set相同,均是copy-on-write。
• 还有remove等修改内容的操作。
除写方法(修改,删除,添加)外,CopyOnWriteArrayList类还提供了ArrayList相类似和功能更齐全的方法供选择使用。
• public ListIterator<E> listIterator() : 该方法返回一个ListIterator类型的迭代器,但是该迭代器的真正类型是COWIterator类型的,不允许有插入、删除、添加等方法。
使用方法与ArrayList类似,只是用时选择的问题。因为在写操作时大量使用了System.arrayCopy方法,所以在效率上会有所降低。因此它适合使用在读操作远远大于写操作的场景中。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)