基于属性值相关距离的KNN算法
该博客的观点来自于中国知网上由肖辉辉和段艳明执笔的论文《基于属性值相关距离的KNN算法的改进研究》。我只是因为最近做项目,老师分配任务研究KNN算法的改进而找到这篇论文,最后把论文中的算法代码。下面是Python代码:#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time: 2017/3/29 0029 19:15# @Autho
·
该博客的观点来自于中国知网上由肖辉辉和段艳明执笔的论文《基于属性值相关距离的KNN算法的改进研究》。我只是因为最近做项目,老师分配任务研究KNN算法的改进而找到这篇论文,最后把论文中的算法代码。



下面是Python代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/3/29 0029 19:15
# @Author : Aries
# @Site :
# @File : FCD_KNN.py
# @Software: PyCharm Community Edition
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import neighbors
from sklearn.model_selection import train_test_split
import operator
def Feature_Correlation_Distance(Train_Data,Test_Data):
"""
这是计算测试集与训练集之间的属性值相关距离的函数
:param Train_Data: 训练集
:param Test_Data: 测试集
:return: 返回测试集与训练集之间的属性值相关距离
"""
#计算测试集与训练集之间的相关系数
feature_correlation_distance = []
for j in range(len(Train_Data)):
cov = []
cov.append(Test_Data)
train_data = Train_Data[j,:]
cov.append(train_data)
cov = np.cov(cov)
# print(cov)
corr = cov[1, 0] / ((cov[0, 0] ** 0.5) * (cov[1, 1] ** 0.5))
corr_dist = 1 - corr
feature_correlation_distance.append(corr_dist)
feature_correlation_distance = np.array(feature_correlation_distance)
return feature_correlation_distance
def class_reliability(Train_Label,class_count,feature_correlation_distance,feature_correlation_nearest_distance_index):
"""
这是求测试样本与训练集之间的类可信度函数
:param Train_Label: 训练标签
:param class_count: 类标签计数字典
:param feature_correlation_distance: 测试集与训练集之间的属性值相关距离
:param feature_correlation_nearest_distance_index: 测试集与训练集之间的最近k个属性值相关距离的下标
:return: 返回测试样本的预测分类
"""
#计算每个可能分类的类可信度
Realiability = {}
n = len(feature_correlation_nearest_distance_index)
for i in range(len(class_count)):
nr = class_count[i][1]
predict_label = class_count[i][0]
sum = 0
for j in range(n):
nearest_index = feature_correlation_nearest_distance_index[j]
if Train_Label[nearest_index] == predict_label:
sum = sum + feature_correlation_distance[nearest_index]
realiability = (n - nr) * sum / ( n ** 2)
Realiability[realiability] = predict_label
print(Realiability)
print("rwdsfsdaf")
Realiability = sorted(Realiability.items(),key = operator.itemgetter(0),reverse = False)
print(Realiability)
return Realiability[0][1]
def FCD_KNN(Train_Data,Train_Label,Test_Data,Test_Label,k):
"""
这是FCD_KNN分类算法
:param Train_Data:训练集数据
:param Train_Label: 训练集标签
:param Test_Data: 测试集数据
:param Test_Label: 测试集标签
:param k: 分类的种类
"""
test_labels = []
error = 0.0
for i in range(len(Test_Data)):
class_count = {}
test_data = Test_Data[i]
# 求出测试集与训练集之间的属性值相关距离
feature_correlation_distance = Feature_Correlation_Distance(Train_Data, test_data)
# 对feature_correlation_distance从小到大排序,返回相应的数组下标数组
feature_correlation_distance_index = feature_correlation_distance.argsort()
feature_correlation_nearest_distance_index = []
for j in range(k):
vote_label = Train_Label[feature_correlation_distance_index[j]]
class_count[vote_label] = class_count.get(vote_label, 0) + 1
feature_correlation_nearest_distance_index.append(feature_correlation_distance_index[j])
print(class_count)
print("wrwfsdsfd")
class_count = sorted(class_count.items(),key = operator.itemgetter(1),reverse = True)
print(class_count)
test_label = class_reliability(Train_Label,class_count,feature_correlation_distance,feature_correlation_nearest_distance_index)
test_labels.append(test_label)
if test_label != Test_Label[i]:
error = error + 1.0
return error*1.0/len(Test_Data)
def autoNorm(Data):
"""
:param Data: 需要进行归一化的数据
:return: 进行Max-Min标准化的数据
"""
#求出数据中每列的最大值,最小值,以及相应的范围
data_min = Data.min(0)
data_max = Data.max(0)
data_range = data_max-data_min
#进行归一化
m = np.shape(Data)[0]
Norm_Data = Data - np.tile(data_min,(m,1))
Norm_Data = Norm_Data / data_range
return Norm_Data
def run_main():
"""
这是实现FCD_KNN分类算法的主函数
"""
#导入Iris数据
Iris = datasets.load_iris()
Iris_Data = Iris.data
Iris_Label = Iris.target
#数据归一化
Iris_Norm_Data = autoNorm(Iris_Data)
#训练,测试数据分割
Iris_Train_Data,Iris_Test_Data,Iris_Train_Label,Iris_Test_Label = train_test_split(Iris_Norm_Data,Iris_Label,test_size= 1/3,random_state= 10)
#FCD_KNN分类算法
Error_FCD_KNN= []
K = np.arange(3,30,1)
for k in K:
error = FCD_KNN(Iris_Train_Data,Iris_Train_Label,Iris_Test_Data,Iris_Test_Label,k)
Error_FCD_KNN.append(error)
plt.plot(K, Error_FCD_KNN, color='red',label = "FCD_KNN")
#传统KNN算法,利用sklearn库
Error_KNN = []
for k in K:
KNN = neighbors.KNeighborsClassifier(k)
KNN.fit(Iris_Train_Data,Iris_Train_Label)
test_label= KNN.predict(Iris_Test_Data)
error = 0
for i in range(len(test_label)):
if test_label[i] != Iris_Test_Label[i]:
error = error + 1
error = error / float(len(test_label))
Error_KNN.append(error)
plt.plot(K,Error_KNN,color = 'blue',label = 'KNN')
plt.legend(bbox_to_anchor = (0.,1.02,1.,.102),loc = 2,ncol = 2)
plt.title("Error")
plt.savefig("KNN算法错误率")
plt.show()
if __name__ == '__main__':
run_main()
下面是错误率的图像:
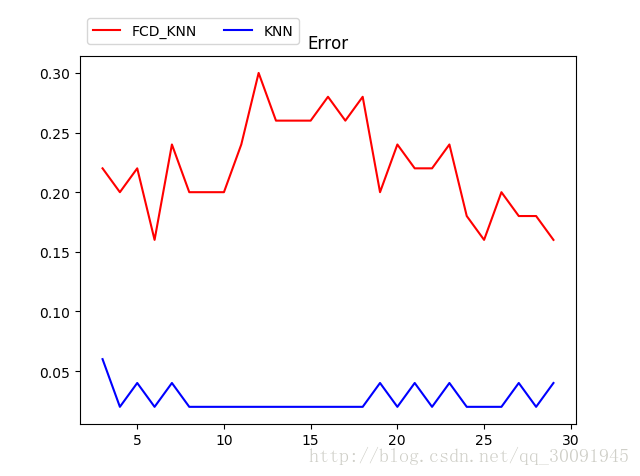
(PS:从此图可以看出无论自己写的代码有多好,还是比不过开源库。但是在学习期间还是自己多写写,加深理解,这样才能在工作中灵活运用,是的算法不断优化。)
点击阅读全文

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)