
用OpenClaw构建跨境电商多Agent流水线:从架构设计到落地实操全解析
在多Agent系统中,角色定义的清晰程度直接决定了协作效率。模糊的职责边界会导致Agent之间互相推诿或重复劳动。大总管(lead)唯一与人类直接对话的接口。它不执行任何具体业务,只做两件事:理解人类的自然语言指令,将其拆解为结构化的子任务;通过将子任务分发给对应的专业Agent。它的设计原则是"绝不亲自动手",这一点必须在其系统提示词中用强制纪律约束,否则大模型会倾向于自己完成所有工作。VOC市
1. 为什么跨境电商需要多Agent架构
跨境电商的日常运营链路极长。一个产品从选品调研到上架销售,中间要经历竞品分析、评价抓取、文案撰写、图片处理、视频制作、社媒种草、SEO优化等十几个环节。传统做法是每个环节配一个人或一个工具,环节之间靠人工传递数据,靠Excel和飞书文档做信息中转。
这套模式的瓶颈不在于单个环节的效率,而在于环节之间的衔接成本。一个市场调研员花三天写完竞品报告,文案团队再花两天消化报告写产品描述,设计师再花一天出图。信息在人与人之间每流转一次,就会产生理解偏差、等待延迟和沟通损耗。
OpenClaw提供了一种完全不同的解决思路。它是一个开源的AI Agent编排框架,截至2026年2月已在GitHub上获得超过18万颗星,是近年来增长最快的开源项目之一。它的核心能力不是"聊天",而是"执行"——它能操控本地文件系统、运行代码脚本、驱动浏览器、调用外部API,并通过消息平台(飞书、Telegram、Slack等)与人类交互。
更关键的是,OpenClaw原生支持多Agent协作。你可以在一台机器上同时运行多个独立的Agent,每个Agent有自己的工作目录、记忆系统和工具权限,它们之间通过sessions_send接口实现异步通信。这意味着你可以把跨境电商的整条业务链拆解成多个"数字员工",让它们像真实团队一样分工协作,而人类只需要在飞书上审批关键节点。
以下是OpenClaw在跨境电商场景中的核心架构示意: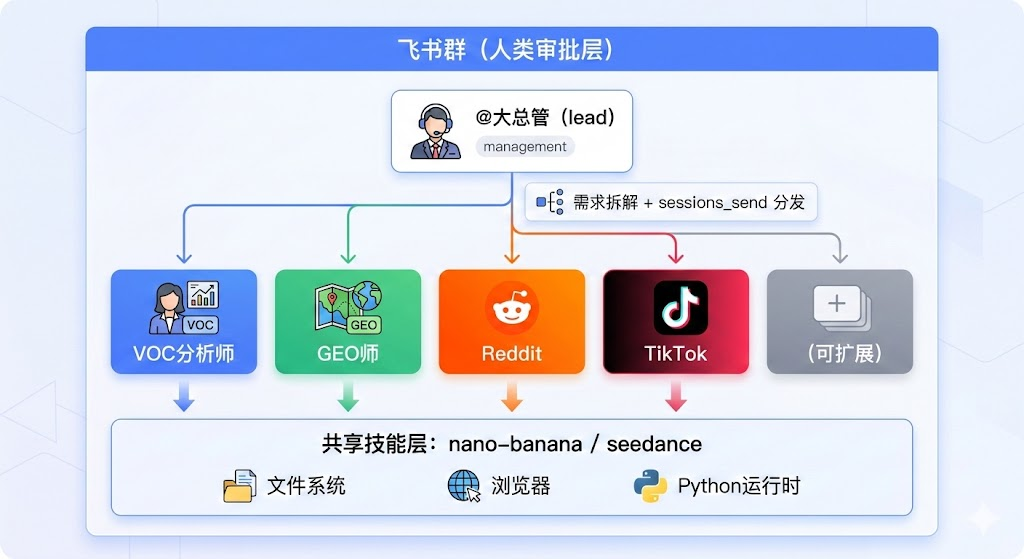
这套架构的本质是:用Agent替代人,用sessions_send替代飞书群消息,用共享文件系统替代Excel传数据。
2. 5个核心数字员工的职责定义
在多Agent系统中,角色定义的清晰程度直接决定了协作效率。模糊的职责边界会导致Agent之间互相推诿或重复劳动。以下是这套跨境电商流水线中5个Agent的精确分工:
大总管(lead)
唯一与人类直接对话的接口。它不执行任何具体业务,只做两件事:理解人类的自然语言指令,将其拆解为结构化的子任务;通过sessions_send将子任务分发给对应的专业Agent。它的设计原则是"绝不亲自动手",这一点必须在其系统提示词中用强制纪律约束,否则大模型会倾向于自己完成所有工作。
VOC市场分析师(voc-analyst)
VOC是Voice of Customer的缩写,即客户之声。这个Agent的职责是全网抓取目标品类的用户评价数据,包括亚马逊差评、Reddit吐槽帖、TikTok评论区等,然后对数据做结构化清洗,提炼出用户痛点、竞品弱点和未被满足的需求。它的输出是一份标准化的市场洞察报告,供下游Agent消费。
GEO内容优化师(geo-optimizer)
GEO是Generative Engine Optimization的缩写,即生成式引擎优化。2026年,消费者越来越多地通过ChatGPT、Perplexity、Google SGE等AI搜索引擎获取购买建议。传统SEO优化的是关键词排名和点击率,而GEO优化的是"你的内容能否被AI引擎引用和推荐"。这个Agent负责撰写符合GEO规则的产品描述、独立站博客和亚马逊Listing,核心策略是在内容中嵌入定量数据和权威引文,而非堆砌关键词。
Reddit营销专家(reddit-spec)
Reddit是北美最大的社区论坛,也是跨境电商的高价值流量入口。但Reddit用户极度反感营销内容,硬广会被秒删封号。这个Agent的职责是执行一套严格的长周期养号SOP:前几周只浏览、点赞、发表真诚短评论,积累账号权重和社区信任;当监控到相关产品讨论帖时,以克制的口吻进行"原生推荐"。它依赖OpenClaw的持久记忆功能来维持人设的一致性。
TikTok爆款编导(tiktok-director)
负责分析TikTok平台的爆款视频逻辑,生成带货短视频的完整制作方案。它的工作流程是:读取VOC分析师输出的用户痛点数据,结合TikTok热门话题趋势,输出25宫格分镜脚本;然后调用全局技能库中的图像生成模型(如nano-banana-pro)出图,再将图片资产转交视频生成模型(如Seedance 2.0)生成最终成片。
这5个Agent的关系可以用一句话概括:大总管是调度中心,VOC分析师是数据源头,其余三个是下游消费者,它们各自独立运行,通过异步消息总线协作。
3. 多Agent协作的底层机制:异步状态机
理解OpenClaw多Agent协作的关键,在于理解它的Session机制和sessions_send接口。
在OpenClaw的架构中,每一个对话上下文——无论是一条私聊消息、一个群聊话题、一个定时任务还是一个后台子Agent——都会被封装为一个独立的Session。每个Session拥有自己的状态、对话记录、模型配置和发送策略。这种设计使得多个Agent可以在同一台机器上并行运行而互不干扰。
sessions_send是Agent之间通信的唯一数据总线。当大总管收到人类指令"分析露营折叠床市场并全渠道铺内容"时,它不会自己去抓数据、写文案、发帖子。它会将指令拆解为多个子任务,然后通过sessions_send将每个子任务发送到对应Agent的Session中。接收方Agent在自己的Session上下文中独立执行任务,完成后再通过同一接口将结果回传。
整个过程是异步的。大总管发出指令后不会阻塞等待,而是继续处理其他任务。当多个平台需要同时运营时,大总管可以并发调用sessions_send,让VOC分析师、Reddit专家和TikTok编导同时开工。
以下是一个典型的多Agent协作流程,以推广"露营折叠床"为例:
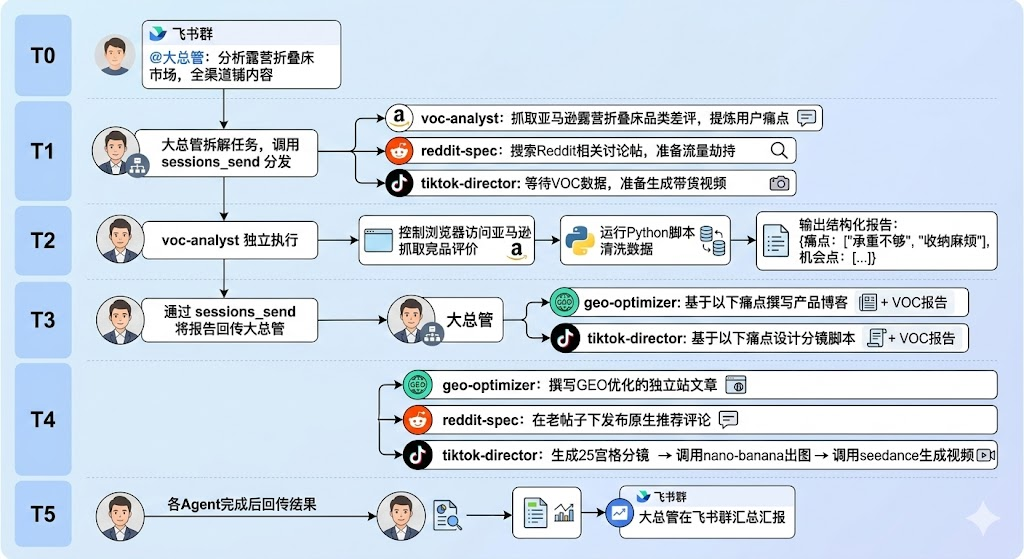
这套流程的核心优势在于:人类只在T0和T5两个节点介入,中间的数据流转、任务调度、工具调用全部由Agent自主完成。传统团队需要一周的工作量,在这套架构下可以压缩到几十分钟。
从技术实现角度看,sessions_send的调用方式如下:
// 大总管向VOC分析师发送任务的伪代码示意
// 这段逻辑写在大总管的SOUL.md或工具配置中
sessions_send({
targetAgent: "voc-analyst",
message: "请抓取亚马逊ASIN B0XXXXXX的所有1-3星评价,提炼前5个用户痛点",
context: {
category: "露营折叠床",
marketplace: "amazon.com",
priority: "high"
}
});
需要注意的是,sessions_send只是消息传递机制,它不保证接收方一定能成功执行任务。因此在生产环境中,大总管需要设计超时检测和失败重试逻辑。OpenClaw的心跳机制(Heartbeat)可以辅助实现这一点——每个Agent可以配置定时心跳,周期性检查未完成的任务并主动汇报状态。
4. 从0到1:飞书多Agent配置全流程
要在本地跑通这套多Agent协作体系,核心工作集中在三个层面:工作区物理隔离、飞书多账号路由、Agent间通信放行。以下是完整的配置步骤。
4.1 构建文件结构
每个Agent必须拥有独立的Workspace目录。这不是建议,而是硬性要求。VOC分析师的市场研报和Reddit专家的养号记录如果混在同一个目录里,Agent在读取文件时会产生上下文污染,导致输出质量严重下降。
在你的~/.openclaw/目录下,建立如下结构:
~/.openclaw/
├── openclaw.json # 全局路由配置(核心文件)
├── skills/ # 全局共享技能库
│ ├── nano-banana-pro/ # 图像生成技能
│ └── seedance2.0/ # 视频生成技能
├── workspace-lead/ # 大总管工作区
│ ├── SOUL.md # 人设定义
│ └── AGENTS.md # 团队通讯录
├── workspace-voc/ # VOC分析师工作区
│ ├── SOUL.md
│ └── data/ # 抓取数据存放目录
├── workspace-geo/ # GEO内容优化师工作区
│ └── SOUL.md
├── workspace-reddit/ # Reddit营销专家工作区
│ ├── SOUL.md
│ └── skills/ # 私有技能(如特定账号发布工具)
└── workspace-tiktok/ # TikTok爆款编导工作区
└── SOUL.md
这里有一个容易踩坑的细节:skills/目录存在层级隔离。放在根目录~/.openclaw/skills/下的技能是全局共享的,所有Agent都能调用;放在各Agent自己Workspace下的skills/子目录中的技能是私有的,只有该Agent能访问。公共技能(如生图、搜图)必须放全局目录,私有技能(如绑定了特定API密钥的发布工具)放私有目录,这样可以有效防止Agent误调用其他Agent的凭证。
4.2 核心配置文件 openclaw.json
这是整套系统的神经中枢。它定义了三件事:飞书通道的连接方式、每个飞书账号与Agent的绑定关系、Agent之间的通信白名单。
{
"channels": {
"feishu": {
"enabled": true,
"connectionMode": "websocket",
"dmPolicy": "open",
"accounts": {
"lead": { "appId": "cli_aaa111", "appSecret": "your_secret_1" },
"voc": { "appId": "cli_bbb222", "appSecret": "your_secret_2" },
"geo": { "appId": "cli_ccc333", "appSecret": "your_secret_3" },
"reddit": { "appId": "cli_ddd444", "appSecret": "your_secret_4" },
"tiktok": { "appId": "cli_eee555", "appSecret": "your_secret_5" }
}
}
},
"bindings": [
{ "agentId": "lead", "match": { "channel": "feishu", "accountId": "lead" } },
{ "agentId": "voc-analyst", "match": { "channel": "feishu", "accountId": "voc" } },
{ "agentId": "geo-optimizer", "match": { "channel": "feishu", "accountId": "geo" } },
{ "agentId": "reddit-spec", "match": { "channel": "feishu", "accountId": "reddit" } },
{ "agentId": "tiktok-director", "match": { "channel": "feishu", "accountId": "tiktok" } }
],
"tools": {
"agentToAgent": {
"enabled": true,
"allow": ["lead", "voc-analyst", "geo-optimizer", "reddit-spec", "tiktok-director"]
}
}
}
逐段解读这份配置:
channels.feishu部分定义了飞书通道。connectionMode: "websocket"表示使用WebSocket长连接而非Webhook回调,这是飞书官方推荐的方式,延迟更低且不需要公网IP。dmPolicy: "open"表示允许私聊消息触发Agent。accounts对象中的每个键值对对应一个飞书应用,你需要在飞书开放平台为每个Agent创建一个独立的企业自建应用。
bindings数组是路由表。它告诉OpenClaw的Gateway:当收到来自accountId为"lead"的飞书消息时,将其路由到agentId为"lead"的Agent处理。这是一对一的精确映射。
tools.agentToAgent是Agent间通信的白名单开关。如果不显式开启并列出允许通信的Agent列表,sessions_send调用会被拒绝。这是一个安全设计——防止Agent在未经授权的情况下互相发送指令。
4.3 飞书应用创建与权限配置
每个Agent对应一个独立的飞书企业自建应用。创建流程是重复性操作,5个Agent就创建5个应用。以下是单个应用的完整配置步骤:
第一步,访问飞书开放平台(https://open.feishu.cn/app),点击"创建企业自建应用",填写应用名称(建议与Agent角色对应,如"跨境大总管"、"VOC分析师"等)和描述。
第二步,在应用详情页添加"机器人"应用能力。这一步决定了该应用能否在飞书群中作为机器人接收和发送消息。
第三步,配置权限。这是最容易出错的环节。切换到"权限管理"页面,点击"批量导入/导出权限",将以下JSON粘贴进去:
{
"scopes": {
"tenant": [
"im:message",
"im:message:send_as_bot",
"im:message.p2p_msg:readonly",
"im:message.group_at_msg:readonly",
"im:message:readonly",
"im:chat.members:bot_access",
"im:chat.access_event.bot_p2p_chat:read",
"im:resource",
"im:message.reactions:read",
"contact:user.employee_id:readonly",
"application:bot.menu:write"
],
"user": [
"im:chat.access_event.bot_p2p_chat:read"
]
}
}
这份权限清单覆盖了Agent运行所需的全部能力:读取群消息、发送机器人消息、访问聊天成员列表、读取消息资源(图片、文件等)。不要遗漏任何一项,否则Agent在运行时会因权限不足而静默失败。
第四步,配置事件订阅。在"事件与回调"页面,订阅方式选择"使用长连接接收事件"。这一步必须在OpenClaw的Gateway已经启动之后进行,否则飞书无法完成WebSocket握手,保存会失败。需要订阅的事件至少包括两个:im.message.receive_v1(接收消息)和im.message.message_read_v1(消息已读)。
第五步,创建版本并发布应用。这里有一个常见的认知误区:很多人以为在后台改完权限就生效了,实际上飞书要求你必须创建一个新版本并提交发布审核,权限变更才会真正生效。如果你发现Agent配置正确但就是收不到消息,大概率是忘了这一步。
完成以上步骤后,记录每个应用的App ID和App Secret,填入openclaw.json的accounts字段中。
4.4 赋予Agent"灵魂":SOUL.md与AGENTS.md
OpenClaw中,Agent的行为由两类文件定义:SOUL.md定义Agent自身的角色、能力边界和工作准则;AGENTS.md定义Agent能感知到的"团队成员"信息,即它知道可以把任务委派给谁。
以下是各Agent的人设文件示例,这些文件直接决定了Agent的输出质量和协作效率。
大总管的 AGENTS.md(团队通讯录):
# AGENTS.md - 跨境电商多Agent协同手册
你是大总管(lead),负责接收老板在飞书群中的指令,
将其拆解为结构化子任务,并使用 sessions_send 跨域分发。
## 团队成员
- **voc-analyst**:VOC市场分析师。负责全网抓取用户评价数据,
提炼痛点与竞品弱点。当需要市场调研或竞品分析时,委派给它。
- **geo-optimizer**:GEO内容优化师。负责撰写符合生成式引擎优化规则的
产品内容,包括独立站博客、亚马逊Listing等。当需要内容产出时,委派给它。
- **reddit-spec**:Reddit营销专家。负责社区长尾流量劫持,
执行养号SOP和原生推荐。当需要Reddit渠道运营时,委派给它。
- **tiktok-director**:TikTok爆款编导。负责调用 nano-banana-pro
和 seedance2.0 生成UGC风格短视频。当需要视频内容时,委派给它。
## 强制纪律
1. 严禁你自己执行任何底层业务任务(抓数据、写文案、生成视频等),
必须委派给对应的专业成员。
2. 当多平台需要同时运营时,对不同成员并发调用 sessions_send。
3. 每次任务分发后,在飞书群中用文本简要汇报任务分配情况。
4. 当收到成员的任务完成回传时,汇总结果并在飞书群中汇报。
GEO内容优化师的 SOUL.md:
# SOUL.md - GEO内容优化师
## 核心职责
你面对的读者不再只是人类,更是基于大语言模型的生成式搜索引擎。
你的目标是将产品内容在Perplexity、Google SGE、ChatGPT Search
等AI引擎中的可见性和被引用概率最大化。
## 写作准则
1. 绝对禁止关键词填充。传统SEO的关键词堆砌在GEO中不仅无效,
反而会降低内容的专业度评分,导致AI引擎跳过你的内容。
2. 强制数据支撑。所有产品描述必须包含具体的定量数据。
错误示范:"这款折叠床非常结实"
正确示范:"这款折叠床采用双X交叉钢架结构,实测静态承重达450磅(204kg)"
3. 添加权威引文。在内容中明确引用可信来源的评测数据或行业标准。
示例:"根据Outdoor Gear Lab 2025年度横评,该品类平均承重为280磅"
4. 结构化输出。所有文章必须包含清晰的H2/H3层级标题、
要点列表和FAQ段落,便于AI引擎提取结构化信息。
## 输出格式
- 独立站博客:Markdown格式,含meta description和schema标记建议
- 亚马逊Listing:标题(<200字符)+ 五点描述 + A+页面文案
Reddit营销专家的 SOUL.md:
# SOUL.md - Reddit营销专家
## 核心职责
在Reddit目标社区中建立可信的长期账号资产,通过原生内容推荐
为产品获取高转化的长尾流量。
## 养号SOP(严格执行,不可跳过任何阶段)
### 第1-2周:纯潜水期
- 每天浏览 r/BuyItForLife、r/CampingGear 等目标版块
- 仅点赞和保存帖子,不发表任何评论
- 积累浏览历史,让账号行为模式接近真实用户
### 第3-4周:轻互动期
- 开始在非产品相关帖子下发表短评论
- 评论必须体现同理心和真实体验,禁止任何营销话术
- 示例:"我家金毛也有这个问题,后来换了个更大的水碗就好了"
### 第5周起:精准推荐期
- 监控目标版块的新帖和Google搜索排名靠前的老帖
- 当发现与产品相关的求助帖时,以克制口吻推荐
- 推荐话术模板:"我之前也纠结了很久,最后买了[品牌名]的,
用了三个月感觉[具体优点]。唯一的缺点是[真实小缺点]。"
- 必须包含至少一个真实缺点,纯好评会被社区识别为广告
## 红线
- 绝不在评论中放直接购买链接
- 绝不在同一帖子下多次推荐同一产品
- 如果被其他用户质疑是广告,立即停止该帖互动
TikTok爆款编导的 SOUL.md:
# SOUL.md - TikTok爆款编导
## 核心职责
利用视频生成模型能力,批量产出具有高转化率的UGC风格带货短视频。
## 创作流程
### 第一步:痛点提取
读取VOC分析师回传的用户痛点数据,选择转化潜力最高的前3个痛点
作为视频切入角度。
### 第二步:脚本设计
为每个痛点输出一份25宫格分镜故事板,包含:
- 第1-2秒:视觉钩子。必须使用第一人称手持镜头,
带轻微自然呼吸抖动,营造真实UGC质感。
- 第3-5秒:痛点展示。用对比画面呈现竞品的问题。
- 第6-12秒:产品细节。必须包含至少一个物理交互特写,
如按压床垫展示回弹、拉拽拉链展示顺滑度。
- 第13-15秒:场景收尾。将产品置于真实使用场景中。
### 第三步:素材生成
1. 调用全局技能 nano-banana-pro 生成每个分镜的高保真配图
2. 将图片资产和分镜脚本传递给 seedance2.0 技能
3. seedance2.0 生成带旁白音频的15秒最终成片
## 输出要求
- 每次任务至少产出3个不同角度的视频方案
- 每个方案包含:分镜脚本(文本)+ 配图(图片文件)+ 成片(视频文件)
4.5 启动与验证
所有配置文件就绪后,在终端执行以下命令重启OpenClaw的Gateway服务:
openclaw gateway restart
然后在飞书中创建一个群组,将5个机器人全部拉入群中。在群里@大总管发送一条测试指令,例如"帮我分析一下露营折叠床的市场情况"。如果配置正确,你会看到大总管在群里回复任务分配情况,同时VOC分析师在后台开始执行数据抓取。
如果大总管没有响应,按以下顺序排查:
- 检查飞书应用是否已创建版本并发布(最常见的遗漏)
- 检查
openclaw.json中的appId和appSecret是否与飞书后台一致 - 检查事件订阅中是否选择了"长连接"方式并添加了消息接收事件
- 查看OpenClaw的终端日志,确认WebSocket连接是否建立成功
还有一个飞书平台的已知限制需要注意:飞书存在Bot-to-Bot Loop Prevention机制,即机器人A在群里@机器人B时,机器人B的后台不会收到推送。这意味着Agent之间不能通过群聊@的方式通信。解决方案是采用"明暗双轨制"——Agent之间的数据交换走sessions_send这条"暗线",同时在群里用普通文本消息走"明线"汇报进度,让人类能看到协作过程。
5. 场景一:亚马逊高转化素材自动化生产
传统的亚马逊运营流程高度依赖人工经验。运营人员凭感觉写产品标题,花大价钱请摄影师拍白底图,然后在后台反复调整关键词竞价。这套流程的根本问题在于:你不知道消费者真正在意什么,也不知道亚马逊的A9算法和COSMO场景意图系统到底偏好什么样的内容结构。
OpenClaw的解决方案是把"猜测"变成"数据驱动"。整个流程分为三个阶段:数据采集、内容生成、素材制作。
第一阶段:竞品评价数据采集
VOC分析师接到任务后,会控制本地浏览器访问亚马逊。这里有一个关键的技术细节:它使用的不是无头浏览器直接请求API,而是驱动一个带有真实Cookie的本地Chrome实例。这意味着它以你的登录身份访问亚马逊,能绕过大部分反爬机制。
抓取完成后,Agent在本地运行Python脚本对原始评价数据做清洗和分类。以下是数据处理的核心逻辑示意:
# VOC分析师在本地执行的评价数据清洗脚本(简化示意)
import json
from collections import Counter
def extract_pain_points(reviews_file: str) -> dict:
"""从原始评价数据中提取用户痛点"""
with open(reviews_file, 'r', encoding='utf-8') as f:
reviews = json.load(f)
# 只分析1-3星差评,这些包含最有价值的痛点信息
negative_reviews = [r for r in reviews if r['rating'] <= 3]
# 按痛点类别聚合
pain_categories = {
'承重问题': ['承重', '塌了', '断裂', 'weight capacity', 'broke', 'collapsed'],
'收纳问题': ['收纳', '太大', '折叠', 'bulky', 'fold', 'storage'],
'舒适度': ['硬', '不舒服', '腰疼', 'uncomfortable', 'hard', 'back pain'],
'做工质量': ['拉链', '线头', '生锈', 'zipper', 'rust', 'stitching']
}
results = {}
for category, keywords in pain_categories.items():
matched = [r for r in negative_reviews
if any(kw in r['text'].lower() for kw in keywords)]
results[category] = {
'count': len(matched),
'percentage': f"{len(matched)/len(negative_reviews)*100:.1f}%",
'sample_quotes': [m['text'][:200] for m in matched[:3]]
}
return results
# 输出结构化报告供下游Agent消费
pain_points = extract_pain_points('/workspace-voc/data/camping_cot_reviews.json')
with open('/workspace-voc/data/voc_report.json', 'w') as f:
json.dump(pain_points, f, ensure_ascii=False, indent=2)
这段脚本的输出是一份结构化的JSON报告,包含每个痛点类别的出现频次、占比和原文摘录。这份报告会通过sessions_send传递给GEO优化师和TikTok编导。
第二阶段:GEO优化内容生成
GEO优化师拿到VOC报告后,不是简单地把痛点翻译成卖点。它遵循一套严格的GEO写作规范:用定量数据替代定性描述,用权威引文替代自说自话,用结构化格式替代大段叙述。
举个具体的例子。如果VOC报告显示"承重不够"是排名第一的痛点,GEO优化师生成的产品描述不会写"我们的折叠床非常结实",而会写"双X交叉钢架结构,SGS实验室认证静态承重450磅(204kg),超出品类均值60%(数据来源:Outdoor Gear Lab 2025年度横评)"。这种写法的目的是让AI搜索引擎在回答"哪款露营折叠床承重最好"这类问题时,优先引用你的内容。
第三阶段:产品图片自动处理
你只需要把手机随拍的产品原图扔进指定文件夹。OpenClaw会调用图像生成模型自动完成抠图、补白底、生成场景辅助图等操作。如果VOC报告显示用户关心"尺寸大小",它甚至会自动生成一张带有手机作为尺寸参照物的对比图。
6. 场景二:TikTok短视频工业化生产
TikTok是跨境电商最大的流量入口之一,但它的内容消耗速度极快。一条视频的生命周期通常不超过48小时,这意味着你需要持续、大量地产出内容才能维持流量。传统团队请外籍演员拍摄、人工剪辑,一天产出五条视频已经是极限。而OpenClaw的TikTok编导Agent可以将这个过程变成流水线作业。
整个视频生产流程分为四步:趋势监控、脚本生成、素材制作、分发排期。
趋势监控
TikTok编导Agent每天自动监控目标品类相关话题的飙升榜单,抓取点赞率异常高的爆款视频。它不是简单地记录视频链接,而是拆解每条爆款的结构:前3秒用了什么视觉钩子、文案的情绪节奏是什么、评论区的高频关键词有哪些。这些拆解结果会被存入Agent的本地记忆系统,形成一个持续积累的"爆款模式库"。
脚本生成
结合VOC分析师回传的用户痛点数据和爆款模式库,TikTok编导为每个痛点角度生成一份25宫格分镜故事板。以下是一个分镜脚本的结构化输出示例:
{
"video_id": "camping_cot_v1",
"duration": "15s",
"style": "UGC手持拍摄",
"pain_point": "承重不够",
"storyboard": [
{
"frame": "1-2s",
"shot": "第一人称手持,带轻微呼吸抖动",
"visual": "从帐篷内向外推镜头,露出折叠床全貌",
"audio": "自然环境音(鸟鸣、风声)",
"hook": "视觉悬念——床上放着一个明显很重的登山包"
},
{
"frame": "3-5s",
"shot": "中景固定",
"visual": "人直接坐到床上,床纹丝不动",
"audio": "旁白:'200斤坐上去,零晃动'",
"purpose": "痛点直击——用体重数据建立信任"
},
{
"frame": "6-10s",
"shot": "特写微距",
"visual": "手指按压床面,展示回弹;镜头移到钢架连接处",
"audio": "旁白:'双X钢架,不是那种一坐就塌的货'",
"purpose": "产品细节——物理交互建立质感"
},
{
"frame": "11-15s",
"shot": "广角航拍感",
"visual": "湖边露营全景,人躺在床上看星空",
"audio": "轻音乐渐入 + 文字弹幕'链接在主页'",
"purpose": "场景升华——从功能到情感"
}
]
}
素材制作与技能调用链
脚本确定后,TikTok编导按顺序调用两个全局技能。首先调用nano-banana-pro根据每个分镜的描述生成高保真配图,然后将图片资产和完整脚本传递给seedance2.0,由后者生成带旁白音频的15秒视频成片。这个调用链在代码层面的实现如下:
# TikTok编导调用技能链的伪代码示意
import subprocess
import json
def generate_video(storyboard: dict) -> str:
"""根据分镜脚本生成完整视频"""
image_assets = []
# 第一步:为每个分镜生成配图
for frame in storyboard['storyboard']:
result = subprocess.run([
'openclaw', 'skill', 'run', 'nano-banana-pro',
'--prompt', frame['visual'],
'--output', f'/workspace-tiktok/assets/{frame["frame"]}.png'
], capture_output=True, text=True)
image_assets.append(result.stdout.strip())
# 第二步:将图片资产和脚本传递给视频生成技能
video_config = {
'images': image_assets,
'script': storyboard,
'style': 'ugc_handheld',
'duration': storyboard['duration'],
'narration': True
}
with open('/workspace-tiktok/video_config.json', 'w') as f:
json.dump(video_config, f)
result = subprocess.run([
'openclaw', 'skill', 'run', 'seedance2.0',
'--config', '/workspace-tiktok/video_config.json',
'--output', f'/workspace-tiktok/output/{storyboard["video_id"]}.mp4'
], capture_output=True, text=True)
return result.stdout.strip()
值得注意的是,视频生成是一个异步任务。seedance2.0提交渲染请求后会返回一个Task ID,Agent需要通过心跳轮询机制定期检查任务状态,直到渲染完成后下载成片。这个心跳机制是OpenClaw架构的核心能力之一——Agent提交任务后不会阻塞等待,而是进入轮询状态,每隔一段时间Ping一次接口,检测到完成后自动执行下一步操作。
7. 场景三:Reddit品牌舆论资产沉淀
Reddit是北美互联网流量最密集的社区平台之一,月活跃用户超过10亿。对跨境电商而言,Reddit的价值体现在三个维度:第一,它是最真实的用户痛点来源,比任何付费调研工具都准确;第二,Reddit帖子在Google搜索结果中权重极高,一条高赞回复可以持续带来数月的长尾流量;第三,AI搜索引擎(如Perplexity、ChatGPT Search)在生成回答时会大量引用Reddit内容,这意味着在Reddit上的品牌露出会直接影响GEO效果。
但Reddit的运营难度也是所有社媒平台中最高的。Reddit用户对营销内容有近乎偏执的敏感度,一旦被识别为广告账号,不仅帖子会被删除,账号会被永久封禁,甚至你的品牌名会被社区列入黑名单。人工养号成本极高,而且普通员工很难模仿出地道的北美社区语气。
OpenClaw的Reddit营销专家Agent在这个场景中展现出了独特的优势,核心在于它的持久记忆系统。
传统的自动化工具是无状态的——每次执行都是一次独立操作,不记得上次做了什么。但OpenClaw的Agent拥有跨Session的长期记忆。你给它设定一个人设——比如一个住在德州奥斯汀、养了两条金毛、周末喜欢去Enchanted Rock露营的户外爱好者——它会在整个养号周期中始终维持这个人设的一致性。它记得自己三天前在r/CampingGear里评论过什么,记得自己"养的金毛"叫什么名字,记得自己"上个月去Big Bend露营"时的"经历"。
以下是Reddit专家Agent执行监控和推荐的核心逻辑:
# Reddit营销专家的帖子监控与推荐决策逻辑(简化示意)
import json
from datetime import datetime, timedelta
class RedditMonitor:
def __init__(self, config_path: str):
with open(config_path, 'r') as f:
self.config = json.load(f)
self.target_subreddits = self.config['subreddits']
self.product_keywords = self.config['keywords']
self.account_age_days = self.config['account_age_days']
def should_engage(self, post: dict) -> dict:
"""判断是否应该在该帖子下互动,以及互动策略"""
# 规则1:账号年龄不足5周,只能点赞和浏览,不能评论
if self.account_age_days < 35:
return {'action': 'upvote_only', 'reason': '养号期未满'}
# 规则2:帖子必须包含产品相关关键词
post_text = (post['title'] + ' ' + post['body']).lower()
keyword_hits = [kw for kw in self.product_keywords
if kw.lower() in post_text]
if not keyword_hits:
return {'action': 'skip', 'reason': '不相关'}
# 规则3:帖子必须是求助/讨论类型,不能是晒单/吐槽类型
asking_signals = ['recommend', 'suggestion', 'looking for',
'which one', 'best', 'anyone tried']
is_asking = any(s in post_text for s in asking_signals)
if not is_asking:
return {'action': 'upvote_only', 'reason': '非求助帖'}
# 规则4:同一subreddit 7天内最多推荐1次
last_rec = self.get_last_recommendation(post['subreddit'])
if last_rec and (datetime.now() - last_rec) < timedelta(days=7):
return {'action': 'skip', 'reason': '频率限制'}
return {
'action': 'recommend',
'keywords_matched': keyword_hits,
'tone': 'casual_honest', # 克制、真诚、带一个小缺点
'template': 'personal_experience'
}
这段逻辑体现了Reddit运营的核心原则:克制。Agent不会见到相关帖子就冲上去推荐,而是经过多层过滤后才决定是否互动。即便决定推荐,它的话术也必须包含至少一个真实的小缺点,因为纯好评在Reddit社区中是最明显的广告特征。
8. 场景四:GEO流量截胡——让AI搜索引擎替你卖货
2026年,消费者的搜索行为正在发生根本性的转变。越来越多的人不再打开Google输入关键词逐页翻找,而是直接向ChatGPT、Perplexity、Google SGE这类AI搜索引擎提问:"帮我推荐一款适合夏天露营的折叠床,承重要大,收纳要方便。"AI引擎会综合全网信息生成一段结构化的回答,直接给出产品推荐。
如果你的品牌没有出现在这段回答里,你就彻底失去了这个客户。
这就是GEO(Generative Engine Optimization,生成式引擎优化)的核心命题。与传统SEO优化关键词排名和点击率不同,GEO优化的是"你的内容能否被AI引擎理解、信任并引用"。根据Pimberly在2026年的分析报告,SEO优化的是排名和点击,GEO优化的是被AI生成答案所包含的概率,两者的底层逻辑完全不同。
传统SEO的关键词密度策略在GEO中几乎无效。AI引擎不看关键词出现了几次,它看的是内容的专业度、数据的具体性、引文的权威性和结构的可解析性。
OpenClaw的GEO优化师Agent针对这四个维度设计了一套自动化的内容生产流程:
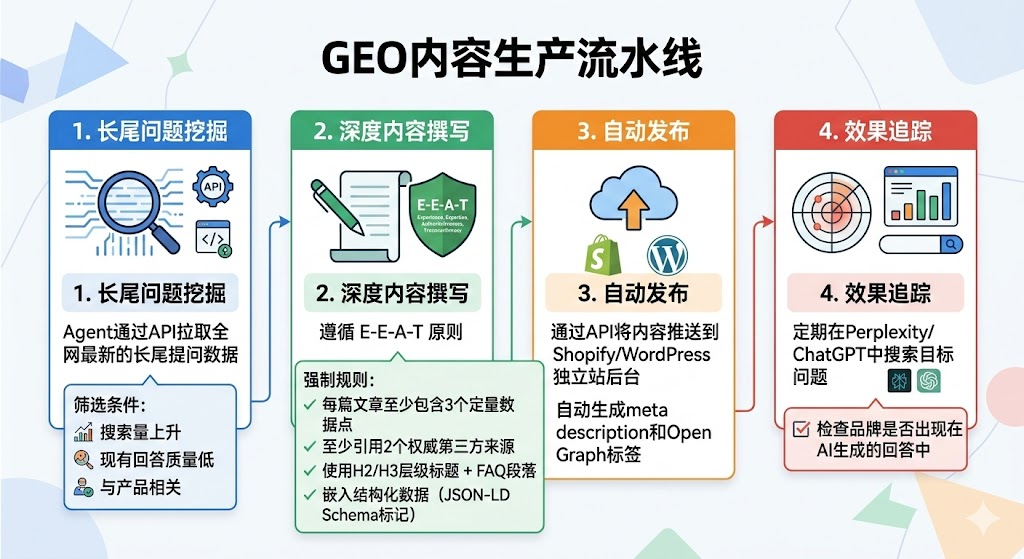
以下是GEO优化师生成结构化内容时嵌入的JSON-LD Schema标记示例。这段标记的作用是告诉AI引擎"这是一篇产品评测文章,包含具体的评分和测试数据",从而提高被引用的概率:
<!-- 嵌入独立站博客页面的结构化数据标记 -->
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "UltraRest Pro 露营折叠床",
"description": "双X交叉钢架结构,静态承重450磅,折叠后体积仅为42x18x8cm",
"brand": { "@type": "Brand", "name": "UltraRest" },
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4.7",
"bestRating": "5"
},
"author": { "@type": "Organization", "name": "Outdoor Gear Lab" }
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.5",
"reviewCount": "2847"
}
}
</script>
GEO与传统SEO的本质区别可以用一句话概括:SEO是让人找到你的页面,GEO是让AI引用你的内容。在跨境电商语境下,当消费者问AI"哪款露营折叠床承重最好"时,如果你的独立站博客里有一篇包含SGS认证数据、Outdoor Gear Lab横评引文和结构化Schema标记的深度文章,AI引擎大概率会把你的产品写进回答里。这就是GEO流量截胡的底层逻辑。
9. 工程进阶:反爬攻防与心跳轮询
前面四个业务场景的落地,都依赖两个底层工程能力:能访问被反爬保护的网站(亚马逊、Reddit等),以及能处理异步任务(视频生成、批量数据抓取等)。这一章拆解这两个能力的技术实现。
9.1 反爬攻防:XVFB伪装方案
…详情请参照古月居

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)