<从PAXOS到ZOOKEEPER分布式一致性原理与实践>读书笔记-zookeeper全局唯一id生成
http://blog.csdn.net/hengyunabc/article/details/44244951
本文属于分布式系统学习笔记系列,上篇文章整理了第5章的zookeeper使用。第六章原书作者写的比较宽泛,介绍了zookeeper的使用场景,本文介绍其中之一,生成全局唯一ID。
一背景
传统生成id方式可以靠数据库的自增来实现,但是在分布式环境下不太适应。依赖数据库容易造成单点。
为什么不用UUID的,网上看别人介绍的时候,从两个方面去分析:
1 大并发的情况下,UUID会出现重复。
2.UUID是随即的,含义不明。从业务角度去考虑,如果用作订单,用户查询订单在数据分片的情况下很可能分散在多个库,查询困难。
全局唯一id的要求比较高:
不能有单点故障。
性能好,毫秒级返回。
能顺序便于DB存储及划分。
二 使用zookeeper生成全局唯一id.
2.1 利用Zookeeper的znode数据版本生成序列号
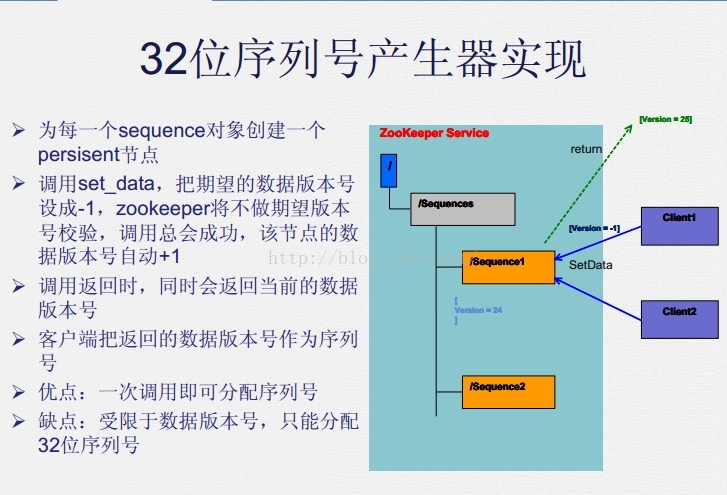
客户端采用:zkClient (https://github.com/adyliu/zkclient)
<dependency>
<groupId>com.github.adyliu</groupId>
<artifactId>zkclient</artifactId>
<version>2.1.1</version>
</dependency>public class ZKSeqTest {
//提前创建好存储Seq的"/createSeq"结点 CreateMode.PERSISTENT
public static final String SEQ_ZNODE = "/seq";
//通过znode数据版本实现分布式seq生成
public static class Task1 implements Runnable {
private final String taskName;
public Task1(String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
ZkClient zkClient = new ZkClient("192.168.190.36:2181", 3000, 50000);
Stat stat =zkClient.writeData(SEQ_ZNODE, new byte[0], -1);
int versionAsSeq = stat.getVersion();
System.out.println(taskName + " obtain seq=" +versionAsSeq );
zkClient.close();
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
//main
final ExecutorService service = Executors.newFixedThreadPool(20);
for (int i = 0; i < 10; i++) {
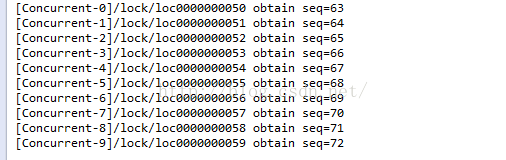
service.execute(new Task1("[Concurrent-" + i + "]"));
}
}
}2.2利用带序列号的znode实现
public class ZKLock {
//提前创建好锁对象的结点"/lock" CreateMode.PERSISTENT
public static final String LOCK_ZNODE = "/lock";
//分布式锁实现分布式seq生成
public static class Task2 implements Runnable, IZkChildListener {
private final String taskName;
private final ZkClient zkClient;
private final String lockPrefix = "/loc";
private final String selfZnode;
public Task2(String taskName) {
this.taskName = taskName;
zkClient = new ZkClient("192.168.190.36:2181", 30000, 50000);
selfZnode = zkClient.createEphemeralSequential(LOCK_ZNODE + lockPrefix, new byte[0]);
}
@Override
public void run() {
createSeq();
}
private void createSeq() {
Stat stat = new Stat();
byte[] oldData = zkClient.readData(LOCK_ZNODE, stat);
byte[] newData = update(oldData);
zkClient.writeData(LOCK_ZNODE, newData);
System.out.println(taskName + selfZnode + " obtain seq=" + new String(newData));
}
private byte[] update(byte[] currentData) {
String s = new String(currentData);
int d = Integer.parseInt(s);
d = d + 1;
s = String.valueOf(d);
return s.getBytes();
}
@Override
public void handleChildChange(String parentPath,
List<String> currentChildren) throws Exception {
// TODO Auto-generated method stub
}
}
public static void main(String[] args) {
final ExecutorService service = Executors.newFixedThreadPool(20);
for (int i = 0; i < 10; i++) {
service.execute(new Task2("[Concurrent-" + i + "]"));
}
service.shutdown();
}
}
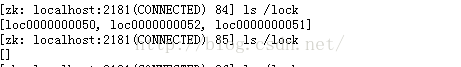
三 开源方案
这是结合书上第六章的生成唯一id的示意,网上还有开源的更好的开源实现方案值得借鉴。
3.1Flikr
3.2 Snowflake
twitter利用zookeeper实现了一个全局ID生成的服务snowflake,https://github.com/twitter/snowflake,可以生成全局唯一的64bit ID。
生成的ID的构成:
时间--用前面41 bit来表示时间,精确到毫秒,可以表示69年的数据
机器ID--用10 bit来表示,也就是说可以部署1024台机器
序列数--用12 bit来表示,意味着每台机器,每毫秒最多可以生成4096个ID3.3instagram
instagram参考了flickr的方案,再结合twitter的经验,利用Postgres数据库的特性,实现了一个更简单可靠的ID生成服务。
使用41 bit来存放时间,精确到毫秒,可以使用41年。
使用13 bit来存放逻辑分片ID。
使用10 bit来存放自增长ID,意味着每台机器,每毫秒最多可以生成1024个ID优: 开发成本低
劣: 基于postgreSQL的存储过程,通用性差
参考:
http://blog.csdn.net/hengyunabc/article/details/19025973
http://aiilive.blog.51cto.com/1925756/1685614

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)