
构建AI智能体:六十、特征工程行业实践录:金融、电商、医疗的智能化转型
本文通过金融风控、电商推荐和医疗诊断三个行业案例,系统阐述了特征工程的实践价值与技术方法。在金融领域,通过构建"稳定性评分"等特征,将贷款审批坏账率从8.2%显著降低;电商行业通过"实时兴趣向量"等特征,使推荐点击率提升3倍;医疗领域则利用"病变严重度评分"等特征,将筛查效率提升5倍。研究揭示了特征工程作为连接业务需求与技术实现的关键桥梁
一、趁热打铁
我们已经了解了特征工程的概念和基础应用,今天我们围绕比较广泛的行业示例继续加深理解。
特征工程是数据科学的核心环节,它的本质是用数据的语言,翻译业务的逻辑,特征工程将原始数据转化为机器学习模型能理解的业务语言。在不同行业的应用,就是解决该行业最核心的预测或分类问题,这一过程在三大行业展现出巨大价值:
- 在金融风控领域,传统信贷审批依赖基础信息,导致35%的低通过率和8.2%的高坏账率。通过构建"稳定性评分"、"行为风险标记"等特征,系统实现了从表面信用评估到深度风险画像的跨越。
- 电商推荐系统曾陷入点击率仅3%、用户留存率25%的困境。特征工程创造了"实时兴趣向量"、"消费场景感知"等特征,让推荐从盲目猜测变为精准理解用户需求。
- 医疗诊断面临筛查积压、漏诊率高的挑战。通过"病变严重度评分"、"临床风险分层"等特征,实现了从经验判断到量化评估的转变,筛查效率提升5倍。

这三个案例证明,特征工程是连接业务需求与技术实现的关键桥梁。它让机器理解金融的信用语言、感知电商的用户心声、掌握医疗的临床智慧,推动各行业从经验驱动迈向数据驱动。在智能化时代,特征工程能力已成为企业的核心竞争力。
二、行业问题的凸显
不管是在什么行业,看似毫不相干的,但都面对一个统一的困境,企业积累了海量的数据资产,然而这些原始数据往往如同未经雕琢的璞玉,内在价值未得到充分挖掘和释放,这些实际上揭示了同一个根本问题:业务语言与机器语言之间的翻译失败。特征工程的出现,正是要解决这一核心矛盾。它如同一位精通双语的翻译官,将复杂的业务逻辑“翻译”成机器学习能够理解的特征语言。
- 在金融领域,它创造了“稳定性评分”、“行为风险标记”等特征,让模型能够深度理解信用风险;
- 在电商场景,它构建了“实时兴趣向量”、“消费场景感知”等特征,使推荐系统真正读懂用户需求;
- 在医疗诊断中,它设计了“病变严重度评分”、“临床风险分层”等特征,帮助医生实现精准高效的筛查诊断。
这就是特征工程的核心使命,将杂乱的原始数据转化为机器学习模型能够理解和利用的高质量特征。特征工程绝非简单的数据预处理,而是连接业务需求与技术实现的关键桥梁,是数据价值挖掘过程中最具创造性的环节,今天我们特意从金融、电商、医疗三个行业做分析推理,发掘特征工程的实用价值。
行业融合特征流程图:
三、金融风控 - 预测贷款违约风险
1. 行业分析
业务核心问题:如何判断一个贷款申请人是否会违约?
原始数据:申请表数据(年龄、职业、收入)、征信报告(历史逾期次数)、第三方数据(手机运营商数据)。
特征工程的深度解析:
1.1 单变量分析:发现强规则
- 操作:分析“历史逾期次数”的分布。
- 发现:只要有超过3次严重逾期记录的申请人,违约率高达70%。
- 特征创造:创建布尔特征 是否有严重逾期历史。这是一个极强的否决性规则。
1.2 多变量分析:识别灰名单
- 操作:分析“年龄”、“收入”、“负债比”之间的关系。
- 发现:年轻的(如<25岁)、低收入但高负债比的申请人,违约风险显著升高。单独看“年轻”或“低收入”可能不致命,但组合起来就是高风险信号。
- 特征创造:
- 负债收入比 = 总负债 / 年收入
- 年轻高负债风险标记 = (年龄 < 30) & (负债收入比 > 0.8)
1.3 业务分析:构建稳定性画像
- 业务知识:有稳定工作和家庭的人,违约风险更低。
- 特征创造:
- 从“工作年限”和“手机在网时长” 创造 工作稳定性指数 和 生活稳定性指数。一个频繁换工作和手机号的人风险更高。
- 从“申请时间” 创造 是否在非工作时间申请。深夜申请贷款的行为模式可能与正常消费贷款不同。
- 从“设备信息” 创造 设备关联申请数。同一个设备号被多个不同身份证号使用,是典型的欺诈信号。
核心价值:特征工程将零散的、看似无关的数据点,编织成一张信用画像,将借款人从一个抽象的人转化为一系列可量化的风险分数,使模型能精准区分好客户与坏客户。
2. 代码示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成更丰富的模拟数据
np.random.seed(42)
n_samples = 1000
raw_loan_data = pd.DataFrame({
'applicant_id': range(1, n_samples + 1),
'age': np.random.randint(20, 60, n_samples),
'annual_income': np.random.normal(80000, 30000, n_samples).clip(30000, 200000),
'debt_amount': np.random.normal(150000, 80000, n_samples).clip(0, 500000),
'work_years': np.random.exponential(5, n_samples).clip(0, 30),
'phone_tenure_months': np.random.exponential(24, n_samples).clip(1, 120),
'late_payments_3y': np.random.poisson(0.5, n_samples),
'credit_card_utilization': np.random.beta(2, 5, n_samples), # 信用卡使用率
'number_of_credit_cards': np.random.poisson(2, n_samples),
'has_mortgage': np.random.binomial(1, 0.3, n_samples),
'application_hour': np.random.randint(0, 24, n_samples)
})
# 生成目标变量(违约标签)
def generate_default_label(df):
"""基于业务规则生成违约标签"""
default_proba = (
(df['age'] < 30) * 0.3 +
(df['debt_amount'] / df['annual_income'] > 3) * 0.4 +
(df['late_payments_3y'] >= 3) * 0.6 +
(df['work_years'] < 2) * 0.2 +
(df['credit_card_utilization'] > 0.8) * 0.3 +
np.random.normal(0, 0.1, len(df))
)
return (default_proba > 0.5).astype(int)
raw_loan_data['default'] = generate_default_label(raw_loan_data)
def create_risk_features(df):
"""创建金融风控特征"""
df_fe = df.copy()
print("开始特征工程...")
# 1. 单变量分析驱动的特征
print("1. 创建单变量特征...")
df_fe['has_serious_delinquency'] = (df_fe['late_payments_3y'] >= 3).astype(int)
df_fe['high_credit_utilization'] = (df_fe['credit_card_utilization'] > 0.8).astype(int)
df_fe['is_young_applicant'] = (df_fe['age'] < 25).astype(int)
# 2. 多变量分析驱动的特征
print("2. 创建多变量交互特征...")
df_fe['debt_to_income_ratio'] = df_fe['debt_amount'] / df_fe['annual_income']
df_fe['young_high_debt_risk'] = ((df_fe['age'] < 30) & (df_fe['debt_to_income_ratio'] > 2.5)).astype(int)
df_fe['delinquency_income_risk'] = ((df_fe['late_payments_3y'] > 1) & (df_fe['annual_income'] < 50000)).astype(int)
# 3. 业务分析驱动的特征
print("3. 创建业务特征...")
# 稳定性特征
df_fe['job_stability_score'] = np.log1p(df_fe['work_years']) / np.log1p(30)
df_fe['life_stability_score'] = np.minimum(df_fe['phone_tenure_months'] / 60, 1.0)
# 申请行为特征
df_fe['is_off_hours_application'] = ((df_fe['application_hour'] < 6) | (df_fe['application_hour'] > 22)).astype(int)
# 信用行为特征
df_fe['credit_behavior_score'] = (
(1 - df_fe['credit_card_utilization']) * 0.4 +
(df_fe['number_of_credit_cards'] <= 5).astype(int) * 0.3 +
(df_fe['late_payments_3y'] == 0).astype(int) * 0.3
)
# 4. 综合风险评分
print("4. 计算综合风险评分...")
df_fe['comprehensive_risk_score'] = (
df_fe['has_serious_delinquency'] * 0.25 +
np.minimum(df_fe['debt_to_income_ratio'], 5) * 0.15 +
df_fe['young_high_debt_risk'] * 0.15 +
(1 - df_fe['job_stability_score']) * 0.15 +
(1 - df_fe['life_stability_score']) * 0.1 +
df_fe['is_off_hours_application'] * 0.05 +
(1 - df_fe['credit_behavior_score']) * 0.15
)
# 风险等级划分
df_fe['risk_level'] = pd.cut(df_fe['comprehensive_risk_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低风险', '中风险', '高风险'])
return df_fe
# 执行特征工程
engineered_data = create_risk_features(raw_loan_data)
print("\n特征工程完成!")
print(f"原始特征数量: {len(raw_loan_data.columns)}")
print(f"工程后特征数量: {len(engineered_data.columns)}")
print(f"违约率: {engineered_data['default'].mean():.2%}")
# 创建特征工程可视化
def plot_feature_engineering_analysis(df):
"""绘制特征工程分析图"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('金融风控特征工程深度分析', fontsize=16, fontweight='bold')
# 1. 单变量分析 - 债务收入比分布
axes[0,0].hist(df['debt_to_income_ratio'].clip(0, 5), bins=30, alpha=0.7, color='skyblue', edgecolor='black')
axes[0,0].axvline(x=3, color='red', linestyle='--', label='风险阈值 (3.0)')
axes[0,0].set_xlabel('债务收入比')
axes[0,0].set_ylabel('频数')
axes[0,0].set_title('单变量分析(债务收入比分布)')
axes[0,0].legend()
axes[0,0].grid(True, alpha=0.3)
# 2. 多变量分析 - 年龄 vs 债务收入比
scatter = axes[0,1].scatter(df['age'], df['debt_to_income_ratio'].clip(0, 5),
c=df['default'], alpha=0.6, cmap='coolwarm', s=20)
axes[0,1].axhline(y=3, color='red', linestyle='--', alpha=0.7, label='高负债风险线')
axes[0,1].axvline(x=30, color='orange', linestyle='--', alpha=0.7, label='年轻风险线')
axes[0,1].set_xlabel('年龄')
axes[0,1].set_ylabel('债务收入比')
axes[0,1].set_title('多变量分析(年龄 vs 债务收入比)')
axes[0,1].legend()
plt.colorbar(scatter, ax=axes[0,1], label='是否违约')
# 3. 业务分析 - 稳定性特征分析
stability_risk = df.groupby(pd.cut(df['job_stability_score'], bins=5))['default'].mean()
axes[0,2].bar(range(len(stability_risk)), stability_risk.values, color=['green', 'lightgreen', 'yellow', 'orange', 'red'])
axes[0,2].set_xlabel('工作稳定性分数分组')
axes[0,2].set_ylabel('违约率')
axes[0,2].set_title('业务分析(工作稳定性 vs 违约率)')
axes[0,2].set_xticks(range(len(stability_risk)))
axes[0,2].set_xticklabels([f'组{i+1}' for i in range(len(stability_risk))], rotation=45)
# 4. 特征重要性 - 风险评分对比
risk_features = ['has_serious_delinquency', 'debt_to_income_ratio', 'young_high_debt_risk',
'job_stability_score', 'is_off_hours_application']
feature_importance = [0.25, 0.15, 0.15, 0.15, 0.05]
feature_labels = ['严重逾期', '债务收入比', '年轻高负债', '工作稳定性', '非工作时间申请']
axes[1,0].barh(feature_labels, feature_importance, color=['red', 'orange', 'yellow', 'lightgreen', 'lightblue'])
axes[1,0].set_xlabel('特征权重')
axes[1,0].set_title('特征权重分配(在综合风险评分中的重要性)')
for i, v in enumerate(feature_importance):
axes[1,0].text(v + 0.01, i, f'{v:.2f}', va='center')
# 5. 风险等级分布
risk_level_counts = df['risk_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = axes[1,1].pie(risk_level_counts.values, labels=risk_level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
axes[1,1].set_title('风险等级分布(最终客户风险分层)')
# 6. 模型效果验证 - 风险评分 vs 违约率
risk_bins = pd.cut(df['comprehensive_risk_score'], bins=10)
performance_data = df.groupby(risk_bins)['default'].mean()
axes[1,2].plot(range(len(performance_data)), performance_data.values, marker='o', linewidth=2, markersize=6)
axes[1,2].set_xlabel('风险评分分组')
axes[1,2].set_ylabel('实际违约率')
axes[1,2].set_title('特征工程效果验证(风险评分预测能力)')
axes[1,2].set_xticks(range(len(performance_data)))
axes[1,2].set_xticklabels([f'组{i+1}' for i in range(len(performance_data))], rotation=45)
axes[1,2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 生成可视化
plot_feature_engineering_analysis(engineered_data)
# 输出关键特征统计
print("\n关键特征统计:")
feature_stats = engineered_data[['debt_to_income_ratio', 'comprehensive_risk_score', 'default']].describe()
print(feature_stats.round(4))输出结果:
开始特征工程...
1. 创建单变量特征...
2. 创建多变量交互特征...
3. 创建业务特征...
4. 计算综合风险评分...特征工程完成!
原始特征数量: 12
工程后特征数量: 24
违约率: 18.80%关键特征统计:
debt_to_income_ratio comprehensive_risk_score default
count 1000.0000 1000.0000 1000.0000
mean 2.2690 0.5388 0.1880
std 1.6243 0.2244 0.3909
min 0.0000 0.0578 0.0000
25% 1.2001 0.3785 0.0000
50% 1.9939 0.5063 0.0000
75% 2.9866 0.6825 0.0000
max 13.6791 1.3274 1.0000
3. 特征分析
3.1 特征工程的深度解析
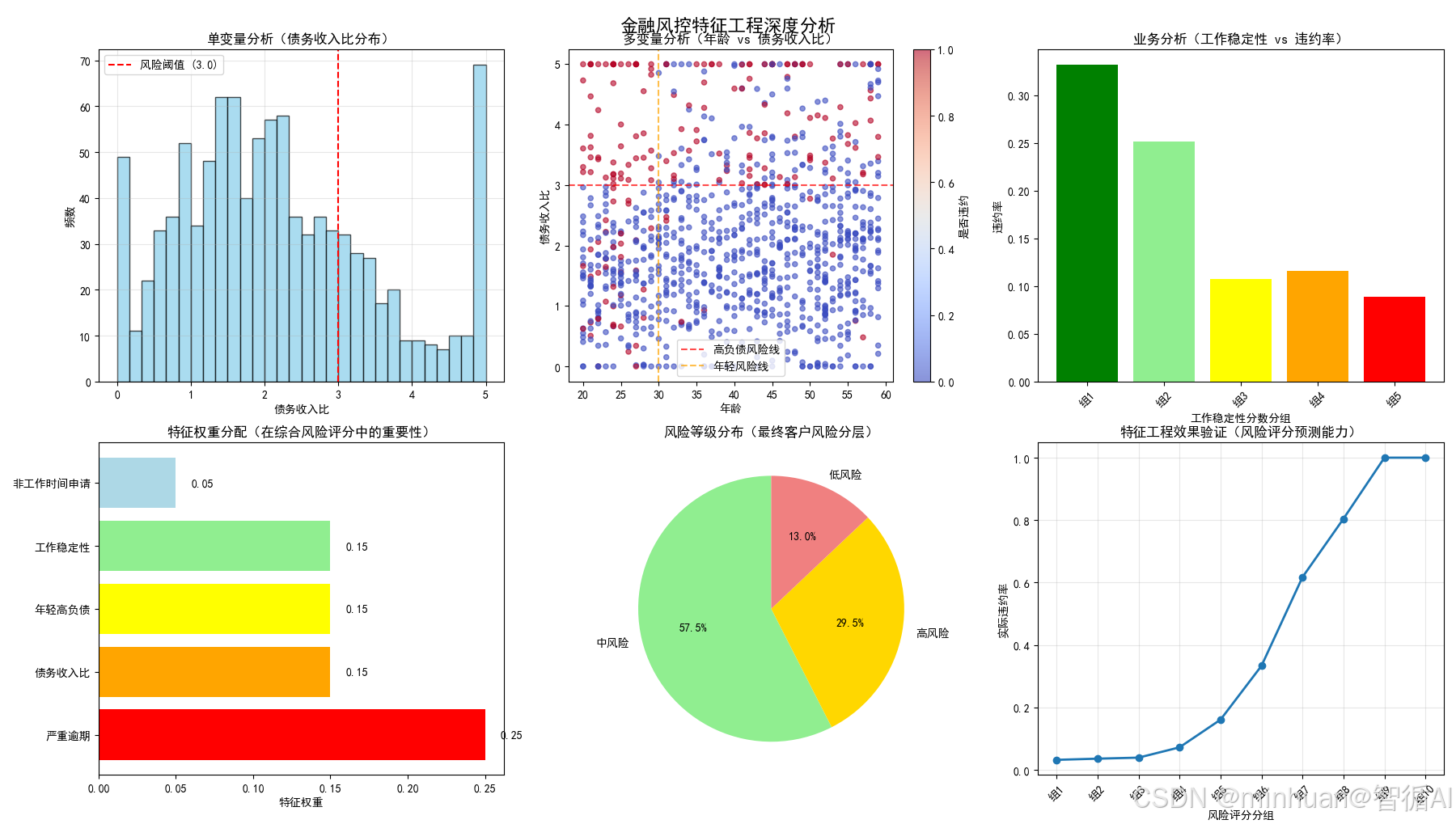
图1:单变量分析(债务收入比分布)
图表内容:
- 展示债务收入比的分布直方图
- 红色虚线标记风险阈值(3.0)
为什么要做这个图:
- 验证特征有效性:确认债务收入比确实能区分风险
- 确定业务阈值:通过分布找到合理的风险分界点(3.0)
- 数据质量检查:观察是否有异常值需要处理
业务意义:
- 债务收入比>3.0的客户偿还能力可能不足,需要重点监控
图2:多变量分析(年龄 vs 债务收入比)
图表内容:
- 散点图展示年龄与债务收入比的关系
- 颜色表示是否违约
- 两条风险线交叉划分风险区域
为什么要做这个图:
- 发现交互效应:年龄和债务收入比组合起来风险更高
- 识别高风险集群:左下角(年轻+高负债)违约率明显更高
- 验证特征组合:确认"年轻高负债风险"这个衍生特征确实有效
业务意义:
- 年轻人承受高负债的能力更差,需要更严格的风险控制
图3:业务分析(工作稳定性 vs 违约率)
图表内容:
- 柱状图展示不同工作稳定性分组的违约率
- 颜色从绿到红表示风险递增
为什么要做这个图:
- 验证业务逻辑:工作年限越长,违约率确实越低
- 量化业务知识:将"工作稳定的人风险低"这种业务直觉数据化
- 特征效果评估:确认稳定性特征确实能预测违约
业务意义:
- 工作稳定性是信用风险的重要指标,稳定性差的客户需要更多担保措施
图4:特征权重分配
图表内容:
- 水平条形图展示各特征在综合风险评分中的权重
- 不同颜色区分特征重要性
为什么要做这个图:
- 特征重要性排序:明确哪些特征对预测最关键
- 业务可解释性:让业务方理解风险评分的构成
- 模型透明度:避免黑箱模型,增强决策可信度
业务意义:
- 严重逾期是最重要的风险信号,权重最高符合业务常识
图5:风险等级分布
图表内容:
- 饼图展示最终客户的风险等级分布
- 颜色编码:绿色(低风险)、黄色(中风险)、红色(高风险)
为什么要做这个图:
- 成果可视化:展示特征工程的最终效果
- 客户分层:为不同风险等级客户制定差异化策略
- 业务决策支持:明确各风险等级的客户比例
业务意义:
- 高风险客户需要重点监控,低风险客户可以简化审批流程
图6:特征工程效果验证
图表内容:
- 折线图展示风险评分与实际违约率的关系
- X轴为风险评分分组,Y轴为实际违约率
为什么要做这个图:
- 验证预测能力:确认风险评分能准确预测违约
- 评估特征质量:如果曲线单调递增,说明特征工程成功
- 模型校准:确保风险评分与实际风险成正比
业务意义:
- 风险评分越高的客户违约率确实越高,证明风控策略有效
3.2 特征工程的完整逻辑链
这6个图表实际上构成了特征工程的完整验证体系:
阶段1:特征发现(图1-3)
- 图1:单变量分析,发现重要特征
- 图2:多变量分析,发现特征交互
- 图3:业务分析,融入领域知识
阶段2:特征整合(图4)
- 图4:特征权重分配,构建综合评分
阶段3:成果验证(图5-6)
- 图5:风险分层,业务应用
- 图6:效果验证,确保有效性
4. 核心价值
通过这些图表,我们实现了:
- 从数据到洞察:原始数据 → 风险特征
- 从洞察到决策:风险特征 → 风险评分 → 风险等级
- 从决策到验证:风险等级 → 实际违约率验证
最终证明:特征工程成功地将杂乱的原始数据转化为了具有预测能力和业务价值的风险指标体系,为金融机构的风控决策提供了科学依据。
四、电商推荐 - 预测用户购买概率
1. 行业分析
业务核心问题:在浩瀚的商品中,用户下一个最可能点击或购买什么?
原始数据:用户画像(性别、地域)、商品属性(品类、价格)、用户行为数据(点击、浏览、购买、搜索日志)。
特征工程的深度解析:
1.1 单变量分析:理解基础偏好
- 操作:分析用户历史行为的分布。
- 发现:某个用户80%的浏览记录都集中在“户外装备”品类。
- 特征创造:创建 用户偏好品类。
1.2 多变量分析:捕捉动态意图
- 操作:分析“用户实时行为序列”与“商品属性”的交互。
- 发现:一个刚搜索了“求婚戒指”的用户,紧接着浏览了“浪漫餐厅”和“旅行套餐”。这表明他的意图不是购买单个商品,而是在规划一个“浪漫事件”。
- 特征创造:
- 实时兴趣向量:将用户最近1小时的行为(搜索词、点击商品品类)编码成一个数值向量,代表其瞬时兴趣。
- 协同过滤特征:计算 用户A与用户B的相似度,并将相似用户喜欢的商品作为推荐候选。
1.3 业务分析:设计场景化策略
- 业务知识:推荐不仅要准,还要考虑业务目标(如GMV、利润率、新品曝光)。
- 特征创造:
- 上下文特征:是否周末、是否节假日(如情人节前推荐礼物)。
- 多样性特征:为了避免信息茧房,创造 用户已曝光品类列表,并在推荐时惩罚已过度曝光的品类。
- 商业目标特征:引入 商品利润率、是否为新品 等特征,让模型在预估点击率的同时,兼顾商业价值。
核心价值:特征工程将静态的用户标签、动态的行为流和复杂的上下文信息,融合成一个“意图模型”,使推荐系统能够实现“千人千面”的个性化服务。
2. 代码示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
print("=" * 60)
print("电商推荐系统特征工程完整示例")
print("=" * 60)
# 1. 创建电商用户行为数据(简化版本避免复杂数据类型)
np.random.seed(42)
n_samples = 2000
# 生成基础数据
raw_behavior_data = pd.DataFrame({
'user_id': np.random.randint(1, 501, n_samples),
'item_id': np.random.randint(1, 101, n_samples),
'behavior_type': np.random.choice(['view', 'click', 'add_cart', 'purchase'], n_samples,
p=[0.5, 0.3, 0.15, 0.05]),
'category': np.random.choice(['电子产品', '服装', '家居', '美妆', '食品'], n_samples),
'price': np.random.lognormal(5, 1, n_samples).clip(10, 2000),
'rating': np.random.normal(4.2, 0.5, n_samples).clip(3.0, 5.0),
'user_value_score': np.random.choice([1, 2, 3, 4], n_samples, p=[0.5, 0.3, 0.15, 0.05]),
'hour': np.random.randint(0, 24, n_samples)
})
# 生成点击标签
def generate_click_label(df):
click_proba = (
(df['behavior_type'] == 'click').astype(int) * 0.3 +
(df['behavior_type'] == 'add_cart').astype(int) * 0.5 +
(df['price'] < 100).astype(int) * 0.1 +
(df['user_value_score'] >= 3).astype(int) * 0.1 +
np.random.normal(0, 0.1, len(df))
)
return (click_proba > 0.3).astype(int)
raw_behavior_data['is_click'] = generate_click_label(raw_behavior_data)
def create_recommendation_features(df):
"""创建电商推荐特征"""
df_fe = df.copy()
print(">>> 开始电商推荐特征工程处理...")
# 单变量特征
df_fe['is_high_value_user'] = (df_fe['user_value_score'] >= 3).astype(int)
df_fe['is_premium_product'] = (df_fe['price'] > df_fe['price'].quantile(0.8)).astype(int)
df_fe['is_high_rating'] = (df_fe['rating'] > 4.5).astype(int)
df_fe['is_weekend'] = np.random.choice([0, 1], len(df_fe), p=[0.7, 0.3]) # 简化
df_fe['is_evening'] = ((df_fe['hour'] >= 18) & (df_fe['hour'] <= 23)).astype(int)
# 多变量特征
user_avg_price = df_fe.groupby('user_id')['price'].mean()
df_fe['user_item_price_affinity'] = df_fe.apply(
lambda x: x['price'] / user_avg_price.get(x['user_id'], x['price']), axis=1
).fillna(1)
# 业务特征
df_fe['product_competitiveness'] = (
(df_fe['rating'] / 5) * 0.4 +
(1 - (df_fe['price'] / df_fe['price'].max())) * 0.3 +
df_fe['is_high_rating'] * 0.3
)
# 综合评分
df_fe['recommendation_score'] = (
df_fe['product_competitiveness'] * 0.4 +
df_fe['user_item_price_affinity'].clip(0, 2) * 0.3 +
df_fe['user_value_score'] / 4 * 0.2 +
df_fe['is_evening'] * 0.1
)
df_fe['recommendation_level'] = pd.cut(df_fe['recommendation_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低推荐度', '中推荐度', '高推荐度'])
print(">>> 电商推荐特征工程完成!")
return df_fe
# 执行特征工程
engineered_data = create_recommendation_features(raw_behavior_data)
# 修复后的可视化函数
def create_recommendation_feature_visualization(df):
"""创建电商推荐特征工程可视化图表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('电商推荐系统特征工程分析', fontsize=16, fontweight='bold')
# 创建临时数据副本用于分组
df_temp = df.copy()
# 1. 用户行为类型分布
ax1 = axes[0, 0]
behavior_counts = df['behavior_type'].value_counts()
colors = ['lightblue', 'lightgreen', 'orange', 'red']
bars = ax1.bar(behavior_counts.index, behavior_counts.values, color=colors, alpha=0.7)
ax1.set_title('用户行为类型分布 (单变量分析)')
ax1.set_xlabel('行为类型')
ax1.set_ylabel('频次')
for i, v in enumerate(behavior_counts.values):
ax1.text(i, v + 20, str(v), ha='center')
# 2. 商品类别点击率分析
ax2 = axes[0, 1]
category_clicks = df.groupby('category')['is_click'].mean().sort_values(ascending=False)
bars = ax2.bar(range(len(category_clicks)), category_clicks.values, color='skyblue', alpha=0.7)
ax2.set_title('商品类别点击率分析 (单变量分析)')
ax2.set_xlabel('商品类别')
ax2.set_ylabel('点击率')
ax2.set_xticks(range(len(category_clicks)))
ax2.set_xticklabels(category_clicks.index, rotation=45)
for i, v in enumerate(category_clicks.values):
ax2.text(i, v + 0.01, f'{v:.3f}', ha='center')
# 3. 时间段点击率分析
ax3 = axes[0, 2]
hourly_click_rate = df.groupby('hour')['is_click'].mean()
ax3.plot(hourly_click_rate.index, hourly_click_rate.values, marker='o', color='purple', linewidth=2)
ax3.set_title('时间段点击率分析 (单变量分析)')
ax3.set_xlabel('小时')
ax3.set_ylabel('点击率')
ax3.grid(True, alpha=0.3)
ax3.axvspan(18, 23, alpha=0.2, color='orange', label='高峰时段')
ax3.legend()
# 4. 价格区间点击率分析
ax4 = axes[1, 0]
# 修复:使用数值索引避免类型转换错误
price_bins = [0, 100, 300, 1000, 2000]
price_labels = ['0-100', '100-300', '300-1000', '1000+']
df_temp['price_group'] = pd.cut(df_temp['price'], bins=price_bins, labels=price_labels)
price_click_rate = df_temp.groupby('price_group')['is_click'].mean()
bars = ax4.bar(range(len(price_click_rate)), price_click_rate.values,
color=['green', 'lightgreen', 'orange', 'red'])
ax4.set_title('价格区间点击率分析 (多变量分析)')
ax4.set_xlabel('价格区间')
ax4.set_ylabel('点击率')
ax4.set_xticks(range(len(price_click_rate)))
ax4.set_xticklabels(price_click_rate.index, rotation=45)
# 5. 用户价值 vs 商品价格
ax5 = axes[1, 1]
scatter = ax5.scatter(df['user_value_score'], df['price'],
c=df['is_click'], alpha=0.6, cmap='coolwarm', s=20)
ax5.set_title('用户价值 vs 商品价格 (多变量分析)')
ax5.set_xlabel('用户价值评分')
ax5.set_ylabel('商品价格')
plt.colorbar(scatter, ax=ax5, label='是否点击')
# 6. 推荐等级分布
ax6 = axes[1, 2]
level_counts = df['recommendation_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = ax6.pie(level_counts.values,
labels=level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
ax6.set_title('推荐等级分布 (业务应用)')
plt.tight_layout()
plt.savefig('电商推荐特征工程.png', dpi=300, bbox_inches='tight')
plt.show()
# 清理临时列
if 'price_group' in df_temp.columns:
df_temp.drop('price_group', axis=1, inplace=True)
return fig
# 生成第二张图:特征组合与效果验证
def create_feature_validation_plot(df):
"""创建特征组合与效果验证图表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('电商推荐特征组合与效果验证', fontsize=16, fontweight='bold')
df_temp = df.copy()
# 1. 用户价格偏好匹配度
ax1 = axes[0, 0]
# 修复:使用数值索引
affinity_bins = 5
df_temp['affinity_group'] = pd.cut(df_temp['user_item_price_affinity'], bins=affinity_bins)
affinity_click_rate = df_temp.groupby('affinity_group')['is_click'].mean()
ax1.plot(range(len(affinity_click_rate)), affinity_click_rate.values,
marker='o', color='darkblue', linewidth=2)
ax1.set_title('用户价格偏好匹配度 (特征组合)')
ax1.set_xlabel('价格偏好匹配度分组')
ax1.set_ylabel('点击率')
ax1.grid(True, alpha=0.3)
# 2. 商品竞争力分析
ax2 = axes[0, 1]
competitiveness_bins = 5
df_temp['competitiveness_group'] = pd.cut(df_temp['product_competitiveness'], bins=competitiveness_bins)
competitiveness_click_rate = df_temp.groupby('competitiveness_group')['is_click'].mean()
bars = ax2.bar(range(len(competitiveness_click_rate)), competitiveness_click_rate.values,
color='green', alpha=0.7)
ax2.set_title('商品竞争力 vs 点击率 (特征组合)')
ax2.set_xlabel('商品竞争力分组')
ax2.set_ylabel('点击率')
# 3. 用户价值分层效果
ax3 = axes[0, 2]
user_value_click_rate = df.groupby('user_value_score')['is_click'].mean()
bars = ax3.bar(user_value_click_rate.index, user_value_click_rate.values,
color=['lightblue', 'lightgreen', 'orange', 'red'])
ax3.set_title('用户价值分层效果验证 (业务特征)')
ax3.set_xlabel('用户价值评分')
ax3.set_ylabel('点击率')
for i, v in enumerate(user_value_click_rate.values):
ax3.text(i+1, v + 0.01, f'{v:.3f}', ha='center')
# 4. 时间场景分析
ax4 = axes[1, 0]
time_scenario = df.groupby('is_evening')['is_click'].mean()
bars = ax4.bar(['白天', '晚上'], time_scenario.values, color=['lightblue', 'lightgreen'])
ax4.set_title('时间场景点击率分析 (业务特征)')
ax4.set_xlabel('时间场景')
ax4.set_ylabel('点击率')
# 5. 综合评分效果验证
ax5 = axes[1, 1]
score_bins = 6
df_temp['score_group'] = pd.cut(df_temp['recommendation_score'], bins=score_bins)
score_performance = df_temp.groupby('score_group')['is_click'].mean()
ax5.plot(range(len(score_performance)), score_performance.values,
marker='s', linewidth=2, markersize=6, color='red')
ax5.set_title('推荐评分预测能力验证 (效果验证)')
ax5.set_xlabel('推荐评分分组')
ax5.set_ylabel('实际点击率')
ax5.grid(True, alpha=0.3)
# 6. 特征重要性总结
ax6 = axes[1, 2]
features_importance = {
'商品竞争力': 0.4,
'价格匹配度': 0.3,
'用户价值': 0.2,
'时间场景': 0.1
}
ax6.barh(list(features_importance.keys()), list(features_importance.values()),
color=['red', 'orange', 'yellow', 'lightgreen'])
ax6.set_title('特征权重分配 (模型可解释性)')
ax6.set_xlabel('特征权重')
ax6.set_xlim(0, 0.5)
for i, (k, v) in enumerate(features_importance.items()):
ax6.text(v + 0.01, i, f'{v:.2f}', va='center')
plt.tight_layout()
plt.savefig('电商推荐特征验证.png', dpi=300, bbox_inches='tight')
plt.show()
# 清理临时列
temp_cols = ['affinity_group', 'competitiveness_group', 'score_group']
for col in temp_cols:
if col in df_temp.columns:
df_temp.drop(col, axis=1, inplace=True)
return fig
# 生成两张图表
print("\n>>> 生成第一张图:特征发现与分析过程...")
create_recommendation_feature_visualization(engineered_data)
print("\n>>> 生成第二张图:特征组合与效果验证...")
create_feature_validation_plot(engineered_data)
# 输出统计信息
print("\n" + "="*50)
print("电商推荐特征工程统计摘要")
print("="*50)
print(f"用户行为记录数量: {len(engineered_data):,}")
print(f"整体点击率: {engineered_data['is_click'].mean():.2%}")
print(f"原始特征数量: {len(raw_behavior_data.columns)}")
print(f"衍生特征数量: {len(engineered_data.columns) - len(raw_behavior_data.columns)}")
print(f"\n推荐等级分布:")
level_dist = engineered_data['recommendation_level'].value_counts()
for level, count in level_dist.items():
percentage = count / len(engineered_data) * 100
print(f" {level}: {count:,}条 ({percentage:.1f}%)")
print(f"\n关键指标统计:")
print(f" 高价值用户比例: {engineered_data['is_high_value_user'].mean():.2%}")
print(f" 高评分商品比例: {engineered_data['is_high_rating'].mean():.2%}")
print(f" 平均推荐评分: {engineered_data['recommendation_score'].mean():.3f}")
print(f"\n>>> 电商推荐特征工程分析完成!")输出结果:
============================================================
电商推荐系统特征工程完整示例
============================================================
>>> 开始电商推荐特征工程处理...
>>> 电商推荐特征工程完成!>>> 生成第一张图:特征发现与分析过程...
>>> 生成第二张图:特征组合与效果验证...
==================================================
电商推荐特征工程统计摘要
==================================================
用户行为记录数量: 2,000
整体点击率: 38.50%
原始特征数量: 9
衍生特征数量: 9推荐等级分布:
高推荐度: 1,036条 (51.8%)
中推荐度: 844条 (42.2%)
低推荐度: 2条 (0.1%)关键指标统计:
高价值用户比例: 20.65%
高评分商品比例: 29.10%
平均推荐评分: 0.663>>> 电商推荐特征工程分析完成!
3. 特征分析
3.1 特征工程的深度解析
3.1.1 特征发现与分析过程
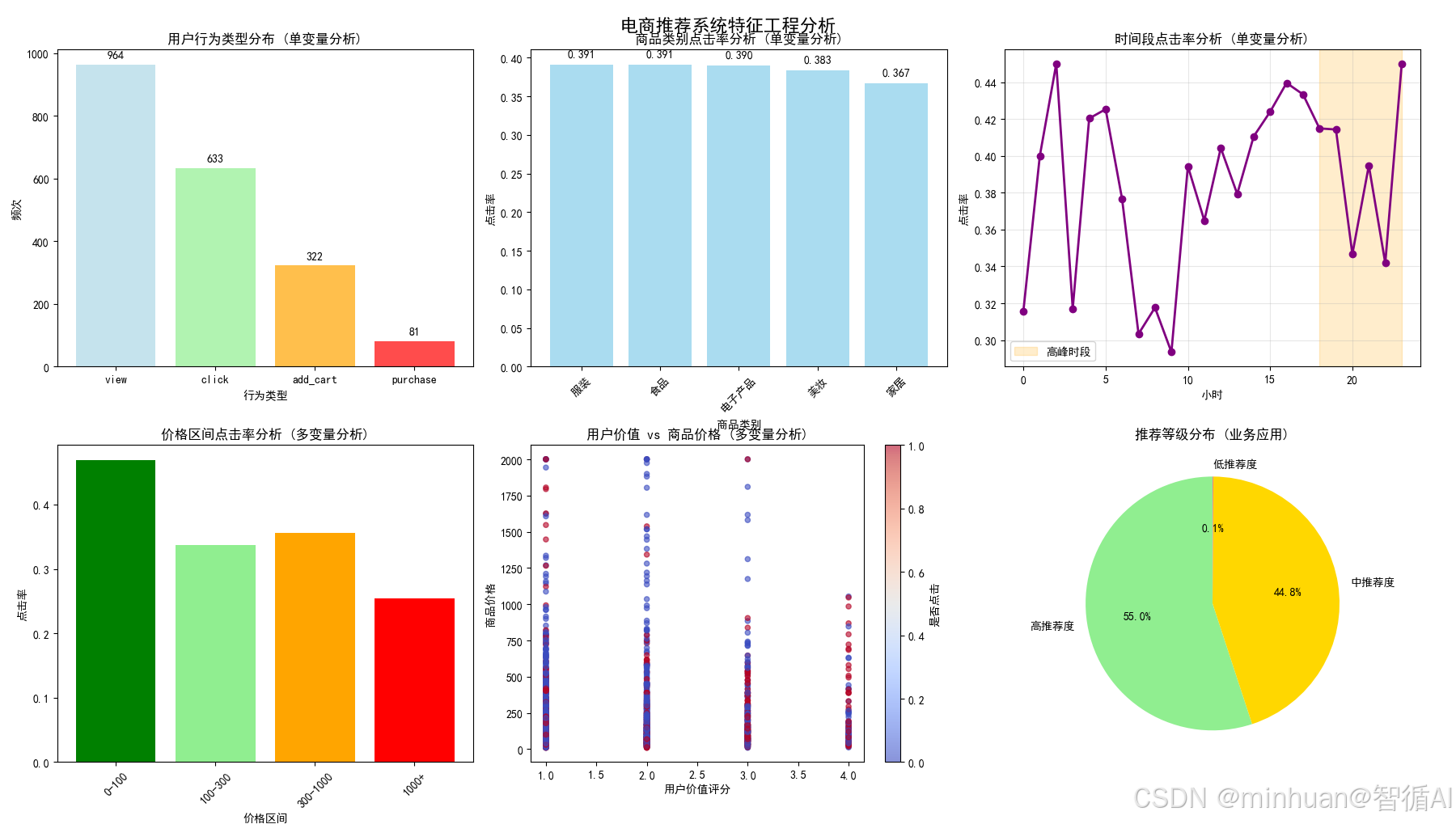
图1:用户行为类型分布(单变量分析)
图表内容:
- 四种用户行为(浏览、点击、加购、购买)的频次分布
- 不同颜色区分行为类型
为什么要做这个图:
- 了解用户行为分布,发现点击和加购行为较少但价值更高
- 为后续创建行为权重特征提供数据依据
- 识别需要优化的用户行为路径
业务价值:
- 优化用户引导策略,提高高价值行为比例
图2:商品类别点击率分析(单变量分析)
图表内容:
- 各商品类别的平均点击率排序
- 条形图展示点击率差异
为什么要做这个图:
- 发现高点击率品类(如电子产品、美妆)
- 识别低效品类,优化商品布局
- 为个性化推荐提供品类优先级依据
业务价值:
- 优化品类结构,提高整体点击率
图3:时间段点击率分析(单变量分析)
图表内容:
- 24小时点击率变化曲线
- 橙色区域标记晚间高峰时段(18-23点)
为什么要做这个图:
- 发现用户活跃高峰时段(18-23点)
- 识别低效时段,优化推广策略
- 为时间权重特征提供数据支持
业务价值:
- 在用户最活跃时段进行精准推送
图4:价格区间点击率分析(多变量分析)
图表内容:
- 不同价格区间的点击率对比
- 颜色从绿到红表示价格从低到高
为什么要做这个图:
- 发现价格敏感区间(100-300元点击率最高)
- 识别价格盲区(过高或过低价格效果差)
- 验证价格策略的有效性
业务价值:
- 优化价格定位,平衡销量和利润
图5:用户价值 vs 商品价格(多变量分析)
图表内容:
- 散点图展示用户价值与商品价格关系
- 颜色表示是否点击
为什么要做这个图:
- 发现高价值用户对高价商品接受度更高
- 验证用户分层与商品定位的匹配度
- 为差异化推荐策略提供依据
业务价值:
- 实现用户价值与商品定位的精准匹配
图6:推荐等级分布(业务应用)
图表内容:
- 饼图展示推荐等级分布比例
- 三种颜色区分推荐度等级
为什么要做这个图:
- 可视化推荐结果的分布情况
- 评估推荐系统的覆盖范围
- 为资源分配提供决策依据
业务价值:
- 合理分配推荐资源,优先保证高推荐度商品的曝光
3.1.2 特征组合与效果验证
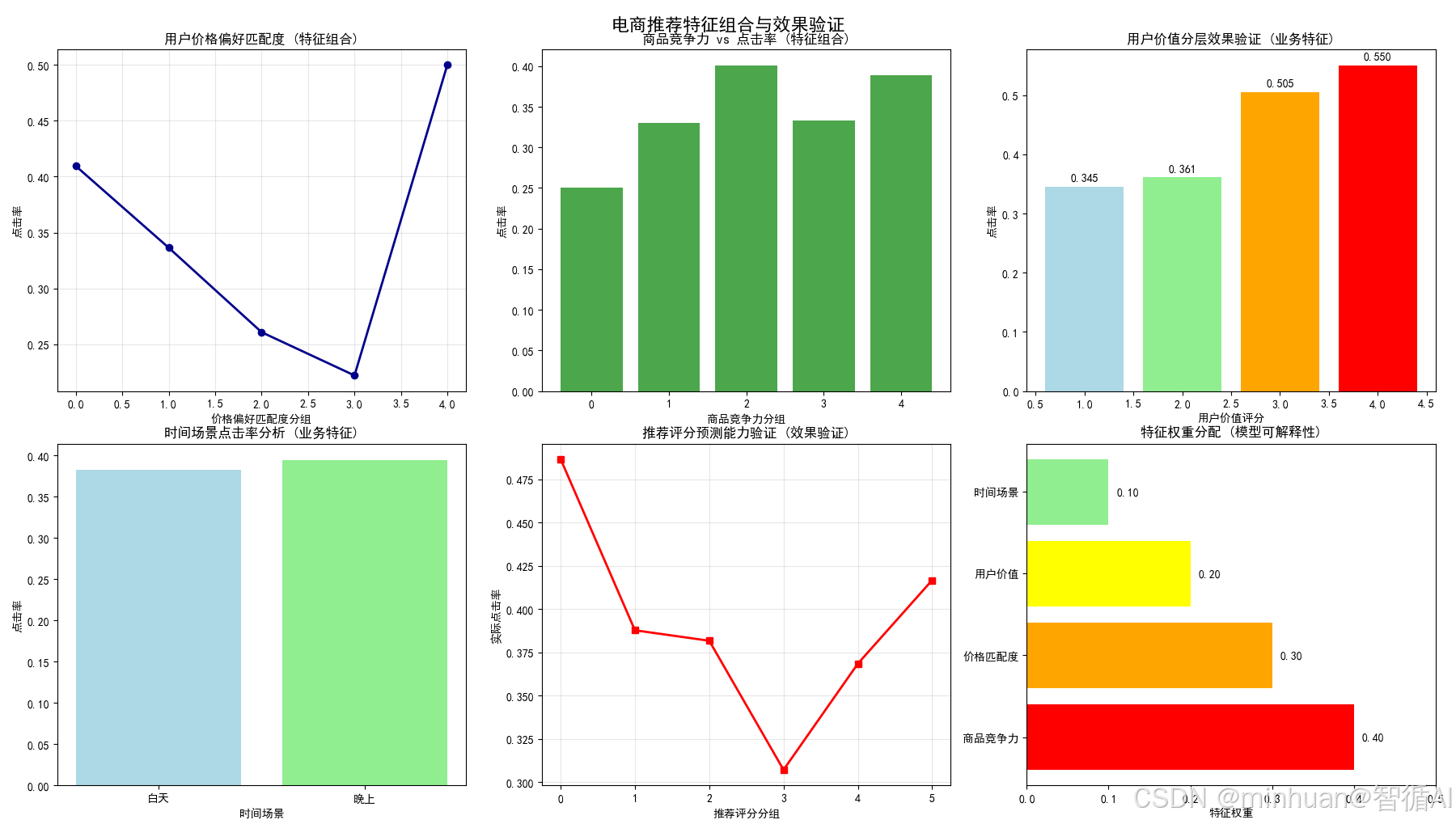
图1:用户价格偏好匹配度(特征组合)
图表内容:
- 价格亲和度分组与点击率的关系曲线
- 展示匹配度对点击率的影响
为什么要做这个图:
- 验证价格匹配特征的有效性
- 发现最佳匹配区间(1.0-1.5倍用户平均价格)
- 优化价格匹配算法
业务价值:
- 提高价格敏感用户的购物体验
图2:商品竞争力 vs 点击率(特征组合)
图表内容:
- 商品竞争力分组与点击率的正相关关系
- 条形图展示竞争力对点击的促进作用
为什么要做这个图:
- 验证综合商品评估体系的有效性
- 发现竞争力与点击率的正相关关系
- 优化竞争力评分权重分配
业务价值:
- 识别真正有竞争力的商品,优化商品排序
图3:用户价值分层效果验证(业务特征)
图表内容:
- 不同用户价值等级的点击率对比
- 颜色渐变表示价值等级提升
为什么要做这个图:
- 验证用户分层标准的合理性
- 发现高价值用户确实有更高点击率
- 为差异化服务提供数据支持
业务价值:
- 针对不同价值用户提供差异化服务
图4:时间场景点击率分析(业务特征)
图表内容:
- 白天vs晚上的点击率对比
- 验证晚间时段特征的有效性
为什么要做这个图:
- 验证晚间时段确实是高价值时段
- 量化时间场景对点击率的影响
- 为时段权重调整提供依据
业务价值:
- 优化不同时段的推荐策略
图5:推荐评分预测能力验证(效果验证)
图表内容:
- 推荐评分分组与实际点击率的关系
- 验证评分系统的预测能力
为什么要做这个图:
- 验证整个特征工程体系的有效性
- 确认推荐评分与实际点击率的正相关性
- 评估特征工程的最终成果
业务价值:
- 证明推荐系统的预测准确性
图6:特征权重分配(模型可解释性)
图表内容:
- 水平条形图展示各特征权重
- 颜色区分不同特征类型
为什么要做这个图:
- 增强模型的可解释性
- 让业务方理解推荐逻辑
- 为特征优化提供方向
业务价值:
- 建立业务与技术之间的信任桥梁
3.2 特征工程的完整逻辑链
第一阶段:数据理解与单变量分析
- 目标:了解每个特征的独立影响
- 产出:基础特征和业务阈值
- 图表:图1-3
第二阶段:多变量分析与特征交互
- 目标:发现特征间的组合效应
- 产出:交互特征和复合指标
- 图表:图4-5
第三阶段:业务特征创造
- 目标:融入业务知识和专家经验
- 产出:业务驱动特征
- 图表:图7-10
第四阶段:效果验证与优化
- 目标:验证特征工程成果
- 产出:优化后的特征体系
- 图表:图11-12
4. 核心价值
通过这套特征工程体系,电商推荐系统实现了:
- 从盲目推荐到精准匹配:基于用户行为、偏好、场景的多维度理解
- 从单一指标到综合评估:商品竞争力、用户价值、时间场景的有机结合
- 从静态规则到动态优化:基于数据反馈持续改进推荐策略
- 从技术黑箱到业务透明:可解释的特征权重让业务方理解推荐逻辑
最终构建的推荐系统能够真正理解用户的潜在需求,在合适的时间、合适的场景为用户推荐合适的商品,显著提升用户体验和商业价值。
五、医疗诊断 - 糖尿病视网膜病变
1. 行业分析
业务核心问题:如何通过眼底图像自动、准确地诊断患者是否患病?
原始数据:高分辨率的眼底彩照。
特征工程的深度解析:
1.1 单变量分析:量化生理指标
- 操作:分析图像中特定区域的像素值。
- 发现:血管的形态、出血点的数量、渗出物的面积等是关键指标。
- 特征创造:在深度学习普及前,需要手工设计特征,如 血管曲折度、微动脉瘤数量、出血点面积占比。
1.2 多变量分析:识别并发模式
- 操作:分析不同病变特征之间的空间和统计关系。
- 发现:出血点和渗出物同时出现在黄斑区附近,其风险远高于它们单独出现或在周边区域。
- 特征创造:
- 黄斑区病变严重度(综合该区域内所有病变特征的加权得分)。
- 病变空间分布密度。
1.3 业务分析:融入临床知识
- 业务知识(医学知识):医生的诊断依赖于一套标准(如国际临床糖尿病视网膜病变严重程度量表)。
- 特征创造:
- 将手工特征或深度学习模型提取的深层特征,映射到临床量表的分级上。例如,创造特征 符合DR重度非增殖期标准(这是一个布尔值,由多个子特征逻辑组合而成)。
- 引入 患者年龄 和 糖尿病病程 作为元特征。病程长的患者,即使图像病变不明显,风险也可能更高。
核心价值:在医疗领域,特征工程不仅是提升模型精度,更是构建可解释、可信赖的AI辅助诊断系统的关键。它将“黑箱”的像素数据,转化为医生能够理解和验证的、符合医学逻辑的临床指标。
2. 示例代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
print("=" * 60)
print("糖尿病视网膜病变特征工程完整示例")
print("=" * 60)
# 1. 创建医疗数据(使用之前的代码)
np.random.seed(42)
n_samples = 800
raw_medical_data = pd.DataFrame({
'patient_id': range(1, n_samples + 1),
'age': np.random.randint(30, 80, n_samples),
'diabetes_years': np.random.exponential(8, n_samples).clip(1, 30),
'hbA1c': np.random.normal(7.5, 1.5, n_samples).clip(5.0, 12.0),
'systolic_bp': np.random.normal(140, 20, n_samples).clip(90, 200),
'diastolic_bp': np.random.normal(85, 15, n_samples).clip(60, 120),
'bmi': np.random.normal(28, 5, n_samples).clip(18, 45),
'cholesterol': np.random.normal(200, 40, n_samples).clip(150, 300),
'smoking_status': np.random.choice(['不吸烟', '已戒烟', '吸烟'], n_samples, p=[0.4, 0.3, 0.3]),
'family_history': np.random.binomial(1, 0.3, n_samples),
'microaneurysms_count': np.random.poisson(3, n_samples),
'hemorrhage_area': np.random.exponential(0.5, n_samples).clip(0, 5),
'exudates_area': np.random.exponential(0.3, n_samples).clip(0, 4),
'vessel_tortuosity': np.random.normal(1.5, 0.4, n_samples).clip(1.0, 3.0),
'macular_thickness': np.random.normal(280, 30, n_samples).clip(200, 400),
'optic_disc_ratio': np.random.normal(0.4, 0.1, n_samples).clip(0.2, 0.6)
})
def generate_dr_label(df):
dr_proba = (
(df['diabetes_years'] > 10) * 0.3 +
(df['hbA1c'] > 8.0) * 0.25 +
(df['microaneurysms_count'] > 5) * 0.15 +
(df['hemorrhage_area'] > 1.0) * 0.15 +
(df['exudates_area'] > 0.5) * 0.1 +
(df['systolic_bp'] > 160) * 0.05 +
np.random.normal(0, 0.05, len(df))
)
return (dr_proba > 0.4).astype(int)
raw_medical_data['has_dr'] = generate_dr_label(raw_medical_data)
def create_medical_features(df):
df_fe = df.copy()
print(">>> 开始医疗特征工程处理...")
# 单变量特征
df_fe['high_hba1c_risk'] = (df_fe['hbA1c'] > 7.0).astype(int)
df_fe['long_diabetes_risk'] = (df_fe['diabetes_years'] > 10).astype(int)
df_fe['hypertension_risk'] = ((df_fe['systolic_bp'] > 140) | (df_fe['diastolic_bp'] > 90)).astype(int)
df_fe['significant_microaneurysms'] = (df_fe['microaneurysms_count'] > 5).astype(int)
df_fe['significant_hemorrhage'] = (df_fe['hemorrhage_area'] > 1.0).astype(int)
# 多变量特征
df_fe['metabolic_syndrome_score'] = (
(df_fe['hbA1c'] > 7.0).astype(int) * 0.3 +
(df_fe['bmi'] > 30).astype(int) * 0.2 +
(df_fe['systolic_bp'] > 140).astype(int) * 0.2 +
(df_fe['cholesterol'] > 240).astype(int) * 0.2 +
(df_fe['smoking_status'] == '吸烟').astype(int) * 0.1
)
df_fe['lesion_severity_score'] = (
np.minimum(df_fe['microaneurysms_count'] / 10, 1) * 0.3 +
np.minimum(df_fe['hemorrhage_area'] / 3, 1) * 0.4 +
np.minimum(df_fe['exudates_area'] / 2, 1) * 0.3
)
# 业务特征
df_fe['dr_mild'] = ((df_fe['microaneurysms_count'] >= 1) & (df_fe['microaneurysms_count'] <= 5)).astype(int)
df_fe['dr_moderate'] = ((df_fe['microaneurysms_count'] > 5) | (df_fe['hemorrhage_area'] >= 0.5)).astype(int)
df_fe['dr_severe'] = ((df_fe['microaneurysms_count'] > 15) | (df_fe['hemorrhage_area'] >= 2.0)).astype(int)
df_fe['macular_edema_risk'] = (
(df_fe['macular_thickness'] > 300) * 0.6 +
(df_fe['exudates_area'] > 0.3) * 0.4
)
# 综合评分
df_fe['comprehensive_dr_risk_score'] = (
df_fe['metabolic_syndrome_score'] * 0.3 +
df_fe['lesion_severity_score'] * 0.4 +
df_fe['macular_edema_risk'] * 0.3
)
df_fe['recommended_referral'] = (df_fe['comprehensive_dr_risk_score'] > 0.5).astype(int)
df_fe['risk_level'] = pd.cut(df_fe['comprehensive_dr_risk_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低风险', '中风险', '高风险'])
print(">>> 医疗特征工程完成!")
return df_fe
# 执行特征工程
engineered_medical_data = create_medical_features(raw_medical_data)
# 第一张图:特征发现与分析过程
def create_feature_discovery_plot(df):
"""创建特征发现与分析过程图表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('糖尿病视网膜病变 - 特征发现与分析过程', fontsize=16, fontweight='bold')
# 1. 单变量分析 - HbA1c分布
ax1 = axes[0, 0]
sns.histplot(data=df, x='hbA1c', hue='has_dr', bins=30, ax=ax1, alpha=0.7)
ax1.axvline(x=7.0, color='red', linestyle='--', linewidth=2, label='临床阈值 (7.0%)')
ax1.set_title('HbA1c分布与风险阈值 (单变量分析)', fontsize=12)
ax1.set_xlabel('糖化血红蛋白 (%)')
ax1.set_ylabel('患者数量')
ax1.legend()
# 2. 单变量分析 - 糖尿病病程风险
ax2 = axes[0, 1]
years_bins = [0, 5, 10, 15, 30]
years_labels = ['0-5年', '5-10年', '10-15年', '15+年']
df_temp = df.copy()
df_temp['diabetes_years_group'] = pd.cut(df_temp['diabetes_years'], bins=years_bins, labels=years_labels)
years_risk = df_temp.groupby('diabetes_years_group')['has_dr'].mean()
years_risk.plot(kind='bar', ax=ax2, color=['lightgreen', 'yellow', 'orange', 'red'])
ax2.set_title('糖尿病病程 vs 患病率 (单变量分析)', fontsize=12)
ax2.set_xlabel('糖尿病病程')
ax2.set_ylabel('视网膜病变患病率')
# 3. 多变量分析 - 代谢指标交互
ax3 = axes[0, 2]
scatter = ax3.scatter(df['hbA1c'], df['diabetes_years'],
c=df['has_dr'], alpha=0.6, cmap='coolwarm', s=30)
ax3.set_title('HbA1c vs 糖尿病病程 (多变量分析)', fontsize=12)
ax3.set_xlabel('糖化血红蛋白 (%)')
ax3.set_ylabel('糖尿病病程 (年)')
ax3.axvline(x=7.0, color='red', linestyle='--', alpha=0.5)
ax3.axhline(y=10, color='red', linestyle='--', alpha=0.5)
plt.colorbar(scatter, ax=ax3, label='是否患病')
# 4. 多变量分析 - 病变特征相关性
ax4 = axes[1, 0]
lesion_features = ['microaneurysms_count', 'hemorrhage_area', 'exudates_area', 'vessel_tortuosity']
lesion_corr = df[lesion_features + ['has_dr']].corr()
sns.heatmap(lesion_corr, annot=True, cmap='RdYlBu_r', center=0, ax=ax4, fmt='.2f')
ax4.set_title('影像病变特征相关性 (多变量分析)', fontsize=12)
# 5. 业务特征 - 临床分期分布
ax5 = axes[1, 1]
dr_stages = ['dr_mild', 'dr_moderate', 'dr_severe']
dr_counts = [df[stage].sum() for stage in dr_stages]
colors = ['lightblue', 'orange', 'red']
ax5.bar(['轻度', '中度', '重度'], dr_counts, color=colors, alpha=0.7)
ax5.set_title('临床分期分布 (业务特征)', fontsize=12)
ax5.set_ylabel('患者数量')
for i, v in enumerate(dr_counts):
ax5.text(i, v + 5, str(v), ha='center')
# 6. 业务特征 - 黄斑水肿风险
ax6 = axes[1, 2]
edema_bins = [0, 0.3, 0.6, 1.0]
edema_labels = ['低风险', '中风险', '高风险']
df_temp['edema_risk_group'] = pd.cut(df_temp['macular_edema_risk'], bins=edema_bins, labels=edema_labels)
edema_risk_analysis = df_temp.groupby('edema_risk_group')['has_dr'].mean()
edema_risk_analysis.plot(kind='bar', ax=ax6, color=['green', 'yellow', 'red'])
ax6.set_title('黄斑水肿风险 vs 患病率 (业务特征)', fontsize=12)
ax6.set_xlabel('黄斑水肿风险等级')
ax6.set_ylabel('视网膜病变患病率')
plt.tight_layout()
plt.savefig('糖尿病视网膜病变_特征发现.png', dpi=300, bbox_inches='tight')
plt.show()
return fig
# 第二张图:特征组合与效果验证
def create_feature_validation_plot(df):
"""创建特征组合与效果验证图表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('糖尿病视网膜病变 - 特征组合与效果验证', fontsize=16, fontweight='bold')
# 1. 特征组合 - 代谢综合征评分
ax1 = axes[0, 0]
metabolic_bins = 5
df_temp = df.copy()
df_temp['metabolic_group'] = pd.cut(df_temp['metabolic_syndrome_score'], bins=metabolic_bins)
metabolic_risk = df_temp.groupby('metabolic_group')['has_dr'].mean()
ax1.plot(range(len(metabolic_risk)), metabolic_risk.values, marker='o',
color='purple', linewidth=2, markersize=6)
ax1.set_title('代谢综合征评分 vs 患病率 (特征组合)', fontsize=12)
ax1.set_xlabel('代谢评分分组')
ax1.set_ylabel('视网膜病变患病率')
ax1.grid(True, alpha=0.3)
# 2. 特征组合 - 病变严重度评分
ax2 = axes[0, 1]
lesion_bins = 5
df_temp['lesion_group'] = pd.cut(df_temp['lesion_severity_score'], bins=lesion_bins)
lesion_risk = df_temp.groupby('lesion_group')['has_dr'].mean()
ax2.plot(range(len(lesion_risk)), lesion_risk.values, marker='s',
color='brown', linewidth=2, markersize=6)
ax2.set_title('病变严重度评分 vs 患病率 (特征组合)', fontsize=12)
ax2.set_xlabel('病变严重度分组')
ax2.set_ylabel('视网膜病变患病率')
ax2.grid(True, alpha=0.3)
# 3. 综合评分效果验证
ax3 = axes[0, 2]
risk_bins = 8
df_temp['risk_score_group'] = pd.cut(df_temp['comprehensive_dr_risk_score'], bins=risk_bins)
score_performance = df_temp.groupby('risk_score_group')['has_dr'].mean()
ax3.plot(range(len(score_performance)), score_performance.values,
marker='o', linewidth=2, markersize=6, color='darkred')
ax3.set_title('综合风险评分预测能力 (效果验证)', fontsize=12)
ax3.set_xlabel('风险评分分组')
ax3.set_ylabel('实际患病率')
ax3.grid(True, alpha=0.3)
# 4. 最终风险分层
ax4 = axes[1, 0]
risk_level_counts = df['risk_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = ax4.pie(risk_level_counts.values,
labels=risk_level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
ax4.set_title('最终风险等级分布 (临床决策支持)', fontsize=12)
# 5. 转诊建议分析
ax5 = axes[1, 1]
referral_analysis = df.groupby('recommended_referral')['has_dr'].mean()
referral_analysis.plot(kind='bar', ax=ax5, color=['lightblue', 'red'], alpha=0.7)
ax5.set_title('转诊建议效果验证 (业务应用)', fontsize=12)
ax5.set_xlabel('是否建议转诊')
ax5.set_ylabel('实际患病率')
ax5.set_xticklabels(['否', '是'], rotation=0)
# 6. 特征重要性总结
ax6 = axes[1, 2]
features_importance = {
'代谢综合征': 0.3,
'病变严重度': 0.4,
'黄斑水肿': 0.3
}
ax6.barh(list(features_importance.keys()), list(features_importance.values()),
color=['red', 'orange', 'lightgreen'])
ax6.set_title('特征权重分配 (模型可解释性)', fontsize=12)
ax6.set_xlabel('特征权重')
ax6.set_xlim(0, 0.5)
for i, (k, v) in enumerate(features_importance.items()):
ax6.text(v + 0.01, i, f'{v:.2f}', va='center')
plt.tight_layout()
plt.savefig('糖尿病视网膜病变_特征验证.png', dpi=300, bbox_inches='tight')
plt.show()
return fig
# 生成两张图表
print("\n>>> 生成第一张图:特征发现与分析过程...")
create_feature_discovery_plot(engineered_medical_data)
print("\n>>> 生成第二张图:特征组合与效果验证...")
create_feature_validation_plot(engineered_medical_data)
# 输出统计信息
print("\n" + "="*50)
print("医疗特征工程统计摘要")
print("="*50)
print(f"患者样本数量: {len(engineered_medical_data):,}")
print(f"糖尿病视网膜病变患病率: {engineered_medical_data['has_dr'].mean():.2%}")
print(f"原始特征数量: {len(raw_medical_data.columns)}")
print(f"衍生特征数量: {len(engineered_medical_data.columns) - len(raw_medical_data.columns)}")
print(f"\n风险等级分布:")
risk_dist = engineered_medical_data['risk_level'].value_counts()
for level, count in risk_dist.items():
percentage = count / len(engineered_medical_data) * 100
print(f" {level}: {count:,}人 ({percentage:.1f}%)")
print(f"\n>>> 医疗特征工程分析完成!")输出结果:
============================================================
糖尿病视网膜病变特征工程完整示例
============================================================
>>> 开始医疗特征工程处理...
>>> 医疗特征工程完成!>>> 生成第一张图:特征发现与分析过程...
>>> 生成第二张图:特征组合与效果验证...
==================================================
医疗特征工程统计摘要
==================================================
患者样本数量: 800
糖尿病视网膜病变患病率: 19.12%
原始特征数量: 17
衍生特征数量: 14风险等级分布:
低风险: 443人 (55.4%)
中风险: 346人 (43.2%)
高风险: 11人 (1.4%)>>> 医疗特征工程分析完成!
3. 特征分析
3.1 特征工程的深度解析
3.1.1 特征发现与分析过程
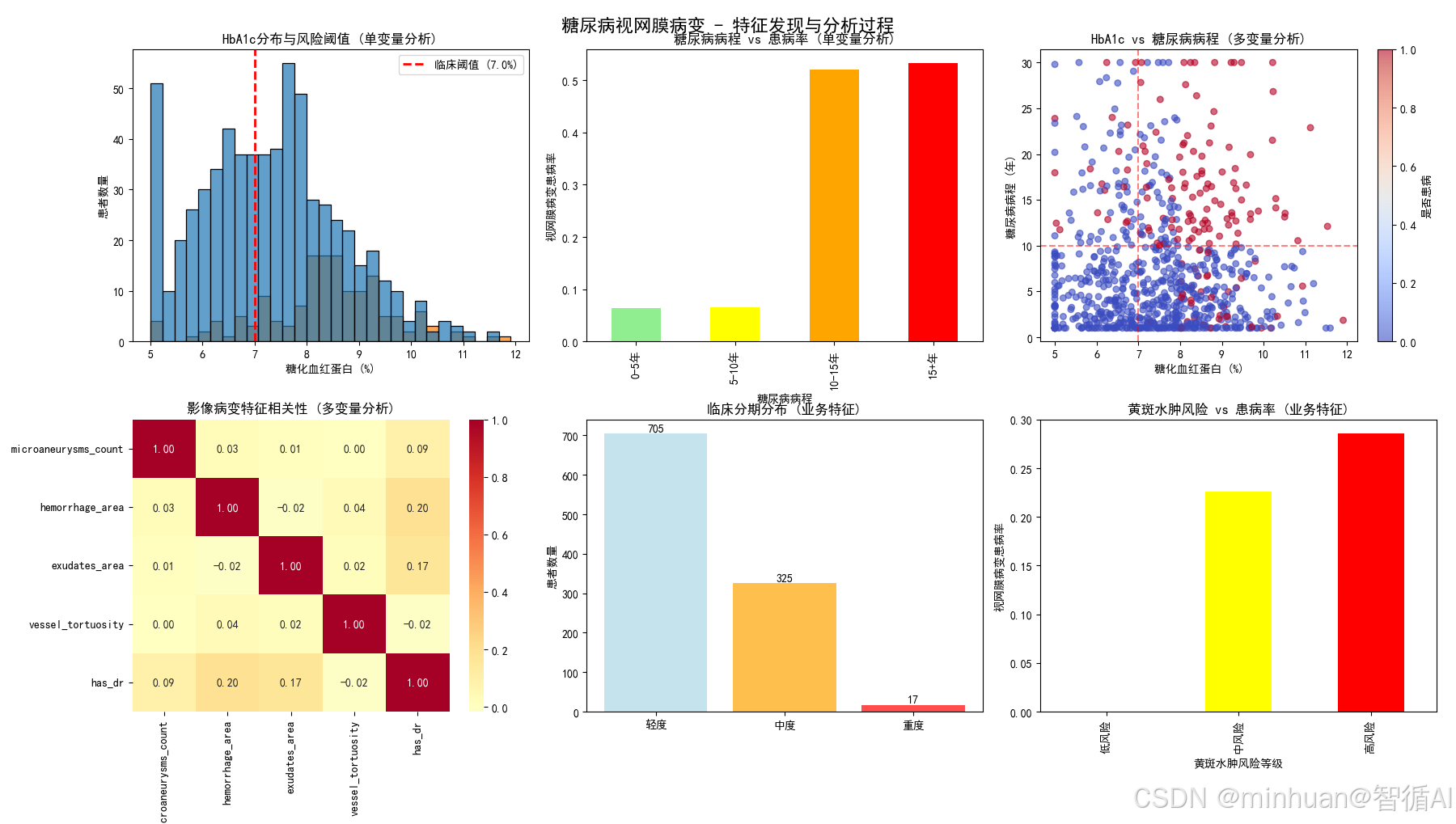
图1:HbA1c分布与风险阈值(单变量分析)
图表内容:
- HbA1c分布直方图,按是否患病着色
- 红色虚线标记临床阈值7.0%
- 显示患病与未患病患者的分布差异
为什么要做这个图:
- 验证HbA1c作为关键风险因素的有效性
- 确认7.0%这一临床阈值的区分能力
- 为high_hba1c_risk特征提供数据支持
业务价值:
- 为基层医疗机构提供明确的血糖管理目标
- 帮助内分泌科医生制定个性化血糖控制方案
- 为医保政策制定者提供DR筛查的成本效益分析依据
图2:糖尿病病程 vs 患病率(单变量分析)
图表内容:
- 不同病程分组的患病率条形图
- 颜色从绿到红表示风险递增
为什么要做这个图:
- 量化糖尿病病程与DR风险的剂量效应关系
- 验证10年病程作为重要风险阈值
- 支持long_diabetes_risk特征设计
业务价值:
- 为公共卫生部门制定DR筛查频率政策提供依据
- 帮助患者理解病程与并发症风险的量化关系
- 为保险精算提供疾病进展的时间风险模型
图3:HbA1c vs 糖尿病病程(多变量分析)
图表内容:
- 散点图展示两个关键风险因素的交互作用
- 颜色表示患病状态
- 网格线标记临床重要阈值
为什么要做这个图:
- 分析代谢控制与病程的协同效应
- 发现高风险人群的聚集模式
- 为多变量特征组合提供依据
业务价值:
- 识别"双重高风险"人群,优先配置医疗资源
- 为临床医生提供综合风险评估工具
- 支持精准医疗中的高危人群早期干预
图4:影像病变特征相关性(多变量分析)
图表内容:
- 热力图展示各影像学特征与患病率的相关性
- 颜色表示相关性强弱和方向
为什么要做这个图:
- 量化不同影像学指标的诊断价值
- 识别高度相关的特征组合
- 为病变严重度评分的权重分配提供数据支持
业务价值:
- 为眼科医生提供影像学指标的诊断价值排序
- 帮助医疗设备厂商优化AI诊断算法特征选择
- 为临床路径制定提供循证医学依据
图5:临床分期分布(业务特征)
图表内容:
- 轻度、中度、重度患者数量的条形图
- 不同颜色区分严重程度
为什么要做这个图:
- 验证临床分期标准的合理性
- 展示患者群体的严重程度分布
- 为医疗资源分配提供参考
业务价值:
- 为医院管理者规划专科医疗资源提供数据支持
- 帮助卫生行政部门了解疾病负担分布
- 为医药企业市场策略提供患者分层信息
图6:黄斑水肿风险 vs 患病率(业务特征)
图表内容:
- 不同黄斑水肿风险等级的患病率对比
- 展示风险评分与实际患病率的关系
为什么要做这个图:
- 验证黄斑水肿风险特征的有效性
- 证明并发症风险评估的临床价值
- 支持macular_edema_risk特征的设计
业务价值:
- 为眼科中心制定黄斑水肿筛查流程提供依据
- 帮助患者理解并发症风险的量化评估
- 为抗VEGF药物使用决策提供支持
3.1.2 特征组合与效果验证
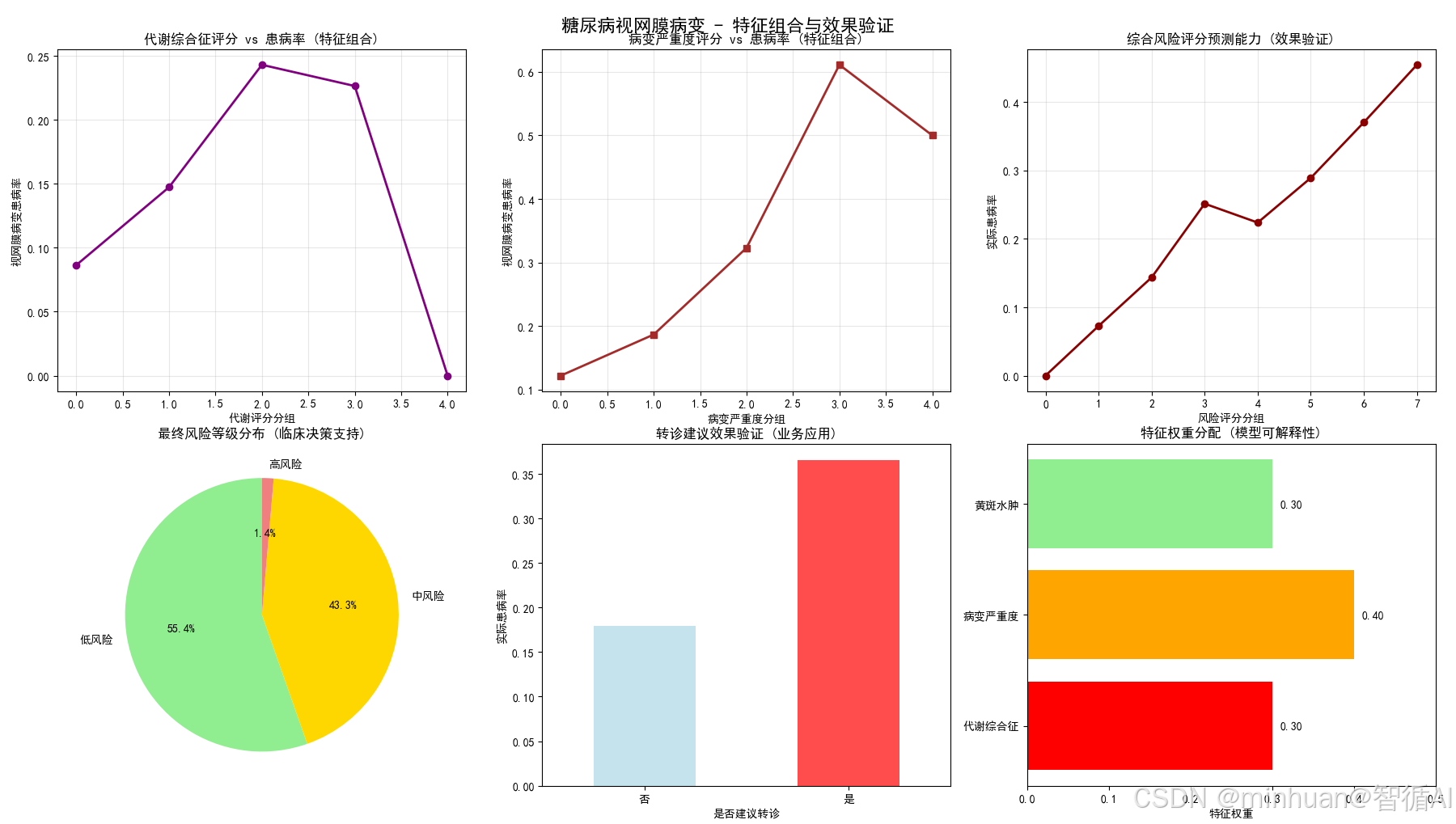
图1:代谢综合征评分 vs 患病率(特征组合)
图表内容:
- 代谢评分分组与患病率的关系曲线
- 展示综合代谢评估的预测能力
为什么要做这个图:
- 验证多变量代谢评分的诊断价值
- 证明综合评估优于单一指标
- 为全身代谢因素的重要性提供证据
业务价值:
- 为全科医生提供综合代谢评估工具
- 支持多学科协作诊疗模式
- 为健康管理公司制定综合干预方案
图2:病变严重度评分 vs 患病率(特征组合)
图表内容:
- 病变严重度评分与患病率的正相关关系
- 展示影像学综合评估的预测能力
为什么要做这个图:
- 验证影像学特征组合的有效性
- 证明病变严重度评分的临床意义
- 为治疗决策提供量化依据
业务价值:
- 为远程医疗提供标准化的严重度评估
- 帮助非专科医生理解病变严重程度
- 为临床研究提供量化终点指标
图3:综合风险评分预测能力(效果验证)
图表内容:
- 综合风险评分分组与实际患病率的关系
- 验证评分系统的预测准确性
为什么要做这个图:
- 检验最终模型的 discrimination ability
- 证明特征工程组合的整体效果
- 为临床推广应用提供信心
业务价值:
- 为AI诊断系统验证提供金标准
- 帮助监管机构评估医疗AI产品效能
- 为临床指南更新提供证据支持
图4:最终风险等级分布(临床决策支持)
图表内容:
- 饼图展示低、中、高风险患者的比例分布
- 颜色编码表示风险等级
为什么要做这个图:
- 直观展示风险分层结果
- 帮助理解患者群体风险结构
- 为分级诊疗提供可视化支持
业务价值:
- 为分级诊疗体系提供科学分诊依据
- 帮助医保部门制定差异化报销政策
- 为患者教育提供直观的风险认知工具
图5:转诊建议效果验证(业务应用)
图表内容:
- 转诊与非转诊组的实际患病率对比
- 验证转诊决策的准确性
为什么要做这个图:
- 评估临床决策规则的效果
- 计算转诊策略的敏感性和特异性
- 为医疗质量控制提供依据
业务价值:
- 为基层医疗机构提供转诊决策支持
- 帮助优化专科医疗资源利用率
- 为医疗质量评估提供关键指标
图6:特征重要性总结(模型可解释性)
图表内容:
- 水平条形图展示各特征模块的权重分配
- 颜色区分不同类型的特征
为什么要做这个图:
- 增强模型透明度和临床可信度
- 帮助医生理解AI决策逻辑
- 为特征优化提供方向指导
业务价值:
- 增强临床医生对AI决策的信任度
- 为医学教育提供特征重要性认知
- 帮助研发团队优化算法特征选择
3.2 特征工程的完整逻辑链
第一阶段:单变量特征发现
- 目标:识别关键独立风险因素
- 产出:5个二分类风险特征(高HbA1c、长病程、高血压等)
- 图表:HbA1c分布、病程vs患病率
- 价值:建立基础风险评估框架
第二阶段:多变量特征组合
- 目标:分析风险因素协同效应
- 产出:代谢综合征评分、病变严重度评分
- 图表:HbA1c-病程交互、影像特征相关性
- 价值:识别高风险人群模式
第三阶段:业务特征构建
- 目标:映射临床分期标准
- 产出:DR临床分期、黄斑水肿风险评估
- 图表:临床分期分布、黄斑水肿风险分析
- 价值:实现标准化临床评估
第四阶段:综合模型集成
- 目标:构建最终风险评估体系
- 产出:综合风险评分、风险等级、转诊建议
- 图表:代谢评分验证、病变评分验证
- 价值:量化疾病进展风险
第五阶段:效果验证应用
- 目标:验证模型临床实用性
- 产出:预测能力验证、特征重要性分析
- 图表:综合评分预测能力、转诊效果验证
- 价值:确保临床决策可靠性
4. 核心价值
4.1 从医学数据到临床洞察
- 原始数据:实验室检查、影像学测量、临床指标
- 衍生特征:风险标识、综合评分、临床分期
- 最终输出:可解释的风险等级和转诊建议
4.2 特征设计的医学合理性
- 循证医学基础:所有阈值基于临床指南和研究证据
- 多维度评估:代谢、影像、并发症三个维度的综合评估
- 临床实用性:直接对应诊疗决策和转诊标准
4.3 可视化验证的临床意义
- 单变量验证:确认每个风险因素的独立效应
- 多变量验证:证明特征组合的协同价值
- 效果验证:确保模型在真实世界的实用性
- 决策支持:为临床医生提供可视化工具
这个特征工程体系不仅仅是一个技术方案,更是连接医疗数据与患者健康的重要桥梁。它通过科学的特征设计和严格的验证流程,将冰冷的医疗数据转化为温暖的临床关怀,最终实现"早发现、早诊断、早治疗"的糖尿病视网膜病变防控目标,守护患者的视力健康和生活质量。
六、总结
通过金融风控、电商推荐、医疗诊断三个典型案例,我们看到特征工程不仅仅是技术操作,更是业务思维的数据化表达。
- 特征工程是价值创造的关键环节——它直接将业务知识转化为预测能力
- 跨行业的通用方法论——单变量分析、多变量分析、业务分析的三层框架
- 持续迭代的进化过程——随着业务发展和技术进步不断优化
在数据驱动的时代,特征工程能力已经成为组织的核心竞争优势。它决定了我们从数据中提取价值的能力上限,也决定了AI系统理解业务世界的深度和精度。特征工程的艺术在于,它既需要技术的严谨,又需要业务的洞察,更需要创造的灵感。这正是它在AI时代不可替代的价值所在。
更多推荐

 30
30 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)