
ZooKeeper的数据结构模型和特点
前面几篇博客学写了ZooKeeper的安装,集群部署,以及常用命令,那么现在来看一下ZooKeeper的数据模型以及适用的场景.ZK的数据结构模型ZooKeeper会会维护一个具有层次关系的数据结构,非常类似于一个标准的文件系统,如下图所示:ZK的数据结构特点ZooKeeper这种数据结构有如下这些特点:1. 每个子目录项如NameService都被称作znode,这个znode是被它所在的
前面几篇博客学写了ZooKeeper的安装,集群部署,以及常用命令,那么现在来看一下ZooKeeper的数据模型以及适用的场景.
ZK的数据结构模型
ZooKeeper会会维护一个具有层次关系的数据结构,非常类似于一个标准的文件系统,如下图所示:
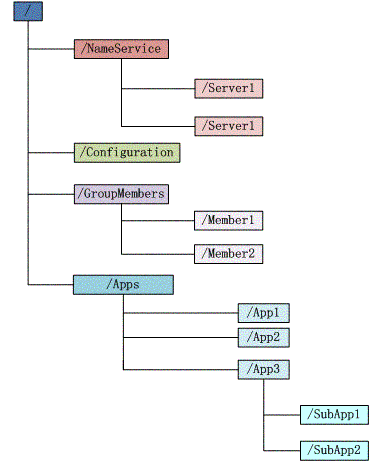
ZK的数据结构特点
ZooKeeper这种数据结构有如下这些特点:
1. 每个子目录项如NameService都被称作znode,这个znode是被它所在的路径唯一标识,如Server1这个znode的标识为/NameService/Server1
2. znode可以有子节点目录,并且每个znode可以存储数据,注意EPHEMERAL类型的目录节点不能有子节点目录
3. znode是有版本的,每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
4. znode可以是临时节点,一旦创建这个znode的客户端与服务器失去联系,这个znode也将自动删除,ZooKeeper的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态成为session,如果znode是临时节点,这个session失效,znode也就被删除.
5. znode的目录名可以自动编号,如App1已经存在,再创建的话,将会自动命名为App2.
6. znode可以被监控,包括这个目录节点中存储的数据被修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是ZooKeeper的核心特性.
参考:
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)