
Hadoop2.6+HA+Zookeeper3.4.6+Hbase1.0.0安装
Hadoop2.6+HA+Zookeeper3.4.6+Hbase1.0.0安装Author : WHP安装hadoop2.6+HA1.准备一台CentOS6.4系统2.环境CentOS6.4 共5台机器名ip地址安装软件运行进程maste
Hadoop2.6+HA+Zookeeper3.4.6+Hbase1.0.0安装
Author : WHP
安装hadoop2.6+HA
- 1.准备一台CentOS6.4系统
- 2.环境CentOS6.4 共5台
机器名 ip地址 安装软件 运行进程
master1 192.168.3.141 hadoop、Zookeeper、hbase NN、RM、DFSZKFC、journalNode、HMaster、QuorumPeerMain
master2 192.168.3.142 hadoop、Zookeeper、hbase NN、RM、DFSZKFC、journalNode、 HRegionServer、QuorumPeerMain
slave1 192.168.3.143 hadoop、Zookeeper、hbase DN、NM、journalNode、HRegionServer、QuorumPeerMain
slave2 192.168.3.144 hadoop、Zookeeper、hbase DN、NM、journalNode、HRegionServer、QuorumPeerMain
slave3 192.168.3.145 hadoop、Zookeeper、hbase DN、NM、journalNode、HRegionServer、QuorumPeerMain
- 3.此时我们先对第一台机器做修改,其他的后期克隆该机器即可
- 4.修改/etc/hosts文件
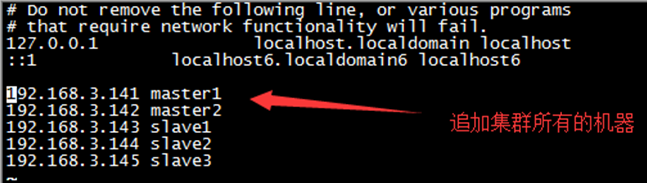
修改/etc/sysconfig/network

- 5.重启机器

或者
临时修改hostname
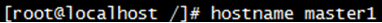
- 6.安装JDK
将JDK解压
编辑/etc/profile 添加jdk路径

保存退出
修改CentOS里的java优先级
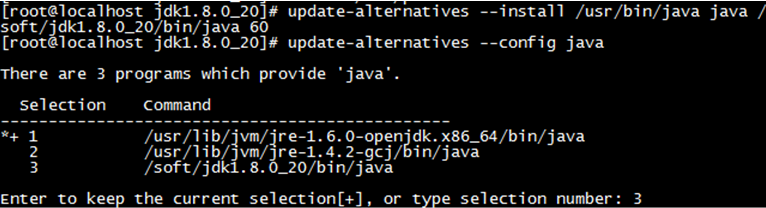
此时JDK已经安装完成

- 7.解压hadoop并修改环境变量
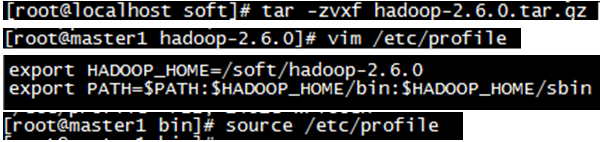
- 8.修改配置文件
8.1 修改$HADOOP_HOME/etc/hadoop/slaves文件
加入所有slave节点的hostname
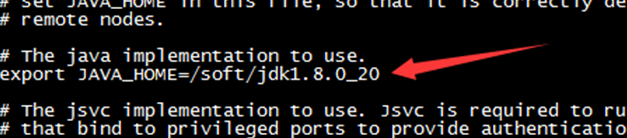
8.2 修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件
修改JAVA_HOME路径
8.3 修改$HADOOP_HOME/etc/hadoop/yarn-env.sh文件
修改JAVA_HOME路径

8.4 修改
HADOOPHOME/etc/hadoop/core−site.xml文件详见附件8.5修改
HADOOP_HOME/etc/hadoop/hdfs-site.xml文件
详见附件
8.6 修改
HADOOPHOME/etc/hadoop/mapred−site.xml文件详见附件8.7修改
HADOOP_HOME/etc/hadoop/yarn-site.xml文件
详见附件(yarn.resourcemanager.ha.id的属性值在master2机器中需要更改为rm2)
8.8 添加$HADOOP_HOME/etc/hadoop/fairscheduler.xml文件
详见附件
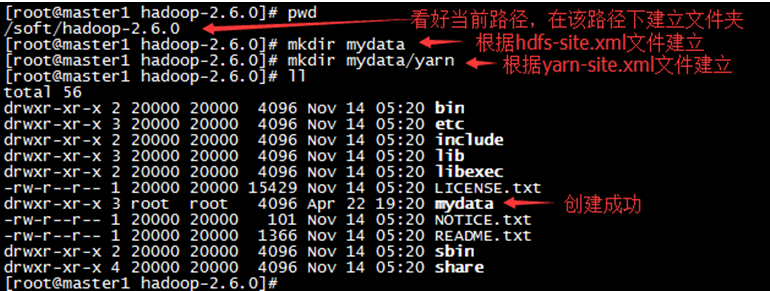
8.9 创建相关文件夹
根据xml配置文件,建立相应的文件夹
此时Hadoop+HA配置文件已经配好,就差ssh免密码登录+格式化Hadoop系统。
等我们装完所有软件(Zookeeper+hbase),克隆机器后再进行ssh免密码登录及Hadoop格式化。克隆后还需要更改每个节点的/etc/sysconfig/network中的hostname,以及更改master2中$HADOOP_HOME/etc/hadoop/yarn-site.xml文件的yarn.resourcemanager.ha.id属性值为rm2
安装Zookeeper3.4.6
- 1.解压Zookeeper
- 2.Zookeeper环境变量的配置
添加Zookeeper的路径

- 3.更改配置文件
将conf/zoo_sample.cfg改成conf/zoo.cfg

然后对zoo.cfg进行更改
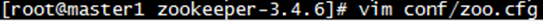
- 4.在DataDir路径下创建myid文件
根据配置文件的dataLogDir路径
创建/soft/zookeeper-3.4.6/var/datalog文件夹
创建/soft/zookeeper-3.4.6/var文件夹
再创建/soft/zookeeper-3.4.6/var/data文件夹
再创建/soft/zookeeper-3.4.6/var/data/myid文件

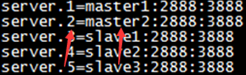
向其中输入数字1 (对应zoo.cfg文件server后的数字)
其他节点在克隆后应根据zoo.cfg中对应的值进行更改
安装Hbase1.0.0
- 1.修改本机配置
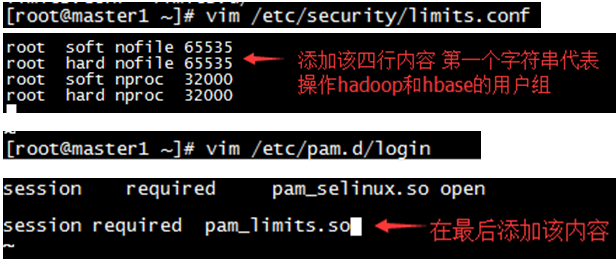
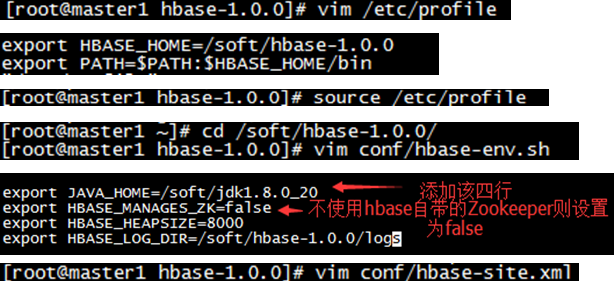
- 2.修改配置文件
conf/hbase-site.xml详见附件(注意hbase.rootdir的值 用ip地址表示)
根据conf/hbase-site.xml中hbase.tmp.dir值来创建文件夹
- 3.创建连接

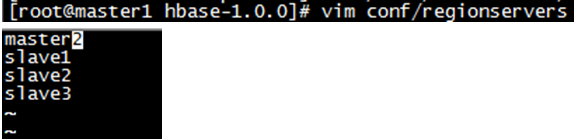
- 4.编辑regionserver文件
- 5.覆盖hbase中lib文件夹下hadoop*.jar文件

(由于后期安装hbase出错,我把所有的hadoop下的jar包都导到hbase/lib下了)
如果hbase下的lib文件夹中的zookeeper的jar包与Zookeeper中的jar包也不符,那么也需要替换。
至此hbase也安装完了,克隆后需要做的是将集群节点的时间进行统一。
克隆机器
- 1.此时机器克隆4份。
分别更改其ip地址。图形界面更改ip操作详情见附件。
- 2.ssh免密码登录
2.1 更改/etc/sysconfig/network文件

2.2生成密钥
2.3 复制到公共密钥中

2.4 将该机器的公共密钥远程复制到想远程登录的机器中

在提示中输入yes、密码
2.5 配置双向ssh登录。
此时master1已经可以通过ssh登录其他机器了,接下来我们配置所有机器相互无密码登录。
我们那其中一台机器slave3举例,其他机器(master2 slave1 slave2)都执行此操作,这里我们就不一一写明。
把slave3密钥传到其他所有机器上。

根据提示,输入yes、密码
在每一台机器上(master2 slave1 slave2 slave3),对其他所有机器都执行此操作。

然后在其他机器上将密钥追加到公钥文件末尾。

此时就可以双向无密钥登录了。
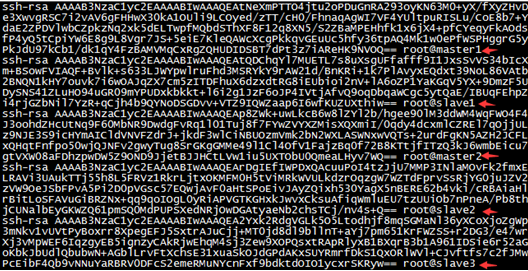
我们可以查看/root/.ssh/authorized_keys文件,就能发现每台机器的密钥。
- 3.更改hadoop配置文件
更改master2中$HADOOP_HOME/etc/hadoop/yarn-site.xml文件中:
Yarn.resourcemanager.ha.id的属性值为rm2


- 4.更改Zookeeper文件
更改$ZOOKEEPER_HOME/var/data/myid文件

相应的值根据$ZOOKEEPER_HOME/conf/zoo.cfg中的id来更改

- 5.同步时间
首先我们确立master1为时间服务器,我们通过配置使其他节点自行与master1进行时间同步。
5.1对master1时间服务器进行操作:
检查时间服务是否安装

更改相关配置文件

启动服务
检查master1是否和自己同步完成

5.2其他机器相对于master1进行时间同步
当master1的时间服务器启动3-5分钟后,我们对其他节点进行与master1的时间同步。
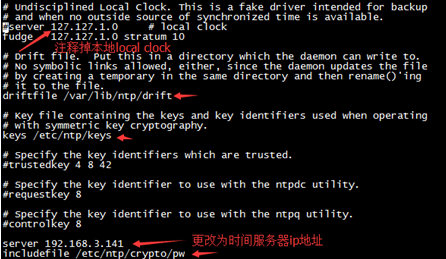
更改/etc/ntp.conf文件配置
将master2的/etc/ntp.conf发送到其他的机器中

在其他节点将时间服务开启
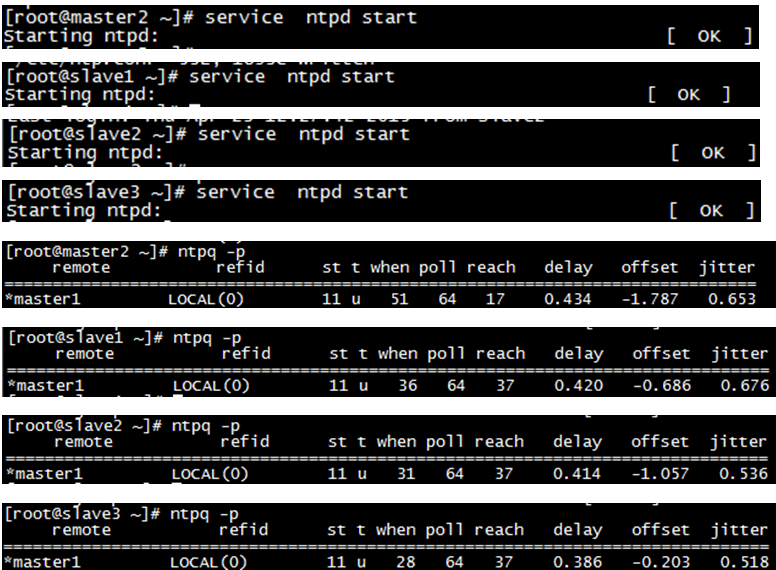
5.3时间服务设置为开机启动
分别在master1 master2 slave1 slave2 slave3执行该命令

5.4 在时间服务器上开放端口
根据ip地址来输入命令

第一次部署+启动hadoop+zookeeper+hbase
刚刚安装完hadoop需要部署,再启动。以下是第一次所需的执行,以后再启动就不需要在这么做了。
- 1.启动Zookeeper
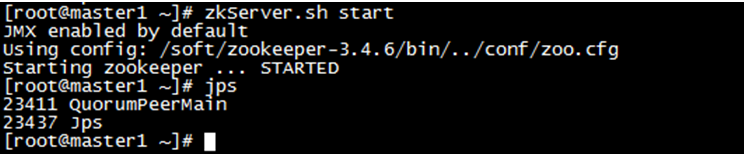
分别在每个机器上运行命令zkServer.sh start或者在$ZOOKEEPER_HOME/bin目录下运行./zkServer.sh start命令。然后可以通过命令jps来查看Zookeeper启动的进程QuorumPeerMain。
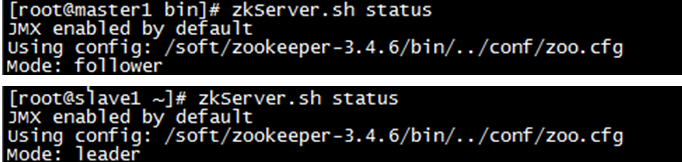
可通过zkServer.sh status命令来查看Zookeeper状态。正常是机器中只有一个leader,其他的都是follow
- 2.格式化ZooKeeper集群
目的是在ZooKeeper集群上建立HA的相应节点。
在master1机器上执行命令

他会根据$HADOOP_HOME/etc/hadoop/core-site.xml文件中ha.zookeeper.quorum的值来进行初始化。
3.启动journalnode进程
在master1节点上执行
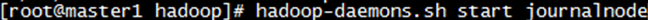
或者在每台机器上执行

slave1 slave2 slave3
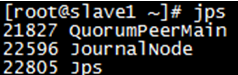
推荐第二种方法,第一种方法master1和master2的journalnode无法启动
启动后在所有节点上多出JournalNode进程
- 4.格式化namenode
在master1上执行命令

会在mydata文件下创建一些文件夹及文件(name或者data以及journal)
- 5.启动namenode
在master1上执行命令

在master1上多出进程NameNode
- 6.将刚才格式化的namenode信息同步到备用namenode上
在master2机器上执行命令

- 7.在master2上启动namenode
在master2上多出进程NameNode

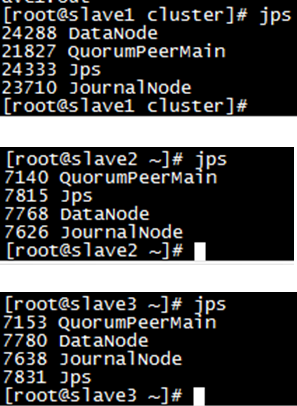
- 8.启动所有datanode
在master1上执行命令

执行后在datanode节点上显示的进程datanode
- 9.启动yarn
在master1上执行命令
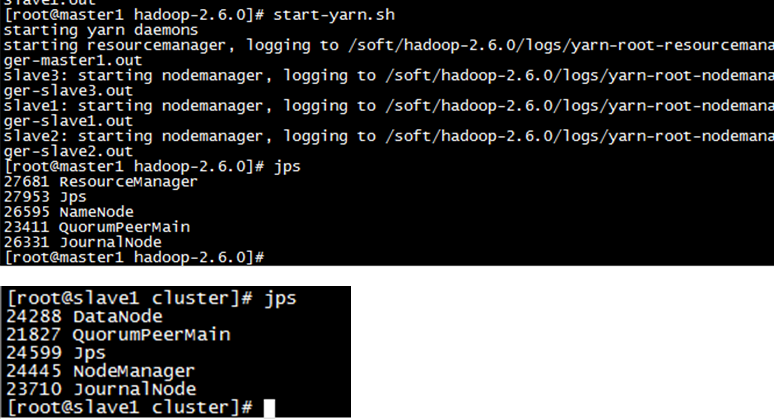
在master1上多出ResourceManager进程,在slave1 slave2 slave3上多出NodeManager进程
- 10.启动ZKFC
在master1和master2上启动zkfc
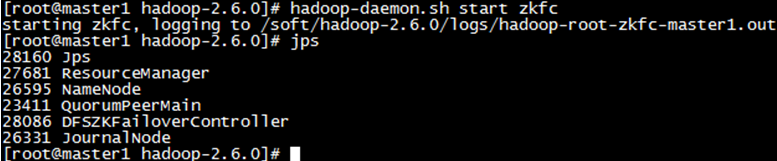
- 11.Hadoop启动成功
下图是两个启动后的master节点
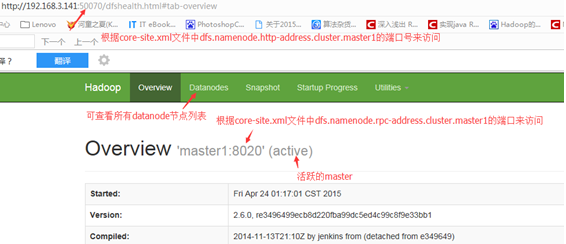

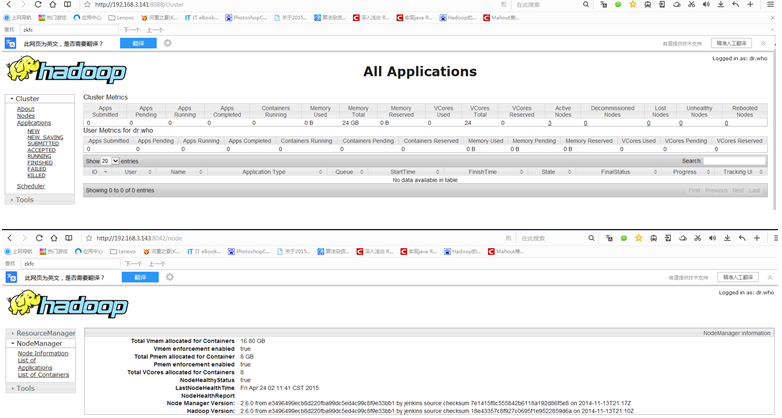
- 12.启动hbase
在master1上执行命令
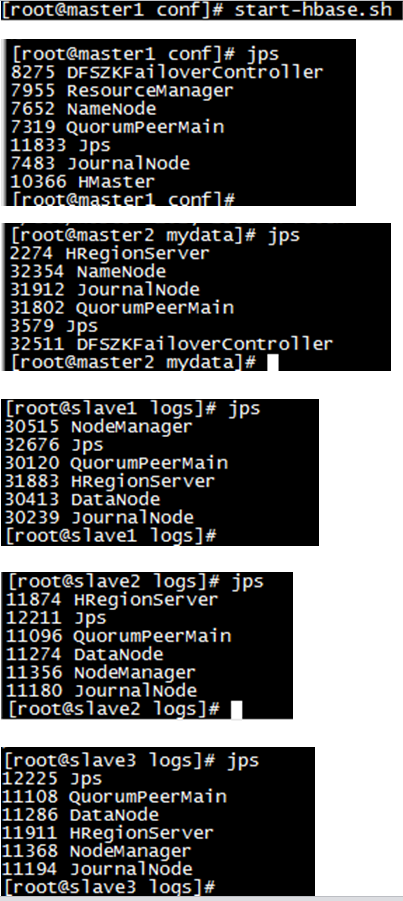
第n次启动
- 1.对于HA,要先启动Zookeeper
zkServer.sh start (每个节点)
- 2.启动hadoop
start-dfs.sh start-yarn.sh (master1节点)
- 3.启动hbase
start-hbase.sh (master1节点)
后续待解决问题
希望大神能帮我指点一二。。。。
问题一:对于HA框架,hbase-site.xml如何根据当前active的master来配置?
问题二:服务全部停止后重启,hbase显示无法启动。不知为何。我只能全部清空格式化hadoop。
步骤:
1.删除hadoop/mydata下的所有文件夹 再新建yarn文件夹
2.删除hadoop/log文件夹下的所有文件
3.删除zookeeper/var/data下的除了myid的所有文件
4.删除Zookeeper/var/datalog下的所有文件夹
5.删除hbase下的file:文件
6.删除hbase下的logs下的所有文件
7.重新格式化hadoop
所有附件下载地址: http://download.csdn.net/detail/onepiecehuiyu/8631719
有任何疑问联系我E-mail: dr.whiker@gmail.com

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)