
【智能体】Agent的四种设计模式之:ReAct
Agent 工作模式之一:ReAct(边想边做)—— 所有智能体的“元模式”
Agent 四种工作模式
1、引言
小屌丝:鱼哥,我最近用 LangChain 搭了个 Agent,跑了半天,不是死循环就是答非所问。我看了那篇《一图带你看懂 Agent 四种设计模式》,图是记住了,但还是不知道怎么选、怎么用。
小鱼:图是记住了,代码呢?
小屌丝:代码在网上拼拼凑凑,跑起来了,但感觉像在摸黑走路。
小鱼:那今天我就把那四种模式,每一种都给你写一段能跑的核心代码,再告诉你什么时候该选它,什么时候千万别选它。让你从“会用 API”进化到“能设计 Agent 架构”。
小屌丝:得嘞,我搬好小板凳了。
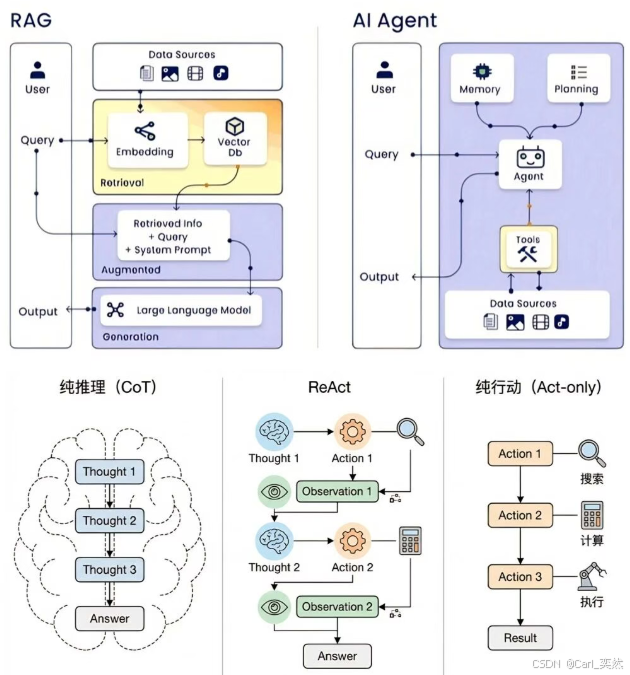
2、四种设计模式之React
2.1 四种工作模式的本质差异
在进代码之前,先把四种模式的底层逻辑对齐。我用一张表把核心差异拉出来:
| 工作模式 | 决策时机 | 执行节奏 | 核心隐喻 | 一句话总结 |
|---|---|---|---|---|
| ReAct | 每步都重新思考 | 思考→行动→观察→再思考 | 走迷宫 | “走一步看一步,边走边想” |
| Plan-and-Execute | 一次性规划,执行中不思考 | 规划(一次)→ 执行(批量) | 查清单 | “先想好全盘,再按清单打勾” |
| Reflection | 执行完再审查 | 生成→评审→修正→再评审 | 校对员 | “做完再检查,检查完再改” |
| Multi-Agent | 多角色分工决策 | 并行或串行协作 | 项目团队 | “一个搞不定,派一个团队上” |
这四种模式不是互斥的,是层层叠加的:
- ReAct 是基础原语
- Plan-and-Execute 在 ReAct 上加了“规划分层”
- Reflection 在 ReAct 上加了“质检反馈”
- Multi-Agent 则是把前三种模式分配给不同的 Agent 并行跑
2.2 ReAct 工作流程图
图中的逻辑画得很清楚
核心思想:Agent 在思考和行动之间不断交替。每一步都依赖上一步的观察结果来决定下一步,没有“全局计划”的概念。
2.3 什么时候用 ReAct
-
任务路径不确定,“下一步是什么”依赖上一步结果
-
工具调用后有大量中间信息需要“消化”
-
你的任务本身就是探索性的(调研、排查问题、信息检索聚合)
2.4 什么时候别用 ReAct
-
任务步骤可以提前确定(那是 Plan-and-Execute 的地盘,能省 80% Token)
-
你对延迟敏感,每一步都调 LLM 太慢
-
输出质量要求极高但 ReAct 没有内建质检(那是 Reflection 要补的)
2.5 核心代码示例
# -*- coding:utf-8 -*-
# @Time : 2026-05-01
# @Author : Carl_DJ
from openai import OpenAI
import json
client = OpenAI()
# ---------- 工具定义 ----------
def search_flights(origin: str, destination: str, date: str) -> str:
"""模拟查询航班"""
return json.dumps({
"flights": [
{"flight_no": "CA1234", "departure": "08:00", "price": 1280},
{"flight_no": "MU5678", "departure": "14:30", "price": 960}
]
}, ensure_ascii=False)
def book_flight(flight_no: str, passenger: str) -> str:
"""模拟订票"""
return json.dumps({"status": "confirmed", "booking_id": "BK20260502", "flight": flight_no, "passenger": passenger}, ensure_ascii=False)
TOOLS = {
"search_flights": search_flights,
"book_flight": book_flight
}
TOOLS_DESC = """
- search_flights(origin, destination, date): 查询航班
- book_flight(flight_no, passenger): 预订机票
"""
# ---------- ReAct Prompt ----------
SYSTEM_PROMPT = f"""你是一个订票助手。你可以使用以下工具:
{TOOLS_DESC}
严格按照以下格式输出,每次只输出一个 Thought/Action 对:
Thought: 你当前的思考
Action: 工具名称
Action Input: {{"key": "value"}}
当你确认任务完成时,输出:
Thought: 任务已完成
Final Answer: 最终的回答
"""
# ---------- ReAct 循环 ----------
def react_loop(user_input: str, max_steps=10):
messages = [{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_input}]
for step in range(max_steps):
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0
)
reply = response.choices[0].message.content
messages.append({"role": "assistant", "content": reply})
# 检查是否完成
if "Final Answer:" in reply:
return reply.split("Final Answer:")[-1].strip()
# 解析 Action
if "Action:" in reply and "Action Input:" in reply:
action_line = [l for l in reply.split("\n") if l.startswith("Action:")][0]
input_line = [l for l in reply.split("\n") if l.startswith("Action Input:")][0]
action_name = action_line.replace("Action:", "").strip()
action_input = json.loads(input_line.replace("Action Input:", "").strip())
# 执行工具
if action_name in TOOLS:
observation = TOOLS[action_name](**action_input)
else:
observation = f"错误:工具 {action_name} 不存在"
# 把观察喂回去
messages.append({"role": "user", "content": f"Observation: {observation}"})
else:
# 格式不对,提醒
messages.append({"role": "user", "content": "Observation: 请严格按 Thought/Action/Action Input 格式输出"})
return "达到最大步数,任务未完成"
# ---------- 运行 ----------
result = react_loop("帮我订一张5月3号从北京到上海的机票,选最便宜的")
print(result)
关键决策点:
- ReAct 的核心管控点不在 Prompt,而在 messages 的拼接方式。
- 每一次工具的返回结果(Observation)必须原样塞回对话历史,否则 Agent 会失去“上下文记忆”。
3、总结
ReAct 是 Agent 的“元模式”,灵活但费 Token。如果你能用其他模式预先确定步骤,就别用它。如果必须用,记得控制循环、校验格式、兜底截断。
看到这里, 《Agent设计模式之:React》就聊的差不多了,
下一篇,我们聊《Agent设计模式之:Plan-and-Execute 》,不见不散。
我是小鱼:
- CSDN 博客专家;
- AIGC 技术MVP专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)