
MCP 优化与 OpenAkita 封装:构建高效 AI Agent 的工程实践
Context Mode 的核心思路是在 Claude Code 和外部工具之间插入一个压缩中间层,工具执行结果不直接进入上下文,而是先经过沙盒处理,只让精简后的结果进入对话。当你调用几次 Playwright、读取若干 GitHub issue、拉取日志文件后,半小时不到,40% 的上下文已被工具输出填满,而不是你真正需要的代码和对话内容。这意味着它不改变 Claude 的能力,只改变它能看到的
1. 引言:AI Agent 时代的基础设施挑战
在 2026 年的 AI 应用开发领域,我们正在经历一场从"对话式 AI"到"行动式 AI"的范式转变。传统的聊天机器人只能回答问题,而现代 AI Agent 需要能够调用工具、访问数据、执行任务。这种转变带来了新的技术挑战:如何让 AI 模型高效地与外部系统交互,同时不被海量的上下文信息淹没。
Model Context Protocol(MCP)作为 Anthropic 在 2024 年 11 月推出的开放标准,试图解决这个问题。它定义了 AI 模型与外部数据源、API、数据库和工具之间的通信规范,被业界称为"AI 的 USB-C 标准"。然而,MCP 在实际应用中暴露出一个严重的性能瓶颈:上下文窗口(context window)的快速消耗。当你使用 Claude Code 或其他 MCP 客户端工作半小时后,会发现 AI 开始"失忆"——回答变慢、理解出错、上下文丢失。这不是模型的问题,而是 MCP 工具调用产生的大量输出数据正在吞噬你的上下文空间。
与此同时,OpenAkita(原名 Clawdbot)作为一个开源 AI Agent 框架,在短短几天内从 9000 星暴涨到 10 万星,成为 AI 历史上增长最快的开源项目之一。它采用了与传统方案截然不同的架构设计:模块化、可观测、基于 Markdown 的内存系统。本文将深入探讨 MCP 的上下文优化方案和 OpenAkita 的工程实践,为构建高效 AI Agent 提供可落地的技术路径。
2. MCP 上下文消耗的系统性问题
2.1 双向消耗机制
MCP 工具调用从两个方向消耗上下文窗口。第一个方向是输入侧:工具定义本身需要占用 token。当你激活 81 个 MCP 工具时,仅工具定义就消耗 143K tokens,占据 200K 上下文预算的 72%。这意味着在你开始对话之前,大部分上下文空间已经被工具描述填满。Cloudflare 曾推出 Code Mode 方案,通过压缩工具定义将这部分消耗降低 99.9%,但这只解决了输入侧的问题。

第二个方向是输出侧:工具执行结果作为原始数据返回,直接写入上下文。一个 Playwright 页面快照包含 56KB 的原始 HTML 结构,20 个 GitHub issues 产生 59KB 文本,一个访问日志文件占用 45KB。这些数字看似不大,但在实际工作流中会快速累积。当你调用几次 Playwright、读取若干 GitHub issue、拉取日志文件后,半小时不到,40% 的上下文已被工具输出填满,而不是你真正需要的代码和对话内容。
2.2 实测数据与影响
根据 fastn.ai 的研究报告,在执行 10-15 个任务后,上下文窗口会被 200K+ tokens 填满。模型开始失去焦点,遗忘早期决策,最终任务失败。开发团队报告称,他们需要花费 30-60 分钟重建上下文。一位开发者的评论很有代表性:“我们现在正淹没在曾经苦苦乞求的上下文中。”
这个问题在长时间会话中尤为明显。开始一个 debug 会话,调用几次 Playwright,再读几个 GitHub issue,拉一下日志——半小时不到,Claude 就开始"失忆"。实际上不是失忆,而是上下文满了,模型被迫开始丢弃早期的对话内容。会话工作时长从理论上的数小时缩短到实际的 30 分钟左右,严重影响开发效率。
3. Context Mode:输出侧优化的工程方案
3.1 核心设计思路
Context Mode 是由 Mert Köseoğlu 开发的开源项目,他运营着 MCP Directory & Hub,每天处理超过 10 万次请求。在审查了所有 MCP 服务器后,他发现一个规律:所有人都在构建会把原始数据塞进上下文的工具,但没有人在解决输出侧的问题。Context Mode 的核心思路是在 Claude Code 和外部工具之间插入一个压缩中间层,工具执行结果不直接进入上下文,而是先经过沙盒处理,只让精简后的结果进入对话。
这个方案完全基于算法实现,没有额外的 LLM 介入。它使用 SQLite FTS5 全文搜索引擎和 BM25 排名算法——这是经典信息检索领域的成熟技术,具有快速、确定性强、无幻觉的特点。当你搜索"authentication JWT token"时,返回的是这些词实际出现的段落,而不是某个 AI 对这些段落的总结。这意味着它不改变 Claude 的能力,只改变它能看到的信息量,但信息仍然准确、完整,没有摘要式的信息损失。
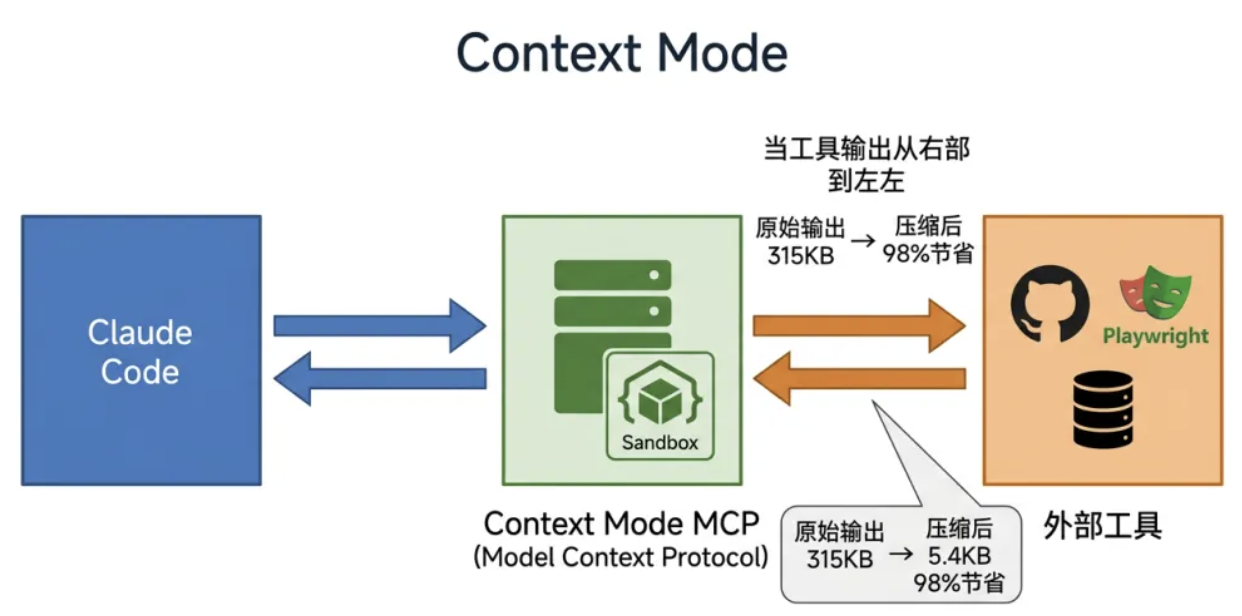
3.2 三层技术架构
Context Mode 的架构包含三个关键组件。第一层是沙盒执行(Sandbox Execution)。每次 execute 调用都在一个隔离的子进程中运行,子进程执行代码并捕获 stdout,只有这个 stdout 最终进入上下文。原始数据——日志文件、API 响应、Playwright 快照——永远不离开沙盒。系统支持 11 种语言运行时:JavaScript、TypeScript、Python、Shell、Ruby、Go、Rust、PHP、Perl、R 和 Elixir。如果检测到 Bun,会自动切换到 Bun 执行 JS/TS,速度提升 3-5 倍。认证过的 CLI 工具(gh、aws、gcloud、kubectl、docker)通过环境变量直通到子进程,不暴露给对话。
第二层是智能过滤机制。当工具输出超过 5KB 且提供了 intent(意图描述)时,Context Mode 会切换到意图驱动过滤模式:把完整输出索引进知识库,搜索匹配你意图的段落,只把相关内容返回。这就像给工具输出建立了一个临时的 RAG(检索增强生成)系统。第三层是知识库系统,使用 SQLite FTS5 虚拟表。index 工具把 Markdown 内容按标题切块存储,搜索使用 BM25 排名算法——一个基于词频和文档长度的概率相关性算法。Porter stemming 在索引时处理词干,所以"running"、“runs”、"ran"都能匹配到同一个词根。搜索还有三层 fallback:Porter stemming → Trigram 子串匹配 → Levenshtein 编辑距离纠错。即使打错字,“kuberntes"也能找到"kubernetes”。
3.3 代码实现示例
以下是 Context Mode 的核心沙盒执行逻辑示例:
// 沙盒执行器的核心实现
class SandboxExecutor {
async execute(code: string, runtime: Runtime, intent?: string): Promise<string> {
// 创建隔离的子进程
const subprocess = spawn(runtime.command, runtime.args, {
env: this.buildSafeEnv(),
cwd: this.workDir,
stdio: ['pipe', 'pipe', 'pipe']
});
// 写入代码到子进程
subprocess.stdin.write(code);
subprocess.stdin.end();
// 捕获输出
const stdout = await this.captureOutput(subprocess.stdout);
const stderr = await this.captureOutput(subprocess.stderr);
// 如果输出过大且有意图描述,进行智能过滤
if (stdout.length > 5000 && intent) {
return await this.filterByIntent(stdout, intent);
}
return stdout;
}
private async filterByIntent(output: string, intent: string): Promise<string> {
// 将输出索引到 FTS5
await this.indexContent(output);
// 使用 BM25 搜索相关段落
const relevantChunks = await this.searchByIntent(intent);
// 返回精简结果
return relevantChunks.join('\n\n');
}
private async searchByIntent(intent: string): Promise<string[]> {
// FTS5 全文搜索查询
const query = `
SELECT content, rank
FROM content_fts
WHERE content_fts MATCH ?
ORDER BY rank
LIMIT 5
`;
const results = await this.db.all(query, [intent]);
return results.map(r => r.content);
}
}
这段代码展示了沙盒执行的核心流程:创建隔离进程、捕获输出、根据输出大小和意图决定是否进行智能过滤。关键在于原始数据永远不进入主上下文,只有经过处理的精简结果才会返回。
3.4 性能数据与实际效果
Context Mode 的官方基准测试覆盖了 8 个真实场景,数据令人印象深刻。Playwright 页面快照从 56.2KB 压缩到 299B,节省 99%;20 个 GitHub Issues 从 58.9KB 压缩到 1.1KB,节省 98%;500 条访问日志从 45.1KB 压缩到 155B,节省 100%。最复杂的代码仓库研究场景,原本需要 37 次工具调用产生 986KB 数据,使用 Context Mode 后只需 5 次调用产生 62KB 数据,节省 94%。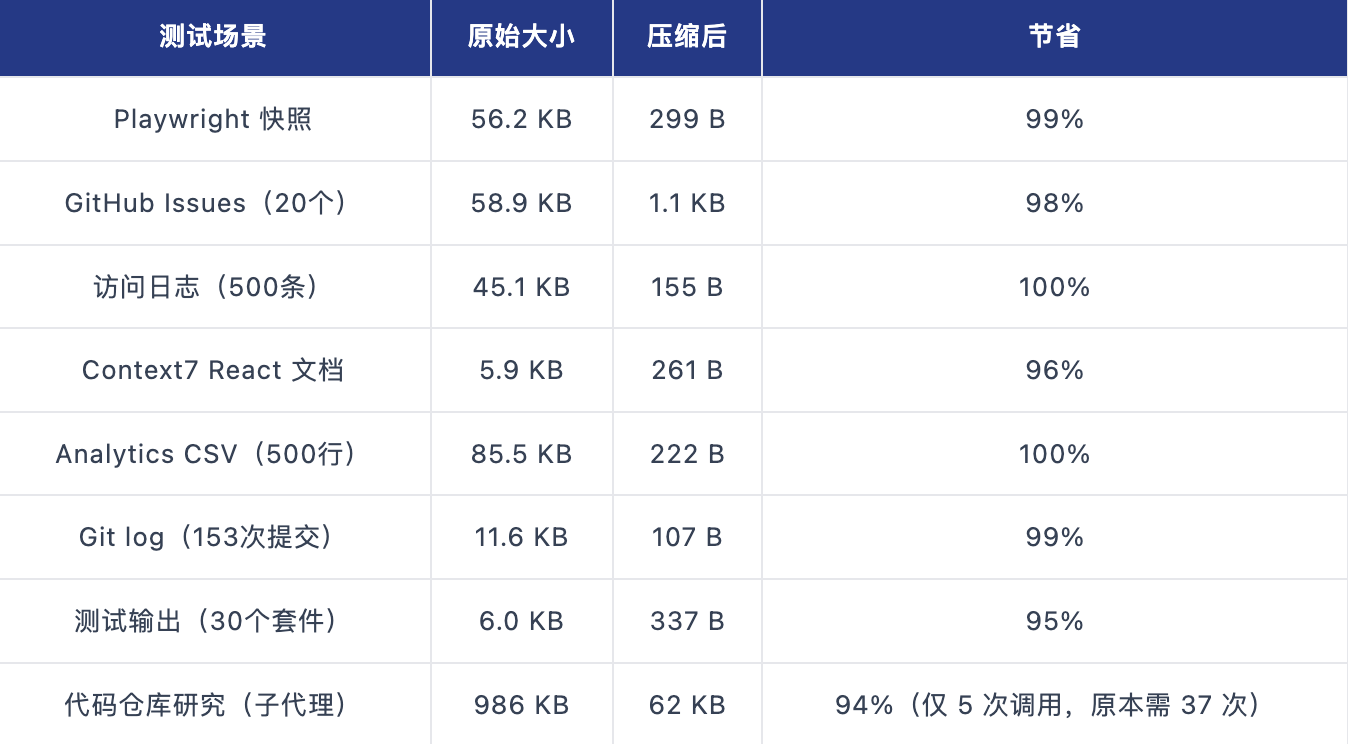
在完整会话中,315KB 的原始工具输出被压缩到 5.4KB,整体节省 98%。会话工作时长从约 30 分钟延长到约 3 小时,提升 6 倍。45 分钟后的剩余上下文从 60% 提升到 99%。这不是微优化,而是用法层面的质变。开发者可以在同一个会话中完成更复杂的任务,而不需要频繁重建上下文。
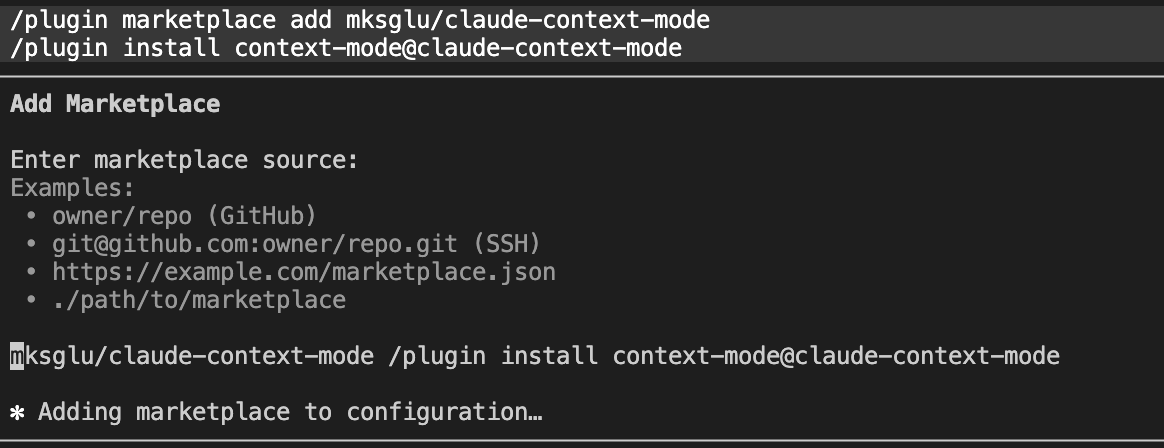
安装 Context Mode 非常简单,通过插件市场只需两行命令:
/plugin marketplace add mksglu/claude-context-mode
/plugin install context-mode@claude-context-mode
安装后会自动注册 PreToolUse hook,将工具输出路由经过沙盒。你不需要改变任何工作方式,系统会透明地处理所有优化。Context Mode 还提供三个诊断命令:/context-mode:stats 查看当前会话的上下文节省情况,/context-mode:doctor 运行诊断检查,/context-mode:upgrade 从 GitHub 拉取最新版本。
4. OpenAkita 模块化 AI Agent 的架构实践
4.1 六层架构体系
OpenAkita 的架构分为六层,每层都有明确的职责边界。最上层是桌面应用层,使用 Tauri + React 构建,提供图形化界面。第二层是推理引擎层,负责任务理解和决策。第三层是 Agent 调度层,包含 AgentOrchestrator 做总调度和 AgentInstancePool 管理 Agent 实例,支持最多 5 层委派深度,防止任务递归失控。
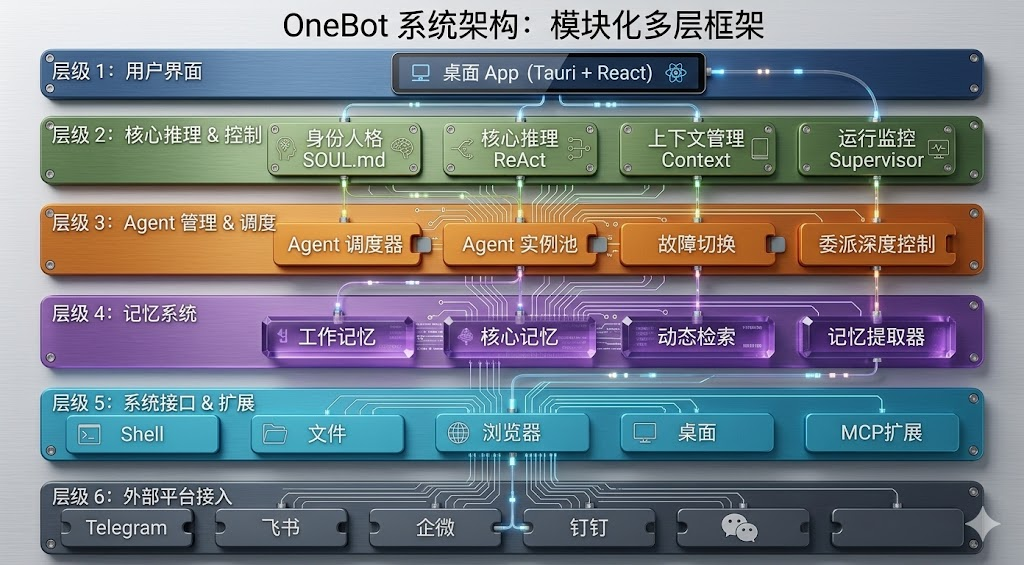
第四层是记忆系统层,这是 OpenAkita 的一大创新。与传统方案使用向量数据库不同,OpenAkita 的整个记忆系统运行在 Markdown 文件上。纯文本文件就放在项目目录中,你可以阅读、编辑、用 git 版本控制,或者随时删除。系统实现了三层记忆:工作记忆(当前任务上下文)、核心记忆(用户画像和偏好)、动态检索(历史经验),支持 7 种记忆类型。两个月前告诉它你喜欢简洁风格,现在写东西它还记得。
第五层是工具层,则是OpenAkita主要的贡献,内置 89 种工具,覆盖 16 个类别。这些工具不是简单的 API 包装,而是具有严格契约的能力单元。每个工具都有明确的输入输出规范、错误处理机制和权限控制。第六层是通信层,对接 6 个 IM 平台:飞书、企微、钉钉、Telegram、QQ、OneBot。在你常用的聊天工具里直接 @ 它,发语音也能识别,不需要单独开一个应用。

两段式 Prompt 架构:Prompt Compiler
OpenAkita 在推理引擎层实现了创新的两段式 Prompt 架构,将任务理解与任务执行分离:
第一阶段:Prompt Compiler(任务编译器)
Prompt Compiler 是一个专门的轻量级模型,负责将用户的自然语言请求转化为结构化的任务定义。它不解决问题,只负责理解和结构化需求。
输出格式(YAML):
task_type: [question/action/creation/analysis/reminder/other]
goal: [一句话描述任务目标]
inputs:
given: [已提供的信息列表]
missing: [缺失但可能需要的信息列表]
constraints: [约束条件列表]
output_requirements: [输出要求列表]
risks_or_ambiguities: [风险或歧义点列表]
第二阶段:主 LLM 执行
主 LLM 接收结构化的任务定义,专注于执行和解决问题。这种分离带来三个优势:
- 降低歧义:结构化定义减少主 LLM 的理解偏差
- 提升质量:主 LLM 可以专注于解决问题而非理解需求
- 成本优化:Compiler 使用小模型,主 LLM 只处理明确任务
渐进式披露工具系统
OpenAkita 的 89 种工具采用三层渐进式披露机制,避免一次性加载所有工具定义导致的上下文膨胀:
| 层级 | 内容 | 时机 | Token 消耗 |
|---|---|---|---|
| Level 1 | 工具清单(name + 简短描述) | 系统提示中提供 | ~2K tokens |
| Level 2 | 详细说明(参数、示例、触发条件) | 通过 get_tool_info 按需获取 |
~200 tokens/工具 |
| Level 3 | 直接执行 | LLM 调用工具 | 实际执行 |
高频工具白名单:5 个最常用工具(run_shell, read_file, write_file, list_directory, ask_user)跳过 Level 2,直接提供完整 schema,减少交互轮次。
16 个工具分类(按系统提示展示顺序):
- File System - 文件系统操作
- Agent - Agent 委派与协作
- Skills - 技能管理
- Memory - 记忆系统
- Web Search - 网络搜索
- Browser - 浏览器自动化
- Desktop (Windows) - 桌面自动化
- Scheduled Tasks - 定时任务
- IM Channel - IM 平台集成
- User Profile - 用户画像
- System - 系统工具
- MCP - Model Context Protocol
- Plan - 计划模式
- Persona - 人格切换
- Sticker - 表情包
- Config - 配置管理
上下文管理策略
OpenAkita 针对 200K 上下文窗口实现了智能管理策略:
# 上下文预算配置
DEFAULT_MAX_CONTEXT_TOKENS = 160000 # 200K - 4K输出预留 - 10%安全边际
COMPRESSION_RATIO = 0.15 # 压缩到原上下文的 15%
CHUNK_MAX_TOKENS = 30000 # 单次压缩块上限
LARGE_TOOL_RESULT_THRESHOLD = 5000 # 大型工具结果独立压缩阈值
MIN_RECENT_TURNS = 4 # 至少保留最近 4 轮对话
当上下文接近预算时,系统会:
- 保护最近对话:最近 4 轮对话永不压缩
- 分块压缩:将早期对话分成 30K token 的块,逐块压缩
- 大结果独立处理:超过 5K tokens 的工具结果单独压缩
- 递归压缩:如果压缩后仍超限,继续压缩直到满足预算
这种策略使得 OpenAkita 可以在长时间会话中保持高质量的上下文,避免传统方案中"越聊越傻"的问题。
4.2 安装与配置
OpenAkita 提供三种安装方式,适合不同使用场景。
方式一:桌面应用(推荐新手)
直接从 GitHub Releases 下载预编译的桌面应用:
# 访问 GitHub Releases 页面
https://github.com/openakita/openakita/releases
# 下载对应平台的安装包
# macOS: OpenAkita-{version}.dmg
# Windows: OpenAkita-{version}.exe
# Linux: OpenAkita-{version}.AppImage
桌面应用内置图形化配置向导,首次启动会引导你完成:
- AI 模型配置(Claude/GPT/Gemini API 密钥)
- IM 平台连接(可选)
- 工作目录设置
方式二:pip 安装(推荐开发者)
使用 Python 包管理器安装,适合需要自定义集成的场景:
# 完整安装(包含所有依赖)
pip install openakita[all]
# 最小安装(仅核心功能)
pip install openakita
# 指定版本安装
pip install openakita[all]==1.2.0
安装后需要手动配置:
# 初始化配置文件
openakita init
# 编辑配置文件
vim ~/.openakita/config.yaml
配置文件示例:
# ~/.openakita/config.yaml
llm:
provider: anthropic # anthropic | openai | google
api_key: YOUR_API_KEY
model: claude-3-opus-20240229
memory:
storage_path: ~/.openakita/memory
max_history: 1000
tools:
enabled:
- file_operations
- web_search
- code_execution
disabled:
- system_commands # 禁用危险操作
im_platforms:
telegram:
enabled: true
bot_token: YOUR_BOT_TOKEN
feishu:
enabled: false
方式三:源码安装(推荐贡献者)
从源码构建,适合需要修改或贡献代码的场景:
# 克隆仓库
git clone https://github.com/openakita/openakita.git
cd openakita
# 安装依赖
npm install # 前端依赖
pip install -e ".[dev]" # Python 依赖(开发模式)
# 构建桌面应用
npm run build
npm run tauri build
# 或直接运行开发模式
npm run tauri dev
验证安装
安装完成后,验证 OpenAkita 是否正常工作:
# 检查版本
openakita --version
# 运行健康检查
openakita doctor
# 启动交互式会话
openakita chat
如果遇到问题,可以查看日志文件:
# 日志位置
~/.openakita/logs/openakita.log
# 实时查看日志
tail -f ~/.openakita/logs/openakita.log
4.3 ReAct 推理机制
OpenAkita 的底层推理逻辑采用 ReAct(Reasoning and Acting)机制:思考 → 行动 → 观察,三阶段显式循环。这不是黑盒推理,而是可观测的决策过程。系统有 Checkpoint 机制,失败了能回退。遇到卡住的任务,它会自动切换策略,而不是直接告诉你"我不行"。
以下是 ReAct 循环的核心实现(基于 OpenAkita 实际源码):
class ReActAgent:
def __init__(self, llm, tools, memory, tracer):
self.llm = llm
self.tools = tools
self.memory = memory
self.tracer = tracer # AgentTracer 实例
self.max_iterations = 10
async def execute(self, task: str, session_id: str) -> str:
# 开始追踪(非上下文管理器版本,适合多返回路径)
trace = self.tracer.begin_trace(session_id, metadata={"task": task})
try:
context = self.memory.load_context(task)
for iteration in range(self.max_iterations):
# 推理循环 Span
with self.tracer.reasoning_span(iteration=iteration):
# 思考阶段:分析当前状态,决定下一步
with self.tracer.llm_span(model="claude-3-opus") as llm_span:
thought = await self.llm.think(
task=task,
context=context,
history=self.memory.get_history()
)
llm_span.set_attribute("input_tokens", thought.input_tokens)
llm_span.set_attribute("output_tokens", thought.output_tokens)
# 行动阶段:选择工具并执行
if thought.action:
# 决策节点 Span(Agent Harness 扩展)
with self.tracer.decision_span(
decision_type="tool_selection",
reasoning=thought.reasoning
) as decision_span:
decision_span.set_attribute("selected_tool", thought.action.name)
# 工具执行 Span
with self.tracer.tool_span(tool_name=thought.action.name) as tool_span:
tool = self.tools.get(thought.action.name)
observation = await tool.execute(thought.action.params)
tool_span.set_attribute("result_size", len(str(observation)))
# 观察阶段:记录结果,更新上下文
context.append({
'thought': thought.reasoning,
'action': thought.action,
'observation': observation
})
# 保存 checkpoint(记忆操作 Span)
with self.tracer.memory_span(operation="save_checkpoint"):
self.memory.save_checkpoint(iteration, context)
# 验证节点 Span(Agent Harness 扩展)
with self.tracer.verification_span(
verification_type="task_completion"
) as verify_span:
if thought.is_complete:
verify_span.set_attribute("result", "completed")
return observation
verify_span.set_attribute("result", "continue")
else:
# 无需行动,直接返回答案
return thought.answer
# 达到最大迭代次数,返回当前状态
return self.memory.summarize(context)
finally:
# 结束追踪
self.tracer.end_trace(metadata={"iterations": iteration + 1})
这段代码展示了 ReAct 循环与追踪系统的深度集成:
- 完整追踪生命周期:使用
begin_trace/end_trace管理整个任务的追踪 - 嵌套 Span 结构:REASONING → LLM/DECISION/TOOL/MEMORY/VERIFICATION 形成父子关系
- Agent Harness 扩展:DECISION 和 VERIFICATION Span 记录关键决策点
- 属性记录:每个 Span 记录 token 消耗、工具名称、结果大小等关键指标
- 异常安全:finally 块确保追踪数据始终被导出
关键在于整个过程是可观测的,每个决策点、工具调用、LLM 推理都被记录为独立的 Span,你可以在神经网络仪表盘实时看到每个 Agent 的工作状态。
Ralph Wiggum 循环引擎:永不放弃的执行哲学
…详情请参照古月居

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)