
Zookeeper简介(一)
使用Zookeeper已经有几年时间了,零零散散的积累了一些经验,但从未想过能写出一些列的文章分享出来。从今天起,计划持续更新关于Zookeeper相关的文章,从基本的搭建使用、原理分析、典型场景分析、引用案例及代码编写,甚至到后期的源代码分析,带领大家一步步的从入门到深入Zookeeper的使用,在这个过程中你会像我一样慢慢的喜欢上它。欢迎大家持续关注本人博客。简介如果你还处于单机时代,那么你将
使用Zookeeper已经有几年时间了,零零散散的积累了一些经验,但从未想过能写出一些列的文章分享出来。从今天起,计划持续更新关于Zookeeper相关的文章,从基本的搭建使用、原理分析、典型场景分析、引用案例及代码编写,甚至到后期的源代码分析,带领大家一步步的从入门到深入Zookeeper的使用,在这个过程中你会像我一样慢慢的喜欢上它。欢迎大家持续关注本人博客。
简介
如果你还处于单机时代,那么你将很少用到Zookeeper,很多更好的方案可以帮助你解决问题。一旦涉及到分布式应用,或许在每做一个决定的时候都要想一想,是否可以使用Zookeeper来实现。
Zookeeper是Apache Hadoop的一个子项目,主要是用来解决分布式应用中经常遇到的一些数据管理问题。下图列举了一些可能会遇到的场景。
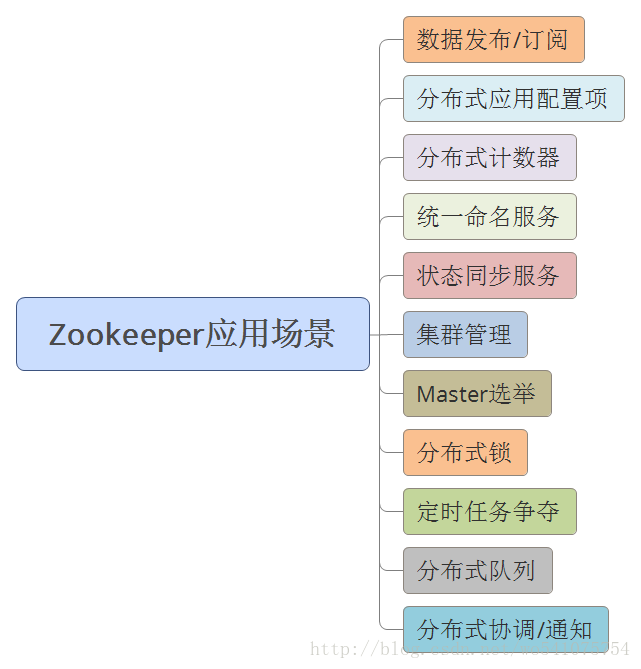
特点
Zookeeper可以保证如下的分布式特性:
- 顺序一致性
- 原子性
- 单一视图
- 可靠性
- 实时性
设计目标
目标一 简单的数据模型
Zookeeper使得分布式程序能够通过一个共享的、树形结构的名字空间来进行相互协调。组成这个树形结构的数据节点被称作ZNode,它们之间的层级关系就像文件系统的目录结构一样。
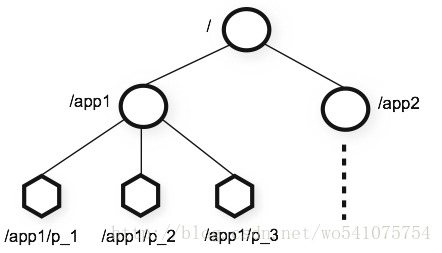
目标二 可以构建集群
也就是Zookeeper服务的可复制性。一般3-5台机器就可以构建一个Zookeeper的集群。只要确保一半以上的服务器能够正常工作,整个机器就能够正常对外服务。相互之间可以进行通信,在内存中维护当前服务器状态。客户可以与任意一台服务器建立TCP连接进行通信,当与此服务器连接断开之后,客户端会自动连接到集群中的其他服务器继续工作。
目标三 顺序访问
客户端的每一个更新请求Zookeeper都会分配一个全局唯一的递增编号,通过这个编号可以确保事物操作的先后顺序。
目标四 高性能
Zookeeper将全量数据存储于内存之中,并直接服务于客户端的所有非事物请求,因此在读操作的应用上优势更为明显。可以在千台服务器组成的读写比例大约为10:1的分布系统上表现优异。

(此图来自官网图片)
版本及官网
Zookeeper的官网地址:http://zookeeper.apache.org/
GitHub地址:https://github.com/apache/zookeeper
目前稳定版本为Release 3.4.9,以后的博客内容也以此版本为基础来讲解。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 2
2 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)