
Superpowers - 10 用 Subagent 驱动开发,把「AI 写代码」变成一条严谨的生产流水线
本文介绍了Subagent驱动开发的核心理念与应用场景。该模式通过为每个任务创建独立的subagent,构建了一条包含实施者、规范审查者、代码质量审查者的三阶段流水线,有效解决了传统AI编码中上下文膨胀、角色混乱和质量滞后等问题。文章详细分析了该工作流的适用条件、执行流程和状态管理机制,特别强调了通过结构化审查流程确保代码质量。这种工程化的AI开发模式,将"会写代码的模型"转化
文章目录
Pre
Superpowers - 01 让 AI 真正“懂工程”:Superpowers 软件开发工作流深度解析
Superpowers - 02 用 15 个技能给你的 AI 装上「工程大脑」:Superpowers 快速开始深度解析
Superpowers - 03 一文搞懂 Superpowers:面向多平台 AI 编码助手的安装与实践指南
Superpowers - 04 从“会写代码”到“会做工程”:Superpowers 工作流引擎架构深度剖析
Superpowers - 05 构建一个“会自己找插件用”的 Agent:深入解析 Superpowers 的技能发现与激活机制
Superpowers - 06 从文档到“结构契约”:Superpowers 技能剖析与 Frontmatter 深度解读
Superpowers - 07 从 SessionStart Hook 看 Superpowers:把「技能库」变成「行为操作系统」
Superpowers - 08 在 AI 时代重写「需求评审会」:深入解读 Superpowers 的头脑风暴与设计规范机制
Superpowers - 09 从构思到落地:如何用「计划编写与任务粒度」驾驭 AI 时代的软件开发
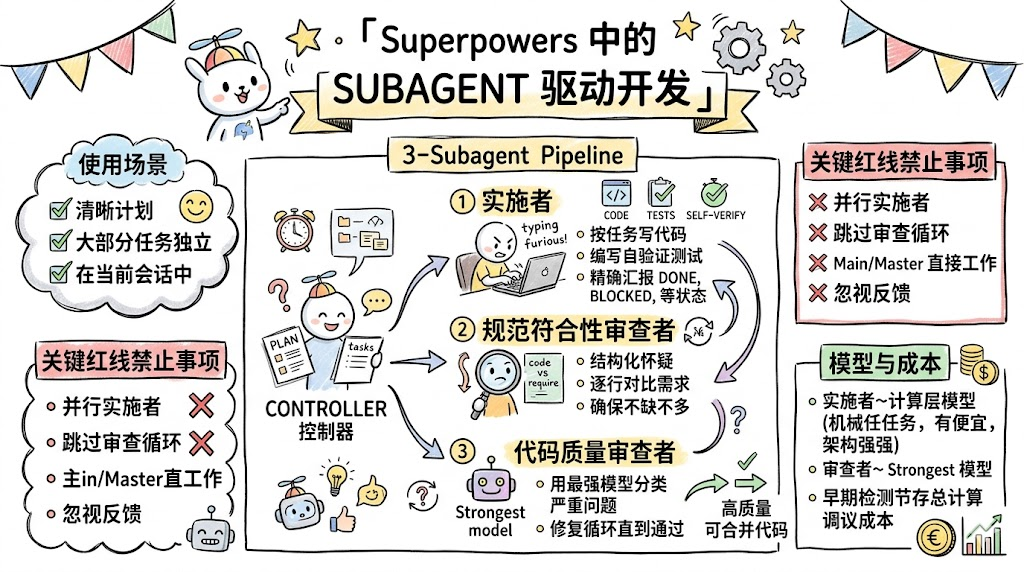
在越来越多的团队把大模型引入开发流程之后,一个越来越现实的问题是:如何把“会写代码的模型”变成“可托付生产环境的开发流水线”。Subagent 驱动开发(subagent-driven-development),就是为此设计的一条核心管线:它不再让一个大模型在同一上下文里从头写到尾,而是为每个任务派发一个全新的、上下文隔离的 subagent,强制经过“规范符合性 → 代码质量”两道审查关卡,在单次会话内产出可合并的生产级代码。
本文面向有一定工程实践的开发者、架构师和对 AI 开发工作流感兴趣的研究者,系统拆解这一技能的设计思路、使用场景、执行细节和工程上的权衡。
一、为什么需要 Subagent 驱动开发?
传统的「让模型直接在当前对话里写代码」方式,存在几个结构性问题:
- 上下文持续膨胀:随着代码、日志、讨论不断塞进对话,模型对关键约束的记忆会越来越模糊,推理质量下降。
- 控制器角色混乱:同一个会话既要写代码、又要改计划、还要解释错误,导致上下文污染严重,很难对整体质量负责。
- 质量反馈滞后:很多问题要到「合并前」甚至「线上」才暴露,返工成本极高。
Subagent 驱动开发的核心思想是:把执行计划转换为一条可控、可审计、强约束的流水线。
- 每个任务单独创建 subagent,拥有独立上下文,避免跨任务串味。
- 控制器只做「编排」(读取一次计划,拆任务,派发、路由反馈),自己绝不写代码。
- 每个任务都经过规范审查 + 代码质量审查,问题在任务粒度被尽早发现和修复。
这本质上,是把「模型写代码」从一次性对话升级为一条工程化的 CI 流水线,只不过 CI 的核心执行者是 subagent。
二、什么时候该用这条流水线?
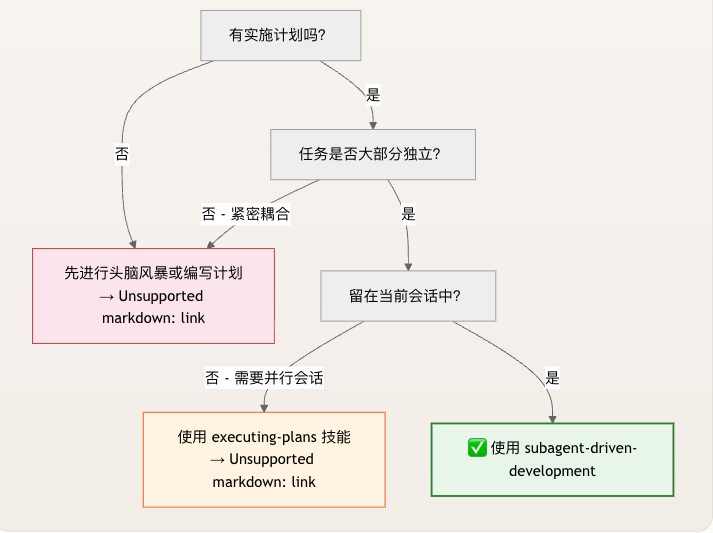
在 Superpowers 的工作流里,执行计划有两条路径:
Subagent 驱动开发(本文主角)内联执行计划(executing-plans-inline)
选择哪一条,由三个问题决定:
- 是否已经有明确的实施计划?
- 没有:先用「头脑风暴与设计规范」「计划编写与任务粒度」等技能,把计划写出来。
- 计划中的任务是否大部分相互独立?
- 如果任务紧密耦合,说明计划本身要重写或重新拆分,而不是直接执行。
- 是否可以留在当前会话执行?
- 如果需要带有手动检查点的独立会话,或者更复杂的会话编排,则交给其他技能处理。
满足「有计划 + 任务大部分独立 + 不需要并行独立会话」这三点,就走 Subagent 驱动开发。
与 executing-plans-inline 的关键区别在于:
- Inline 执行:控制器在当前会话里直接写代码,容易上下文污染。
- Subagent 驱动:控制器只读一次计划,提取任务,之后只作为编排者,从不落笔写代码。
对一个实际项目而言,这条流水线特别适合:
- 功能范围清晰、需求已冻结的迭代开发。
- 需要高质量保证的改动(如核心业务逻辑、支付流水线等)。
- 需要多人/多 agent 协同,但又不希望 Git 冲突满天飞的场景。
三、三 Subagent 流水线:实施者、规范审查者、质量审查者
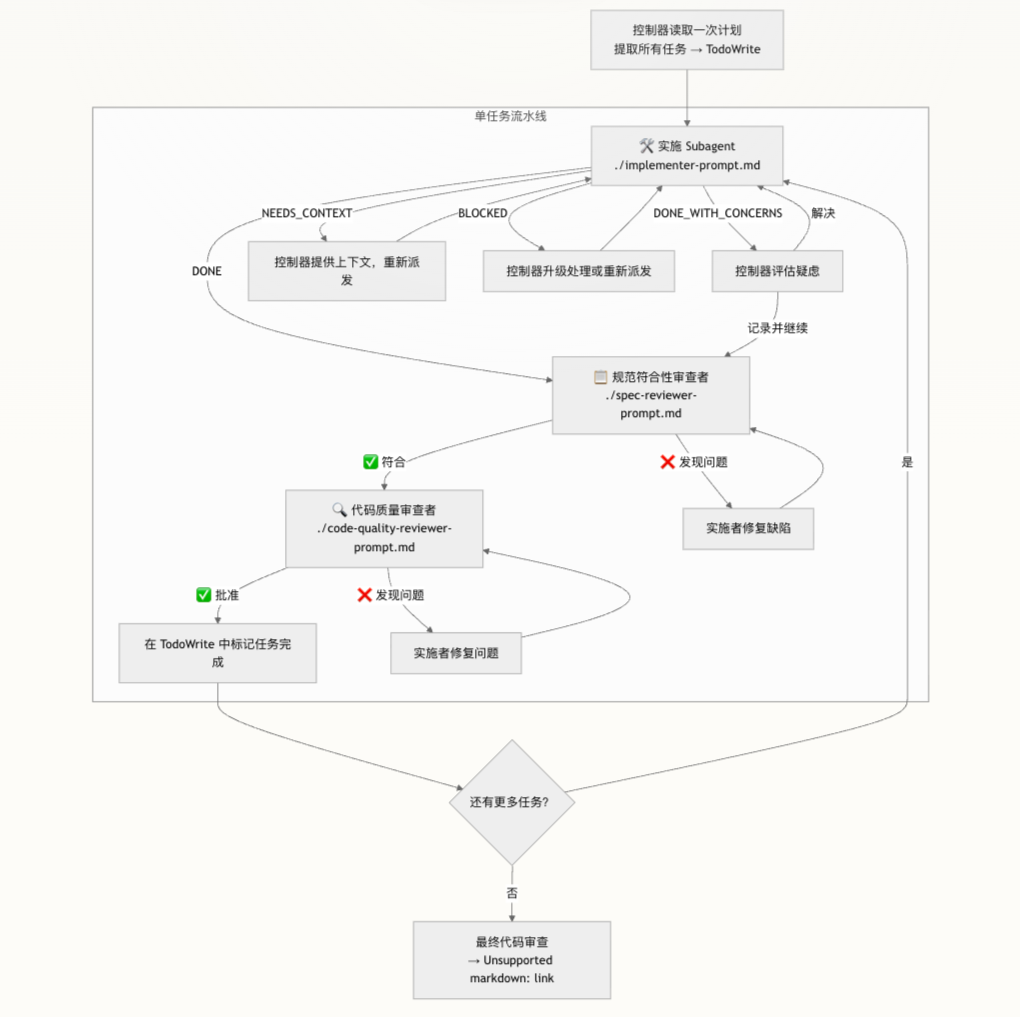
这一技能的架构中心,是一个固定的「三 Agent 串行流水线」:
- 实施 Subagent(Implementer)
- 规范符合性审查者(Spec Reviewer)
- 代码质量审查者(Code Quality Reviewer)
控制器负责:从计划中提取任务 → 写入 Todo 列表 → 为每个任务依次派发这三类 subagent,路由它们的输入输出。
1. 实施 Subagent:只负责把任务做对做完
实施者收到的不是“去读某个计划文件”,而是任务全文直接贴进提示,同时附带必要的铺垫上下文:
- 这个任务在整体架构中的位置。
- 它依赖哪些模块、接口、数据结构。
- 代码库中与之相关的模式、约定等。
实施者的职责边界非常清晰:
- 按任务规定实现功能(不多、不少、不随意发挥)。
- 编写相应测试,并运行验证。
- 根据自查清单进行自审。
- 输出状态报告(后文详细说)。
自查是「硬性步骤」,主要看四个维度:
- 完整性:是否覆盖了所有需求点。
- 质量:命名、结构、可读性是否符合项目标准。
- 纪律性:是否遵守 YAGNI、既有模式、既有约束。
- 测试:是否编写并执行了行为测试,而不是只写 mock。
一个典型的实施者结果示例(简化伪例):
状态: DONE_WITH_CONCERNS
总结:
- 实现了 xxx API,支持 A/B 两种模式
- 为 core/service_xxx 添加了集成测试
自查疑虑:
- service_xxx.go 文件略显臃肿,可能需要后续抽取子模块
测试:
- go test ./... 全部通过
2. 规范符合性审查者:结构化怀疑,而非相信报告
规范审查者的立场可以概括成四个字:“不要相信”。
- 它被明确禁止只看实施者的报告,必须阅读实际改动的代码。
- 它要逐条对照需求,寻找三类典型失败模式:
- 缺失:需求里提到的东西没做。
- 多余:实现了没被要求的内容。
- 误解:功能看起来合理,但与真正需求偏离。
只有当规范审查者给出 ✅,代码才有资格进入「质量审查」阶段。
否则,就会把问题反馈给实施者,进入「修复 → 再审查」循环。
这一步的本质:把“做对什么”的问题解决干净,再去讨论“做得好不好”。
3. 代码质量审查者:完整套用代码审查工作流
在规范通过之后,才会派发代码质量审查者,它遵循 Superpowers 中的标准「代码审查工作流」模板,对这一任务的改动做系统性评估:
- 输入是一组限定范围的 git SHA(这次任务改了什么)。
- 检查内容包括:代码质量、架构合理性、测试质量等。
- 所有问题按严重程度分类(严重 / 重要 / 次要)。
审查者的强制要求是:所有问题必须在通过前被修复。
因此形成闭环:审查者发现问题 → 实施者修复 → 审查者重新审查,直到批准。
从工程视角看,你可以把它理解为一套标准化的「AI 驱动 Code Review」流水线嵌入到了每个任务中,而不是只在最后合并前审一次。
四、实施者状态协议:让失败被显式看见
实施者在结束一个任务时,必须返回四种状态之一:
| 状态 | 含义 | 控制器应对策略 |
|---|---|---|
| DONE | 任务完成,无疑虑 | 直接进入规范符合性审查。 |
| DONE_WITH_CONCERNS | 已完成但有明确疑虑 | 如果是正确性/范围类疑虑,需先解决再送审;如果只是观察(如“文件变大”),记录后继续。 |
| NEEDS_CONTEXT | 缺少关键上下文导致无法判断/实施 | 控制器补充上下文后,重新派发给同一模型继续。 |
| BLOCKED | 结构性阻塞,无法推进 | 控制器识别原因:上下文不足、模型能力不够、任务过大或计划本身有误,并采取对应方案。 |
文档强调一个关键红线:绝不能无视 subagent 的「卡住」信号,也不能在不变更前提条件的情况下强迫同一个模型「再试一次」。
当实施者报告 BLOCKED,控制器必须思考的是:
- 是否需要提供更多上下文?
- 是否需要换更强的模型?
- 是否需要拆分任务?
- 是否需要把问题升级为人工介入?
这套协议避免了「静默失败」:任务不会悄悄以不确定状态结束,也不会在错误前提上反复浪费算力。
五、模型选择策略:把强模型用在最贵的地方
Subagent 驱动开发引入了一套分层模型选择策略,核心目标是:该省的地方省,该花的地方绝不省。
文档给出了一张非常实用的对照表:
| 任务复杂度 | 建议模型层级 | 典型信号 |
|---|---|---|
| 机械性实施 | 快速、廉价模型 | 1–2 个文件、需求明确、逻辑局部,基本是「照着规范搬砖」。 |
| 集成与判断 | 标准模型 | 涉及多文件、需要在模式/约定之间做协调决策。 |
| 架构、设计、审查 | 最强模型 | 需要通盘理解代码库、做跨领域判断或架构评估。 |
同时有一条硬性建议:规范审查者和代码质量审查者应始终使用最强模型。
原因很直接:
- 审查准确度,是模型能力最能发挥价值的地方。
- 漏审一个严重问题的代价,几乎总是比多跑几次强模型要高得多。
换句话说,这套策略是在「实现」阶段做精细成本控制,在「审查」阶段则全面拉满质量保障。
六、控制器执行流:只读一次计划,严格按顺序来

控制器的执行流也被设计得非常严格:
- 在工作流开始时,只读取一次计划文件。
- 从中提取每个任务的全文,以及必要的上下文注释。
- 将这些任务写入一个 Todo 列表(TodoWrite),用于追踪整体进度。
- 对每个任务:
- 派发实施者 → 等待状态与结果。
- 若非 BLOCKED/NEEDS_CONTEXT,则进入规范审查 → 通过后进入代码质量审查。
- 必要时循环「修复 ↔ 审查」。
- 所有任务完成后,再派发一个「最终代码审查」 subagent,从整体视角检查跨任务集成问题。
- 最后进入「完成开发分支」技能,处理测试、合并和清理等工作。
其中有两条非常重要的约束:
- subagent 自己永远不直接读取计划文件,任务文本只能由控制器注入提示。
- 控制器不得随意改变审查顺序,也不得跳过任何一次「发现问题 → 修复 → 复查」循环。
前者确保控制器掌控上下文,避免 subagent 产生不一致理解;后者保证审查链路的完整性,不出现“审查发现问题但没人确认修没修好”的断档。
七、红线规则:这十条绝对不要踩
为了确保这条流水线的质量承诺,文档列出了一组「不可违反」的红线规则:
| 规则 | 原因与影响 |
|---|---|
| 不并行派发多个实施者 | 同时修改重叠文件,几乎必然引发 Git 冲突,破坏任务隔离。 |
| 规范未过,绝不提前做质量审查 | 在错误实现上谈质量是浪费时间,也会掩盖方向性问题。 |
| 不跳过「发现问题 → 修复 → 复查」 | 确保每个问题都有确认闭环,避免“看起来有人修过”的假象。 |
| 不让 subagent 读取计划文件 | 控制器须对每个 subagent 的上下文输入负责,防止各自乱读乱解。 |
| 不跳过铺垫上下文 | 缺上下文的实现,极易与架构意图偏离,增加后期返工。 |
| 不无视 subagent 的问题信号 | NEEDS_CONTEXT / BLOCKED 是结构性信号,必须调整条件再重试。 |
| 规范审查不能接受「差不多」 | 一旦妥协,整个质量标准就会滑坡,很快蔓延到后续任务。 |
| 不用自查代替独立审查 | 实施者难以发现自己盲点,需要独立视角审查。 |
| 未经明确同意不动 main/master | 避免对共享主分支做不可控改动,是基本 Git 卫生标准。 |
| 不手动「帮 subagent 修」 | 人工直改会污染上下文,应通过新的修复 subagent 来完成。 |
这些规则的共同目标,是让「流水线行为」比「个别 agent 的表现」更重要:即便单个 subagent 有失误,只要规则不被破坏,就能通过审查链路把问题兜住。
八、与 Superpowers 工作流中的其他技能如何配合?
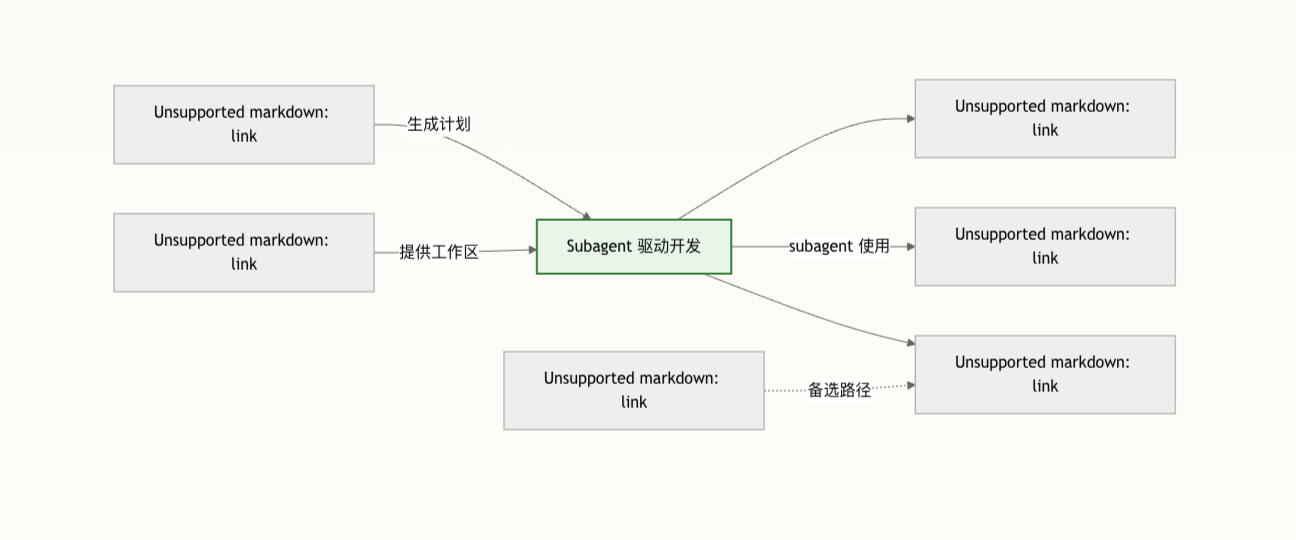
Subagent 驱动开发并不是孤立存在的,它位于整个开发工作流的正中间:
- 前置依赖:
Git Worktrees 隔离:提供一个独立的工作区,让实现和试验不会污染主工作区。计划编写与任务粒度:输出结构化、合理拆分的实施计划,供本技能消费。
- 执行过程中常用能力:
测试驱动开发循环:实施者在每个任务上按 TDD 思路推进,实现–测试–重构的微循环。
- 执行完成后:
完成开发分支:验证测试、展示合并选项、清理工作区等。
如果当前平台不支持 subagent(例如某些只提供单会话模型调用的环境),则可以退化为 内联执行计划。
不过文档明确提示:在支持 subagent 的平台上,内联执行只是一个「质量打折但兼容性更好」的替代方案。
九、与「派发并行 Agent」的关系:什么时候要并行?
在更大的 Superpowers 生态里,还有一个能力叫 派发并行 Agent,同样是用隔离上下文的 agent,但用途完全不同。
官方给出了一张对比表:
| 维度 | Subagent 驱动开发 | 派发并行 Agent |
|---|---|---|
| 主要目的 | 执行结构化的实施计划 | 调试彼此独立的故障区域。 |
| 执行方式 | 串行:一次只处理一个任务。 | 并行:多个 agent 同时工作。 |
| 审查方式 | 强制两阶段流水线(规范 + 质量)。 | 多在集成阶段统一验证。 |
| 输入 | 事先写好的计划任务 | 已识别的、彼此独立的故障点。 |
| Agent 编制 | 每个任务 1 实施者 + 2 审查者。 | 每个问题区域 1 个 agent。 |
Subagent 驱动开发刻意选择串行化实施,以避免 Git 冲突,确保每个任务的改动可以被彻底审查。
而并行派发适用于:你已经知道有多个互不影响的故障点(例如三个失败测试文件,背后是完全不同的根因),此时是「调试」而不是「分解计划执行」。
十、成本与质量的权衡:为何“更贵但更值”
不可否认,这条流水线在调用次数上是更“贵”的:
- 每个任务至少要跑:实施者 + 规范审查者 + 质量审查者。
- 审查一旦发现问题,就要再跑一轮实施者和审查者。
但文档强调:这是一次刻意的成本换质量的决策。
- 控制器在一开始集中解析计划、整理上下文,减少了后续 subagent 重复读文件、重复理解的时间。
- 问题被锁定在「单任务粒度」——越早发现,修复越便宜,也不会污染到后续任务。
- 与在大而杂的上下文里做后期调试相比,多一次审查循环的成本,其实是非常划算的。
对于中大型项目,特别是业务核心链路,这种「前置质量投入」往往能显著降低整体开发和维护成本。
结语:把大模型当工程师用,而不是当宏命令用
Subagent 驱动开发这套设计,有一个很值得借鉴的态度:不要把大模型当作一次性“写代码宏”,而是当作可以被编排的工程师团队。
- 实施者负责干活,自查。
- 审查者负责挑错,把关。
- 控制器负责拆任务、配上下文、做决策。
- 整个过程有显性的状态协议和红线规则,外加与 Git/TDD/分支管理等工程实践的紧密衔接。
如果你正在探索「AI + 开发」的工程化落地,不妨从几个小模块开始尝试这条流水线:
先给出清晰的实施计划,用 Subagent 驱动开发完成一个独立子功能,再逐步把更多任务迁移到这条流水线上,让模型真正融入团队的日常开发过程。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 2
2 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)