
25、LangChain开发框架(二)--快速入门
以目前比较热门的开发框架对比来看,LangChain始终保持快速迭代,其社区也是非常活跃,作为一个开发者想要在大模型开发取得更好的进步和成绩,最好是选择当前大家认可度比较高的框架作为开发语言,就像选择开发语言一样,训现阶段应该选择PyTorch,而不是tensorflow。LangChain从大模型角度出发,通过开发人员在实践过程中对大模型能力的深入理解及其在不同场景下的涌现潜力,使用模块化的方式
一、简单介绍
以目前比较热门的开发框架对比来看,LangChain始终保持快速迭代,其社区也是非常活跃,作为一个开发者想要在大模型开发取得更好的进步和成绩,最好是选择当前大家认可度比较高的框架作为开发语言,就像选择开发语言一样,训现阶段应该选择PyTorch,而不是tensorflow。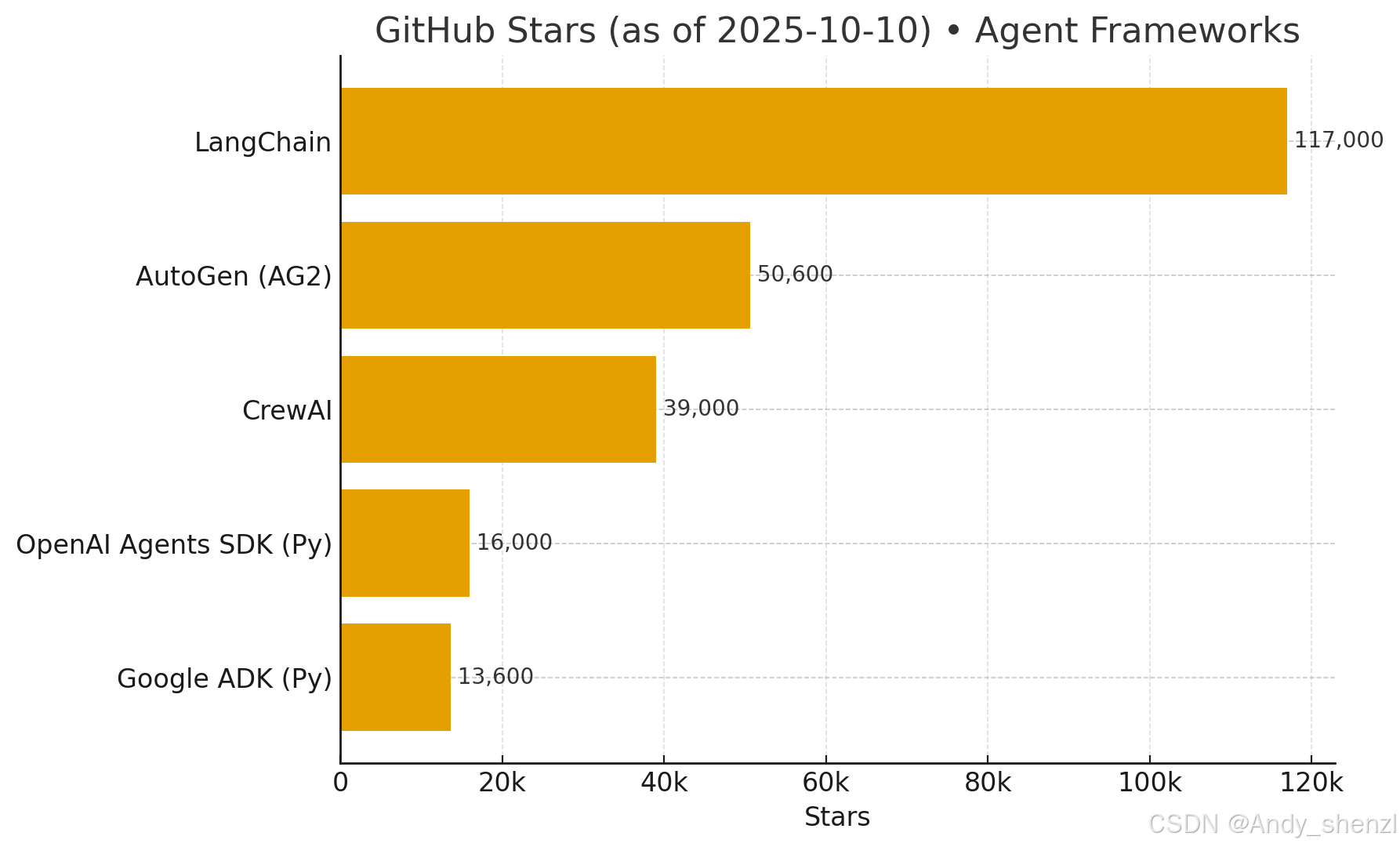
LangChain从大模型角度出发,通过开发人员在实践过程中对大模型能力的深入理解及其在不同场景下的涌现潜力,使用模块化的方式进行高级抽象,设计出统一接口以适配各种大模型。LangChain抽象出最重要的核心模块如下:
1) Model I/O(模型输入/输出)
做什么
把“提示→模型→解析”做成标准化流程:
- Prompt Templates:把输入格式化成模型需要的消息/文本(含 few-shot、多模态等)。(LangChain)
- Chat Models:统一的聊天模型接口,配合一行初始化
init_chat_model()快速切不同厂商(OpenAI/Anthropic/Gemini/Bedrock/DeepSeek…)。(LangChain 文档) - Structured Output:当你要“结构化数据而非纯文本”时,优先用
.with_structured_output()(模型原生 JSON/函数调用能力)或输出解析器(StructuredOutputParser/PydanticOutputParser 等)。(LangChain)
怎么做(最常用 API)
ChatPromptTemplate组织系统/用户消息。(LangChain)init_chat_model("provider:model")一行拿到正确实例(可推断 provider,且可做运行时可配置)。(LangChain)model.with_structured_output(schema)或prompt | model | OutputParser两条路。(LangChain)
何时用
- 任何“单轮/轻编排”的对话、抽取、分类、结构化生成。
注意点
- 先
bind_tools()再with_structured_output()(官方强调顺序以避免解析/工具冲突)。(LangChain)
2) Retrieval(检索)
做什么
把外部知识(文件、网页、SQL/向量库等)接到模型前的“取数”环节:加载 → 切分 → 向量化/索引 → 检索。(LangChain 文档)
怎么做(常用组件)
- Document Loaders / Text Splitters:
RecursiveCharacterTextSplitter是通用首选。(LangChain) - Embeddings + Vector Stores:把切片写入向量库(FAISS、Pinecone、PGVector…),然后通过统一的
as_retriever()暴露检索接口。(LangChain) - 官方“构建语义检索引擎”教程梳理了完整路径与实现。(LangChain)
何时用
- RAG、FAQ、私有知识问答、多文档问答、代码/日志搜索等。
注意点
- 先跑通“最小 RAG”(本地 FAISS + 简单提示),再逐步加多查询、重排、压缩等技巧,稳定再上云后端。(LangChain)
3) Chains(链 / LCEL 编排)
做什么
用 LCEL(LangChain Expression Language) 把“输入→提示→模型→解析→后处理”等步骤像管道一样拼起来;天然支持同步/异步/批处理/流式。(LangChain)
怎么做(关键概念)
- 任何实现了
Runnable接口的组件都能|起来:prompt | model | parser,或并行/条件/映射等组合。(LangChain)
何时用
- 线性或轻分支流程(对话、抽取、分类、调用一两步检索/工具)。
注意点
- 复杂状态/分支/回环/多智能体/HITL 时,用 LangGraph 更稳(下文 Agents 也会提)。(LangChain)
4) Memory(对话/应用记忆)
做什么
在多轮/多次调用中保存状态,把历史上下文注入后续调用,让模型更连贯。官方定义是“在链中维护过去执行的状态并注入到下一次输入”。(LangChain)
新建议(v0.3 之后)
- 迁移到 LangGraph 的 persistence(持久化)来做 Memory:官方在 v0.3 指南中建议把记忆交给 LangGraph 的持久化机制来实现(更可控、更生产级)。(LangChain)
传统 Memory(了解即可)
ConversationBufferMemory / ConversationSummaryBufferMemory / ConversationTokenBufferMemory等均已标注弃用迁移提示,仍可用但建议按迁移文档替换。(LangChain)
何时用
- 多轮助手、任务编排中跨步状态、实体信息跟踪。
注意点
- 生产上优先用 LangGraph + 持久化存储 取代老式“内存类”以获得可靠性与可观测性。(LangChain)
5) Agents(智能体)
做什么
把 LLM 与工具组合,让其推理→决定调用哪个工具→执行→继续推理,迭代完成任务。LangChain 提供生产可用的 ReAct Agent 实现与 create_agent() 入口;LangGraph 提供预构建 Agent 与 ToolNode 等原语。(LangChain 文档)
工具调用(Tool Calling)
- 用
.bind_tools([...])把工具 schema 绑定给模型;模型产生tool_calls,再把执行结果回传形成闭环。(LangChain)
重点:MCP(Model Context Protocol)接入
- 通过
langchain-mcp-adapters,LangChain / LangGraph Agent 可直接消费一个或多个 MCP 服务器暴露的工具(本地stdio或远端 HTTP/SSE)。官方指南与变更日志均已发布。(LangChain 文档) - 这意味着你能把“文件系统/云盘/CRM/自建 API”等 现成 MCP 工具秒变 LangChain 工具,无需重复封装。(Medium)
何时用
- 多步任务、Web 操作、数据读写、自动化流程、企业业务集成。
注意点
- 工具结果必须回传给模型继续推理;在 LangGraph 中可用
ToolNode/预构建 Agent 更好地管理状态与重试。(LangChain)
6) Callbacks(回调与可观测)
做什么
在应用的各个阶段挂钩:日志、监控、流式输出、事件订阅;配合 LangSmith 做端到端追踪与评测(项目级追踪、链路、花费、失败排查)。(LangChain)
怎么做
- LangSmith Tracing Quickstart:设置
LANGSMITH_PROJECT等环境变量后即可把链/代理的每一步都记入可视化追踪。(LangChain 文档) - (JS/TS)v0.3 起 callbacks 默认非阻塞,避免回调阻塞主流程。(js.langchain.com)
何时用
- 调优与回归评测;线上排障;审计合规;A/B 比较。
注意点
- 一开始就把追踪接上,比“出事后补”更省成本。(LangChain 文档)
小结:如何把 6 个模块拼成可落地方案
- 轻流程:
Prompt → Model → (Structured) Parser用 LCEL 串起来(可加检索Retriever);适合多数“问答/抽取/分类/小工具”场景。(LangChain) - 复杂流程:有状态/回环/分支/多 Agent → 上 LangGraph(同时承担 Memory 持久化)。工具选择建议走 MCP 适配器,最大化生态复用。(LangChain)
- 可观测与评估:用 Callbacks + LangSmith 打全链路追踪/监控/回归,避免“看不见、调不动”。(LangChain 文档)
二、快速入门实战演示
2.1 安装
建议创建一个新的虚拟环境来进行安装
Python ≥ 3.10
# LangChain 核心与常用组件
pip install -U langchain langchain-text-splitters langchain-community
# LangGraph(后文“编排”进阶用)
pip install -U langgraph
# 选一个模型提供商(本文以 DeepSeek 为例,同时给出 OpenAI/Gemini 入口)
pip install -U langchain-deepseek
# 或:OpenAI / Google GenAI
# pip install -U langchain-openai
# pip install -U "langchain[google-genai]"
# 本地向量库(RAG 最小可用)
pip install -U faiss-cpu
检查
(lc) PS C:\Users\Administrator> pip show langchain
Name: langchain
Version: 0.3.25
Summary: Building applications with LLMs through composability
Home-page:
Author:
Author-email:
License: MIT
Location: C:\ProgramData\anaconda3\envs\lc\Lib\site-packages
Requires: langchain-core, langchain-text-splitters, langsmith, pydantic, PyYAML, requests, SQLAlchemy
Required-by: langchain-community
2.2 模型接入
在进行LangChain开发之前,首先需要准备一个可以进行调用的大模型,这里我们选择使用DeepSeek的大模型,并使用DeepSeek官方的API_KEK进行调用。如果初次使用,需要现在DeepSeek官网上进行注册并创建一个新的API_Key,其官方地址为:https://platform.deepseek.com/usage
from langchain.chat_models import init_chat_model
# 方式A:显式声明 provider
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
# 方式B:合并写法(也可在其他厂商使用)
# llm = init_chat_model("deepseek:deepseek-chat")
规范输出
from IPython.display import display, Markdown
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
display(Markdown(result.content))
你好!很高兴认识你!😊
我是DeepSeek,由深度求索公司创造的AI助手。让我来详细介绍一下自己:
我的特点:
- 💬 我是一个纯文本模型,擅长理解和生成自然语言
- 📁 支持文件上传功能——可以处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息
- 🌐 具备联网搜索能力(需要你在Web/App中手动开启)
- 💾 拥有128K的上下文长度,能记住我们对话中的很多细节
我能为你做什么:
- 回答各种问题,提供知识解答
- 协助写作、翻译、总结文档
- 进行逻辑推理和分析
- 创意写作和头脑风暴
- 学习辅导和知识解释
- 日常聊天和情感支持
重要提醒:
- 我完全免费使用,没有任何收费计划
- 目前不支持语音功能
- 你可以通过官方应用商店下载App来使用我
我的知识截止到2024年7月,会尽我所能为你提供准确、有用的帮助。有什么想聊的或需要帮助的吗?我很乐意为你服务!✨
result本身包含很多人内容
AIMessage(content='你好!很高兴认识你!😊\n\n我是DeepSeek,由深度求索公司创造的AI助手。让我来详细介绍一下自己:\n\n**我的特点:**\n- 💬 我是一个纯文本模型,擅长理解和生成自然语言\n- 📁 支持文件上传功能——可以处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息\n- 🌐 具备联网搜索能力(需要你在Web/App中手动开启)\n- 💾 拥有128K的上下文长度,能记住我们对话中的很多细节\n\n**我能为你做什么:**\n- 回答各种问题,提供知识解答\n- 协助写作、翻译、总结文档\n- 进行逻辑推理和分析\n- 创意写作和头脑风暴\n- 学习辅导和知识解释\n- 日常聊天和情感支持\n\n**重要提醒:**\n- 我完全免费使用,没有任何收费计划\n- 目前不支持语音功能\n- 你可以通过官方应用商店下载App来使用我\n\n我的知识截止到2024年7月,会尽我所能为你提供准确、有用的帮助。有什么想聊的或需要帮助的吗?我很乐意为你服务!✨', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 247, 'prompt_tokens': 10, 'total_tokens': 257, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '3e42b190-a6f5-4ddc-afc8-f87711d102f8', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4dabe111-2a9d-482a-a022-de112dbc4c96-0', usage_metadata={'input_tokens': 10, 'output_tokens': 247, 'total_tokens': 257, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})
这里先看一下其结构,后面会在介绍agent时具体讲解
还可以看到可以看到,仅仅通过两行代码,便可以在LangChain中顺利调用DeepSeek模型,并得到模型的响应结果。相较于使用DeepSeek的API,使用LangChain调用模型无疑是更加简单的。同时,不仅仅是DeepSeek模型,LangChain还支持其他很多大模型,如OpenAI、Qwen、Gemini等,我们只需要在init_chat_model函数中指定不同的模型名称,就可以调用不同的模型。其工作的原理是这样的: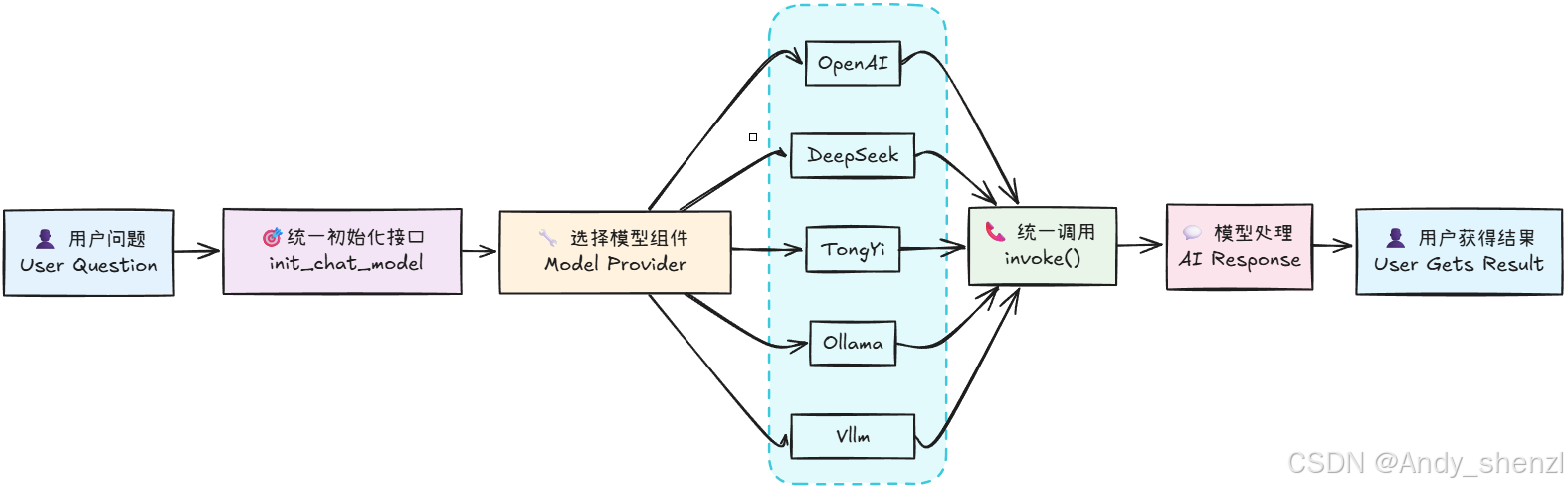
理解了这个基本原理,如果大家想在用LangChain进行开发时使用其他大模型如Qwen3系列,则只需要先获取到Qwen3模型的API_KEY,然后安装Tongyi Qwen的第三方依赖包,即可同样通过init_chat_model函数来初始化模型,并调用invoke方法来得到模型的响应结果。关于LangChain都支持哪些大模型以及每个模型对应的是哪个第三方依赖包,大家可以在LangChain的官方文档中找到,当然,除了在线大模型的接入,langChain也只是使用Ollama、vLLM等框架启动的本地大模型。
2.3 链式调用方法
顾名思义,LangChain之所以被称为LangChain,其核心概念就是Chain。 Chain翻译成中文就是“链”。一个链,指的是可以按照某一种逻辑,按顺序组合成一个流水线的方式。比如我们刚刚实现的问答流程: 用户输入一个问题 --> 发送给大模型 --> 大模型进行推理 --> 将推理结果返回给用户。这个流程就是一个链。
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "你是乐于助人的中文助手。"),
("human", "{question}")
])
llm = init_chat_model("deepseek:deepseek-chat") # 或 openai:gpt-4o-mini, google_vertexai:gemini-2.5-flash
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"question": "给我 3 条高效读论文的要点"}))
当然,高效阅读论文不仅能节省时间,还能快速抓住核心内容。以下是三条实用要点:
-
采用三遍阅读法,层层深入
- 第一遍:快速浏览标题、摘要、图表和结论,判断论文是否相关,决定是否继续阅读。
- 第二遍:精读引言、方法、结果,标记关键信息,忽略细节推导。
- 第三遍:复现作者思路,深入理解实验设计和论证逻辑,提出批判性问题。
-
带着问题主动阅读,避免被动接收
- 边读边问:“研究解决了什么缺口?”“方法的核心创新在哪?”“数据是否支撑结论?”
- 用笔记工具(如MarginNote或表格)整理“问题-答案-疑点”,形成互动式阅读习惯。
-
善用工具与协作,提升效率
- 用AI工具(如ChatGPT)快速解析复杂段落,或用翻译工具突破语言障碍。
- 与同行讨论论文疑点,通过复述和辩论巩固理解,避免陷入思维盲区。
附加技巧:优先阅读高引论文和权威团队的综述,建立领域知识框架后再深入专题论文。
此时result就不再是包含各种模型调用信息的结果,而是纯粹的模型响应的字符串结果。而这里用到的StrOutputParser()实际上就是用于构成LangChain中一个链条的一个对象,其核心功能是用于处理模型输出结果。同时我们也能发现,只需要使用 Prompt |Model | OutputParser,即可高效搭建一个链。
一个最基本的Chain结构,是由Model和OutputParser两个组件构成的,其中Model是用来调用大模型的,OutputParser是用来解析大模型的响应结果的。所以一个最简单的LLMChain结构,其数据流向正如下图所示: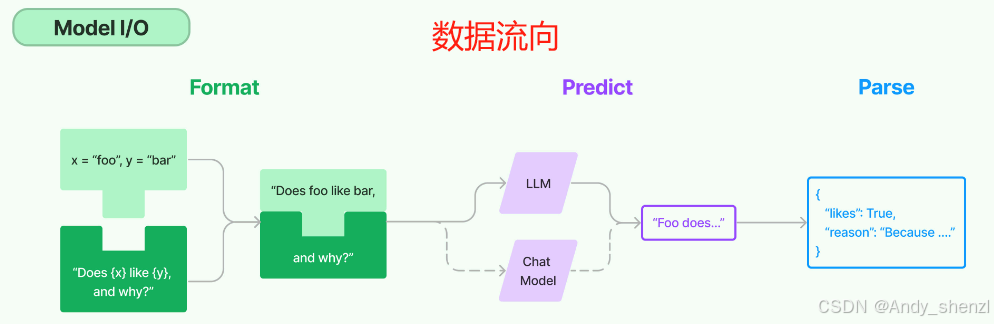
当我们调用指令跟随能力较强的大模型的时候,借助提示词模板即可实现结构化输出的结果。
- 借助提示词模板和结果解析器实现功能更加复杂的链
至此,我们就搭建了一个非常基础的链。在LangChain中,一个基础的链主要由三部分构成,分别是提示词模板、大模型和结果解析器(结构化解析器):
用户输入
↓
PromptTemplate → ChatModel → OutputParser
(提示词模板) (大模型) (结构化解析)
↓
构化结果
2.4 结构化输出:从“字符串”到“可用数据”
结构化解析器功能很多,一些核心的结构化解析器功能如下:
| 解析器名称 | 功能描述 | 类型 |
|---|---|---|
| BooleanOutputParser | 将LLM输出解析为布尔值 | 基础类型解析 |
| DatetimeOutputParser | 将LLM输出解析为日期时间 | 基础类型解析 |
| EnumOutputParser | 解析输出为预定义枚举值之一 | 基础类型解析 |
| RegexParser | 使用正则表达式解析LLM输出 | 模式匹配解析 |
| RegexDictParser | 使用正则表达式将输出解析为字典 | 模式匹配解析 |
| StructuredOutputParser | 将LLM输出解析为结构化格式 | 结构化解析 |
| YamlOutputParser | 使用Pydantic模型解析YAML输出 | 结构化解析 |
| PandasDataFrameOutputParser | 使用Pandas DataFrame格式解析输出 | 数据处理解析 |
| CombiningOutputParser | 将多个输出解析器组合为一个 | 组合解析器 |
| OutputFixingParser | 包装解析器并尝试修复解析错误 | 错误处理解析 |
| RetryOutputParser | 包装解析器并尝试修复解析错误 | 错误处理解析 |
| RetryWithErrorOutputParser | 包装解析器并尝试修复解析错误 | 错误处理解析 |
| ResponseSchema | 结构化输出解析器的响应模式 | 辅助类 |
2.4.1 布尔解析(BooleanOutputParser)
一些功能实现如下,例如借助结构化解析器可以将yes or no转化为True or Fasle:
from langchain.output_parsers.boolean import BooleanOutputParser
prompt_template = ChatPromptTemplate([
("system", "你是一个乐意助人的助手,请根据用户的问题给出回答"),
("user", "这是用户的问题: {topic}, 请用 yes 或 no 来回答")
])
# 直接使用模型 + 输出解析器
bool_qa_chain = prompt_template | llm | BooleanOutputParser()
# 测试
question = "请问 1 + 1 是否 大于 2?"
result = bool_qa_chain.invoke(question)
2.4.2 结构化 JSON(StructuredOutputParser + ResponseSchema)
StructuredOutputParser则可以在文档中提取指定的结构化信息:
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain_core.prompts import PromptTemplate
schemas = [
ResponseSchema(name="name", description="用户的姓名"),
ResponseSchema(name="age", description="用户的年龄")
]
parser = StructuredOutputParser.from_response_schemas(schemas)
prompt = PromptTemplate.from_template(
"请根据以下内容提取用户信息,并返回 JSON 格式:\n{input}\n\n{format_instructions}"
)
chain = (
prompt.partial(format_instructions=parser.get_format_instructions())
| llm
| parser
)
result = chain.invoke({"input": "用户叫李雷,今年25岁,是一名工程师。"})
print(result)
{‘name’: ‘李雷’, ‘age’: ‘25’}
这里可以具体看一下parser的结构
parser
StructuredOutputParser(response_schemas=[ResponseSchema(name='name', description='用户的姓名', type='string'), ResponseSchema(name='age', description='用户的年龄', type='string')])
调用 parser.get_format_instructions() 可自动生成 LLM 能理解的格式要求(例如:“请以 JSON 格式输出,包含以下字段:name(用户的姓名)、age(用户的年龄),不要输出其他内容”);
print(parser.get_format_instructions())
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"name": string // 用户的姓名
"age": string // 用户的年龄
}
ResponseSchema:定义「结构化输出的字段规则」,包括字段名称(name)和字段含义描述(description),用于告诉 LLM 要提取哪些信息。
StructuredOutputParser:「结构化输出解析器」,有两个核心作用:
- 自动生成 格式指令(如 “请用 JSON 输出,包含 name 和 age 字段”),避免手动写复杂的格式要求;
- 将 LLM 输出的文本(如 JSON 字符串)自动解析为 Python 字典,无需手动处理字符串转 JSON。
PromptTemplate:LangChain 的「提示词模板」,用于标准化 LLM 的输入格式,避免每次调用都重复写相同的提示词框架。
2.5. 组合多个子链
LCEL 的任何一步都能插入一个 RunnableLambda 做打印/变换,便于中间态调试:
# 第一步:根据标题生成新闻正文
news_gen_prompt = PromptTemplate.from_template(
"请根据以下新闻标题撰写一段简短的新闻内容(100字以内):\n\n标题:{title}"
)
# 第一个子链:生成新闻内容
news_chain = news_gen_prompt | model
# 第二步:从正文中提取结构化字段
schemas = [
ResponseSchema(name="time", description="事件发生的时间"),
ResponseSchema(name="location", description="事件发生的地点"),
ResponseSchema(name="event", description="发生的具体事件"),
]
parser = StructuredOutputParser.from_response_schemas(schemas)
summary_prompt = PromptTemplate.from_template(
"请从下面这段新闻内容中提取关键信息,并返回结构化JSON格式:\n\n{news}\n\n{format_instructions}"
)
# 第二个子链:生成新闻摘要
summary_chain = (
summary_prompt.partial(format_instructions=parser.get_format_instructions())
| model
| parser
)
# 组合成一个复合 Chain
full_chain = news_chain | summary_chain
# 调用复合链
result = full_chain.invoke({"title": "苹果公司在加州发布新款AI芯片"})
print(result)
{‘time’: ‘未明确提及’, ‘location’: ‘加州’, ‘event’: ‘苹果公司发布新款AI芯片,显著提升设备端AI处理能力,采用先进架构支持更复杂机器学习任务,将应用于新一代iPhone及Mac产品’}
代码脉络:
用户输入(title)
│
▼
┌────────────────────────────┐
│ Chain 1: 生成新闻正文 │
│ Prompt: news_gen_prompt │
│ Model: DeepSeek │
└────────────────────────────┘
│
▼
生成的新闻内容(news)
│
▼
┌───────────────────────────────────────┐
│ Chain 2: 提取结构化字段(摘要) │
│ Prompt: summary_pro mpt │
│ Model: DeepSeek │
│ OutputParser: StructuredOutputParser │
└───────────────────────────────────────┘
│
▼
结化输出(如 JSON:时间、地点、事件)
2.6 自定义运行节点
from langchain_core.runnables import RunnableLambda
from langchain_core.runnables import RunnableLambda
# 一个简单的打印函数,调试用
def debug_print(x):
print("中间结果(新闻正文):", x)
return x
debug_node = RunnableLambda(debug_print)
# 插入 debug 节点
full_chain = news_chain | debug_node | summary_chain
中间结果(新闻正文): content=‘苹果公司在加州发布新款AI芯片,显著提升设备端人工智能处理能力。该芯片采用先进架构,支持更复杂的机器学习任务,有望应用于新一代iPhone及Mac产品,为用户带来更智能、高效的体验。’ additional_kwargs={‘refusal’: None} response_metadata={‘token_usage’: {‘completion_tokens’: 44, ‘prompt_tokens’: 29, ‘total_tokens’: 73, ‘completion_tokens_details’: None, ‘prompt_tokens_details’: {‘audio_tokens’: None, ‘cached_tokens’: 0}, ‘prompt_cache_hit_tokens’: 0, ‘prompt_cache_miss_tokens’: 29}, ‘model_name’: ‘deepseek-chat’, ‘system_fingerprint’: ‘fp_ffc7281d48_prod0820_fp8_kvcache’, ‘id’: ‘80136b1a-f3d3-49e5-aa4d-cb636bd4e909’, ‘service_tier’: None, ‘finish_reason’: ‘stop’, ‘logprobs’: None} id=‘run–b98c21e2-a01b-4d88-a3e1-3a331aaac8ba-0’ usage_metadata={‘input_tokens’: 29, ‘output_tokens’: 44, ‘total_tokens’: 73, ‘input_token_details’: {‘cache_read’: 0}, ‘output_token_details’: {}}
{‘time’: ‘未提及’, ‘location’: ‘加州’, ‘event’: ‘苹果公司发布新款AI芯片,显著提升设备端人工智能处理能力,采用先进架构支持更复杂机器学习任务,将应用于新一代iPhone及Mac产品’}
通过上述不同的尝试,我们就已经理解了在langChain中,如何使用Model、OutputParser、ChatPromptTemplate来构建一个简单的Chain。其中:
ChatPromptTemplate是用来构建提示模板的,将输入的问题转化为消息列表,可以设置系统指令,也可以添加一些变量;Model是用来调用大模型的,可以指定使用不同的模型;OutputParser是用来解析大模型的响应结果的,可以指定使用不同的解析器。
2.7 流式输出
大家经常看到的问答机器人其实都是采用流式传输模式。用户输入问题,等待模型直接返回回答,然后用户再输入问题,模型再返回回答,这样循环下去,用户输入问题和模型返回回答之间的时间间隔太长,导致用户感觉机器人反应很慢。所以LangChain提供了一个astream方法,可以实现流式输出,即一旦模型有输出,就立即返回,这样用户就可以看到模型正在思考,而不是等待模型思考完再返回。
实现的方法也非常简单,只需要在调用模型时将invoke方法替换为astream方法,然后使用async for循环来获取模型的输出即可。代码如下:
from langchain_core.output_parsers import StrOutputParser
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你叫小智,是一名乐于助人的助手。"),
("human", "{input}")
])
llm = init_chat_model("deepseek:deepseek-chat")
qa_chain = prompt | llm | StrOutputParser()
async def demo():
async for chunk in qa_chain.astream({"input": "简单介绍下你自己"}):
print(chunk, end="", flush=True)
await demo()
你好!我是小智,一名乐于助人的智能助手。我的主要任务是为你提供信息、解答问题、协助处理日常事务,或者陪你聊天。无论是学习、工作、生活还是娱乐相关的问题,我都会尽力帮助你。随时欢迎向我提问或分享你的想法! 😊
2.8 前端交互界面
首先需要安装一下gradio的第三方依赖包,
# 安装 Gradio
! pip install gradio
完整代码:
import gradio as gr
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = init_chat_model("deepseek:deepseek-chat")
system_prompt = ChatPromptTemplate.from_messages([
("system", "你叫小智,是一名乐于助人的助手。"),
("human", "{input}")
])
qa_chain = system_prompt | llm | StrOutputParser()
async def chat_response(message, history):
partial = ""
async for chunk in qa_chain.astream({"input": message}):
partial += chunk
yield partial
with gr.Blocks(title="LangChain x DeepSeek Demo") as demo:
chat = gr.Chatbot(height=480)
msg = gr.Textbox()
send = gr.Button("发送")
async def on_send(m, h):
h = h + [(m, None)]; yield "", h
async for resp in chat_response(m, h):
h[-1] = (m, resp); yield "", h
send.click(on_send, [msg, chat], [msg, chat])
demo.launch()
c:\ProgramData\anaconda3\envs\lc\Lib\site-packages\pydantic\_internal\_generate_schema.py:276: RuntimeWarning: coroutine 'demo' was never awaited
def _add_custom_serialization_from_json_encoders(
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
C:\Users\Administrator\AppData\Local\Temp\ipykernel_37552\1905437079.py:20: UserWarning: You have not specified a value for the `type` parameter. Defaulting to the 'tuples' format for chatbot messages, but this is deprecated and will be removed in a future version of Gradio. Please set type='messages' instead, which uses openai-style dictionaries with 'role' and 'content' keys.
chat = gr.Chatbot(height=480)
* Running on local URL: http://127.0.0.1:7861
* To create a public link, set `share=True` in `launch()`.
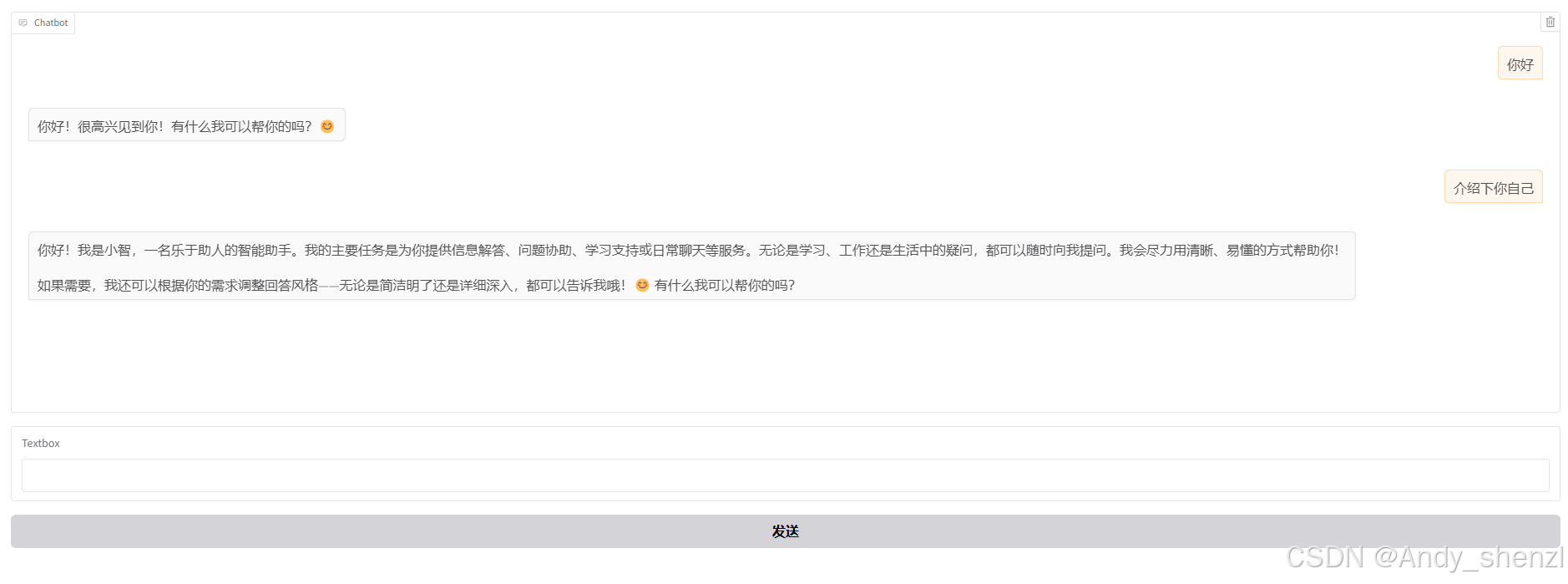
2.9 最小RAG
RAG 典型流水线:加载/切分 → 向量化入库 → 检索 → 组装上下文 → 生成。建议先用本地 FAISS 起步,再切换云向量库。
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.embeddings import init_embeddings
from langchain_core.runnables import RunnablePassthrough
docs = [
"LangChain 将 LLM、工具、检索串成可观测工作流。",
"LangGraph 用状态图编排多步骤/多智能体流程,适合生产级代理。"
]
splits = RecursiveCharacterTextSplitter(chunk_size=120, chunk_overlap=20)\
.create_documents(docs)
emb = init_embeddings("openai:text-embedding-3-small", openai_api_key="sk-e53", openai_api_base="https:/v1") # 可换本地/其他厂商
vectordb = FAISS.from_documents(splits, emb)
retriever = vectordb.as_retriever() # 统一检索接口
prompt = ChatPromptTemplate.from_messages([
("system", "仅依据给定{context}回答;若缺少依据请说“我不知道”。"),
("human", "{question}")
])
llm = init_chat_model("deepseek:deepseek-chat")
def join_docs(docs): return "\n\n".join(d.page_content for d in docs)
rag = ({"context": retriever | join_docs, "question": RunnablePassthrough()}
| prompt | llm | StrOutputParser())
print(rag.invoke( "LangGraph 适合哪些场景?"))
根据给定信息,LangGraph 适合以下场景:
-
编排多步骤流程
- 适用于需要按顺序或条件执行多个步骤的任务,例如数据处理、决策流程或复杂查询处理。
-
多智能体系统
- 支持多个智能体(如不同功能的 LLM 或工具)协同工作,通过状态图管理它们之间的交互和状态转移。
-
生产级代理应用
- 设计用于构建可靠、可扩展的生产环境系统,集成 LLM、工具和检索组件,并确保工作流可观测。
如果涉及具体技术细节或超出上述范围,请提供更多上下文,我将尽力协助。
RecursiveCharacterTextSplitter:推荐的通用文本切分器,按段落→句子→词的优先级递归切分,得到均匀的 chunk。
FAISS:本地内存型向量库,快速完成相似度检索;LangChain 内置了便捷构建方法。
init_embeddings:一行初始化嵌入模型;参数(如 API base、key)会透传到具体 provider 的集成。
RunnablePassthrough:LCEL 的“原样透传”节点,常和并行映射一起用来把“原始输入”带到后续步骤(比如把用户问题同时送给 Prompt 的 {question})。
更多推荐


 33
33 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)