
【Linux 驱动】Netfilter/Iptables (七) 内核协议栈skb封装分析(续六)
上文介绍了netfilter机制下,如何重造并发送一个skb,涉及到内核协议栈编程,而不是我们平时所说的用户层socket网络编程。我们先来介绍下上面skb重构程序涉及到的几个函数:首先,有必要说下,也是后面每段程序中都有说道的,就是开发源码树版本是3.13的,这个版本的skb_buff和我们常见的2.4、2.6有很大的不同。一、主要看一下四个字段://typedef unsigned int
上文介绍了netfilter机制下,如何重造并发送一个skb,涉及到内核协议栈编程,而不是我们平时所说的用户层socket网络编程。
我们先来介绍下上面skb重构程序涉及到的几个函数:
首先,有必要说下,也是后面每段程序中都有说道的,就是开发源码树版本是3.13的,这个版本的skb_buff和我们常见的2.4、2.6有很大的不同。
一、主要看一下四个字段:
//typedef unsigned int sk_buff_data_t;
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;其表示含义如下图所示《深入理解linux网络技术内幕》
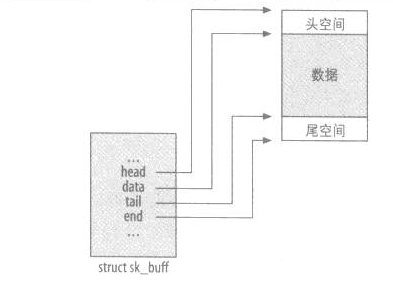
head和end指向缓冲区的头部和尾部,而data和tail指向实际数据的头部和尾部,每一层会在head和data之间填充协议头,或者在tail和end之间添加新的协议数据。
所以根据上面的分析,head和data之间是协议头和有效负载,比如传输层、网络层、以太网帧头。
重点:sk_buff 中的数据部分包含协议层头部和有效负载!
下面就是sk_buff中各个头部的长度字段:
//局部
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
//sk_buff取消了在该数据结构内放置联合体union字段,
//所以编程的时候不能直接调用sk_buff中的联合体成员定位到对应的传输层头部、网络层头部等。
//但是却提供给我们更为便捷的方式:
//举网络层为例
static inline struct iphdr *ip_hdr(const struct sk_buff *skb)
{
return (struct iphdr *)skb_network_header(skb);
}
static inline unsigned char *skb_network_header(const struct sk_buff *skb)
{
return skb->head + skb->network_header;
}
//和我们在linux网路协议栈分析的如出一辙,就是通过先定位整个换缓冲区的头端,
//再根据协议层的偏移量定位该协议层,至于协议头的顺序..都知道二、alloc_skb 和 skb_reserve
还有,对于alloc_skb(),我们只需要指定其数据部分的大小即可(应用层数据+协议层头部),该函数内部会额外把skb_buff所占的那部分空间也给分配出来,这无需我们操心。
skb_reserve(),是一个定位函数,就是前面alloc一个skb之后,用这个函数调整下data和tail数据指针
static inline void skb_reserve(struct sk_buff *skb, int len)
{
skb->data += len;
skb->tail += len;
}
//len取多大,取决于你后面怎么填充数据了skb_reserve() 这个函数就是在缓冲区中预留skb协议头部以及有效数据部分的空间,空间可大可小。
经过前面的alloc_skb和skb_reserve,现在那两个指针(data和tail)发生了变化:
alloc_skb():
//tail以及tail之前的字段初始化为0
memset(skb, 0, offsetof(struct sk_buff, tail));
/* Account for allocated memory : skb + skb->head */
...
skb->head = data;
skb->data = data;
...
skb->end = skb->tail + size;
//head和data均指向分配的skb数据部分(协议头+有效负载)的首地址位置,
//end则指向尾端位置,tail值就是0skb_reserve(skb, len)之后,data和tail的指针发生了变化,换句话说在head与data之间预留了len大小的空间用于填充协议头和有效负载。
上面预留了整体空间,下面我们还要细分空间,上面的整体空间包括了各个协议层头部和有效负载部分,我们还得按照各层协议头部的防止顺序合理划分空间:
三、skb_push 和 skb_put
怎么分,我们前面用的是 skb_push()
unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
{
skb->data -= len;
skb->len += len;
if (unlikely(skb->data<skb->head))
skb_under_panic(skb, len, __builtin_return_address(0));
return skb->data;
}
//看到起实现,我们就知道,调用这个函数来细分空间,必须严格按照数据帧的格式来划分
//以太网帧头 | 网络层首部 | 传输层首部 | 应用层数据
//所以先得细分应用层数据,最后是以太网帧头
//eg,
pdata = skb_push(skb, pkt_len);
udph = (struct udphdr*)skb_push(skb, sizeof(struct udphdr));
iph = (struct iphdr*)skb_push(skb, sizeof(struct iphdr));
ethdr = (struct ethhdr*)skb_push(skb, sizeof(struct ethhdr));如果前面你看懂了,知道sk_buff 的数据空间布局的话,这个函数一看便知。额,sk_buff 中有好几个len,分别表征有效负载长度,各个协议头部长度,以及整个长度。
再来看看 skb_put()
unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
{
unsigned char *tmp = skb_tail_pointer(skb);
SKB_LINEAR_ASSERT(skb);
skb->tail += len;
skb->len += len;
if (unlikely(skb->tail > skb->end))
skb_over_panic(skb, len, __builtin_return_address(0));
return tmp;
}
//看代码,这里改动的是tail(数据的尾部指针),所以这里就是在数据区的尾部追加数据,
//和skb_push()恰恰是反过来的所以调用skb_put() 的话,前面的skb_reserve()就只需要预留以太网帧头的空间,后面则调用skb_put(),依次往后追加细分网络层头部、协议层头部和有效负载部分了。
两个函数都是用于细分空间,返回细分空间后的首部地址指针,便于后续的协议头部以及有效负载数据填充。
空间细分之后就是单纯的协议层字段填充和有效负载填充了。
可以看出来创建skb几个重要的函数接口就是:
alloc_skb、skb_reserver、skb_push、skb_put
后面三个函数其实都是简单的修改指针操作。
上篇及本篇介绍的都是自己创建一个skb,实际上我们还可以拷贝(skb_copy())接收到的skb,然后针对性的修改发送出去。或者直接修改接收到的skb。由于接收到的skb,空间已经细分好,我们则不需要以上后面三个函数,直接调用以下几个函数定位到各个协议层头部:
static inline struct ethhdr *eth_hdr(const struct sk_buff *skb);
static inline struct iphdr *ip_hdr(const struct sk_buff *skb);
static inline struct tcphdr *tcp_hdr(const struct sk_buff *skb);
static inline struct udphdr *udp_hdr(const struct sk_buff *skb);
...然后针对性的修改即可,其余原理是差不多的,这里就不额外介绍了。
参考资料:
《深入理解Linux网络技术内幕》
http://www.2cto.com/os/201502/376226.html
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)